对React性能优化的研究-----------------引用
JSX的背后
这个过程一般在前端会称为“转译”,但其实“汇编”将是一个更精确的术语。
React开发人员敦促你在编写组件时使用一种称为JSX的语法,混合了HTML和JavaScript。但浏览器对JSX及其语法毫无头绪,浏览器只能理解纯碎的JavaScript,所以JSX必须转换成JavaScript。这里是一个div的JSX代码,它有一个class name和一些内容:
<div className='cn'>
Content!
</div>以上的代码,被转换成“正经”的JavaScript代码,其实是一个带有一些参数的函数调用:
React.createElement('div',{className:'cn'},'Content!');让我们仔细看看这些参数。
第一个是元素的type。对于HTML标签,它将是一个带有标签名称的字符串。
第二个参数是一个包含所有元素属性(attributes)的对象。如果没有,它也可以是空的对象。
剩下的参数都可以认为是元素的子元素(children)。元素中的文本也算作一个child,是个字符串’Content!’ 作为函数调用的第三个参数放置。
你应该可以想象,当我们有更多的children时会发生什么:
<div className='cn'>
Content 1! <br />
Content 2!</div>
React.createElement(
'div',
{ className: 'cn' },
'Content 1!', // 1st child
React.createElement('br'), // 2nd child
'Content 2!' // 3rd child
)我们的函数现在有五个参数:
一个元素的类型
一个属性对象
三个子元素。
因为其中一个child是一个React已知的HTML标签(<br/>),所以它也会被描述为一个函数调用(React.createElement('br'))。
到目前为止,我们已经涵盖了两种类型的children:
简单的String
另一种会调用React.createElement。
然而,还有其他值可以作为参数:
基本类型 false, null, undefined, true
数组
React Components
可以使用数组是因为可以将children分组并作为一个参数传递:
React.createElement(
'div',
{ className: 'cn' },
['Content 1!', React.createElement('br'), 'Content 2!']
)当然了,React的厉害之处,不仅仅因为我们可以把HTML标签直接放在JSX中使用,而是我们可以自定义自己的组件,例如:
function Table({ rows }) {
return (
<table>
{rows.map(row => (
<tr key={row.id}>
<td>{row.title}</td>
</tr>
))}
</table>
);
}组件可以让我们把模板分解为多个可重用的块。在上面的“函数式”(functional)组件的例子里,我们接收一个包含表格行数据的对象数组,最后返回一个调用React.createElement方法的<table>元素,rows则作为children传进table。
无论什么时候,我们这样去声明一个组件时:
<Table rows={rows} />从浏览器的角度来看,我们是这么写的:
React.createElement(Table,{rows:rows});注意,这次我们的第一个参数不是String描述的HTML标签,而是一个引用,指向我们编写组件时编写的函数。组件的attributes现在是接收的props参数了。
把组件(components)组合成页面(page)
所以,我们已经将所有JSX组件转换为纯JavaScript,现在我们有一大堆函数调用,它的参数会被其他函数调用的,或者还有更多的其他函数调用这些参数……这些带参数的函数调用,是怎么转化成组成这个页面的实体DOM的呢?
为此,我们有一个ReactDOM库及其它的render方法:
function Table({ rows }) { /* ... */ } // defining a component
// rendering a component
ReactDOM.render(
React.createElement(Table, { rows: rows }), // "creating" a component
document.getElementById('#root') // inserting it on a page
);当ReactDOM.render被调用时,React.createElement最终也会被调用,返回以下对象:
// There are more fields, but these are most important to us
{
type: Table,
props: {
rows: rows
},
// ...
}这些对象,在React的角度上,构成了虚拟DOM。
他们将在所有进一步的渲染中相互比较,并最终转化为 真正的DOM(virtual VS real, 虚拟DOM VS 真实DOM)。
下面是另一个例子:这次div有一个class属性和几个children:
React.createElement(
'div',
{ className: 'cn' },
'Content 1!',
'Content 2!',
);变成:
{
type: 'div',
props: {
className: 'cn',
children: [
'Content 1!',
'Content 2!'
