Django之ORM数据库
5.1 数据库的配置
1 django默认支持sqlite,mysql, oracle,postgresql数据库。
<1> sqlite
django默认使用sqlite的数据库,默认自带sqlite的数据库驱动 , 引擎名称:django.db.backends.sqlite3
<2> mysql
引擎名称:django.db.backends.mysql
2 mysql驱动程序
- MySQLdb(mysql python)
- mysqlclient
- MySQL
- PyMySQL(纯python的mysql驱动程序)
3 在django的项目中会默认使用sqlite数据库,在settings里有如下设置:

如果我们想要更改数据库,需要修改如下:

DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'books', #你的数据库名称
'USER': 'root', #你的数据库用户名
'PASSWORD': '', #你的数据库密码
'HOST': '', #你的数据库主机,留空默认为localhost
'PORT': '', #你的数据库端口
}
}
注意:
NAME即数据库的名字,在mysql连接前该数据库必须已经创建,而上面的sqlite数据库下的db.sqlite3则是项目自动创建 USER和PASSWORD分别是数据库的用户名和密码。 设置完后,再启动我们的Django项目前,我们需要激活我们的mysql。 然后,启动项目,会报错:no module named MySQLdb 这是因为django默认你导入的驱动是MySQLdb,可是MySQLdb对于py3有很大问题,所以我们需要的驱动是PyMySQL 所以,我们只需要找到项目名文件下的__init__,在里面写入: import pymysql
pymysql.install_as_MySQLdb() 问题解决!
5.2 ORM表模型
表(模型)的创建:
实例:我们来假定下面这些概念,字段和关系
作者模型:一个作者有姓名。
作者详细模型:把作者的详情放到详情表,包含性别,email地址和出生日期,作者详情模型和作者模型之间是一对一的关系(one-to-one)(类似于每个人和他的身份证之间的关系),在大多数情况下我们没有必要将他们拆分成两张表,这里只是引出一对一的概念。
出版商模型:出版商有名称,地址,所在城市,省,国家和网站。
书籍模型:书籍有书名和出版日期,一本书可能会有多个作者,一个作者也可以写多本书,所以作者和书籍的关系就是多对多的关联关系(many-to-many),一本书只应该由一个出版商出版,所以出版商和书籍是一对多关联关系(one-to-many),也被称作外键。
from django.db import models<br>
class Publisher(models.Model):
name = models.CharField(max_length=, verbose_name="名称")
address = models.CharField("地址", max_length=)
city = models.CharField('城市',max_length=)
state_province = models.CharField(max_length=)
country = models.CharField(max_length=)
website = models.URLField() class Meta:
verbose_name = '出版商'
verbose_name_plural = verbose_name def __str__(self):
return self.name class Author(models.Model):
name = models.CharField(max_length=)
def __str__(self):
return self.name class AuthorDetail(models.Model):
sex = models.BooleanField(max_length=, choices=((, '男'),(, '女'),))
email = models.EmailField()
address = models.CharField(max_length=)
birthday = models.DateField()
author = models.OneToOneField(Author) class Book(models.Model):
title = models.CharField(max_length=)
authors = models.ManyToManyField(Author)
publisher = models.ForeignKey(Publisher)
publication_date = models.DateField()
price=models.DecimalField(max_digits=,decimal_places=,default=)
def __str__(self):
return self.title
分析代码:
<1> 每个数据模型都是django.db.models.Model的子类,它的父类Model包含了所有必要的和数据库交互的方法。并提供了一个简介漂亮的定义数据库字段的语法。
<2> 每个模型相当于单个数据库表(多对多关系例外,会多生成一张关系表),每个属性也是这个表中的字段。属性名就是字段名,它的类型(例如CharField)相当于数据库的字段类型(例如varchar)。大家可以留意下其它的类型都和数据库里的什么字段对应。
<3> 模型之间的三种关系:一对一,一对多,多对多。
一对一:实质就是在主外键(author_id就是foreign key)的关系基础上,给外键加了一个UNIQUE=True的属性;
一对多:就是主外键关系;(foreign key)
多对多:(ManyToManyField) 自动创建第三张表(当然我们也可以自己创建第三张表:两个foreign key)
ORM之增(create,save)
from app01.models import *
#create方式一: Author.objects.create(name='Alvin')
