内置json&pickle&shelve&xml
序列化:把对象(变量)从内存中变成可存储可传输的过程称之为序列化,Python中叫做pickling,其他语言中也被称之为serialization,marshalling,flattening等等
序列化之后就可以将内容存储到硬盘或通过网络传输到别的机器上
反序列化:将序列化的对象从硬盘中读取到内存中,叫做unpickling
如果想在不同语言之间传递信息,必须将对象序列化成标准格式
json是一种通用标准格式,表现为一个字符串,可以被其他语言读取
json是JavaScript语言的对象,json与Python的数据类型对比:
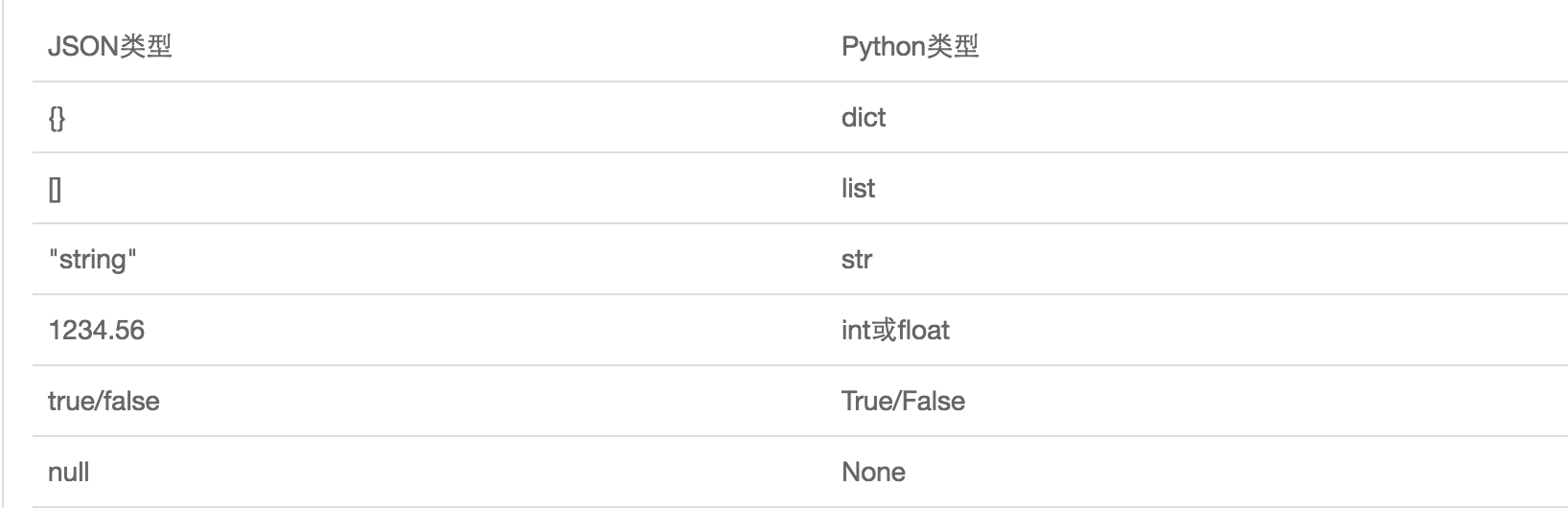
#json模块:任何语言都通用,json它是JavaScript中一个对象
import json dic = {"name":"sjy"}
date = json.dumps(dic) #这个得到的是json字符串,将传入的数据类型都变成json字符串
#json只认双引号,它会把数据类型的里面的所有单引号变成双引号,实质是变成json中的字符串格式
f = open("new","w")
f.write(date) #将经过json方法处理过的json字符串写进文件中
f.close()
with open("new","r") as f_r:
n = json.loads(f_r.read()) #用json方法读取这个文件,这样得到的内容时json字符串内的数据类型
print(n) #相当于eval()提取字符串中的数据类型,但json是通用的,经过json处理可以直接在其他语言上用
print(type(n)) # json.dump(dic,f) #这个等同于date=json.dumps(dic);f.write(date)这两步
# json.load(f_r) #等同于json.loads(f_r.read())
#这两种用于文件操作,建议用 dumps,loads 这两个可使用范围广些
"""
json 会把给的数据类型里面的单引号变成双引号,并将其变成json字符串,实质是变成json中的字符串格式
例如:原内容 ------> 转换成字符串 ---->显示给用户的内容
dic = {'name':'sjy'} ------> '{"name":"sjy"}'---->{"name":"sjy"}
i = 7 ------> '7' ---->7
s = 'hello' ------> '"hello"' ---->"hello"
l = [1,2,3] ------> "[1,2,3]" ---->[1,2,3] json是通用的,对一些内容进行json处理后,可以以json字符串的形式存放在硬盘中
而调用这些内容时,可以用json的方法直接调用json字符串里的数据类型,类似eval()
但相比较而言json可以跨语言使用,其他语言可以直接拿取使用
json中dumps方式是将内容序列化,loads是反序列化
"""
#pickle模块,使用方法和json一样,功能也类似
#pickle是Python特有的序列化操作,只适用于Python,且不同版本之间可能还存在不兼容的情况
import pickle
dic = {'name':'sjy'}
j = pickle.dumps(dic) #注意和json的区别,pickle是将数据类型转换成字节
with open("new_p","wb") as f: #因为是pickle是将内容转换成字节,要wb方式写入
f.write(j)
with open("new_p","rb") as f_r:
n = pickle.loads(f_r.read())
print(n)
#shelve模块
import shelve
f = shelve.open(r"new_s") #用shelve方法建立文件,再将数据内容写进去,会生成3个文件
f["shout"] = {"name":"sjy"}
f.close()
f.get("shout") #用这个模块可以直接使用写进去的数据类型的方法,这个模块是在内部已做好序列化和反序列化的操作
xml:和json一样,也是可以实现不同语言之间的互通
xml格式是通过<>节点来区分数据结构的,如下
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data> xml数据
