Task2.特征提取
参考:https://blog.csdn.net/u012052268/article/details/77825981/
利用jieba分词工具去除停用词:
停用词:1.在SEO中为节省空间和提高搜索效率,搜索引擎会在索引页面或处理搜索请求时自动忽略某些字或词。使用广泛,甚至是用的过于频繁的词,如英文中的‘i’,'is','what',中文中的‘我’,'就'等等几乎在每篇文章中都会出现,但是如果使用了太多的停用词,也同样可能无法得到较为精确的结果。2.在文章中出现频率很高,但是实际意义不大,主要包括语气助词、副词、介词、连词等,例如‘的’,‘在’,‘与’,‘虽然’等等。
import jieba #创建停用词表
def stopwordslist():
stopwords = [line.strip() for line in open('stopwords.txt',encoding='utf-8').readlines()]
return stopwords #对句子今进行分词
def seg_depart(sentence):
sentence_depart = jieba.cut(sentence.strip())
stopwords = stopwordslist()
#print(''.join(sentence_depart))
outstr = ''
for word in sentence_depart:
if word not in stopwords:
if word != '\t':
outstr += word
outstr += " "
return outstr filename = 'NBA.txt'
outfilename = 'outputs.txt'
inputs = open(filename,'r',encoding='utf8')
outputs = open(outfilename,'w',encoding='utf8') #将结果写入output.txt中
for line in inputs:
line_seg = seg_depart(line)
outputs.write(line_seg +'\n') outputs.close()
inputs.close()
print("success")
结果如下:
北京 时间 月 20 日 2017 年 NBA 全明星 正赛 之前 训练 中 出现 有趣 一幕 起初 威少 脱离 西部 全明星 球员 独自 练习 投篮 全队 跑 篮 过程 中 威少 加入 西部 全 明星队 凯文 - 杜兰特 出现 互动
推特上 媒体 拍 照片 来看 西部 全明星 球员 赛前 投篮 热身 中 威少 一个 一个 半场 投篮 西部 全明星 球员 一个 半场 投篮 看来 杜兰特 威少 拒绝
外界 看来 威少 刻意 避开 杜兰特 也许 威少 一个 投篮 太 孤独 詹姆斯 - 哈登 加入 威少
之后 全队 跑 篮中 威少 加入 西部 全 明星队 杜兰特 出现 期待 互动 互相 传球
了解 杜兰特 威少 送出 上篮 助攻 勇士 记者 安东尼 - 斯莱特 推特上 表示 威少 杜兰特 没有 变得 友好 没有 忽视 KD 威少 互相 传球 抢 篮板 天呐 天呐 看见 没 杜兰特 更衣柜 刚好 韦 斯布鲁克 更衣柜 对面 梅 拉斯 写道 发布 一段 小视频 清楚 看出 韦 斯布鲁克 杜兰特 之间 相隔 名 球员
韦 斯布鲁克 身旁 身披 15 号 考辛斯 杜兰特 位于 对角 位置 左侧 位置 汤普森 库里 格林 勇士 四人组 更衣柜 位置 挨 一块儿
昔日 雷霆 效力 杜 韦二少 如今 关系 非常 恶劣 勇士 客场 击败 雷霆 赛后 两人 先后 进入 一家 牛排馆 吃饭 相隔 五米 全程 毫无 交流 全明星 周末 期间 韦 斯布鲁克 杜兰特 迎面 碰到 两人 装作 没有 看见 宛若 空气
破裂 感情 修复 或许 只能 依靠 时间 有趣 昨天 三分球 大赛 现场 主持人 介绍 到场 嘉宾 时 出现 口误 端坐 场边 杜兰特 称为 俄克拉荷马 杜兰特 显得 一脸 不爽 本届 全明星 正赛 最大 看点 杜韦二少 重逢 会 擦 出 火花 掌握 勇士 主帅 史蒂夫 - 科尔 手里 韦少 完成 全明星 MVP 三连庄 成为 正赛 一个 噱头 张卫平 指导 本次 正赛 看法 看看 说
