Ajax爬取豆瓣电影目录(Python)
下面的分析相当于一个框架,搞懂之后,对于类似的文字爬取,我们也可以实现。就算不能使用Ajax方法,我们也能够使用相同思想去爬取我们想要的数据。
豆瓣电影排行榜分析
首先我们打开网页的审查元素,选中Network==》XHR==》电影相关信息网页文件
筛选并比较以下数据(三个文件数据)
请求地址
Request URL:https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0 Request URL:https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=20 Request URL:https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=40
查询参数
type:movie
tag:热门
sort:recommend
page_limit:
page_start: type:movie
tag:热门
sort:recommend
page_limit:
page_start: type:movie
tag:热门
sort:recommend
page_limit:
page_start:
请求报头
Host:movie.douban.com
Referer:https://movie.douban.com/explore
User-Agent:Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36
X-Requested-With:XMLHttpRequest
通过比较请求地址和查询参数,得出
请求地址 = baseurl+type+tag+sort+page_limit+page_start baseurl:https://movie.douban.com/j/search_subjects?
type:固定为movie
tag:关键字,需要将utf-8转换为urlencode
sort:固定为recommend
page_limit:表示一页显示的电影数量,固定20
page_start:表示电影页数,从0开始,20为公差的递增函数
由此我们获取到了我们需要的数据,可以将爬虫分为三步
- 获取网页json格式代码
- 从代码中获取电影名和电影海报图片链接
- 将获得的图片命名为电影名
流程
准备工作
在函数外部定义伪装的请求报头
headers={
'Host': 'movie.douban.com',
'Referer': 'https://movie.douban.com/explore',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
获取json格式代码
def get_page(page):
#请求参数
params={
'type': 'movie',
'tag': '奥特曼',
'sort': 'recommend',
'page_limit': '',
'page_start': page,
}
#基本网页链接
base_url = 'https://movie.douban.com/j/search_subjects?'
#将基本网页链接与请求参数结合在一起
url = base_url + urlencode(params)
try:
#获取网页代码
resp = requests.get(url, headers=headers)
print(url)
#返回json数据格式代码
if 200 == resp.status_code:
print(resp.json())
return resp.json()
except requests.ConnectionError:
return None
筛选数据
通过观察电影列表代码文件的preview,进行数据筛选
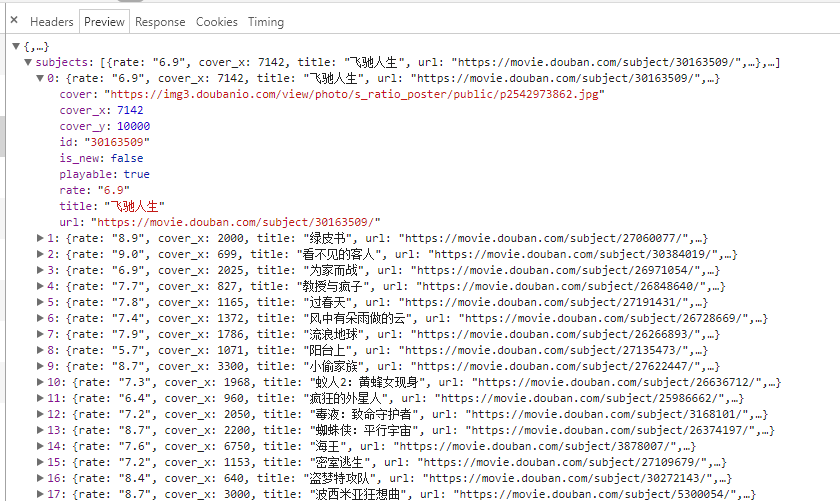
def get_image(json):
if(json.get('subjects')):
data=json.get('subjects')
for item in data:
title=item.get('title')
imageurl=item.get('cover')
#返回"信息"字典
yield {
'title':title,
'images':imageurl,
}
存储图片文件
def save_page(item):
#文件夹名称
file_name = '奥特曼电影大全'
if not os.path.exists(file_name):
os.makedirs(file_name) #获取图片链接
response=requests.get(item.get('images'))
#储存图片文件
if response.status_code==200:
file_path = file_name + os.path.sep + item.get('title') + '.jpg'
with open(file_path, 'wb') as f:
f.write(response.content)
多线程处理
def main(page):
json = get_page(page)
for item in get_image(json):
print(item)
save_page(item) if __name__ == '__main__':
pool = Pool()
pool.map(main, [i for i in range(0, 200, 20)])
pool.close()
pool.join()

总代码
import requests
from urllib.parse import urlencode
import os
from multiprocessing.pool import Pool headers={
'Host': 'movie.douban.com',
'Referer': 'https://movie.douban.com/explore',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
} def get_page(page):
#请求参数
params={
'type': 'movie',
'tag': '奥特曼',
'sort': 'recommend',
'page_limit': '',
'page_start': page,
}
#基本网页链接
base_url = 'https://movie.douban.com/j/search_subjects?'