#create方式二: Author.objects.create(**{"name":"alex"})
#save方式一: author=Author(name="alvin")
author.save()
#save方式二: author=Author()
author.name="alvin"
author.save()
重点来了------->那么如何创建存在一对多或多对多关系的一本书的信息呢?(如何处理外键关系的字段如一对多的publisher和多对多的authors)
#一对多(ForeignKey):
#方式一: 由于绑定一对多的字段,比如publish,存到数据库中的字段名叫publish_id,所以我们可以直接给这个
# 字段设定对应值:
Book.objects.create(title='php',
publisher_id=, #这里的2是指为该book对象绑定了Publisher表中id=2的行对象
publication_date='2017-7-7',
price=)
#方式二:
# <> 先获取要绑定的Publisher对象:
pub_obj=Publisher(name='河大出版社',address='保定',city='保定',
state_province='河北',country='China',website='http://www.hbu.com')
OR pub_obj=Publisher.objects.get(id=)
# <>将 publisher_id= 改为 publisher=pub_obj
#多对多(ManyToManyField()):
author1=Author.objects.get(id=)
author2=Author.objects.filter(name='alvin')[]
book=Book.objects.get(id=)
book.authors.add(author1,author2)
#等同于:
book.authors.add(*[author1,author2])
book.authors.remove(*[author1,author2])
#-------------------
book=models.Book.objects.filter(id__gt=)
authors=models.Author.objects.filter(id=)[]
authors.book_set.add(*book)
authors.book_set.remove(*book)
#-------------------
book.authors.add()
book.authors.remove()
authors.book_set.add()
authors.book_set.remove()
#注意: 如果第三张表是通过models.ManyToManyField()自动创建的,那么绑定关系只有上面一种方式
# 如果第三张表是自己创建的:
class Book2Author(models.Model):
author=models.ForeignKey("Author")
Book= models.ForeignKey("Book")
# 那么就还有一种方式:
author_obj=models.Author.objects.filter(id=)[]
book_obj =models.Book.objects.filter(id=)[]
s=models.Book2Author.objects.create(author_id=,Book_id=)
s.save()
s=models.Book2Author(author=author_obj,Book_id=)
s.save()
ORM之删(delete)
>>> Book.objects.filter(id=).delete()
(, {'app01.Book_authors': , 'app01.Book': })
我们表面上删除了一条信息,实际却删除了三条,因为我们删除的这本书在Book_authors表中有两条相关信息,这种删除方式就是django默认的级联删除。
ORM之改(update和save)
实例:
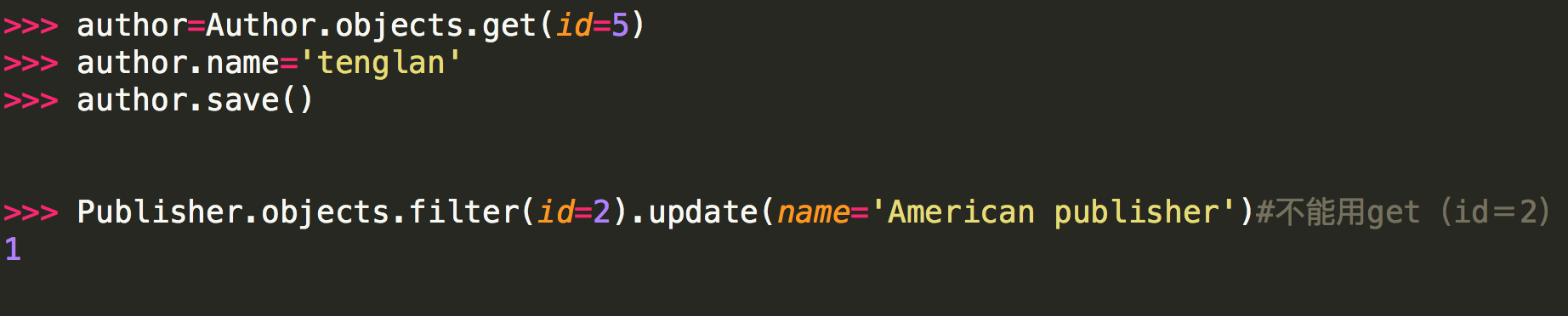
注意:
<1> 第二种方式修改不能用get的原因是:update是QuerySet对象的方法,get返回的是一个model对象,它没有update方法,而filter返回的是一个QuerySet对象(filter里面的条件可能有多个条件符合,比如name='alvin',可能有两个name='alvin'的行数据)。
<2>在“插入和更新数据”小节中,我们有提到模型的save()方法,这个方法会更新一行里的所有列。 而某些情况下,我们只需要更新行里的某几列。
#---------------- update方法直接设定对应属性----------------
models.Book.objects.filter(id=).update(title="PHP")
##sql:
##UPDATE "app01_book" SET "title" = 'PHP' WHERE "app01_book"."id" = ; args=('PHP', ) #--------------- save方法会将所有属性重新设定一遍,效率低-----------
obj=models.Book.objects.filter(id=)[]
obj.title="Python"
obj.save()
# SELECT "app01_book"."id", "app01_book"."title", "app01_book"."price",
# "app01_book"."color", "app01_book"."page_num",
# "app01_book"."publisher_id" FROM "app01_book" WHERE "app01_book"."id" = LIMIT ;
#
# UPDATE "app01_book" SET "title" = 'Python', "price" = , "color" = 'red', "page_num" = ,
# "publisher_id" = WHERE "app01_book"."id" = ;
此外,update()方法对于任何结果集(QuerySet)均有效,这意味着你可以同时更新多条记录update()方法会返回一个整型数值,表示受影响的记录条数。
