Hive学习之路 (十一)Hive的5个面试题
一、求单月访问次数和总访问次数
1、数据说明
数据字段说明
用户名,月份,访问次数
数据格式
A,2015-01,5
A,2015-01,15
B,2015-01,5
A,2015-01,8
B,2015-01,25
A,2015-01,5
A,2015-02,4
A,2015-02,6
B,2015-02,10
B,2015-02,5
A,2015-03,16
A,2015-03,22
B,2015-03,23
B,2015-03,10
B,2015-03,1
2、数据准备
(1)创建表
use myhive;
create external table if not exists t_access(
uname string comment '用户名',
umonth string comment '月份',
ucount int comment '访问次数'
) comment '用户访问表'
row format delimited fields terminated by ","
location "/hive/t_access";
(2)导入数据
load data local inpath "/home/hadoop/access.txt" into table t_access;
(3)验证数据
select * from t_access;
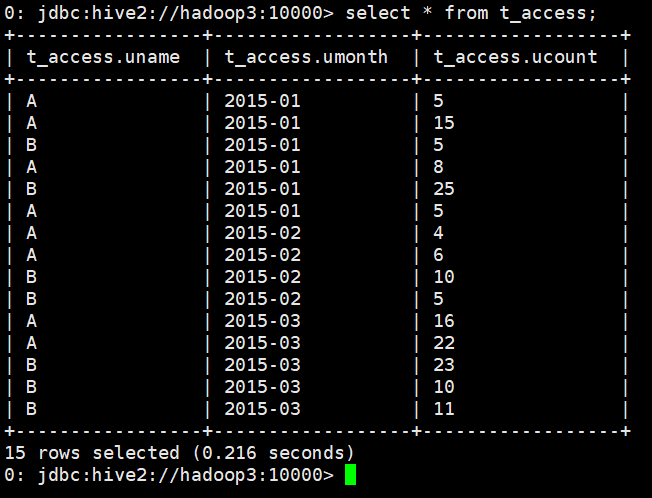
3、结果需求
现要求出:
每个用户截止到每月为止的最大单月访问次数和累计到该月的总访问次数,结果数据格式如下

4、需求分析
此结果需要根据用户+月份进行分组
(1)先求出当月访问次数
--求当月访问次数
create table tmp_access(
name string,
mon string,
num int
); insert into table tmp_access
select uname,umonth,sum(ucount)
from t_access t group by t.uname,t.umonth; select * from tmp_access;
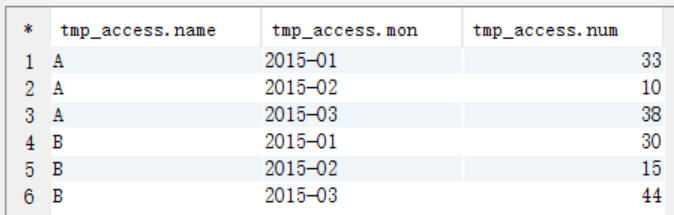
(2)tmp_access进行自连接视图
create view tmp_view as
select a.name anme,a.mon amon,a.num anum,b.name bname,b.mon bmon,b.num bnum from tmp_access a join tmp_access b
on a.name=b.name; select * from tmp_view;
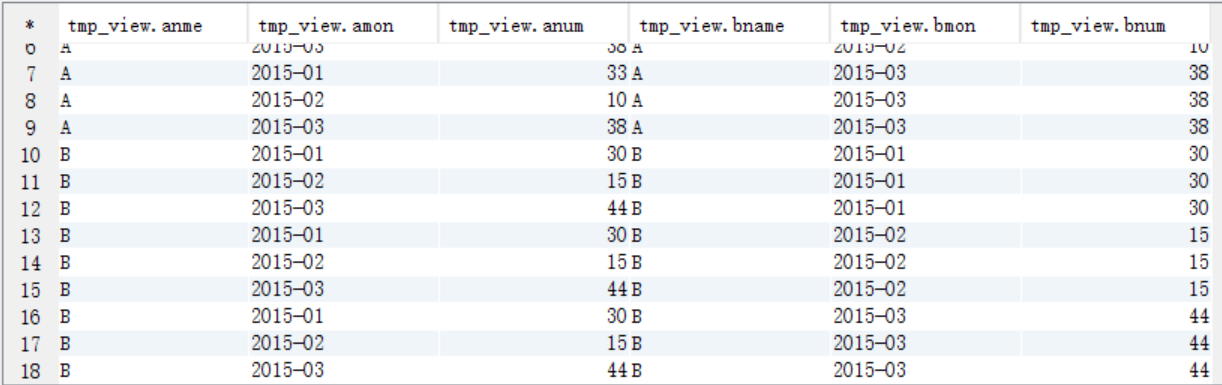
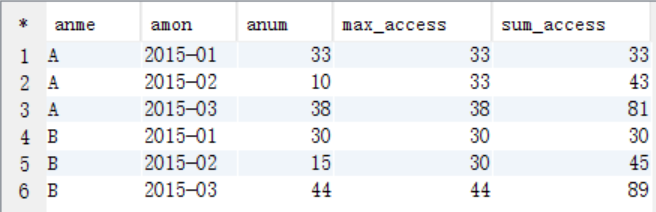
(3)进行比较统计
select anme,amon,anum,max(bnum) as max_access,sum(bnum) as sum_access
from tmp_view
where amon>=bmon
group by anme,amon,anum;
二、学生课程成绩
1、说明
use myhive;