张卫平 预测 全明星 正赛 因素 助 韦少 MVP 三连庄
张卫平 指导 预测 全明星 正赛
全明星赛 MVP 归属 张 指导 认为 韦少 当选 机会 很大 韦少 已经 连续 两年 成为 全明星 MVP 归属 ( 2015 年 全明星赛 韦少 轰下 41 分 夺得 全明星赛 MVP 2016 年 全明星赛 砍 31 分 蝉联 全明星赛 MVP 韦少 成为 继 佩蒂特 之后 NBA 历史 第二位 蝉联 全明星赛 MVP 球员 ) 韦少 今年 再夺 全明星赛 MVP 成为 NBA 史上 第一位 完成 全明星赛 MVP 三连庄 球员 目标 全力 冲击
说 前 凯尔特人 队 现 快船队 主教练 道 格 - 里 弗斯 科尔 提 建议 死敌 全明星赛 疯狂 发挥 免得 将来 见面 玩命 现在 勇士 西部 死敌 韦少 带领 雷霆 究其原因 杜兰特 韦少 之间 冗长 肥皂剧 科尔 一定 会 韦少 全明星赛 打个 痛快
张 指导 认为 勇士 四 巨头 不会 科尔 全明星赛 控制 出场 时间 埋怨 主教练 对手 会 怠慢 记下 仇来 科尔 不出意外 应该 会 听从 里 弗斯 建议 韦少 玩命
第三点 韦少 性格 来看 全明星赛 娱乐 性质 比赛 没有 特别 认真 地去 韦少 不会 在意 特点 上场 干 性格 两次 全明星 MVP 最好 佐证 大伙 心照不宣 韦少 目前 保持 着场 均 三双 全明星 先发 心里 一直 憋着 一口气 证明
看来 科尔 选择 韦少 战个 痛快 加上 韦少 性格 第三座 全明星 MVP 应该 稳稳地 收下 张 指导 说 不能 说 韦少 一定 MVP 预测 具体 临场 发挥 ( 栗旬 )
统计词频:
import jieba
#encoding=utf8
#创建停用词表
def stopwordslist():
stopwords = [line.strip() for line in open('stopwords.txt',encoding='utf-8').readlines()]
return stopwords #对句子今进行分词
def seg_depart(sentence):
sentence_depart = jieba.cut(sentence.strip())
stopwords = stopwordslist()
#print(''.join(sentence_depart))
word_list=[]
for word in sentence_depart:
if word not in stopwords:
if word != '\t':
word_list.append(word) return word_list filename = 'NBA.txt'
outfilename = 'outputs.txt'
inputs = open(filename,'r',encoding='utf-8-sig')#读取开头避免把\ufeff读进去 dic_count={}#统计词频的字典 for line in inputs:
line_seg = seg_depart(line)
for word in line_seg:
if word not in dic_count:
dic_count[word] = 1
else:
dic_count[word] += 1 inputs.close()
print("success")
print(dic_count)
{'周末': 1, '第三座': 1, '完成': 2, '孤独': 1, '推特上': 2, '佩蒂特': 1, '打个': 1, '心里': 1, '不出意外': 1, '最大': 1, '砍': 1, '出现': 4, '拍': 1, '刚好': 1, '进入': 1, 'MVP': 12, '不能': 1, '只能': 1, '很大': 1, '出': 1, '北京': 1, '忽视': 1, '左侧': 1, '发挥': 2, '第二位': 1, '一口气': 1, '到场': 1, '目前': 1, '身旁': 1, '里': 2, '两人': 2, '篮': 1, '汤普森': 1, '称为': 1, '佐证': 1, '年': 