]
}
}需要注意的是,那些除了type和attribute以外的属性,原本是单独传进来的,转换之后,会作为在props.children以一个数组的形式打包存在。也就是说,无论children是作为数组还是参数列表传递都没关系 —— 在生成的虚拟DOM对象的时候,它们最后都会被打包在一起的。
进一步说,我们可以直接在组件中把children作为一项属性传进去,结果还是一样的:
<div className='cn' children={['Content 1!', 'Content 2!']} />在构建虚拟DOM对象完成之后,ReactDOM.render将会按下面的原则,尝试将其转换为浏览器可以识别和展示的DOM节点:
如果type包含一个带有String类型的标签名称(tag name)—— 创建一个标签,附带上props下所有attributes。
如果type是一个函数(function)或者类(class),调用它,并对结果递归地重复这个过程。
如果props下有children属性 —— 在父节点下,针对每个child重复以上过程。
最后,得到以下HTML(对于我们的表格示例):
<table>
<tr>
<td>Title</td>
</tr>
...</table>重新构建DOM(Rebuilding the DOM)
在实际应用场景,render通常在根节点调用一次,后续的更新会有state来控制和触发调用。
请注意,标题中的“重新”!当我们想更新一个页面而不是全部替换时,React中的魔法就开始了。我们有一些实现它的方式。我们先从最简单的开始 —— 在同一个node节点再次执行ReactDOM.render。
// Second call
ReactDOM.render(
React.createElement(Table, { rows: rows }),
document.getElementById('#root')
);这一次,上面的代码的表现,跟我们已经看到的有所不同。React将从头开始创建所有DOM节点并将其放在页面上,而不是从头开始创建所有DOM节点,React将启动其diff算法,来确定节点树的哪些部分必须更新,哪些可以保持不变。
那么,它是怎样工作的呢?其实只有少数几个简单的场景,理解它们将对我们的优化帮助很大。请记住,现在我们在看的,是在React Virtual DOM里面用来代表节点的对象。
场景1:type是一个字符串,type在通话中保持不变,props也没有改变。
/ before update
{ type: 'div', props: { className: 'cn' } }
// after update
{ type: 'div', props: { className: 'cn' } }这是最简单的情况:DOM保持不变。
场景2:type仍然是相同的字符串,props是不同的。
// before update:
{ type: 'div', props: { className: 'cn' } }
// after update:
{ type: 'div', props: { className: 'cnn' } }type仍然代表HTML元素,React知道如何通过标准DOM API调用来更改元素的属性,而无需从DOM树中删除一个节点。
场景3:type已更改为不同的String或从String组件。
/ before update:
{ type: 'div', props: { className: 'cn' } }
// after update:
{ type: 'span', props: { className: 'cn' } }React看到的type是不同的,它甚至不会尝试更新我们的节点:old元素将和它的所有子节点一起被删除(unmounted卸载)。因此,将元素替换为完全不同于DOM树的东西代价会非常昂贵。幸运的是,这在现实世界中很少发生。
划重点,记住React使用===(triple equals)来比较type的值,所以这两个值需要是相同类或相同函数的相同实例。
下一个场景更加有趣,通常我们会这么使用React。
场景4:type是一个component。
// before update:
{ type: Table, props: { rows: rows } }
// after update:
{ type: Table, props: { rows: rows } }你可能会说,“咦,但没有任何变化啊!”,但是你错了。
如果type是对函数或类的引用(即常规的React组件),并且我们启动了tree diff的过程,则React会持续地去检查组件的内部逻辑,以确保render返回的值不会改变(类似对副作用的预防措施)。对树中的每个组件进行遍历和扫描 —— 是的,在复杂的渲染场景下,成本可能会非常昂贵!
值得注意的是,一个component的render(只有类组件在声明时有这个函数)跟ReactDom.render不是同一个函数。
关注子组件(children)的情况
除了上述四种常见场景之外,当一个元素有多个子元素时,我们还需要考虑React的行为。现在假设我们有这么一个元素:
// ...
props: {
children: [
{ type: 'div' },
{ type: 'span' },
{ type: 'br' }
]
},
// ...我们想要交换一下这些children的顺序:
// ...
props: {
children: [
{ type: 'span' },
{ type: 'div' },
{ type: 'br' }
]
},
// ...之后会发生什么呢?