CREATE TABLE `course` (
`id` int,
`sid` int ,
`course` string,
`score` int
) ;
// 插入数据
// 字段解释:id, 学号, 课程, 成绩
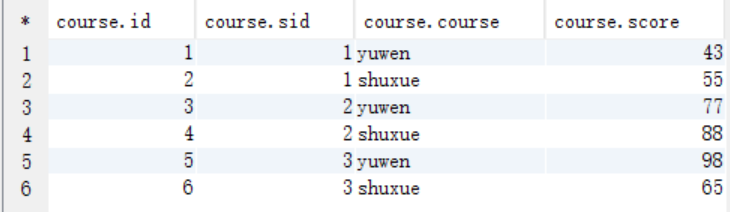
INSERT INTO `course` VALUES (1, 1, 'yuwen', 43);
INSERT INTO `course` VALUES (2, 1, 'shuxue', 55);
INSERT INTO `course` VALUES (3, 2, 'yuwen', 77);
INSERT INTO `course` VALUES (4, 2, 'shuxue', 88);
INSERT INTO `course` VALUES (5, 3, 'yuwen', 98);
INSERT INTO `course` VALUES (6, 3, 'shuxue', 65);
2、需求
求:所有数学课程成绩 大于 语文课程成绩的学生的学号
1、使用case...when...将不同的课程名称转换成不同的列
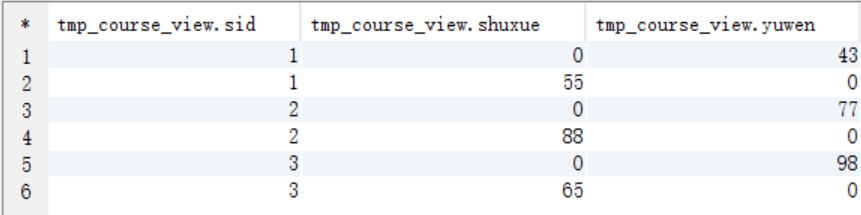
create view tmp_course_view as
select sid, case course when "shuxue" then score else 0 end as shuxue,
case course when "yuwen" then score else 0 end as yuwen from course; select * from tmp_course_view;
2、以sid分组合并取各成绩最大值
create view tmp_course_view1 as
select aa.sid, max(aa.shuxue) as shuxue, max(aa.yuwen) as yuwen from tmp_course_view aa group by sid; select * from tmp_course_view1;

3、比较结果
select * from tmp_course_view1 where shuxue > yuwen;

三、求每一年最大气温的那一天 + 温度
1、说明
数据格式
2010012325
具体数据
2014010114
2014010216
2014010317
2014010410
2014010506
2012010609
2012010732
2012010812
2012010919
2012011023
2001010116
2001010212
2001010310
2001010411
2001010529
2013010619
2013010722
2013010812
2013010929
2013011023
2008010105
2008010216
2008010337
2008010414
2008010516
2007010619
2007010712
2007010812
2007010999
2007011023
2010010114
2010010216
2010010317
2010010410
2010010506
2015010649