注意,这里因为update返回的是一个整形,所以没法用query属性;对于每次创建一个对象,想显示对应的raw sql,需要在settings加上日志记录部分:
LOGGING = {
'version': ,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
ORM之查(filter,value)
查询API:
# 查询相关API: # <>filter(**kwargs): 它包含了与所给筛选条件相匹配的对象 # <>all(): 查询所有结果 # <>get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。 #-----------下面的方法都是对查询的结果再进行处理:比如 objects.filter.values()-------- # <>values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列 model的实例化对象,而是一个可迭代的字典序列 # <>exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象 # <>order_by(*field): 对查询结果排序 # <>reverse(): 对查询结果反向排序 # <>distinct(): 从返回结果中剔除重复纪录 # <>values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列 # <>count(): 返回数据库中匹配查询(QuerySet)的对象数量。 # <>first(): 返回第一条记录 # <>last(): 返回最后一条记录 # <>exists(): 如果QuerySet包含数据,就返回True,否则返回False
---------------了不起的双下划线(__)之单表条件查询---------------- # models.Tb1.objects.filter(id__lt=, id__gt=) # 获取id大于1 且 小于10的值
#
# models.Tb1.objects.filter(id__in=[, , ]) # 获取id等于11、、33的数据
# models.Tb1.objects.exclude(id__in=[, , ]) # not in
#
# models.Tb1.objects.filter(name__contains="ven")
# models.Tb1.objects.filter(name__icontains="ven") # icontains大小写不敏感
#
# models.Tb1.objects.filter(id__range=[, ]) # 范围bettwen and
#
# startswith,istartswith, endswith, iendswith,
了不起的双下划线
QuerySet与惰性机制
所谓惰性机制:Publisher.objects.all()或者.filter()等都只是返回了一个QuerySet(查询结果集对象),它并不会马上执行sql,而是当调用QuerySet的时候才执行。
QuerySet特点:
<1> 可迭代的
<2> 可切片
#objs=models.Book.objects.all()#[obj1,obj2,ob3...]
#QuerySet: 可迭代
# for obj in objs:#每一obj就是一个行对象
# print("obj:",obj)
# QuerySet: 可切片
# print(objs[])
# print(objs[:])
# print(objs[::-])
QuerySet的高效使用:
<>Django的queryset是惰性的
Django的queryset对应于数据库的若干记录(row),通过可选的查询来过滤。例如,下面的代码会得
到数据库中名字为‘Dave’的所有的人:person_set = Person.objects.filter(first_name="Dave")
上面的代码并没有运行任何的数据库查询。你可以使用person_set,给它加上一些过滤条件,或者将它传给某个函数,
这些操作都不会发送给数据库。这是对的,因为数据库查询是显著影响web应用性能的因素之一。
<>要真正从数据库获得数据,你可以遍历queryset或者使用if queryset,总之你用到数据时就会执行sql.
为了验证这些,需要在settings里加入 LOGGING(验证方式)
obj=models.Book.objects.filter(id=)
# for i in obj:
# print(i)
# if obj:
# print("ok")
<>queryset是具有cache的
当你遍历queryset时,所有匹配的记录会从数据库获取,然后转换成Django的model。这被称为执行
(evaluation).这些model会保存在queryset内置的cache中,这样如果你再次遍历这个queryset,
你不需要重复运行通用的查询。
obj=models.Book.objects.filter(id=)
# for i in obj:
# print(i)
## models.Book.objects.filter(id=).update(title="GO")
## obj_new=models.Book.objects.filter(id=)
# for i in obj:
# print(i) #LOGGING只会打印一次
<>
简单的使用if语句进行判断也会完全执行整个queryset并且把数据放入cache,虽然你并不需要这些
数据!为了避免这个,可以用exists()方法来检查是否有数据:
obj = Book.objects.filter(id=)
# exists()的检查可以避免数据放入queryset的cache。
if obj.exists():
print("hello world!")
