Netty源码分析第6章(解码器)---->第3节: 行解码器
Netty源码分析第六章: 解码器
第三节: 行解码器
这一小节了解下行解码器LineBasedFrameDecoder, 行解码器的功能是一个字节流, 以\r\n或者直接以\n结尾进行解码, 也就是以换行符为分隔进行解析
同样, 这个解码器也继承了ByteToMessageDecoder
首先看其参数:
//数据包的最大长度, 超过该长度会进行丢弃模式
private final int maxLength;
//超出最大长度是否要抛出异常
private final boolean failFast;
//最终解析的数据包是否带有换行符
private final boolean stripDelimiter;
//为true说明当前解码过程为丢弃模式
private boolean discarding;
//丢弃了多少字节
private int discardedBytes;
其中的丢弃模式, 我们会在源码中看到其中的含义
我们看其decode方法:
protected final void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
Object decoded = decode(ctx, in);
if (decoded != null) {
out.add(decoded);
}
}
这里的decode方法和我们上一小节分析的decode方法一样, 调用重载的decode方法, 并将解码后的内容放到out集合中
我们跟到重载的decode方法中:
protected Object decode(ChannelHandlerContext ctx, ByteBuf buffer) throws Exception {
//找这行的结尾
final int eol = findEndOfLine(buffer);
if (!discarding) {
if (eol >= 0) {
final ByteBuf frame;
//计算从换行符到可读字节之间的长度
final int length = eol - buffer.readerIndex();
//拿到分隔符长度, 如果是\r\n结尾, 分隔符长度为2
final int delimLength = buffer.getByte(eol) == '\r'? 2 : 1;
//如果长度大于最大长度
if (length > maxLength) {
//指向换行符之后的可读字节(这段数据完全丢弃)
buffer.readerIndex(eol + delimLength);
//传播异常事件
fail(ctx, length);
return null;
}
//如果这次解析的数据是有效的
//分隔符是否算在完整数据包里
//true为丢弃分隔符
if (stripDelimiter) {
//截取有效长度
frame = buffer.readRetainedSlice(length);
//跳过分隔符的字节
buffer.skipBytes(delimLength);
} else {
//包含分隔符
frame = buffer.readRetainedSlice(length + delimLength);
}
return frame;
} else {
//如果没找到分隔符(非丢弃模式)
//可读字节长度
final int length = buffer.readableBytes();
//如果朝超过能解析的最大长度
if (length > maxLength) {
//将当前长度标记为可丢弃的
discardedBytes = length;
//直接将读指针移动到写指针
buffer.readerIndex(buffer.writerIndex());
//标记为丢弃模式
discarding = true;
//超过最大长度抛出异常
if (failFast) {
fail(ctx, "over " + discardedBytes);
}
}
//没有超过, 则直接返回
return null;
}
} else {
//丢弃模式
if (eol >= 0) {
//找到分隔符
//当前丢弃的字节(前面已经丢弃的+现在丢弃的位置-写指针)