2015010722
2015010812
2015010999
2015011023
数据解释
2010012325表示在2010年01月23日的气温为25度
2、 需求
比如:2010012325表示在2010年01月23日的气温为25度。现在要求使用hive,计算每一年出现过的最大气温的日期+温度。
要计算出每一年的最大气温。我用
select substr(data,1,4),max(substr(data,9,2)) from table2 group by substr(data,1,4);
出来的是 年份 + 温度 这两列数据例如 2015 99
但是如果我是想select 的是:具体每一年最大气温的那一天 + 温度 。例如 20150109 99
请问该怎么执行hive语句。。
group by 只需要substr(data,1,4),
但是select substr(data,1,8),又不在group by 的范围内。
是我陷入了思维死角。一直想不出所以然。。求大神指点一下。
在select 如果所需要的。不在group by的条件里。这种情况如何去分析?
3、解析
(1)创建一个临时表tmp_weather,将数据切分
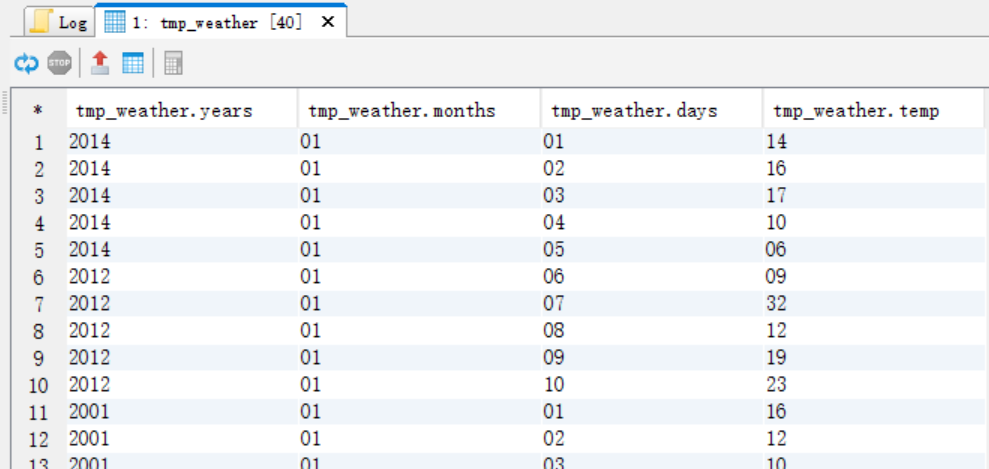
create table tmp_weather as
select substr(data,1,4) years,substr(data,5,2) months,substr(data,7,2) days,substr(data,9,2) temp from weather;
select * from tmp_weather;
(2)创建一个临时表tmp_year_weather
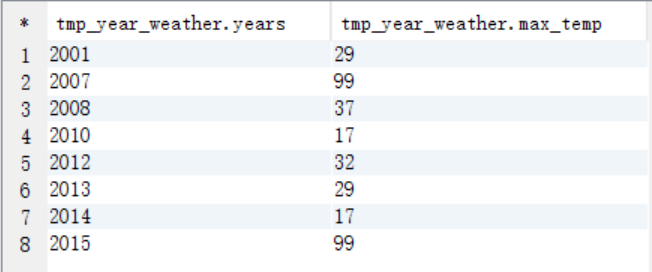
create table tmp_year_weather as
select substr(data,1,4) years,max(substr(data,9,2)) max_temp from weather group by substr(data,1,4);
select * from tmp_year_weather;
(3)将2个临时表进行连接查询
select * from tmp_year_weather a join tmp_weather b on a.years=b.years and a.max_temp=b.temp;
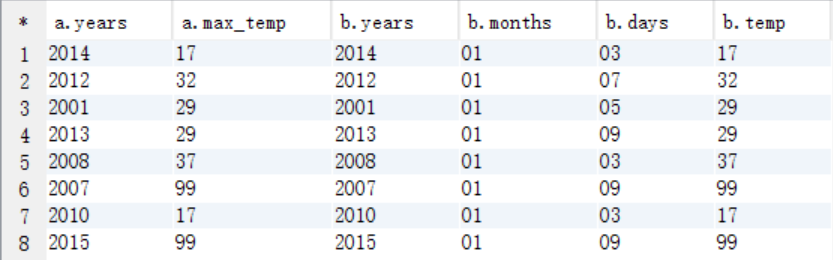
四、求学生选课情况
1、数据说明
(1)数据格式
id course
1,a
1,b
1,c
1,e
2,a
2,c
2,d
2,f
3,a
3,b
3,c
3,e
(2)字段含义
表示有id为1,2,3的学生选修了课程a,b,c,d,e,f中其中几门。
2、数据准备
(1)建表t_course
create table t_course(id int,course string)
row format delimited fields terminated by ",";

(2)导入数据
load data local inpath "/home/hadoop/course/course.txt" into table t_course;