<>当queryset非常巨大时,cache会成为问题
处理成千上万的记录时,将它们一次装入内存是很浪费的。更糟糕的是,巨大的queryset可能会锁住系统
进程,让你的程序濒临崩溃。要避免在遍历数据的同时产生queryset cache,可以使用iterator()方法
来获取数据,处理完数据就将其丢弃。
objs = Book.objects.all().iterator()
# iterator()可以一次只从数据库获取少量数据,这样可以节省内存
for obj in objs:
print(obj.name)
#BUT,再次遍历没有打印,因为迭代器已经在上一次遍历(next)到最后一次了,没得遍历了
for obj in objs:
print(obj.name)
#当然,使用iterator()方法来防止生成cache,意味着遍历同一个queryset时会重复执行查询。所以使
#用iterator()的时候要当心,确保你的代码在操作一个大的queryset时没有重复执行查询
总结:
queryset的cache是用于减少程序对数据库的查询,在通常的使用下会保证只有在需要的时候才会查询数据库。
使用exists()和iterator()方法可以优化程序对内存的使用。不过,由于它们并不会生成queryset cache,可能
会造成额外的数据库查询。
对象查询,单表条件查询,多表条件关联查询
#--------------------对象形式的查找--------------------------
# 正向查找
ret1=models.Book.objects.first()
print(ret1.title)
print(ret1.price)
print(ret1.publisher)
print(ret1.publisher.name) #因为一对多的关系所以ret1.publisher是一个对象,而不是一个queryset集合 # 反向查找
ret2=models.Publish.objects.last()
print(ret2.name)
print(ret2.city)
#如何拿到与它绑定的Book对象呢?
print(ret2.book_set.all()) #ret2.book_set是一个queryset集合 #---------------了不起的双下划线(__)之单表条件查询---------------- # models.Tb1.objects.filter(id__lt=, id__gt=) # 获取id大于1 且 小于10的值
#
# models.Tb1.objects.filter(id__in=[, , ]) # 获取id等于11、、33的数据
# models.Tb1.objects.exclude(id__in=[, , ]) # not in
#
# models.Tb1.objects.filter(name__contains="ven")
# models.Tb1.objects.filter(name__icontains="ven") # icontains大小写不敏感
#
# models.Tb1.objects.filter(id__range=[, ]) # 范围bettwen and
#
# startswith,istartswith, endswith, iendswith, #----------------了不起的双下划线(__)之多表条件关联查询--------------- # 正向查找(条件) # ret3=models.Book.objects.filter(title='Python').values('id')
# print(ret3)#[{'id': }] #正向查找(条件)之一对多 ret4=models.Book.objects.filter(title='Python').values('publisher__city')
print(ret4) #[{'publisher__city': '北京'}] #正向查找(条件)之多对多
ret5=models.Book.objects.filter(title='Python').values('author__name')
print(ret5)
ret6=models.Book.objects.filter(author__name="alex").values('title')
print(ret6) #注意
#正向查找的publisher__city或者author__name中的publisher,author是book表中绑定的字段
#一对多和多对多在这里用法没区别 # 反向查找(条件) #反向查找之一对多:
ret8=models.Publisher.objects.filter(book__title='Python').values('name')
print(ret8)#[{'name': '人大出版社'}] 注意,book__title中的book就是Publisher的关联表名 ret9=models.Publisher.objects.filter(book__title='Python').values('book__authors')
print(ret9)#[{'book__authors': }, {'book__authors': }] #反向查找之多对多:
ret10=models.Author.objects.filter(book__title='Python').values('name')
print(ret10)#[{'name': 'alex'}, {'name': 'alvin'}] #注意
#正向查找的book__title中的book是表名Book
#一对多和多对多在这里用法没区别
注意:条件查询即与对象查询对应,是指在filter,values等方法中的通过__来明确查询条件。
聚合查询和分组查询
<1> aggregate(*args,**kwargs):
通过对QuerySet进行计算,返回一个聚合值的字典。aggregate()中每一个参数都指定一个包含在字典
from django.db.models import Avg,Min,Sum,Max 从整个查询集生成统计值。比如,你想要计算所有在售书的平均价钱。Django的查询语法提供了一种方式描述所有
图书的集合。 >>> Book.objects.all().aggregate(Avg('price'))
{'price__avg': 34.35} aggregate()子句的参数描述了我们想要计算的聚合值,在这个例子中,是Book模型中price字段的平均值 aggregate()是QuerySet 的一个终止子句,意思是说,它返回一个包含一些键值对的字典。键的名称是聚合值的
标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。如果你想要为聚合值指定