3, ')': 2, '雷霆': 3, 'NBA': 3, '前': 1, '疯狂': 1, '破裂': 1, '会': 4, '助': 1, '掌握': 1, '蝉联': 2, '没': 1, '': 1, '心照不宣': 1, '传球': 2, '证明': 1, '三双': 1, '选择': 1, '安东尼': 1, '关系': 1, '西部': 6, '五米': 1, '说': 4, '全队': 2, '巨头': 1, '杜兰特': 13, '之后': 2, '梅': 1, '预测': 3, '有趣': 2, '噱头': 1, '毫无': 1, '勇士': 6, '脱离': 1, '跑': 2, '宛若': 1, '现场': 1, '了解': 1, '凯尔特人': 1, '性格': 3, '主教练': 2, '清楚': 1, '全明星赛': 12, '明星队': 2, '一块儿': 1, '两年': 1, '出场': 1, '-': 5, '队': 1, '地去': 1, '也许': 1, '埋怨': 1, '全': 2, '再夺': 1, '主持人': 1, '没有': 4, '一直': 1, '本次': 1, '嘉宾': 1, '格': 1, '日': 1, '最好': 1, '科尔': 6, '先后': 1, '詹姆斯': 1, '避开': 1, '大赛': 1, '位于': 1, '正赛': 6, '第一位': 1, '加入': 3, '性质': 1, '助攻': 1, '不爽': 1, '比赛': 1, '加上': 1, '四人组': 1, '保持': 1, '拒绝': 1, '': 1, '史蒂夫': 1, '杜韦二少': 1, '韦二少': 1, '指导': 5, '提': 1, '独自': 1, '道': 1, '位置': 3, '栗旬': 1, '互相': 2, '期待': 1, '格林': 1, '昨天': 1, '': 1, '球员': 6, '连续': 1, '之间': 2, '表示': 1, '看出': 1, '全力': 1, '第三点': 1, '更衣柜': 3, '相隔': 2, '装作': 1, '痛快': 2, '分': 2, '着场': 1, '媒体': 1, '三分球': 1, '憋着': 1, '库里': 1, '特别': 1, '挨': 1, '带领': 1, '杜': 1, '昔日': 1, '写道': 1, '一幕': 1, '小视频': 1, '韦少': 17, '认为': 2, '娱乐': 1, '轰下': 1, '发布': 1, '快船队': 1, '口误': 1, '特点': 1, '张': 3, '(': 2, '': 1, '对面': 1, '看看': 1, '碰到': 1, '天呐': 2, '效力': 1, '送出': 1, '一个': 5, '四': 1, '凯文': 1, '击败': 1, '对角': 1, '变得': 1, '擦': 1, '看见': 2, '看来': 3, '恶劣': 1, '听从': 1, '现': 1, 'KD': 1, '俄克拉荷马': 1, '半场': 2, '非常': 1, '三连庄': 3, '手里': 1, '建议': 2, '稳稳地': 1, '': 1, '起初': 1, '空气': 1, '本届': 1, '时': 1, '过程': 1, '感情': 1, '先发': 1, '端坐': 1, '免得': 1, '玩命': 2, '身披': 1, '冗长': 1, '交流': 1, '认真': 1, '一定': 2, '看点': 1, '之前': 1, '见面': 1, '火花': 1, '一家': 1, '抢': 1, '显得': 1, '夺得': 1, '不会': 2, '名': 1, '考辛斯': 1, '应该': 2, '均': 1, '篮板': 1, '主帅': 1, '记下': 1, '来看': 2, '仇来': 1, '月': 1, '或许': 1, '究其原因': 1, '战个': 1, '成为': 4, '韦': 4, '目标': 1, '依靠': 1, '肥皂剧': 1, '牛排馆': 1, '客场': 1, '机会': 1, '中': 3, '上篮': 1, '看法': 