3、需求
编写Hive的HQL语句来实现以下结果:表中的1表示选修,表中的0表示未选修
id a b c d e f
1 1 1 1 0 1 0
2 1 0 1 1 0 1
3 1 1 1 0 1 0
4、解析
第一步:
select collect_set(course) as courses from id_course;
第二步:
set hive.strict.checks.cartesian.product=false; create table id_courses as select t1.id as id,t1.course as id_courses,t2.course courses
from
( select id as id,collect_set(course) as course from id_course group by id ) t1
join
(select collect_set(course) as course from id_course) t2;
启用严格模式:hive.mapred.mode = strict // Deprecated
hive.strict.checks.large.query = true
该设置会禁用:1. 不指定分页的orderby
2. 对分区表不指定分区进行查询
3. 和数据量无关,只是一个查询模式hive.strict.checks.type.safety = true
严格类型安全,该属性不允许以下操作:1. bigint和string之间的比较
2. bigint和double之间的比较hive.strict.checks.cartesian.product = true
该属性不允许笛卡尔积操作
第三步:得出最终结果:
思路:
拿出course字段中的每一个元素在id_courses中进行判断,看是否存在。
select id,
case when array_contains(id_courses, courses[]) then 1 else 0 end as a,
case when array_contains(id_courses, courses[]) then 1 else 0 end as b,
case when array_contains(id_courses, courses[]) then 1 else 0 end as c,
case when array_contains(id_courses, courses[]) then 1 else 0 end as d,
case when array_contains(id_courses, courses[]) then 1 else 0 end as e,
case when array_contains(id_courses, courses[]) then 1 else 0 end as f
from id_courses;
五、求月销售额和总销售额
1、数据说明
(1)数据格式
a,01,150
a,01,200
b,01,1000
b,01,800
c,01,250
c,01,220
b,01,6000
a,02,2000
a,02,3000
b,02,1000
b,02,1500
c,02,350
c,02,280
