利用yacc和lex制作一个小的计算器
买了本《自制编程语言》,这本书有点难,目前只是看前两章,估计后面的章节,最近一段时间是不会看了,真的是好难啊!!
由于本人是身处弱校,学校的课程没有编译原理这一门课,所以就想看这两章,了解一下编译原理,增加一下自己的软实力。免得被别人鄙视。
一、安装yacc和lex
我是在Windows下使用这两个软件的。所以使用bison代替yacc,用flex代替lex。两者的下载地址是http://sourceforge.net/projects/winflexbison/ 我的gcc环境是使用以前用过的mingw。我们吧解压后的flex和bison放到mingw的bin目录下。这一步就完成了。
二、编译代码
先编译代码,看一下结果,然后在分析。在这本书中提供的一个网址有书中代码下载。下载地址 http://avnpc.com/pages/devlang 下载后找到mycalc这个文件夹。然后执行下面进行编译
bison --yacc -dv mycalc.y -o y.tab.c
flex mycalc.l
gcc -o mycalc y.tab.c lex.yy.c
三、yacc/lex是什么
一般编程语言的语法处理,都会有以下的过程。
1.词法分析
将源代码分割成若干个记号的处理。
2.语法分析
即从记号构建分析树的处理。分析树也叫作语法树或抽象语法树。
3.语义分析
经过语法分析生成的分析树,并不包含数据类型等语义信息。因此在语义分析阶段,会检查程序中是否含有语法正确但是存在逻辑问题的错误。
4.生成代码
如果是C语言等生成机器码的编译器或Java这样生成字节码的编译器,在分析树构建完毕后会进入代码生成阶段。
例如有下面源代码
if(a==)
{
printf("hoge\n");
}
else
{
printf("piyo\n");
}
执行词法分析后,将被分割为如下的记号(每一块就是一个记号)
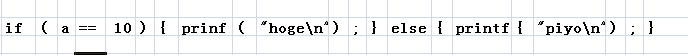
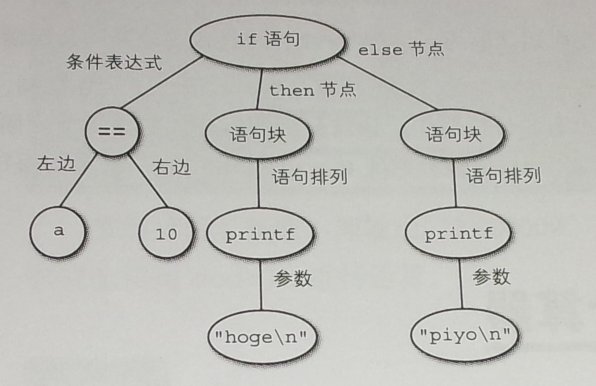
对此进行语法分析后构建的分析树,如下图所示
执行词法分析的程序称为词法分析器。lex的工作就是根据词法规则自动生成词法分析器。
执行语法分析的程序则称为解析器。yacc就是根据语法规则自动生成解析器的程序。
四、分析计算器代码
1.mycalc.l源代码
%{
#include <stdio.h>
#include "y.tab.h"
int
yywrap(void)
{
return ;
}
%}
%%
"+" return ADD;
"-" return SUB;
"*" return MUL;
"/" return DIV;
"\n" return CR;
([-][-]*)||([-]+\.[-]*) {
double temp;
sscanf(yytext, "%lf", &temp);
yylval.double_value = temp;
return DOUBLE_LITERAL;
}
[ \t] ;
. {
fprintf(stderr, "lexical error.\n");
exit();
}
%%
第一行到第十行是一个定义区块,lex中用 %{...}%定义,这里面代码将原样输出。
第11行到第28行是一个规则区块。语法大概就是前面一部分是使用正则表达式后面一部分是返回匹配到后这一部分是类型标记。大括号里面是动作。例如 ([1-9][0-9]*)|0|([0-9]+\.[0-9]*)是匹配小数,然后对这个小数进行sscanf处理后返回一个DOUBLE_LITERAL类型。
2.mycalc.y 源代码
%{
#include <stdio.h>
#include <stdlib.h>
#define YYDEBUG 1
%}
%union {
int int_value;
double double_value;
}
%token <double_value> DOUBLE_LITERAL
%token ADD SUB MUL DIV CR
%type <double_value> expression term primary_expression
%%
line_list
: line
| line_list line
;
line
: expression CR
{
printf(">>%lf\n", $);
}
expression
: term
| expression ADD term
{
$$ = $ + $;
}
| expression SUB term
{
$$ = $ - $;
}
;
term
: primary_expression
| term MUL primary_expression
{
$$ = $ * $;
}
| term DIV primary_expression
{
$$ = $ / $;
}
;