当diffing的时候,如果React在检查props.children下的数组时,按顺序去对比数组内元素的话:index 0将与index 0进行比较,index 1和index 1,等等。对于每一次对比,React会使用之前提过的diff规则。在我们的例子里,它认为div成为一个span,那么就会运用到情景3。这样不是很有效率的:想象一下,我们已经从1000行中删除了第一行。React将不得不“更新”剩余的999个子项,因为按index去对比的话,内容从第一条开始就不相同了。
幸运的是,React有一个内置的方法(built-in)来解决这个问题。如果一个元素有一个key属性,那么元素将按key而不是index来比较。只要key是唯一的,React就会移动元素,而不是将它们从DOM树中移除然后再将它们放回(这个过程在React里叫mounting和unmounting)。
// ...
props: {
children: [ // Now React will look on key, not index
{ type: 'div', key: 'div' },
{ type: 'span', key: 'span' },
{ type: 'br', key: 'bt' }
]
},
// ...当state发生了改变
到目前为止,我们只聊了下React哲学里面的props部分,却忽视了另外很重要的一部分state。下面是一个简单的stateful组件:
class App extends Component {
state = { counter: 0 }
increment = () => this.setState({
counter: this.state.counter + 1,
})
render = () => (<button onClick={this.increment}>
{'Counter: ' + this.state.counter}
</button>)
}在state对象里,我们有一个keycounter。点击按钮时,这个值会增加,然后按钮的文本也会发生相应的改变。但是,当我们这样做时,DOM中发生了什么?哪部分将被重新计算和更新?
调用this.setState会导致re-render(重新渲染),但不会影响到整个页面,而只会影响组件本身及其children组件。父母和兄弟姐妹都不会受到影响。当我们有一个层级很深的组件链时,这会让状态更新变得非常方便,因为我们只需要重绘(redraw)它的一部分。
把问题说清楚
我们准备了一个小demo,以便你可以在看到在“野蛮生长”的React编码方式下最常见的问题,后续我也告诉大家怎么去解决这些问题。你可以在这里看看它的源代码。你还需要React Developer Tools,请确保浏览器安装了它们。
