sqoop 数据导入hive
一. sqoop: mysql->hive
sqoop import -m 1 --hive-import --connect "jdbc:mysql://127.0.0.1:3306/TEST?zeroDateTimeBehavior=CONVERT_TO_NULL&useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai" --username sa --password-file /user/root/_sqoop/pwd127.txt --table user --hive-database TEST --hive-table user
这里jdbc url后面跟了一些连接参数,看情况可有可无;
二.sqoop: oracle->hive
# 使用oracle 服务名jdbc url
sqoop import --connect jdbc:oracle:thin:@//127.0.0.1:1521/ORCL --username sa --password 123456 --table TEST.user--hive-import --hive-database test --hive-table user -m 1
# 使用oracle SID jdbs url
sqoop import --connect jdbc:oracle:thin:@127.0.0.1:1521:ORCL --username sa --password 123456 --table TEST.user --hive-import --hive-database test --hive-table user -m 1
三.建立增量任务
1.启动sqoop metastore服务存储job
sqoop metastore
2.创建增量任务
sqoop job [metastore] --create <job_name> -- <import_task> --incremental append --check-column id --last-value <last_id> sqoop job --meta-connect jdbc:hsqldb:hsql://192.168.1.70:16000/sqoop --create sync_test -- \
import -m 1 --hive-import --connect "jdbc:mysql://192.168.1.196:3306/TEST" --username sa --password-file /user/root/_sqoop/pwd127.txt --table user --hive-database TEST --hive-table user \
--incremental append --check-column id --last-value 0
TIPS: 不指定metastore时默认使用本地的hsql,分布式的时候不可用;
--check-cloumn 须要是 not null ,有序字段
--last-value 如果是第一次导入可以是 0,(一开始就使用增量导入)
3.运行任务
sqoop job [metastore] --exec <job_name>
sqoop job --meta-connect jdbc:hsqldb:hsql://192.168.1.70:16000/sqoop --exec sync_test
sqoop job [metastore] --list 可以查看任务列表
四,HUE 任务
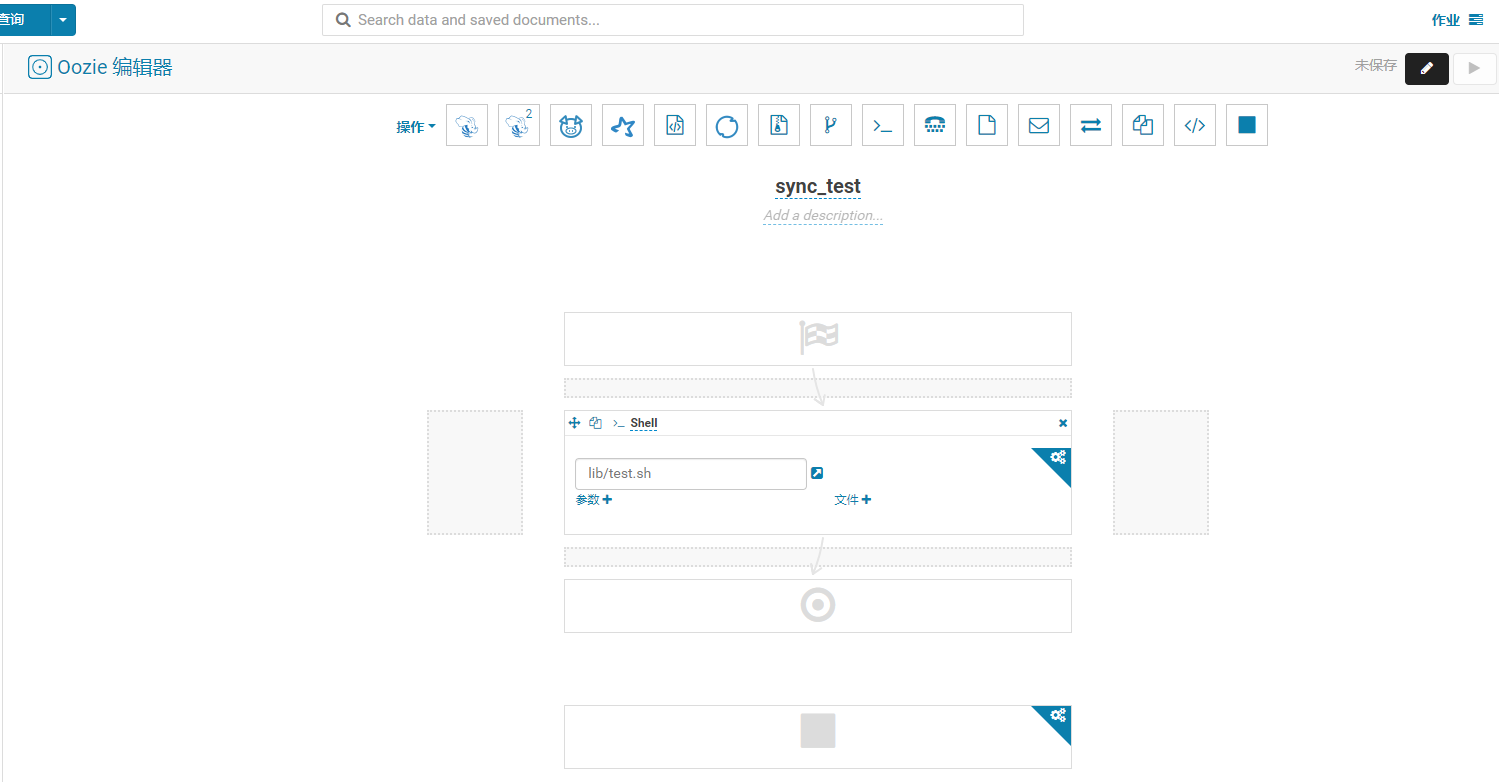
1.建立workflow;
2.在workspace 空间中建立sh文件
3.在sh中写入增量任务命令::sqoop job --meta-connect jdbc:hsqldb:hsql://192.168.1.70:16000/sqoop --exec sync_test
4.再编辑workflow 添加shell组件,选择workspace中的sh文件, 测试
5.建立schedule,将workflow添加进来,编辑运行规则;
更多细节可参考:
https://www.cnblogs.com/canyangfeixue/p/4731520.html
.http://archive.cloudera.com/cdh/3/sqoop/SqoopUserGuide.html
sqoop 数据导入hive的更多相关文章
- 使用sqoop把mysql数据导入hive
使用sqoop把mysql数据导入hive export HADOOP_COMMON_HOME=/hadoop export HADOOP_MAPRED_HOME=/hadoop cp /hive ...