1, '张卫平': 3, '': 1, '斯布鲁克': 4, '将来': 1, '哈登': 1, '介绍': 1, '弗斯': 2, '全明星': 13, '一脸': 1, '继': 1, '全程': 1, '威少': 11, '期间': 1, '热身': 1, '投篮': 5, '': 1, '记者': 1, '号': 1, '因素': 1, '外界': 1, '怠慢': 1, '赛后': 1, '拉斯': 1, '时间': 3, '史上': 1, '篮中': 1, '干': 1, '友好': 1, '当选': 1, '对手': 1, '迎面': 1, '临场': 1, '死敌': 2, '赛前': 1, '如今': 1, '今年': 1, '训练': 1, '场边': 1, '收下': 1, '大伙': 1, '历史': 1, '练习': 1, '现在': 1, '冲击': 1, '控制': 1, '一段': 1, '上场': 1, '刻意': 1, '互动': 2, '两次': 1, '在意': 1, '太': 1, '吃饭': 1, '照片': 1, '斯莱特': 1, '修复': 1, '重逢': 1, '具体': 1, '归属': 2, '已经': 1}
语言模型
统计语言模型是一个单词序列上的概率分布,比如给定长度为m的序列,它可以为整个序列产生一个概率P(w1,w2...wm),其实就是想办法找到一个概率分布,它可以表示任意一个句子或者序列出现的概率。
目前在自然语言处理相关应用非常广泛,如语音识别(speech recognition) , 机器翻译(machine translation), 词性标注(part-of-speech tagging), 句法分析(parsing)等。传统方法主要是基于统计学模型,最近几年基于神经网络的语言模型也越来越成熟。
n-gram:
为了解决自由参数数目过多的问题,引入了马尔科夫假设:随意一个词出现的概率只与它前面出现的有限的n-1个词有关。基于上述假设的统计语言模型被称为N-gram语言模型。一阶markov说的就是只与前面1个词有关)
从模型的效果来看,理论上n的取值越大,效果越好。但随着n取值的增加,效果提升的幅度是在下降的。同时还涉及到一个可靠性和可区别性的问题,参数越多,可区别性越好,但同时单个参数的实例变少从而降低了可靠性。经验上,trigram用的最多,尽管如此,原则上,能用bigram解决,绝不使用trigram
通常,通过计算最大似然估计(Maximum Likelihood Estimate)构造语言模型,这是对训练数据的最佳估计,公式如下:
p(w1|wi-1) = count(wi1-, wi) / count(wi-1)
如给定句子集“<s> I am Sam </s>
<s> Sam I am </s>
<s> I do not like green eggs and ham </s>”
部分bigram语言模型如下所示:
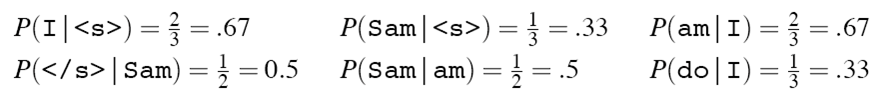
则 I am Sam出现的概率为p = 0.67 * 0.67 * 0.5 * 0.5 = 0.112225
count(wi)如下:

count(wi-1,wi)如下:
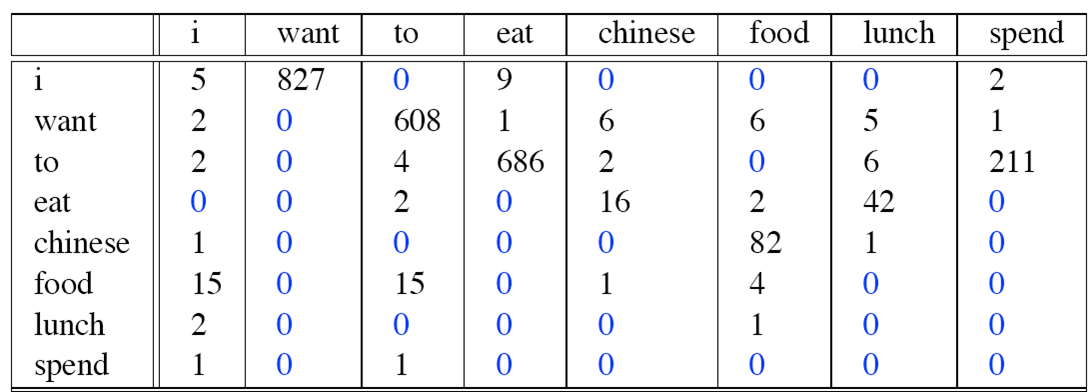
则bigram为:
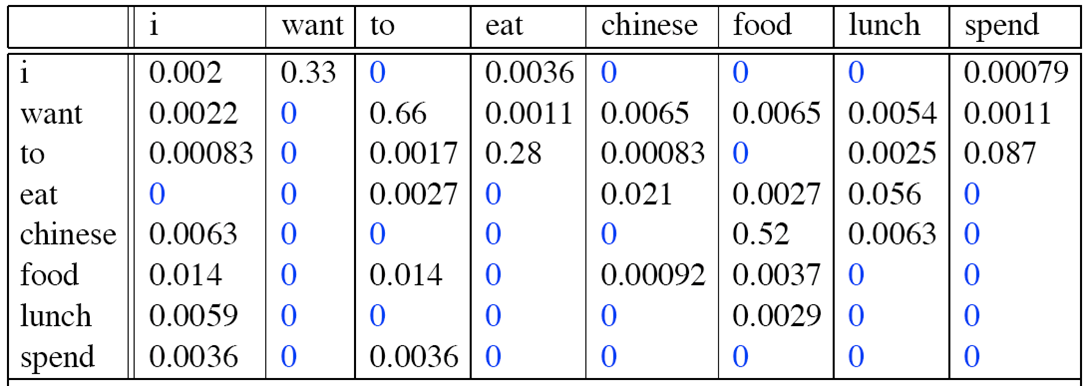
bigram
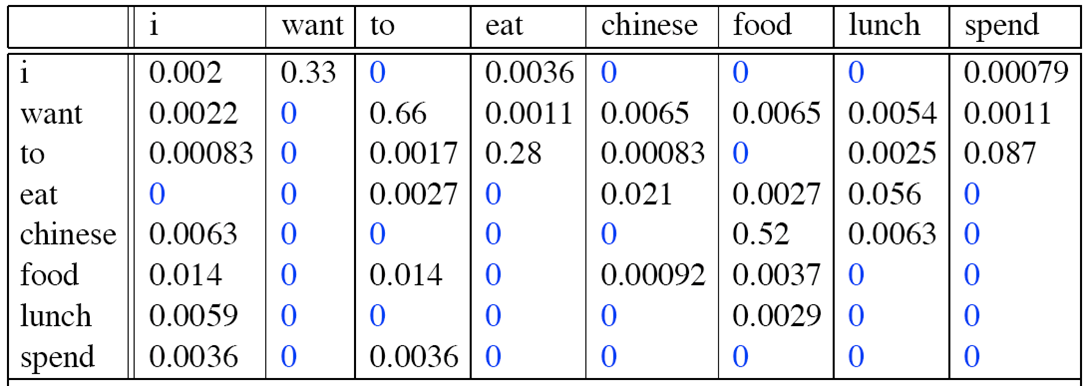
那么,句子“<s> I want english food </s>”的概率为:
p(<s> I want english food </s>)=p(I|<s>) × P(want|I) × P(english|want) × P(food|english) × P(</s>|food) = 0.000031
为了避免数据溢出、提高性能,通常会使用取log后使用加法运算替代乘法运算。
log(p1*p2*p3*p4) = log(p1) + log(p2) + log(p3) + log(p4)
语言模型的评价:
1.在实际应用中的表现
2.困惑度(perplexity)

