网络爬虫之Selenium模块和Xpath表达式+Lxml解析库的使用
实际生产环境下,我们一般使用lxml的xpath来解析出我们想要的数据,本篇博客将重点整理Selenium和Xpath表达式,关于CSS选择器,将另外再整理一篇!
一.介绍:
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如跳转、输入、点击、下拉等,来拿到网页渲染之后的结果,可支持多种浏览器 from selenium import webdriver
browser=webdriver.Chrome()
browser=webdriver.Firefox()
browser=webdriver.PhantomJS()
browser=webdriver.Safari()
browser=webdriver.Edge()
可以参考Selenium的官方地址:http://selenium-python.readthedocs.io
二 安装
#安装:selenium+chromedriver
#安装:selenium+chromedriver
pip3 install selenium
下载chromdriver.exe放到python安装路径的Scripts目录中即可,
去官网下载最新的版本:https://sites.google.com/a/chromium.org/chromedriver/downloads
目前最新的是2.35版本;下载解压后,将Python的Scripts目录安装到系统的环境变量下,然后进行验证: #验证安装
C:\Users\Administrator>python3
Python 3.6. (v3.6.1:69c0db5, Mar , ::) [MSC v. bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> from selenium import webdriver
>>> driver=webdriver.Chrome() #弹出浏览器
>>> driver.get('https://www.baidu.com')
>>> driver.page_source
可以看到这里就打印了百度首页的网页源代码 #注意:
selenium3默认支持的webdriver是Firfox,而Firefox需要安装geckodriver
下载链接:https://github.com/mozilla/geckodriver/releases
#安装:selenium+phantomjs
.phantomjs:无界面的浏览器。在做爬虫时,使用selenium库需要打开一个浏览器,这样做有点繁琐。因此我们可以使用phantomjs。它会在后台静默地运行。google找到其官网,下载windows2..1版本:http://phantomjs.org/download.html。
解压后放到:D:\Software\phantomjs-2.1.-windows,同时
将其bin目录D:\Software\phantomjs-2.1.-windows\bin\ 配置到环境变量中,bin目录下存在一个phantomjs.exe文件。 重新打开cmd命令行,输入phantomjs,如下:
#验证安装
C:\Users\Administrator>phantomjs
phantomjs> console.log('egon gaga')
egon gaga
undefined
phantomjs> ^C
C:\Users\Administrator>python3
Python 3.6. (v3.6.1:69c0db5, Mar , ::) [MSC v. bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> from selenium import webdriver
>>> driver=webdriver.PhantomJS() #无界面浏览器
>>> driver.get('https://www.baidu.com')
>>> driver.page_source
三.Selenium的基本使用:
# _*_ coding:utf-8 _*_
import time from selenium import webdriver
from selenium.webdriver.common.by import By # 按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.keys import Keys # 键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait # 等待页面加载某些元素 browser = webdriver.Chrome()
wait = WebDriverWait(browser, 3) # 这里我们以百度为例进行说明:
def base_search():
try:
browser.get('https://www.baidu.com') input_tag = browser.find_element_by_id('kw') # 找到百度的输入框
input_tag.send_keys('美女') # python2中输入中文错误,字符串前加个u
input_tag.send_keys(Keys.ENTER) # 输入回车 # 只有等相应的JS代码都加载完毕后,我们才能执行点击操作
wait.until(EC.presence_of_element_located((By.ID, 'content_left'))) # 等到id为content_left的元素加载完毕,最多等10秒
print(browser.page_source)
print(browser.current_url)
print(browser.get_cookies())
time.sleep(3) # 当打印完结果后,睡眠3秒后再关闭浏览器
except TimeoutException: # 防止由于网络原因终端而退出程序运行,所以当产生TimeoutException时直接进行重试
base_search()
finally:
browser.close() def main():
base_search() if __name__ == '__main__':
main()
四.Selenium选择器的基本用法:这里一般都使用在测试开发中,我们一般使用xpath表达式或者CSS选择器来提取数据
# _*_ coding:utf-8 _*_ # 官网链接:http://selenium-python.readthedocs.io/locating-elements.html
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By # 按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys # 键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait # 等待页面加载某些元素