我们首先要看看的是,哪些元素以及什么时候导致Virtual DOM的更新。在浏览器的开发工具中,打开React面板并选择“Highlight Updates”复选框:
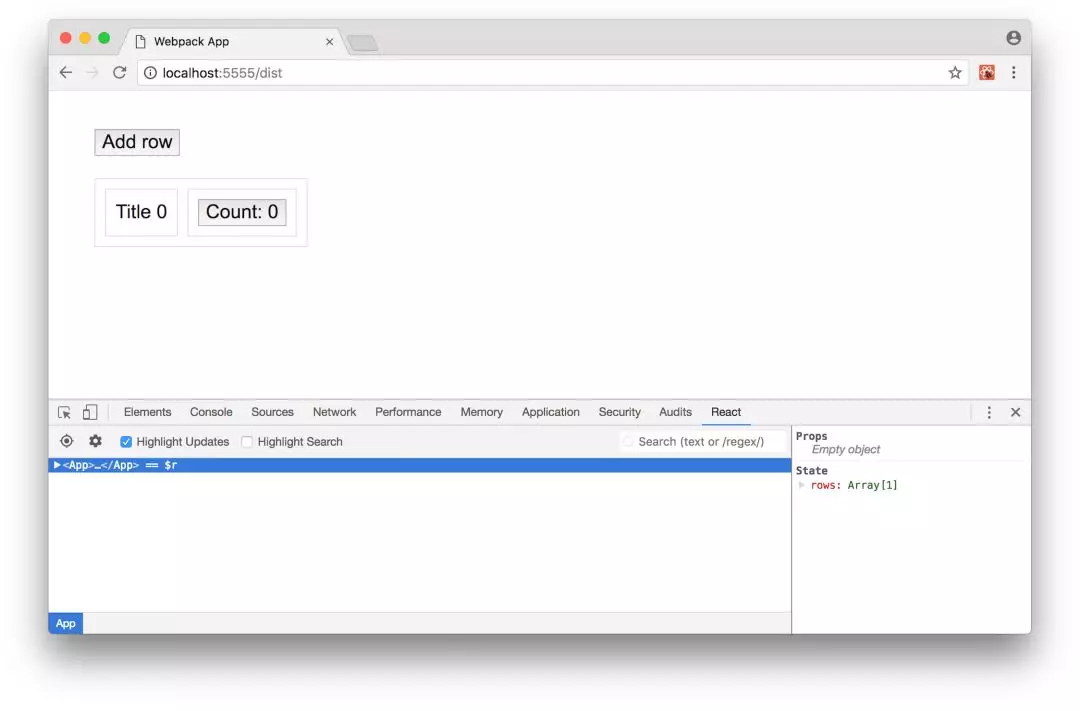
在Chrome中使用“突出显示更新”复选框选中DevTools
现在尝试在表格中添加一行。如你所见,页面上的每个元素周围都会显示一个边框。这意味着每次添加一行时,React都在计算和比较整个虚拟DOM树。现在尝试点击一行内的counter按钮。你将看到state更新后虚拟DOM如何更新 —— 只有引用了state key的元素及其children受到影响。
React DevTools会提示问题出在哪里,但不会告诉我们有关细节的信息:特别是所涉及的更新,是由diffing元素引起的?还是被挂载(mounting)或者被卸载(unmounting)了?要了解更多信息,我们需要使用React的内置分析器(注意它不适用于生产模式)。
添加?react_perf到应用的URL,然后转到Chrome DevTools中的“Performance”标签。点击“录制”(Record)并在表格上点击。添加一些row,更改一下counter,然后点击“停止”(Stop)。
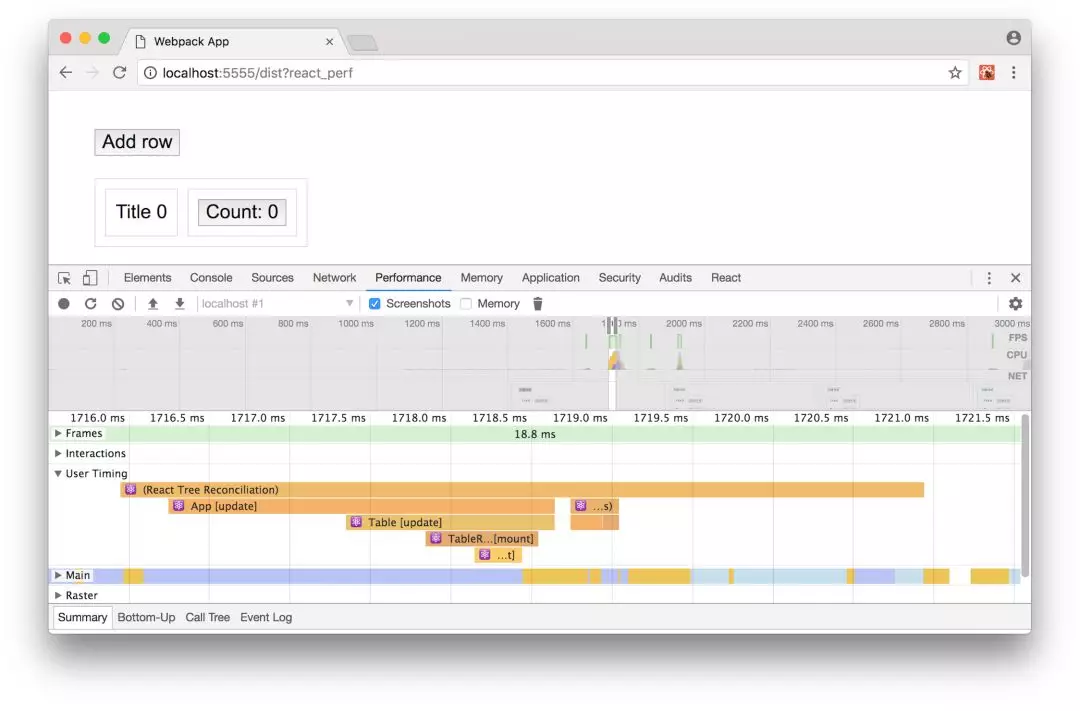
React DevTools的“Performance”选项卡
在输出的结果中,我们关注“User timing”这项指标。放大时间轴直到看到“React Tree Reconciliation”这个组及其子项。这些就是我们组件的名称,它们旁边都写着[update]或[mount]。
我们的大部分性能问题都属于这两类问题之一。
无论是组件(还是从它分支的其他组件)出于某种原因都会在每次更新时re-mounted(慢),又或者我们在大型应用上执行对每个分支做diff,尽管这些组件并没有发生改变,我们不希望这些情况的发生。
优化我们的代码:Mounting / Unmounting
现在,我们已经了解到当需要update Virtual Dom时,React是依据哪些规则去判断要不要更新,以及也知道了我们可以通过什么方式去追踪这些diff场景的背后发生了什么,我们终于准备好优化我们的代码了!首先,我们来看看mounts/unmounts。
如果你能够注意到当一个元素包含的多个children,他们是由array组成的话,你可以实现十分显著的速度优化。
我们来看看这个case:
<div>
<Message />
<Table />
<Footer />
</div>在我们的Virtual DOM里这么表示:
// ...