a,03,350
a,03,250
(2)字段含义
店铺,月份,金额
2、数据准备
(1)创建数据库表t_store
use class;
create table t_store(
name string,
months int,
money int
)
row format delimited fields terminated by ",";
(2)导入数据
load data local inpath "/home/hadoop/store.txt" into table t_store;
3、需求
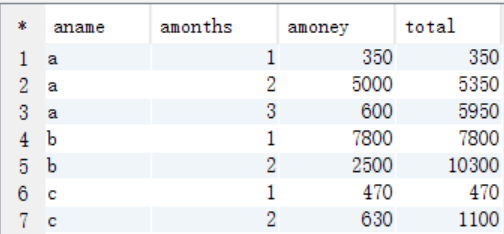
编写Hive的HQL语句求出每个店铺的当月销售额和累计到当月的总销售额
4、解析
(1)按照商店名称和月份进行分组统计
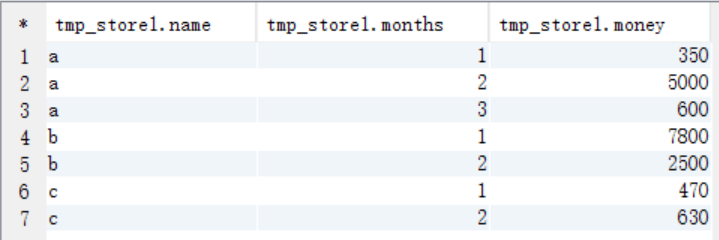
create table tmp_store1 as
select name,months,sum(money) as money from t_store group by name,months; select * from tmp_store1;
(2)对tmp_store1 表里面的数据进行自连接
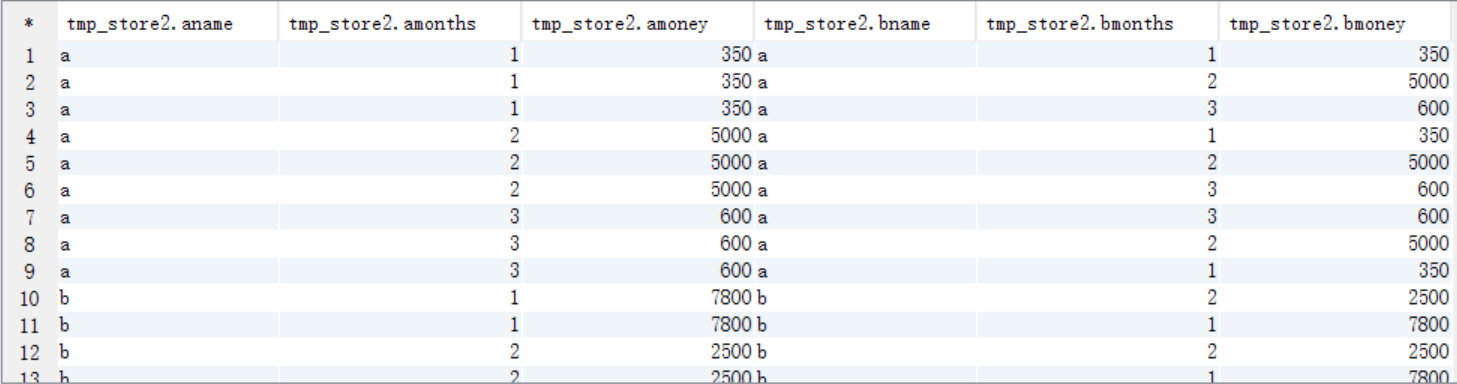
create table tmp_store2 as
select a.name aname,a.months amonths,a.money amoney,b.name bname,b.months bmonths,b.money bmoney from tmp_store1 a
join tmp_store1 b on a.name=b.name order by aname,amonths; select * from tmp_store2;
(3)比较统计
select aname,amonths,amoney,sum(bmoney) as total from tmp_store2 where amonths >= bmonths group by aname,amonths,amoney;
Hive学习之路 (十一)Hive的5个面试题的更多相关文章
- [转帖]Hive学习之路 (一)Hive初识
Hive学习之路 (一)Hive初识 https://www.cnblogs.com/qingyunzong/p/8707885.html 讨论QQ:1586558083 目录 Hive 简介 什么是 ...
- Hive学习之路 (二十一)Hive 优化策略
一.Hadoop 框架计算特性 1.数据量大不是问题,数据倾斜是个问题 2.jobs 数比较多的作业运行效率相对比较低,比如即使有几百行的表,如果多次关联多次 汇总,产生十几个 jobs,耗时很长.原 ...
- hive学习笔记之十一:UDTF
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Hive学习之路 (一)Hive初识
Hive 简介 什么是Hive 1.Hive 由 Facebook 实现并开源 2.是基于 Hadoop 的一个数据仓库工具 3.可以将结构化的数据映射为一张数据库表 4.并提供 HQL(Hive S ...