primary_expression
: DOUBLE_LITERAL
;
%%
int
yyerror(char const *str)
{
extern char *yytext;
fprintf(stderr, "parser error near %s\n", yytext);
return ;
}
int main(void)
{
extern int yyparse(void);
extern FILE *yyin;
yyin = stdin;
if (yyparse()) {
fprintf(stderr, "Error ! Error ! Error !\n");
exit();
}
}
上面第13行到第48行,语法规则简化为下面格式
A
: B C
| D
;
即A的定义是B与C的组合,或者为D。
上面的过程可以用一个游戏的方式解释。就是一个数字是定位为DOUBLE_LITERAL类型,通过第45行的规则可以将DOUBLE_LITERAL升级成primary_expression类型,然后通过34行规则可以升级为term类型。又term类型可以升级为expression类型。所以 “2+4” 符合的规则是数字2升级到expression类型,而当数字4升级到term类型时,此时的状态是 expression ADD term 通过第25行的规则可以得到两者的结合,得到一个term类型。(PS:这个时候让我想起了一个动漫,就是数码宝贝,类型可以进行进化,进化,超进化,究极进化,还可以合体进化。<笑>)上面一个专业的叫法是叫做归约。
由于归约情况比较复杂和不好讲,我就截书本上的原图进行讲解吧。



至于左结合或右结合是由写的词法分析器来决定的。例如给出的代码,为什么是右结合呢,是因为用到了递归,所以会首先和低级的类型进行结合,这就是为什么MUL,DIV是term类型,ADD,SUB是expression类型,就是处理优先级的问题。
对于C或Java有这样的一个问题
a+++++b;
我们可以分析为a++ + ++b 为什么编译器还会报错呢?是因为我们如果定义优先级的话,++优先级大于+。那么在代码中就是实现为尽量使++在一起,而不是+优先,如果是+优先的话,那么每次都不会结合为++。所以代码在词法分析器阶段代码就会被分割成a ++ ++ + b ;这样几段。从而错误的。由于词法分析器和解析器是各自独立的。又因为词法分析器先于语法分析器运行。
上面的过程就是这样进行语法分析的。上面的过程虽然简单,但是如果用代码实现就有点困难了。我们使用yacc生成的执行文件就是对上面模拟的执行代码,使用yacc自动生成的。如果我们要自制编程语言的话,那么这个过程就要自己写了。因为有很多细节问题。不过不多说了,我们先了解这个就行。生成后的代码文件是y.tab.c y.tab.h 。生成的代码有几十K呢,我们要了解这个过程还是比较难的。
五、用代码实现词法分析器
该代码在calc/llparser目录下
lexicalanalyzer.c
#include <stdio.h>
#include <stdlib.h>
#include <ctype.h>
#include "token.h" static char *st_line;
static int st_line_pos; typedef enum {
INITIAL_STATUS,
IN_INT_PART_STATUS,
DOT_STATUS,
IN_FRAC_PART_STATUS
} LexerStatus; void
get_token(Token *token)
{
int out_pos = ;
LexerStatus status = INITIAL_STATUS;
char current_char; token->kind = BAD_TOKEN;
while (st_line[st_line_pos] != '\0') {
current_char = st_line[st_line_pos];
if ((status == IN_INT_PART_STATUS || status == IN_FRAC_PART_STATUS)
&& !isdigit(current_char) && current_char != '.') {
token->kind = NUMBER_TOKEN;
sscanf(token->str, "%lf", &token->value);
return;
}
if (isspace(current_char)) {
if (current_char == '\n') {
token->kind = END_OF_LINE_TOKEN;
return;
}
st_line_pos++;
continue;
} if (out_pos >= MAX_TOKEN_SIZE-) {
fprintf(stderr, "token too long.\n");
exit();
}