props: {
children: [
{ type: Message },
{ type: Table },
{ type: Footer }
]
}
// ...这里有一个简单的Message例子,就是一个div写着一些简单的文本,和以及一个巨大的Table,比方说,超过1000行。它们(Message和Table)都是顶级div的子组件,所以它们被放置在父节点的props.children下,并且它们key都不会有。React甚至不会通过控制台警告我们要给每个child分配key,因为children正在React.createElement作为参数列表传递给父元素,而不是直接遍历一个数组。
现在我们的用户已读了一个通知,Message(譬如新通知按钮)从DOM上移除。Table和Footer是剩下的全部。
// ...
props: {
children: [
{ type: Table },
{ type: Footer }
]
}
// ...React会怎么处理呢?它会看作是一个array类型的children,现在少了第一项,从前第一项是Message现在是Table了,也没有key作为索引,比较type的时候又发现它们俩不是同一个function或者class的同一个实例,于是会把整个Tableunmount,然后在mount回去,渲染它的1000+行子数据。
因此,你可以给每个component添加唯一的key(但在目特殊的case下,使用key并不是最佳选择),或者采用更聪明的小技巧:使用短路求值(又名“最小化求值”),这是JavaScript和许多其他现代语言的特性。看:
// Using a boolean trick
<div>
{isShown && <Message />}
<Table />
<Footer />
</div>虽然Message会离开屏幕,父元素div的props.children仍然会拥有三个元素,children[0]具有一个值false(一个布尔值)。请记住true, false, null, undefined是虚拟DOM对象type属性的允许值,我们最终得到了类似的结果:
// ...
props: {
children: [
false, // isShown && <Message /> evaluates to false
{ type: Table },
{ type: Footer }
]
}
// ...因此,有没有Message组件,我们的索引值都不会改变,Table当然仍然会跟Table比较(当type是一个函数或类的引用时,diff比较的成本还是会有的),但仅仅比较虚拟DOM的成本,通常比“删除DOM节点”并“从0开始创建”它们要来得快。
现在我们来看看更多的东西。大家都挺喜欢用HOC的,高阶组件是一个将组件作为参数,执行某些操作,最后返回另外一个不同功能的组件:
function withName(SomeComponent) {
// Computing name, possibly expensive...
return function(props) {
return <SomeComponent {...props} name={name} />;
}
}这是一种常见的模式,但你需要小心。如果我们这么写:
class App extends React.Component() {
render() {
// Creates a new instance on each render
const ComponentWithName = withName(SomeComponent);
return <SomeComponentWithName />;
}
我们在父节点的render方法内部创建一个HOC。当我们重新渲染(re-render)树时,虚拟DOM是这样子的:
// On first render:
{
type: ComponentWithName,
props: {},
}
// On second render:
{
type: ComponentWithName, // Same name, but different instance
props: {},
}现在,React会对ComponentWithName这个实例做diff,但由于此时同名引用了不同的实例,因此全等比较(triple equal)失败,一个完整的re-mount会发生(整个节点换掉),而不是调整属性值或顺序。注意它也会导致状态丢失,如此处所述。幸运的是,这很容易解决,你需要始终在render外面创建一个HOC:
// Creates a new instance just once
const ComponentWithName = withName(Component);
class App extends React.Component() {
render() {
return <ComponentWithName />;
}
}优化我的代码:Updating
现在我们可以确保在非必要的时候,不做re-mount的事情了。然而,对位于DOM树根部附近(层级越上面的元素)的组件所做的任何更改都会导致其所有children的diffing和调整(reconciliation)。在层级很多、结构复杂的应用里,这些成本很昂贵,但经常是可以避免的。
如果有一种方法可以告诉React你不用来检查这个分支了,因为我们可以肯定那个分支不会有更新,那就太棒了!