- Hive学习之路 (二)Hive安装
Hive的下载 下载地址http://mirrors.hust.edu.cn/apache/ 选择合适的Hive版本进行下载,进到stable-2文件夹可以看到稳定的2.x的版本是2.3.3 Hive ...
- Hive学习之路 (二十)Hive 执行过程实例分析
一.Hive 执行过程概述 1.概述 (1) Hive 将 HQL 转换成一组操作符(Operator),比如 GroupByOperator, JoinOperator 等 (2)操作符 Opera ...
- Hive学习之路 (十八)Hive的Shell操作
一.Hive的命令行 1.Hive支持的一些命令 Command Description quit Use quit or exit to leave the interactive shell. s ...
- Hive学习之路 (四)Hive的连接3种连接方式
一.CLI连接 进入到 bin 目录下,直接输入命令: [hadoop@hadoop3 ~]$ hive SLF4J: Class path contains multiple SLF4J bindi ...
- Hive 学习之路(八)—— Hive 数据查询详解
一.数据准备 为了演示查询操作,这里需要预先创建三张表,并加载测试数据. 数据文件emp.txt和dept.txt可以从本仓库的resources目录下载. 1.1 员工表 -- 建表语句 CREAT ...
随机推荐
- 三:vim常用快捷键
窗口移动操作: j或者Ctrl+e(就是Ctrl+e):向下细微滚动窗口. k或者Ctrl+y:向上细微滚动窗口. h:向左细微滚动窗口. l:向右细微滚动窗口. gg:跳转到页面的顶部. G(就是s ...
- Linux安装jdk,编写helloworld程序
今天学习了Linux安装jdk,做个笔记记录一下. 第一步,确定Linux是32位的还是64位的,然后到oracle官网上下载对应版本的jdk,一般下载.tar.gz文件.查看Linux的版本的命令是 ...
- Android开发之旅2:HelloWorld项目的目录结构
引言 前面Android开发之旅:环境搭建及HelloWorld,我们介绍了如何搭建Android开发环境及简单地建立一个HelloWorld项目,本篇将通过HelloWorld项目来介绍Androi ...
- Maven 使用 Nexus 内部库 代理
反正任由总理怎么强调,在中国的当前的网络环境下,中央库的访问速度总是令人心碎.建一个nexus内部库可以建立缓存,只要有人通过它下载了相关的maven依赖,那么别人需要时可以马上从本地网络的服务器上返 ...
- 第二十三天- 模块 re
# 1. 正则表达式 # 元字符# . 除了换行符外任意字符# \w 数字 字母 下划线# \s 空白符# \b 单词的末尾# \d 数字# \W 除了数字 字母 下划线# \D 除了数字# \S 除 ...
- mysql + excel 校正线上数据
积分问题处理 1. 所有应补汇总 select driver_id, SUM(integral) from detail_score group by driver_id; 2. 原汇总积分 sele ...
- 【代码笔记】iOS-archive保存图片到本地
一,工程图: 二,代码: RootViewController.h #import <UIKit/UIKit.h> @interface RootViewController : UIVi ...
- maven 安装下载与配置 代理设置 《解决下载慢问题》
maven:下载地址http://mirror.bit.edu.cn/apache/maven/maven-3/ 解压之后配置环境 %maven_home% d:\*****path 中添加 %ma ...
- HTTP请求封装:Ajax与RESTful API
一.HTTP请求 HTTP即超文本传输协议,用以进行HTML 文件. 图片文件. 查询结果等的网络传输. 一个完整的HTTP请求包括:请求行.请求头.空行和请求数据(请求数据可以为空) HTTP1.1 ...
- Surface电池阈值
Surface电池阈值 笔记本电脑一般都会提供一个电池保养的软件,其主要最用是让电池在插电情况下保持在50%-80%之间,以延长电池寿命,减少电池损耗.而微软自家的Surface却一直没有这个设置. ...