迷惑度越小,句子概率越大,语言模型越好。使用《华尔街日报》训练数据规模为38million words构造n-gram语言模型,测试集规模为1.5million words,迷惑度如下表所示:

为了避免出现0概率,还引入了数据平滑技术。
n_gram分词:
参考:https://baike.baidu.com/item/unigram/8675709
import re
pattern = re.compile(u'[^a-zA-Z\u4E00-\u9FA5]')#去除非汉字和字母的字符或数字 def generate_ngram(sentence,n=3):
if len(sentence) < n:
n = len(sentence)
list =[]
for i in range(n,len(sentence)+1):
if len(''.join(sentence[i-n:i]).strip()) > 1 and len(pattern.findall(''.join(sentence[i-n:i]).strip())) == 0: list.append(sentence[i-n:i])
return list
sentence="438&*^%^&*我爱北京天安门"
g =generate_ngram(sentence)
g
['我爱北', '爱北京', '北京天', '京天安', '天安门']
进行词频统计
dic_ngram={}
for word in g:
if word in dic_ngram:
dic_ngram[word] += 1
else:
dic_ngram[word] = 1
print(dic_ngram)
{'京天安': 1, '爱北京': 1, '我爱北': 1, '天安门': 1, '北京天': 1}
将文本NBA.txt进行trigram分词,并进行词频统计
import re
pattern = re.compile(u'[^a-zA-Z\u4E00-\u9FA5]') def generate_ngram(sentence,n=3,m=3):
if len(sentence) < n:
n = len(sentence)
list =[]
for i in range(n,len(sentence)+1):
if len(''.join(sentence[i-n:i]).strip()) > 1 and len(pattern.findall(''.join(sentence[i-n:i]).strip())) == 0: list.append(sentence[i-n:i])
return list
filename = 'NBA.txt'
#outfilename = 'outputs.txt'
inputs = open(filename,'r',encoding='utf8')
#outputs = open(outfilename,'w',encoding='utf8') #将结果写入output.txt中
res = []
dict_ngram={}
for line in inputs:
line_seg = generate_ngram(line)
res.append(' '.join(line_seg))
for word in line_seg:
if word in dict_ngram:
dict_ngram[word] += 1
else:
dict_ngram[word] = 1 inputs.close()
print(res) #[dict_ngram[word] +=1 if word in dict_ngram else dict_ngram[word] = 1 for line in inputs for word in generate_ngram(line)] print(dict_ngram)
Task2.特征提取的更多相关文章
- 医学CT图像特征提取算法(matlab实现)
本科毕设做的是医学CT图像特征提取方法研究,主要是肺部CT图像的特征提取.由于医学图像基本为灰度图像,因此我将特征主要分为三类:纹理特征,形态特征以及代数特征,每种特征都有对应的算法进行特征提取. 如 ...