#将基本网页链接与请求参数结合在一起
url = base_url + urlencode(params)
try:
#获取网页代码
resp = requests.get(url, headers=headers)
print(url)
#返回json数据格式代码
if 200 == resp.status_code:
print(resp.json())
return resp.json()
except requests.ConnectionError:
return None def get_image(json):
if(json.get('subjects')):
data=json.get('subjects')
for item in data:
title=item.get('title')
imageurl=item.get('cover')
#返回"信息"字典
yield {
'title':title,
'images':imageurl,
} def save_page(item):
#文件夹名称
file_name = '奥特曼电影大全'
if not os.path.exists(file_name):
os.makedirs(file_name) #获取图片链接
response=requests.get(item.get('images'))
#储存图片文件
if response.status_code==200:
file_path = file_name + os.path.sep + item.get('title') + '.jpg'
with open(file_path, 'wb') as f:
f.write(response.content) def main(page):
json = get_page(page)
for item in get_image(json):
print(item)
save_page(item) if __name__ == '__main__':
pool = Pool()
pool.map(main, [i for i in range(0, 200, 20)])
pool.close()
pool.join()
本来是准备使用https://movie.douban.com/tag/#/ 不过在后面,刷新网页时,总是出现服务器问题。不过下面的代码还是可以用。
import requests
from urllib.parse import urlencode
import os
from hashlib import md5
from multiprocessing.pool import Pool headers={
'Host': 'movie.douban.com',
'Referer': 'https://movie.douban.com/tag/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
} def get_page(page):
params={
'sort':'U',
'range':'0,10',
'tags':'奥特曼',
'start': page,
}
base_url = 'https://movie.douban.com/j/new_search_subjects?'
url = base_url + urlencode(params)
try:
resp = requests.get(url, headers=headers)
print(url)
if 200 == resp.status_code:
print(resp.json())
return resp.json()
except requests.ConnectionError:
return None def get_image(json):
if(json.get('data')):
data=json.get('data')
for item in data:
title=item.get('title')
imageurl=item.get('cover')
yield {
'title':title,
'images':imageurl,
} def save_page(item):
file_name='奥特曼大全'+os.path.sep+item.get('title')
if not os.path.exists(file_name):
os.makedirs(file_name)
try:
response=requests.get(item.get('images'))
if response.status_code==200:
file_path = '{0}/{1}.{2}'.format(file_name, md5(response.content).hexdigest(), 'jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(response.content)
else:
print('Already Downloaded', file_path)
except requests.ConnectionError:
print('Failed to Save Image') def main(page):
json = get_page(page)
for item in get_image(json):
print(item)
save_page(item) if __name__ == '__main__':
pool = Pool()
pool.map(main, [i for i in range(0, 200, 20)])
pool.close()
pool.join()
Ajax爬取豆瓣电影目录(Python)的更多相关文章
- 爬虫系列1:Requests+Xpath 爬取豆瓣电影TOP
爬虫1:Requests+Xpath 爬取豆瓣电影TOP [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]: ...
- 利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中 我们先来看一下通过浏览器的方式来筛选某些特定的电影: 我们把URL来复制出来分析分析: https://movie.douban.com ...