final int length = discardedBytes + eol - buffer.readerIndex();
//当前换行符长度为多少
final int delimLength = buffer.getByte(eol) == '\r'? 2 : 1;
//读指针直接移到换行符+换行符的长度
buffer.readerIndex(eol + delimLength);
//当前丢弃的字节为0
discardedBytes = 0;
//设置为未丢弃模式
discarding = false;
//丢弃完字节之后触发异常
if (!failFast) {
fail(ctx, length);
}
} else {
//累计已丢弃的字节个数+当前可读的长度
discardedBytes += buffer.readableBytes();
//移动
buffer.readerIndex(buffer.writerIndex());
}
return null;
}
}
final int eol = findEndOfLine(buffer) 这里是找当前行的结尾的索引值, 也就是\r\n或者是\n:
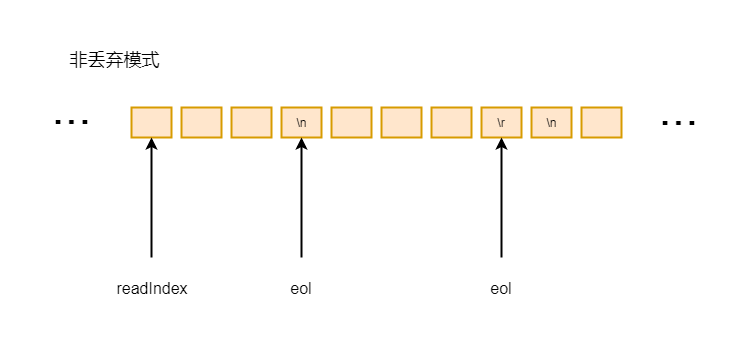
6-3-1
图中不难看出, 如果是以\n结尾的, 返回的索引值是\n的索引值, 如果是\r\n结尾的, 返回的索引值是\r的索引值
我们看findEndOfLine(buffer)方法:
private static int findEndOfLine(final ByteBuf buffer) {
//找到/n这个字节
int i = buffer.forEachByte(ByteProcessor.FIND_LF);
//如果找到了, 并且前面的字符是-r, 则指向/r字节
if (i > 0 && buffer.getByte(i - 1) == '\r') {
i--;
}
return i;
}
这里通过一个forEachByte方法找\n这个字节, 如果找到了, 并且前面是\r, 则返回\r的索引, 否则返回\n的索引
回到重载的decode方法中:
if (!discarding) 判断是否为非丢弃模式, 默认是就是非丢弃模式, 所以进入if中
if (eol >= 0) 如果找到了换行符, 我们看非丢弃模式下找到换行符的相关逻辑:
final ByteBuf frame;
final int length = eol - buffer.readerIndex();
final int delimLength = buffer.getByte(eol) == '\r'? 2 : 1;
if (length > maxLength) {
buffer.readerIndex(eol + delimLength);
fail(ctx, length);
return null;
}
if (stripDelimiter) {
frame = buffer.readRetainedSlice(length);
buffer.skipBytes(delimLength);
} else {
frame = buffer.readRetainedSlice(length + delimLength);
} return frame;
首先获得换行符到可读字节之间的长度, 然后拿到换行符的长度, 如果是\n结尾, 那么长度为1, 如果是\r结尾, 长度为2
if (length > maxLength) 带表如果长度超过最大长度, 则直接通过 readerIndex(eol + delimLength) 这种方式, 将读指针指向换行符之后的字节, 说明换行符之前的字节需要完全丢弃
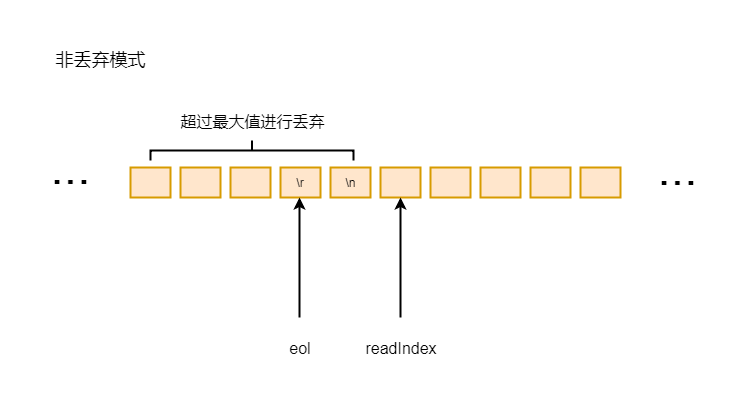
6-3-2
丢弃之后通过fail方法传播异常, 并返回null
继续往下看, 走到下一步, 说明解析出来的数据长度没有超过最大长度, 说明是有效数据包
if (stripDelimiter) 表示是否要将分隔符放在完整数据包里面, 如果是true, 则说明要丢弃分隔符, 然后截取有效长度, 并跳过分隔符长度
将包含分隔符进行截取
以上就是非丢弃模式下找到换行符的相关逻辑
我们再看非丢弃模式下没有找到换行符的相关逻辑, 也就是非丢弃模式下, if (eol >= 0) 中的else块:
final int length = buffer.readableBytes();
if (length > maxLength) {
discardedBytes = length;
buffer.readerIndex(buffer.writerIndex());
discarding = true;
if (failFast) {
fail(ctx, "over " + discardedBytes);
}
}
return null;
首先通过 final int length = buffer.readableBytes() 获取所有的可读字节数
然后判断可读字节数是否超过了最大值, 如果超过最大值, 则属性discardedBytes标记为这个长度, 代表这段内容要进行丢弃
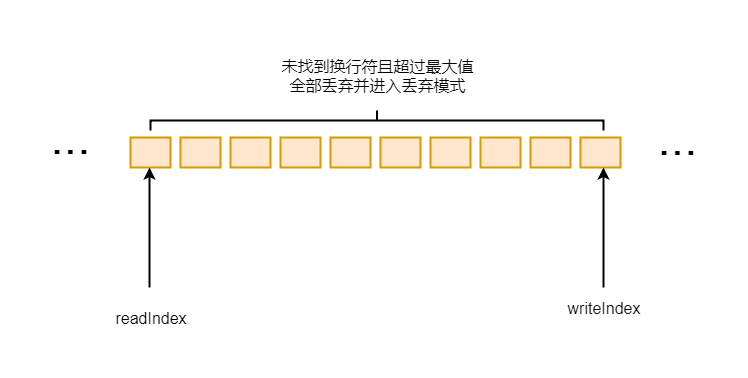
6-3-3
buffer.readerIndex(buffer.writerIndex()) 这里直接将读指针移动到写指针, 并且将discarding设置为true, 就是丢弃模式
如果可读字节没有超过最大长度, 则返回null, 表示什么都没解析出来, 等着下次解析
我们再看丢弃模式的处理逻辑, 也就是 if (!discarding) 中的else块:
首先这里也分两种情况, 根据 if (eol >= 0) 判断是否找到了分隔符, 我们首先看找到分隔符的解码逻辑:
final int length = discardedBytes + eol - buffer.readerIndex();
final int delimLength = buffer.getByte(eol) == '\r'? 2 : 1;
buffer.readerIndex(eol + delimLength);
discardedBytes = 0;
discarding = false;
if (!failFast) {
fail(ctx, length);
}
如果找到换行符, 则需要将换行符之前的数据全部丢弃掉
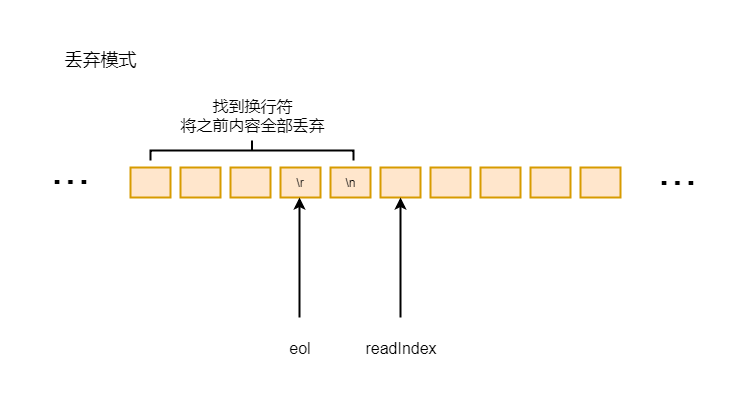
6-3-4
final int length = discardedBytes + eol - buffer.readerIndex() 这里获得丢弃的字节总数, 也就是之前丢弃的字节数+现在需要丢弃的字节数
然后计算换行符的长度, 如果是\n则是1, \r\n就是2
buffer.readerIndex(eol + delimLength) 这里将读指针移动到换行符之后的位置
然后将discarding设置为false, 表示当前是非丢弃状态
我们再看丢弃模式未找到换行符的情况, 也就是丢弃模式下, if (eol >= 0) 中的else块:
discardedBytes += buffer.readableBytes();
buffer.readerIndex(buffer.writerIndex());
这里做的事情非常简单, 就是累计丢弃的字节数, 并将读指针移动到写指针, 也就是将数据全部丢弃
最后在丢弃模式下, decode方法返回null, 代表本次没有解析出任何数据
以上就是行解码器的相关逻辑
Netty源码分析第6章(解码器)---->第3节: 行解码器的更多相关文章
- Netty源码分析第4章(pipeline)---->第4节: 传播inbound事件
Netty源码分析第四章: pipeline 第四节: 传播inbound事件 有关于inbound事件, 在概述中做过简单的介绍, 就是以自己为基准, 流向自己的事件, 比如最常见的channelR ...
- Netty源码分析第4章(pipeline)---->第5节: 传播outbound事件
Netty源码分析第五章: pipeline 第五节: 传播outBound事件 了解了inbound事件的传播过程, 对于学习outbound事件传输的流程, 也不会太困难 在我们业务代码中, 有可 ...
- Netty源码分析第4章(pipeline)---->第6节: 传播异常事件
Netty源码分析第四章: pipeline 第6节: 传播异常事件 讲完了inbound事件和outbound事件的传输流程, 这一小节剖析异常事件的传输流程 首先我们看一个最最简单的异常处理的场景 ...