- 特征提取k_word
1) 若直接以20种氨基酸统计k_word: (以ZD98数据集为例) k Dimension 2 400 3 6490 4 22265 维数太大不适用构造特征向量 考虑氨基酸约化后特征提取 约化方案 ...
- 图像特征提取之LBP特征
LBP(Local Binary Pattern,局部二值模式)是一种用来描述图像局部纹理特征的算子:它具有旋转不变性和灰度不变性等显著的优点.它是首先由T. Ojala, M.Pietik?inen ...
- Surf特征提取分析
Surf特征提取分析 Surf Hessian SIFT 读"H.Bay, T. Tuytelaars, L. V. Gool, SURF:Speed Up Robust Features[ ...
- SIFT特征提取分析
SIFT特征提取分析 sift 关键点,关键点检测 读'D. G. Lowe. Distinctive Image Features from Scale-Invariant Keypoints[J] ...
- SIFT特征提取分析(转载)
转载自: http://blog.csdn.net/abcjennifer/article/details/7639681 SIFT(Scale-invariant feature transform ...
- Python_sklearn机器学习库学习笔记(一)_Feature Extraction and Preprocessing(特征提取与预处理)
# Extracting features from categorical variables #Extracting features from categorical variables 独热编 ...
- SIFT 特征提取算法总结
原文链接:http://www.cnblogs.com/cfantaisie/archive/2011/06/14/2080917.html 主要步骤 1).尺度空间的生成: 2).检测尺度空间极 ...
- [转]SIFT特征提取分析
SIFT(Scale-invariant feature transform)是一种检测局部特征的算法,该算法通过求一幅图中的特征点(interest points,or corner points) ...
随机推荐
- Failed to connect to github.com port 443: Timed out
Git Clone下载仓库代码的时候,出现以下情况 Failed to connect to github.com port 443: Timed out 解决办法: 输入 git config -- ...
- 局域网IP耗尽
w 大量的vm 大量的实例 动态修改 mac
- linux中也有闹钟alarm, timer, stopwatch, world clock 等等
stopwatch和timer的区别? timer叫计时器, 是先给出一个时间, 然后从现在开始, 倒数, 减少, 直到时间为0 stopwatch 叫跑錶, 则是从现在开始, 往后 增加时间, 事先 ...
- 如何实现免登陆功能(cookie session?)
Cookie的机制 Cookie是浏览器(User Agent)访问一些网站后,这些网站存放在客户端的一组数据,用于使网站等跟踪用户,实现用户自定义功能. Cookie的Domain和Path属性标识 ...
- KETTLE——(三)数据输出
数据输出和数据输入基本差不多,KETTLE本身支持的数据输出方式也特别多,还是以数据库输出为例. 打开表输出的界面,简单介绍一下其功能: 就这个界面,如果不勾选[指定数据库字段],KETTLE ...
- sync_binlog innodb_flush_log_at_trx_commit 深入理解
innodb_flush_log_at_trx_commit和sync_binlog 两个参数是控制MySQL 磁盘写入策略以及数据安全性的关键参数.本文从参数含义,性能,安全角度阐述两个参数为不同的 ...
- vue登录注册实践
步骤一 1.安装脚手架:npm install vue-cli -g2.wepack生成html模版:vue init webpack ' 文件名'3.安装axios.js-cookie.elemen ...
- [转]JavaScript构造函数及原型对象
JavaScript中没有类的概念,所以其在对象创建方面与面向对象语言有所不同. JS中对象可以定义为”无序属性的集合”.其属性可以包含基本值,对象以及函数.对象实质上就是一组没有特定顺序的值,对象中 ...
- Ubuntu操作系统的总结操作
一.Ubuntu系统环境变量 Ubuntu Linux系统环境变量配置文件分为两种:系统级文件和用户级文件 1.系统级文件: /etc/profile:在登录时,操作系统定制用户环境时使用的第一个文件 ...
- 前端 CSS 一些标签默认有padding
一个html body标签 默认有 margin外边距属性 比如ul标签,有默认的padding-left值. 那么我们一般在做站的时候,是要清除页面标签中默认的padding和margin.以便于我 ...