token->str[out_pos] = st_line[st_line_pos];
st_line_pos++;
out_pos++;
token->str[out_pos] = '\0'; if (current_char == '+') {
token->kind = ADD_OPERATOR_TOKEN;
return;
} else if (current_char == '-') {
token->kind = SUB_OPERATOR_TOKEN;
return;
} else if (current_char == '*') {
token->kind = MUL_OPERATOR_TOKEN;
return;
} else if (current_char == '/') {
token->kind = DIV_OPERATOR_TOKEN;
return;
} else if (isdigit(current_char)) {
if (status == INITIAL_STATUS) {
status = IN_INT_PART_STATUS;
} else if (status == DOT_STATUS) {
status = IN_FRAC_PART_STATUS;
}
} else if (current_char == '.') {
if (status == IN_INT_PART_STATUS) {
status = DOT_STATUS;
} else {
fprintf(stderr, "syntax error.\n");
exit();
}
} else {
fprintf(stderr, "bad character(%c)\n", current_char);
exit();
}
}
} void
set_line(char *line)
{
st_line = line;
st_line_pos = ;
} #if 1
void
parse_line(char *buf)
{
Token token; set_line(buf); for (;;) {
get_token(&token);
if (token.kind == END_OF_LINE_TOKEN) {
break;
} else {
printf("kind..%d, str..%s\n", token.kind, token.str);
}
}
} int
main(int argc, char **argv)
{
char buf[]; while (fgets(buf, , stdin) != NULL) {
parse_line(buf);
} return ;
}
#endif
token.h
#ifndef TOKEN_H_INCLUDED
#define TOKEN_H_INCLUDED typedef enum {
BAD_TOKEN,
NUMBER_TOKEN,
ADD_OPERATOR_TOKEN,
SUB_OPERATOR_TOKEN,
MUL_OPERATOR_TOKEN,
DIV_OPERATOR_TOKEN,
END_OF_LINE_TOKEN
} TokenKind; #define MAX_TOKEN_SIZE (100) typedef struct {
TokenKind kind;
double value;
char str[MAX_TOKEN_SIZE];
} Token; void set_line(char *line);
void get_token(Token *token); #endif /* TOKEN_H_INCLUDED */
上面使用的方法是DFA(确定有限状态自动机)
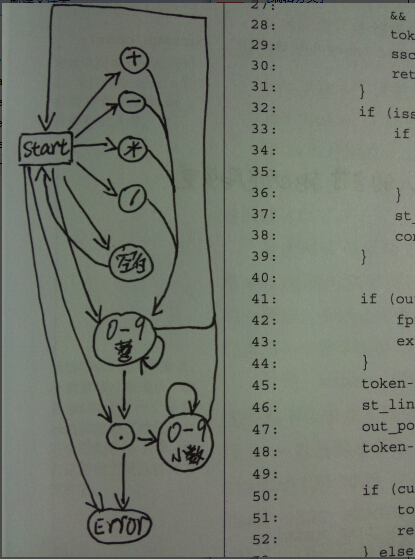
上面的图有些指向error的箭头没有标出,不过这个图就大概描述了这个过程。可以自己baidu一些状态机的知识。
有了这两章的基础就可以自己写个分析器了(作用:以后写应用程序时,要给程序一个配置文件时,可以自己写个脚本进行解析,方便用户书写配置文件。不过现在都使用xml语法了,都还有解析的库呢。都不知道学了以后还有没有机会用到实际中呢)。不过循环和判断就还不能实现。书中后面有讲到,不过看到后面一些内容就有一些力不从心了。感觉难难哒!
DFA:http://www.cnblogs.com/zhanghaiba/p/3569928.html
本文地址:http://www.cnblogs.com/wunaozai/p/3869101.html
利用yacc和lex制作一个小的计算器的更多相关文章
- three.js 利用uv和ThreeBSP制作一个快递柜
最近有three网友,问我要不要学习blender,其实我感觉学习一下也无妨,不过花大量时间精通,尚可不必,术业有专攻给别人留一条路吧,哈哈.那我我们就是用ThreeBSP和uv贴图的知识来制作一个定 ...