- Python开发爬虫之静态网页抓取篇:爬取“豆瓣电影 Top 250”电影数据
所谓静态页面是指纯粹的HTML格式的页面,这样的页面在浏览器中展示的内容都在HTML源码中. 目标:爬取豆瓣电影TOP250的所有电影名称,网址为:https://movie.douban.com/t ...
- Python爬虫爬取豆瓣电影之数据提取值xpath和lxml模块
工具:Python 3.6.5.PyCharm开发工具.Windows 10 操作系统.谷歌浏览器 目的:爬取豆瓣电影排行榜中电影的title.链接地址.图片.评价人数.评分等 网址:https:// ...
- python 爬取豆瓣电影评论,并进行词云展示及出现的问题解决办法
本文旨在提供爬取豆瓣电影<我不是药神>评论和词云展示的代码样例 1.分析URL 2.爬取前10页评论 3.进行词云展示 1.分析URL 我不是药神 短评 第一页url https://mo ...
- Python爬取豆瓣电影top
Python爬取豆瓣电影top250 下面以四种方法去解析数据,前面三种以插件库来解析,第四种以正则表达式去解析. xpath pyquery beaufifulsoup re 爬取信息:名称 评分 ...
- python爬取豆瓣电影信息数据
题外话+ 大家好啊,最近自己在做一个属于自己的博客网站(准备辞职回家养老了,明年再战)在家里 琐事也很多, 加上自己 一回到家就懒了(主要是家里冷啊! 广东十几度,老家几度,躲在被窝瑟瑟发抖,) 由于 ...
- python 爬取豆瓣电影短评并wordcloud生成词云图
最近学到数据可视化到了词云图,正好学到爬虫,各种爬网站 [实验名称] 爬取豆瓣电影<千与千寻>的评论并生成词云 1. 利用爬虫获得电影评论的文本数据 2. 处理文本数据生成词云图 第一步, ...
- python 爬虫&爬取豆瓣电影top250
爬取豆瓣电影top250from urllib.request import * #导入所有的request,urllib相当于一个文件夹,用到它里面的方法requestfrom lxml impor ...
随机推荐
- 分布式锁的实现【基于ZooKeeper】
引言 ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件.它是一个为分布式应用提供一致性服务的软件,提 ...
- python设置文字输出颜色
#!/usr/bin/env python # -*- coding:utf-8 -*- """ @Time: 2018/5/5 20:43 @Author: Jun H ...
- php current()函数 语法
php current()函数 语法 作用:返回数组中的当前元素的值.直线电机工作原理 语法:current(array) 参数: 参数 描述 array 必需.规定要使用的数组. 说明:返回数组中的 ...
- 透明的LISTVIEW
.NET就是封装的太密了,有时很多时候让我们反而更麻烦,特别是COPY不到的时候,又不懂自已想的话,说土一点就是死路一条, 记得以前经常用一句话,C++支持,可C#他不支持啊!就这样安慰自已 其实做多 ...
- Solr核心(内核)
Solr核心(内核) Solr核心(Core)是Lucene索引的运行实例,包含使用它所需的所有Solr配置文件.我们需要创建一个Solr Core来执行索引和分析等操作. Solr应用程序可以包 ...
- 学习日记3、投机取巧使两个表的数据同时在一个treeGrid中显示
不多说了直接上代码, $('#List').treegrid({ url: '@Url.Action("GetList")', width: $(window).width() - ...
- android7.0对于SharedPreferences设置模式的限制
错误信息: 03-28 10:16:12.701 830 932 E AndroidRuntime: FATAL EXCEPTION: Thread-903-28 10:16:12.701 ...
- C#-概念-类库:类库
ylbtech-C#-概念-类库:类库 1.返回顶部 1. 类库(Class Library)是一个综合性的面向对象的可重用类型集合,这些类型包括:接口.抽象类和具体类.类库可以解决一系列常见编程任务 ...
- linux 执行shell文件
执行的时候总是报错 安装软件: yum install dos2unix chmod +x test.sh dos2unix test.sh 这样执行sh文件不会报一下异常,主要是因为windows中 ...
- 数据可视化-D3js-展示古地理图和古地理坐标反算^_^gplates古地理坐标反算接口
在线演示 <!DOCTYPE html> <html> <head> <link type="image/png" rel="i ...