import time driver = webdriver.Chrome()
driver.get('https://www.baidu.com')
wait = WebDriverWait(driver, 5) try:
# ===============所有方法===================
# 1、find_element_by_id
# 2、find_element_by_link_text
# 3、find_element_by_partial_link_text
# 4、find_element_by_tag_name
# 5、find_element_by_class_name
# 6、find_element_by_name
# 7、find_element_by_css_selector
# 8、find_element_by_xpath
# 强调:
# 1、上述均可以改写成find_element(By.ID,'kw')的形式
# 2、find_elements_by_xxx的形式是查找到多个元素,结果为列表 # ===============示范用法===================
# 1、find_element_by_id # 通过标签的ID选择器来定位到标签
# input_tag = driver.find_element_by_id('kw')
# print(input_tag)
# print(input_tag.tag_name) # 获取标签对象的标签名:input
# print(input_tag.get_attribute('name')) # 获取标签的属性name对应的值:wd
# print(input_tag.text) # 获取selenium标签对象input的文本值,这里没有所以为空 """
input_tag是一个selenium对象:
<selenium.webdriver.remote.webelement.WebElement (session="29df7320e42faefe9963e1e1bce028ca", element="0.2962884279499578-1")>
""" # 2、find_element_by_link_text 通过标签修饰的文本来查找标签对象
# 例如通过文本内容'登入'两个字找到百度的登入标签,然后点击
login = driver.find_element_by_link_text('登录')
login.click() # # 3、find_element_by_partial_link_text 通过文本的一部分来定位标签对象
# login = driver.find_elements_by_partial_link_text('录')[0]
# login.click()
#
# # 4、find_element_by_tag_name # 通过标签名来定位到标签对象
# print(driver.find_element_by_tag_name('a'))
# # # 5、find_element_by_class_name 通过标签的类选择器名称来定位到标签对象
# login_for_user=driver.find_element_by_class_name('tang-pass-footerBarULogin')
"""
通过这种方法presence_of_element_located会提示错误:
selenium.common.exceptions.TimeoutException: Message:
那是因为此时找到的login_for_user是一个P标签,还不能点击,所以我们需要等待js代码加载完毕后再
点击,因此使用方法element_to_be_clickable,让标签对象是可点击的
"""
# login_for_user = wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'tang-pass-footerBarULogin')))
# login_for_user.click() """
使用element_to_be_clickable方法,结合上面的方法一起使用即可
"""
login = driver.find_element_by_link_text('登录')
login.click()
login_for_user = wait.until(EC.element_to_be_clickable((By.CLASS_NAME, 'tang-pass-footerBarULogin')))
print(login_for_user)
login_for_user.click() # # 6、find_element_by_name
"""
通过input标签的name属性定位到用户名和密码输入框,这里使用的是By.NAME
"""
input_user = driver.find_element_by_name("userName")
# input_user = wait.until(EC.presence_of_element_located((By.NAME, 'userName')))
input_pwd = wait.until(EC.presence_of_element_located((By.NAME, 'password')))
# 同样当点击提交按钮时,我们也需要设置让它等待相关的JS代码加载完毕后再点击,因此使用的是element_to_be_clickable方法
commit = wait.until(EC.element_to_be_clickable((By.ID, 'TANGRAM__PSP_10__submit'))) input_user.send_keys('scalerlove')
input_pwd.send_keys('187894Love')
commit.click() #
# # 7、find_element_by_css_selector
"""
通过css选择器来定位标签元素
例如我通过百度首页的input输入框的id选择器来定位到input输入框
"""
driver.find_element_by_css_selector('#kw')
time.sleep(2)
finally:
driver.close()
五.Xpath表达式
在解析数据时,我们通常使用的是lxml解析库,因为它是使用C语言开发的,lxml使用的是Xpath表达式。关于具体的使用方法,可以参考如下的官网地址,本文仅仅是做出中文翻译,并结合自己的使用:
http://lxml.de/index.html
http://www.w3school.com.cn/xpath/index.asp