- sqoop数据导入到Hdfs 或者hive
用java代码调用shell脚本执行sqoop将hive表中数据导出到mysql http://www.cnblogs.com/xuyou551/p/7999773.html 用sqoop将mysql ...
- 将数据导入hive,将数据从hive导出
一:将数据导入hive(六种方式) 1.从本地导入 load data local inpath 'file_path' into table tbname; 用于一般的场景. 2.从hdfs上导入数 ...
- 042 将数据导入hive,将数据从hive导出
一:将数据导入hive(六种方式) 1.从本地导入 load data local inpath 'file_path' into table tbname; 用于一般的场景. 2.从hdfs上导入数 ...
- python脚本 用sqoop把mysql数据导入hive
转:https://blog.csdn.net/wulantian/article/details/53064123 用python把mysql数据库的数据导入到hive中,该过程主要是通过pytho ...
- sqoop mysql导入hive 数值类型变成null的问题分析
问题描述:mysql通过sqoop导入到hive表中,发现有个别数据类型为int或tinyint的列导入后数据为null.设置各种行分隔符,列分隔符都没有效果. 问题分析:hive中单独将有问题的那几 ...
- [hadoop读书笔记] 第十五章 sqoop1.4.6小实验 - 将mysq数据导入hive
安装hive 1.下载hive-2.1.1(搭配hadoop版本为2.7.3) 2.解压到文件夹下 /wdcloud/app/hive-2.1.1 3.配置环境变量 4.在mysql上创建元数据库hi ...
- sqoop数据导入命令 (sql---hdfs)
mysql------->hdfs sqoop导入数据工作流程: sqoop提交任务到hadoop------>hadoop启动mapreduce------->mapreduce通 ...
- Sqoop 数据导入导出实践
Sqoop是一个用来将hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如:mysql,oracle,等)中的数据导入到hadoop的HDFS中,也可以将HDFS的数据导入到 ...
随机推荐
- 05.配置为开发模式、配置静态资源locations、自定义消息转化器、FastJson
配置为开发模式,代码做了修改,不用重新运行 idea需要该配置,mac测试无效 <dependency> <groupId>org.springframework</gr ...
- Linux自用指令——2019年10月23日
1.ls ls命令是列出目录内容(List Directory Contents)的意思.运行它就是列出文件夹里的内容,可能是文件也可能是文件夹. ls -a 列出目录所有文件,包含以.开始的隐藏文件 ...
- centos 6.5 查看发行版本
cat /etc/redhat-release 其他发行版 lsb_release -a
- 写出高性能SQL语句的十三条法则
1. 首先要搞明白什么叫执行计划? 执行计划是数据库根据SQL语句和相关表的统计信息作出的一个查询方案,这个方案是由查询优化器自动分析产生的,比如一条SQL语句如果用来从一个10万条记录的表中查1条记 ...
- 【HDOJ6606】Distribution of books(二分,BIT)
题意:给定一个长为n的数组,要求挑它前缀的一段,将其分成k段,使得每段和的最大值最小 1<=k<=n<=2e5,abs(a[i])<=1e9 思路: 刚开始写了线段树TLE 改 ...
- window安装nodejs
nvm管理nodejs 原文: https://www.cnblogs.com/shimily/articles/7244058.html1.下载nvm(nodejs版本管理工具) https://g ...
- [HDU2855]Fibonacci Check-up
题目:Fibonacci Check-up 链接:http://acm.hdu.edu.cn/showproblem.php?pid=2855 分析: 1)二项式展开:$(x+1)^n = \sum^ ...
- [CSP-S模拟测试]:Revive(点分治)
题目背景 $Sparkling\ ashes\ drift\ along\ your\ flames \\ And\ softly\ merge\ into\ the\ sky$ 题目传送门(内部题1 ...
- 写在Flutter 1.0之前
开始 大概有半年没有写东西了,感觉时间过得飞快,18年也过一小半,趁着谷歌大会再为Flutter这个耀眼的新星,再吹一波! 都beta3了,1.0还会远吗 Flutter团队依然不紧不慢,一步一个脚印 ...
- js策略模式vs状态模式
一.策略模式 1.定义:把一些小的算法,封装起来,使他们之间可以相互替换(把代码的实现和使用分离开来)2.利用策略模式实现小方块缓动 html代码: <div id="containe ...