- Netty源码分析第4章(pipeline)---->第7节: 前章节内容回顾
Netty源码分析第四章: pipeline 第七节: 前章节内容回顾 我们在第一章和第三章中, 遗留了很多有关事件传输的相关逻辑, 这里带大家一一回顾 首先看两个问题: 1.在客户端接入的时候, N ...
- Netty源码分析第5章(ByteBuf)---->第4节: PooledByteBufAllocator简述
Netty源码分析第五章: ByteBuf 第四节: PooledByteBufAllocator简述 上一小节简单介绍了ByteBufAllocator以及其子类UnPooledByteBufAll ...
- Netty源码分析第5章(ByteBuf)---->第5节: directArena分配缓冲区概述
Netty源码分析第五章: ByteBuf 第五节: directArena分配缓冲区概述 上一小节简单分析了PooledByteBufAllocator中, 线程局部缓存和arean的相关逻辑, 这 ...
- Netty源码分析第5章(ByteBuf)---->第6节: 命中缓存的分配
Netty源码分析第6章: ByteBuf 第六节: 命中缓存的分配 上一小节简单分析了directArena内存分配大概流程, 知道其先命中缓存, 如果命中不到, 则区分配一款连续内存, 这一小节带 ...
- Netty源码分析第5章(ByteBuf)---->第7节: page级别的内存分配
Netty源码分析第五章: ByteBuf 第六节: page级别的内存分配 前面小节我们剖析过命中缓存的内存分配逻辑, 前提是如果缓存中有数据, 那么缓存中没有数据, netty是如何开辟一块内存进 ...
- Netty源码分析第5章(ByteBuf)---->第10节: SocketChannel读取数据过程
Netty源码分析第五章: ByteBuf 第十节: SocketChannel读取数据过程 我们第三章分析过客户端接入的流程, 这一小节带大家剖析客户端发送数据, Server读取数据的流程: 首先 ...
- Netty源码分析第4章(pipeline)---->第1节: pipeline的创建
Netty源码分析第四章: pipeline 概述: pipeline, 顾名思义, 就是管道的意思, 在netty中, 事件在pipeline中传输, 用户可以中断事件, 添加自己的事件处理逻辑, ...
随机推荐
- Java进阶 -- 文章汇总
文章汇总 Java集合源码 -- Collection框架概述 Java集合源码 -- Map映射和Set集合 Java集合源码 -- List列表 String和StringBuffer 内部类 j ...
- Spring源码分析(二十一)加载BeanFactory
摘要: 本文结合<Spring源码深度解析>来分析Spring 5.0.6版本的源代码.若有描述错误之处,欢迎指正. 目录 一.定制化BeanFactory 二.加载BeanDefinit ...
- STM32中用 stop 模式 配合低功耗模式下的自动唤醒(AWU) 能否实现FreeRTOS tickless 模式
已经实现 ,2018年11月17日11:56:42,具体 如下: 第一步 : 修改 void vPortSetupTimerInterrupt( void ) 函数 ,修改原来的 systick 定 ...
- bat取时间间隔
@echo off echo 现在时间是%time:~,%点%time:~,%分%time:~,%秒 ,%%time:~,%%time:~,% pause echo 现在时间是%time:~,%点%t ...
- 【jq】插件—缓存jquery.cookie.js
jquery.cookie.js插件 轻量级cookie管理 1°下载地址:http://plugins.jquery.com/cookie/ 2°引入方式:(基于jquery) <scri ...
- 填移动端坑系列一——如何让h5页面完美整屏显示
原创哟,转载请附上本文连接(http://www.cnblogs.com/AliceX-J/p/6707908.html),作者 印前 后续更简单 前言: 最近让做一个h5的活动专题,便让我浩浩荡荡进 ...
- 求助:将以下ES5格式代码转换为ES6格式!!!
function Slider(id){ //属性 // 1. 通过id获取元素对象(大盒子) this.bigBox = document.getElementById(i ...
- 洛谷P1028动规算法
首先我们可以写一个递归 #include<bits/stdc++.h> using namespace std; long long n; int main(){ long long f[ ...
- 洛谷P4245 【模板】MTT(任意模数NTT)
题目背景 模板题,无背景 题目描述 给定 22 个多项式 F(x), G(x)F(x),G(x) ,请求出 F(x) * G(x)F(x)∗G(x) . 系数对 pp 取模,且不保证 pp 可以分解成 ...
- 一、用Delphi10.3 创建一条JSON数据
一.用Delphi10.3构造一个JSON数据,非常之容易,代码如下: uses System.JSON; procedure TForm1.Button1Click(Sender: TObject) ...