这种方式是真的有的哈,它涉及一个built-in方法叫shouldComponentUpdate,它也是组件生命周期的一部分。这个方法的调用时机:组件的render和组件接收到state或props的值的更新时。然后我们可以自由地将它们与我们当前的值进行比较,并决定是否更新我们的组件(返回true或false)。如果我们返回false,React将不会重新渲染组件,也不会检查它的所有子组件。
通常来说,比较两个集合(set)props和state一个简单的浅层比较(shallow comparison)就足够了:如果顶层的值不同,我们不必接着比较了。浅比较不是JavaScript的一个特性,但有很多小而美的库(utilities)可以让我们用上那么棒的功能。
现在可以像这样编写我们的代码:
class TableRow extends React.Component {
// will return true if new props/state are different from old ones
shouldComponentUpdate(nextProps, nextState) {
const { props, state } = this;
return !shallowequal(props, nextProps)
&& !shallowequal(state, nextState);
}
render() { /* ... */ }
}但是你甚至都不需要自己写代码,因为React把这个特性内置在一个类React.PureComponent里面。它类似于 React.Component,只是shouldComponentUpdate已经为你实施了一个浅的props/state比较。
这听起来很“不动脑”,在声明class继承(extends)的时候,把Component换成PureComponent就可以享受高效率。事实上,并不是这么“傻瓜”,看看这些例子:
<Table
// map returns a new instance of array so shallow comparison will fail
rows={rows.map(/* ... */)}
// object literal is always "different" from predecessor
style={ { color: 'red' } }
// arrow function is a new unnamed thing in the scope, so there will always be a full diffing
onUpdate={() => { /* ... */ }}
/>上面的代码片段演示了三种最常见的反模式。尽量避免它们!
如果你能注意点,在render定义之外创建所有对象、数组和函数,并确保它们在各种调用间,不发生更改 —— 你是安全的。
你在updated demo,所有table的rows都被“净化”(purified)过,你可以看到PureComponent的表现了。如果你在React DevTools中打开“Highlight Updates”,你会注意到只有表格本身和新行在插入时会触发render,其他的行保持不变。
[译者说:为了便于大家理解purified,译者在下面插入了原文demo的一段代码]
class TableRow extends React.PureComponent {
render() {
return React.createElement('tr', { className: 'row' },
React.createElement('td', { className: 'cell' }, this.props.title),
React.createElement('td', { className: 'cell' }, React.createElement(Button)),
);
}
};不过,如果你迫不及待地all in PureComponent,在应用里到处都用的话 —— 控制住你自己!
shallow比较两组props和state不是免费的,对于大多数基本组件来说,甚至都不值得:shallowCompare比diffing算法需要耗费更多的时间。
使用这个经验法则:pure component适用于复杂的表单和表格,但它们通常会减慢简单元素(按钮、图标)的效率。
感谢你的阅读!现在你已准备好将这些见解应用到你的应用程序中。可以使用我们的小demo(用了或没有用PureComponent)的仓库作为你的实验的起点。此外,请继续关注本系列的下一部分,我们计划涵盖Redux并优化你的数据,目标是提高整个应用的总体性能。
对React性能优化的研究-----------------引用的更多相关文章
- React性能优化之PureComponent 和 memo使用分析
前言 关于react性能优化,在react 16这个版本,官方推出fiber,在框架层面优化了react性能上面的问题.由于这个太过于庞大,我们今天围绕子自组件更新策略,从两个及其微小的方面来谈rea ...