- iOS学习——制作一个小型加法计算器
一.项目要求:制作一个加法计算器.在第1个和第2个文本框中输入两个整数,然后点击“计算”按钮,可将计算结果显示在第3个文本框中. 二.开发步骤: 1.搭建UI界面 2.监听按钮的点击事件 3.获取文本 ...
- iOS:制作一个简易的计算器
初步接触视图,制作了一个简易的计算器,基本上简单的计算是没有问题的,不是很完美,可能还有一些bug,再接再厉. // // ViewController.m // 计算器 // // Created ...
- 《自制编程语言》笔记:使用yacc与lex制作简单计算器
1.代码 1.1)test.l 1.2)test.y 1.3)Makefile (因为是在linux环境下,所以使用了Makefile) 2.编译与运行 2.1)编译 2.2)运行 1.代码(也可以在 ...
- 吴裕雄 Bootstrap 前端框架开发——Bootstrap 按钮:制作一个小按钮
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- Unity制作一个小星球
制作过程 在场景中新建一个球体(Planet)和一个胶囊(Player),适当缩放并添加材质,这里胶囊会被视为玩家 然后将摄像机设为胶囊(Player)的子物体 自行调整合适的摄像机视角 新建脚本Gr ...
- 一起学HTML基础-利用CSS和JavaScript制作一个切换图片的网页
由于个人原因,不详细写步骤 思路: 一.布局 二.制作图片区和按钮区的div及颜色.边框.背景属性等 三.用PS将四张图片剪切到同一个尺寸,重叠放置在图片切换区,透明度设置为0 四.点击对应按钮时,将 ...
- 使用qt制作一个简单的计算器
前言:今天使用qt制作了一个很简单的计算器,觉得挺有意思的,所以在这里跟大家分享一下. 这里先跟大家说说使用到的函数: 一.槽连接函数 connect(信号发送者,发送的信号,信号接收者,信号接收者的 ...
- js利用点击事件做一个简单的计算器
先放一个样式图: 源代码如下: <!DOCTYPE html> <html> <head> <meta charset="UTF-8"&g ...
随机推荐
- 栈的应用实例——中缀表达式转换为后缀表达式
声明:本程序读入一个中缀表达式,将该中缀表达式转换为后缀表达式并输出后缀表达式. 注意:支持+.-.*./.(),并且输入时每输入完一个数字或符号都要加一个空格,特别注意的是在整个表达式输入完成时也要 ...
- bzoj3675【APIO2014】序列切割
3675: [Apio2014]序列切割 Time Limit: 40 Sec Memory Limit: 128 MB Submit: 1468 Solved: 607 [Submit][Sta ...
- 算法笔记_182:历届试题 核桃的数量(Java)
目录 1 问题描述 2 解决方案 1 问题描述 问题描述 小张是软件项目经理,他带领3个开发组.工期紧,今天都在加班呢.为鼓舞士气,小张打算给每个组发一袋核桃(据传言能补脑).他的要求是: 1. ...
- spring mvc上传、下载的实现
下载 //下载 @RequestMapping(value="/download") public ResponseEntity<byte[]> download() ...
- IDEA 开发环境中 调试Spark SQL及遇到问题解决办法
1.问题 java.lang.OutOfMemoryError: PermGen space java.lang.OutOfMemoryError: Java heap space // :: WAR ...
- 【zend studio】如何添加已存在的git项目
1.在zend里面新增项目crm2 2.win下进入crm2目录,右键选择 Git Bash Here,进项git clone操作 3.进入下载下来的GIT项目目录,选择复制,然后返回上一目录crm2 ...
- PHP-Ajax跨域解决方案
1.先了解下Ajax跨域问题: <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "ht ...
- Eclipse中导入项目后js报错解决方法(转未解决问题)
本文转自:http://blog.csdn.net/chenchunlin526/article/details/54666882 Eclipse中导入项目后js报错的原因与解决方法 在我们将项目导入 ...
- HDUOJ------敌兵布阵
敌兵布阵 Time Limit : 2000/1000ms (Java/Other) Memory Limit : 65536/32768K (Java/Other) Total Submissi ...
- WCF中可以使用SVCUtil.exe生成客户端代理类和配置文件
1.找到如下地址“C:\Windows\System32\cmd.exe” 命令行工具,右键以管理员身份运行(视系统是否为win7 而定) 2.输入如下命令: C:\>cd C ...