一个名称,可以向聚合子句提供它:
>>> Book.objects.aggregate(average_price=Avg('price'))
{'average_price': 34.35} 如果你也想知道所有图书价格的最大值和最小值,可以这样查询:
>>> Book.objects.aggregate(Avg('price'), Max('price'), Min('price'))
{'price__avg': 34.35, 'price__max': Decimal('81.20'), 'price__min': Decimal('12.99')}
<2> annotate(*args,**kwargs):
可以通过计算查询结果中每一个对象所关联的对象集合,从而得出总计值(也可以是平均值或总和),即为查询集的每一项生成聚合。
查询alex出的书总价格

查询各个作者出的书的总价格,这里就涉及到分组了,分组条件是authors__name

查询各个出版社最便宜的书价是多少

中的返回值。即在查询集上生成聚合。
F查询和Q查询
仅仅靠单一的关键字参数查询已经很难满足查询要求。此时Django为我们提供了F和Q查询:
# F 使用查询条件的值,专门取对象中某列值的操作
# from django.db.models import F
# models.Tb1.objects.update(num=F('num')+)
# Q 构建搜索条件
from django.db.models import Q
# Q对象(django.db.models.Q)可以对关键字参数进行封装,从而更好地应用多个查询
q1=models.Book.objects.filter(Q(title__startswith='P')).all()
print(q1)#[<Book: Python>, <Book: Perl>]
# 、可以组合使用&,|操作符,当一个操作符是用于两个Q的对象,它产生一个新的Q对象。
Q(title__startswith='P') | Q(title__startswith='J')
# 、Q对象可以用~操作符放在前面表示否定,也可允许否定与不否定形式的组合
Q(title__startswith='P') | ~Q(pub_date__year=)
# 、应用范围:
# Each lookup function that takes keyword-arguments (e.g. filter(),
# exclude(), get()) can also be passed one or more Q objects as
# positional (not-named) arguments. If you provide multiple Q object
# arguments to a lookup function, the arguments will be “AND”ed
# together. For example:
Book.objects.get(
Q(title__startswith='P'),
Q(pub_date=date(, , )) | Q(pub_date=date(, , ))
)
#sql:
# SELECT * from polls WHERE question LIKE 'P%'
# AND (pub_date = '2005-05-02' OR pub_date = '2005-05-06')
# import datetime
# e=datetime.date(,,) #--
# 、Q对象可以与关键字参数查询一起使用,不过一定要把Q对象放在关键字参数查询的前面。
# 正确:
Book.objects.get(
Q(pub_date=date(, , )) | Q(pub_date=date(, , )),
title__startswith='P')
# 错误:
Book.objects.get(
question__startswith='P',
Q(pub_date=date(, , )) | Q(pub_date=date(, , )))
admin的配置
admin是django强大功能之一,它能共从数据库中读取数据,呈现在页面中,进行管理。默认情况下,它的功能已经非常强大,如果你不需要复杂的功能,它已经够用,但是有时候,一些特殊的功能还需要定制,比如搜索功能,下面这一系列文章就逐步深入介绍如何定制适合自己的admin应用。
如果你觉得英文界面不好用,可以在setting.py 文件中修改以下选项
LANGUAGE_CODE = 'en-us' #LANGUAGE_CODE = 'zh-hans'
一 认识ModelAdmin
管理界面的定制类,如需扩展特定的model界面需从该类继承。
二 注册medel类到admin的两种方式:
<1> 使用register的方法
admin.site.register(Book,MyAdmin)
<2> 使用register的装饰器
@admin.register(Book)
三 掌握一些常用的设置技巧
- list_display: 指定要显示的字段
- search_fields: 指定搜索的字段
- list_filter: 指定列表过滤器
- ordering: 指定排序字段
from django.contrib import admin
from app01.models import *
# Register your models here. # @admin.register(Book)#----->单给某个表加一个定制
class MyAdmin(admin.ModelAdmin):
list_display = ("title","price","publisher")
search_fields = ("title","publisher")
list_filter = ("publisher",)
ordering = ("price",)
fieldsets =[
(None, {'fields': ['title']}),
('price information', {'fields': ['price',"publisher"], 'classes': ['collapse']}),
] admin.site.register(Book,MyAdmin)
admin.site.register(Publish)
admin.site.register(Author)
Django之ORM数据库的更多相关文章
- Django【第5篇】:Django之ORM数据库操作
django之ORM数据库操作 一.ORM介绍 映射关系: 表名 -------------------->类名 字段-------------------->属性 表记录-------- ...