- react性能优化
前面的话 本文将详细介绍react性能优化 避免重复渲染 当一个组件的props或者state改变时,React通过比较新返回的元素和之前渲染的元素来决定是否有必要更新实际的DOM.当他们不相等时,R ...
- React性能优化记录(不定期更新)
React性能优化记录(不定期更新) 1. 使用PureComponent代替Component 在新建组件的时候需要继承Component会用到以下代码 import React,{Componen ...
- 关于React性能优化
这几天陆陆续续看了一些关于React性能优化的博客,大部分提到的都是React 15.3新加入的PureComponent ,通过使用这个类来减少React的重复渲染,从而提升页面的性能.使用过Rea ...
- React 性能优化 All In One
React 性能优化 All In One Use CSS Variables instead of React Context https://epicreact.dev/css-variables ...
- React 性能优化总结
初学者对React可能满怀期待,觉得React可能完爆其它一切框架,甚至不切实际地认为React可能连原生的渲染都能完爆--对框架的狂热确实会出现这样的不切实际的期待.让我们来看看React的官方是怎 ...
- React性能优化总结(转)
原文链接: https://segmentfault.com/a/1190000007811296?utm_source=tuicool&utm_medium=referral 初学者对Rea ...
- react 性能优化
React 最基本的优化方式是使用PureRenderMixin,安装工具 npm i react-addons-pure-render-mixin --save,然后在组件中引用并使用 import ...
- React性能优化总结
本文主要对在React应用中可以采用的一些性能优化方式做一下总结整理 前言 目的 目前在工作中,大量的项目都是使用react来进行开展的,了解掌握下react的性能优化对项目的体验和可维护性都有很大的 ...
随机推荐
- webdriervAPI(操作cookie)
from selenium import webdriver driver = webdriver.Chorme() driver.get("http://www.baidu.co ...
- 【Linux开发】Linux模块机制浅析
Linux允许用户通过插入模块,实现干预内核的目的.一直以来,对linux的模块机制都不够清晰,因此本文对内核模块的加载机制进行简单地分析. 模块的Hello World! 我们通过创建一个简单的模块 ...
- C学习笔记-指针
指针的概念 指针也是一个变量,指针变量的值是另一个变量的地址 换句话说就是,指针存放的是一个内存地址,该地址指向另一块内存空间 指针变量的定义 指向一个变量的变量 int *p = NULL; p = ...
- 在C语言中函数及其调用过程
目录 函数 C语言中的变参函数 函数的本质是什么 内存区域的区分技巧 函数的调用过程 栈帧的概念 调用过程细节 按照约定传参 函数 如果一个函数有声明没实现,那么就会出现链接错误: 以上代码会出现链接 ...
- python 爬虫 基于requests模块发起ajax的get请求
基于requests模块发起ajax的get请求 需求:爬取豆瓣电影分类排行榜 https://movie.douban.com/中的电影详情数据 用抓包工具捉取 使用ajax加载页面的请求 鼠标往下 ...
- Laravel NPM包的使用
示例:安装sweetalert插件 1.yarn add sweetalert 2.resources/js/bootstrap.js中引入: require('sweetalert'); $(doc ...
- MSF魔鬼训练营-3.2.2 操作系统辨识
利用操作系统视频进行社会工程学攻击.例如在探测到目标用户所使用的网络设备.服务器设备厂家型号等信息后.可伪装成相关厂家的技术人员通过电话.邮件等方式与系统管理员取得联系得到信任.NMAP 示例: 使用 ...
- 熟悉GitHub、VS工具的使用(《构建之法》第二次作业)
GIT地址 https://github.com/slothph GIT用户名 slothph 学号后五位 62323 博客地址 https://www.cnblogs.com/slothph/ ...
- Shell初学(五)bash shell的基本功能
记住,所谓的bash shell 并不单纯指的是shell脚本,其实是Linux系统的所有指令集. shell脚本 只是汇总了指令集到文件,然后按流程和顺序执行. [1]如何查看我们的预设shell ...
- CF949E Binary Cards 题解
题面 首先发现:一个数最多会出现1次: 然后深入推出:一个数不会既用它又用它的相反数: 这样就可以依次考虑每一位了: 如果所有的数都不含有这一位,那么就直接把所有的数除以2 如果含有,那么就减去这一位 ...