#xml模块:和json的区别,xml使用的是标签语言
import xml.etree.ElementTree as ET #导入这个模块,并将这个模块赋值给某个变量,模块名太长,赋值给变量,方便书写
tree = ET.parse("xml_lesson") #利用parse方法将xml文件解析出来,并将内容赋值给一个变量,此时这个变量就是一个对象
root = tree.getroot() #获取这个对象的根
print(root.tag) #.tag获取这个根标签的名字
for i in root: #循环遍历这个根,获取根下的内容
print(i) #这里打印出来的是内存地址,因为得到的是一个个对象
print(i.tag) #通过.tag获取每个对象的根标签名字
print(i.attrib) #通过.attrib方法获取每个标签里的属性,放在一个字典中
for j in i: #遍历这个根
print(j.tag) #和上面一样,获取名字
print(j.attrib) #获取标签里的属性
print(j.text) #通过.text获取每个标签里的具体文本内容
for node in root.iter("year"): #通过.iter('标签名")获取某一层级的所有这个名字标签
print(node.tag,node.text)
new_year = int(node.text) + 1 #对这个标签里的文本内容进行修改
node.text = str(new_year) #将修改的内容再赋值给这个标签
node.set("date","no") #用.set对这个标签的属性进行修改
tree.write("new_xml.xml") #将修改的内容重新写进xml文件
for count in root.findall("country"): #.findall("标签名")找出所有的这个名字的标签
ran = int(count.find("rank").text)
if ran > 50:
root.remove(count) #移除
tree.write("out_xml.xml")
"""
将一个xml文件通过parse方法解析后,再循环遍历每个层级,
并用.tag方法获取每个层级根标签的名字,注意是根标签,不是所有,不包含根里嵌套的标签
.attrib方法获取每个标签的属性,
.text方法获取标签里具体的文本内容
若想只获取其中一个标签,用.iter("标签名")方法得到这个层级下的所有(含嵌套里的)这个名字的标签
若想修改某个标签里的文本内容:先.next获取内容,再修改获取的内容后传回给.next
修改标签的属性:.set("属性名","属性内容"),最后将修改的内容write写进xml
"""
#创建一个xml
import xml.etree.ElementTree as ET
new_xml_lesson = ET.Element("namelist")
#使用模块方法 .Element("标签名") 创建一个根标签namelist并赋值给一个变量
name = ET.SubElement(new_xml_lesson,"name",attrib = {"enrolled":"no"})
#使用模块方法 .SubElement("上一级标签","当前级标签","当天级标签属性") 创建下一级的标签并赋值给一个变量
age = ET.SubElement(name,"age",attrib={"checked":"no"},)
sex = ET.SubElement(age,"sex")
sex.text = "" #对某个标签添加文本内容 et = ET.ElementTree(new_xml_lesson) #使用模块方法.ElementTree 将整个根内容生成文档对象
et.write("test.xml",encoding="utf8",xml_declaration=True) #把它写进一个xml文件中
# ET.dump(new_xml_lesson) #打印生成的格式
内置json&pickle&shelve&xml的更多相关文章
- python 序列化及其相关模块(json,pickle,shelve,xml)详解
什么是序列化对象? 我们把对象(变量)从内存中编程可存储或传输的过程称之为序列化,在python中称为pickle,其他语言称之为serialization ,marshalling ,flatter ...