- 关于Django中ORM数据库迁移的配置
Django中ORM数据库迁移配置 1,若想将模型转为mysql数据库中的表,需要在settings中配置: DATABASES = { 'default': { 'ENGINE': 'django. ...
- django之ORM数据库操作
一.ORM介绍 映射关系: 表名 -------------------->类名 字段-------------------->属性 表记录----------------->类实例 ...
- Django框架----ORM数据库操作
一.ORM介绍 ORM概念 对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术. 简单的说,ORM是通过使用 ...
- Django框架(八) Django之ORM数据库操作
创建模型 实例:我们来假定下面这些概念,字段和关系 作者模型:一个作者有姓名和年龄. 作者详细模型:把作者的详情放到详情表,包含生日,手机号,家庭住址等信息.作者详情模型和作者模型之间是一对一的关系( ...
- Django: ORM 数据库设置和读写分离
一.Django的数据库配置 (一)修改settings.py文件关于数据库的配置: Django默认使用sqlite: # Django默认的数据库库,SQLit配置 DATABASES = { ' ...
- Django之ORM数据库增删改查
总结:ORM的 查.增.删.改 - 查 - client - 有一个展示页面(xxx_show.html) - 这一个页面一输入执行后,get请求向server端发送 - 这个展示页面有添加按钮.删除 ...
- django框架ORM数据库
字段类型 选项 null是数据库范畴的概念,blank是表单验证范畴的 外键 在设置外键时,需要通过on_delete选项指明主表删除数据时,对于外键引用表数据如何处理,在django.db.mode ...
- Django框架----ORM数据库操作注意事项
1.多对多的正向查询 class Class(models.Model): name = models.CharField(max_length=32,verbose_name="班级名&q ...
随机推荐
- django中使用Ajax
内容: 1.Ajax原理与基本使用 2.Ajax发送get请求 3.Ajax发送post请求 4.Ajax上传文件 5.Ajax设置csrf_token 6.django序列化 参考:https:// ...
- servletConfig的使用案例
servletConfig参数的使用案例 首先,建立Dynamic Web Project ,同样命名FirstServlet,然后建立Servlet:Login.java,包名为cc.openhom ...
- 34. Studio字符串分割split用法
var v = "1,2,3"; var arr = v.toString().split(","); 备注:最好先toString()转为字符串,不然有些情况 ...
- linux获取日志指定行数范围内的内容
假如我要获取“浅浅岁月拂满爱人袖”到“落入凡尘伤情着我”之间的内容. 1.首先得到他们所在的行号: -n选项显示行号 但是有时候grep后显示的是“匹配到二进制文件(标准输入)”,说明搜索的字符串在某 ...
- 19.OGNL与ValueStack(VS)-OGNL入门
转自:https://wenku.baidu.com/view/84fa86ae360cba1aa911da02.html 下面我们在com.asm.vo.User类中增加一个字段private Ad ...
- win2008 server ping不同
win2008 server ping不同,网络正常. 下图可以解决!!!
- 机器学习入门-数据过采样(上采样)1. SMOTE
from imblearn.over_sampling import SMOTE # 导入 overstamp = SMOTE(random_state=0) # 对训练集的数据进行上采样,测试集的 ...
- WINFORM小列子参考
1.用树型列表动态显示菜单 密码:zx9t 二.Popup窗口提醒(桌面右下角出现) 密码:cjjo 三.台历 密码:nq4m 四.文件复制 密码:lsqj 五.进度条 密码:byti 六 ...
- java并发--流量控制demo
实现一个流控程序.控制客户端每秒调用某个远程服务不超过N次,客户端是会多线程并发调用,需要一个轻量简洁的实现,大家看看下面的一个实现,然后可以自己写一个实现. import java.util.Dat ...
- %s %r 区别 转
也可说是 str() 和 repr() 的区别 转自:http://blog.csdn.net/wusuopubupt/article/details/23678291 %r用rper()方法处理对象 ...