- Python全栈开发记录_第八篇(模块收尾工作 json & pickle & shelve & xml)
由于上一篇篇幅较大,留下的这一点内容就想在这里说一下,顺便有个小练习给大家一起玩玩,首先来学习json 和 pickle. 之前我们学习过用eval内置方法可以将一个字符串转成python对象,不过, ...
- python模块--json \ pickle \ shelve \ XML模块
一.json模块 之前学习过的eval内置方法可以将一个字符串转成一个python对象,不过eval方法时有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,e ...
- python序列化及其相关模块(json,pickle,shelve,xml)详解
什么是序列化对象? 我们把对象(变量)从内存中编程可存储或传输的过程称之为序列化,在python中称为pickle,其他语言称之为serialization ,marshalling ,flatter ...
- PYTHON-模块 json pickle shelve xml
""" pickle 和 shevle 序列化后得到的数据 只有python才能解析 通常企业开发不可能做一个单机程序 都需要联网进行计算机间的交互 我们必须保证这个数据 ...
- python笔记-7(shutil/json/pickle/shelve/xml/configparser/hashlib模块)
一.shutil模块--高级的文件.文件夹.压缩包处理模块 1.通过句柄复制内容 shutil.copyfileobj(f1,f2)对文件的复制(通过句柄fdst/fsrc复制文件内容) 源码: Le ...
- Python学习笔记——基础篇【第六周】——json & pickle & shelve & xml处理模块
json & pickle 模块(序列化) json和pickle都是序列化内存数据到文件 json和pickle的区别是: json是所有语言通用的,但是只能序列化最基本的数据类型(字符串. ...
- 常用模块(json/pickle/shelve/XML)
一.json模块(重点) 一种跨平台的数据格式 也属于序列化的一种方式 介绍模块之前,三个问题: 序列化是什么? 我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化. 反序列化又是什么? 将 ...
- 模块 - json/pickle/shelve/xml/configparser
序列化: 序列化是指把内存里的数据类型转变成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘或网络传输时只能接受bytes. 为什么要序列化: 有种办法可以直接把内存数据(eg:10个列表,3 ...
随机推荐
- mysql中对比 JSON_VALUE 与 JSON_QUERY
1. JSON概述 MySQL里的json分为json array和json object. $表示整个json对象,在索引数据时用下标(对于json array,从0开始)或键值(对于json ob ...
- Ansible安装及常用模块
配置文件:/etc/ansible/ansible.cfg 主机列表:/etc/ansible/hosts 安装anslibe wget -O /etc/yum.repos.d/epel.repo ...
- Git - grafted 和 shallow update not allowed
一般人对开源的模板进行修改是总会进行这样的一条龙操作 # 克隆最近一次提交 git clone xxx --depth 1 # 修改修改修改 提交提交提交 vim xxx git commit -am ...
- 用ajax提交请求,预期Json返回 406错误的解决办法!
正常情况下在Controller端已经配置好了 @ResponseBody @RequestMapping 返回Json格式数据 发生406错误 ,应该检查提交的请求路径是否含有 .html ...
- 阶段3 1.Mybatis_11.Mybatis的缓存_2 延迟加载和立即加载的概念
用户关联的account信息,假设一个用户管理的account有100个.那么我们在查询用户的时候那100个关联的信息也被查询出来. 用的时候才去查关联的数据 这两个不同的地方就是查询的时机不同 什么 ...
- robotframework之用户关键字的用法
robotframework是一个关键字驱动框架,核心在于关键字的应用 目录 1.如何创建用户关键字 2.调用用户关键字 3.用户关键字的使用场景 1.如何创建关键字 第一种:直接在项目上右键,添加用 ...
- lazarus 给应用程序创建 配置文件哈哈
lazarus 给应用程序创建 配置文件哈哈procedure TForm1.Button2Click(Sender: TObject);beginForceDirectoriesUTF8(GetAp ...
- is_displayed()检查元素是否可见
返回的结果是bool类型,以百度首页为案例,来验证"©2019 Baidu 使用百度前必读意见反馈京ICP证030173号 "是否可见,见实现的代码: from selenium ...
- 【转载】PHP中foreach的用法
http://www.php.cn/php-weizijiaocheng-399438.html 很好用的PHP中foreach的用法详解,收藏!
- 题解 AT1357 【n^p mod m】
此题就是快速幂取模 先简单讲一讲快速幂 首先,快速幂的目的就是做到快速求幂,假设我们要求a^b,按照朴素算法就是把a连乘b次,这样一来时间复杂度是O(b)也即是O(n)级别,快速幂能做到O(logn) ...