首先看如下的HTML代码:
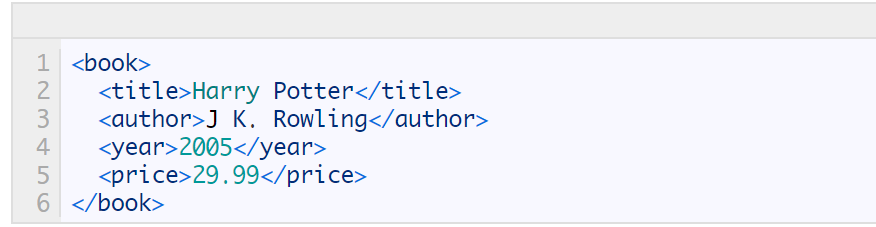
选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
下面列出了最有用的路径表达式:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
实例
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| bookstore | 选取 bookstore 元素的所有子节点。 |
| /bookstore | 选取根元素 bookstore。注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
很多人容易将//和/搞混淆:
例如//表示选取所有的book子元素,不管它们在文档中的位置,而bookstore/book表示选取bookstore元素下面的第一个book子元素
谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。
谓语被嵌在方括号中。
实例
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素,因为book元素可能有多个 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()<3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素,而不管这个title标签在哪 |
| //title[@lang=’eng’] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] |
选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 可以猜出来这里的price是自定义属性 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
实例
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
|---|---|
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
Lxml基本用法:
# _*_ coding:utf-8 _*_ from lxml import etree
text = """
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-2"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
"""
html = etree.HTML(text)
print(html)
print("===>>>>>>")
result = etree.tostring(html)
print(result) # 字节字符串
首先我们使用 lxml 的 etree 库,然后利用 etree.HTML 初始化,然后我们将其打印出来。
其中,这里体现了 lxml 的一个非常实用的功能就是自动修正 html 代码,大家应该注意到了,最后一个 li 标签,其实我把尾标签删掉了,是不闭合的。不过,lxml 因为继承了 libxml2 的特性,具有自动修正 HTML 代码的功能。通过最终的结果可知,它还补全了body标签和html标签
文件读取
除了直接读取字符串,还支持从文件读取内容。比如我们新建一个文件叫做 hello.html,内容为
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-2"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
利用 parse 方法来读取文件:
from lxml import etree
html = etree.parse('hello.html')
result = etree.tostring(html, pretty_print=True)
print(result)
XPath实例测试
依然以上一段程序为例
(1)获取所有的 <li> 标签
from lxml import etree
# 获取所有的li标签
html = etree.parse('hello.html')
print(type(html))
result = html.xpath('//li')
print(result)
print(len(result))
print(type(result))
print(type(result[0]))
打印结果如下:
<class 'lxml.etree._ElementTree'>
[<Element li at 0x18f0077b2c8>, <Element li at 0x18f0077b288>, <Element li at 0x18f0077b308>, <Element li at 0x18f0077b348>, <Element li at 0x18f0077b388>]
5
<class 'list'>
<class 'lxml.etree._Element'>
可见,etree.parse 的类型是 ElementTree,通过调用 xpath 以后,得到了一个列表,包含了 5 个 <li> 元素,每个元素都是 Element 类型。
(2)获取 <li> 标签的所有 class
from lxml import etree
# 获取 所有<li> 标签的所有class选择器的值
html = etree.parse('hello.html')
result = html.xpath('//li/@class')
print(result) # 结果是一个列表
打印结果如下:
['item-0', 'item-2', 'item-inactive', 'item-1', 'item-0']
(3)获取 <li> 标签下 href 为 link1.html 的 <a> 标签
from lxml import etree
# 获取 所有<li> 标签的所有class选择器的值
html = etree.parse('hello.html')
result = html.xpath('//li/a[@href="link1.html"]')
print(result) # 结果如下:
[<Element a at 0x182e0eec2c8>]
(4)获取 <li> 标签下的所有 <span> 标签
from lxml import etree
# 获取 <li> 标签下的所有 <span> 标签
html = etree.parse('hello.html')
result = html.xpath('//li/span')
print(result) # 结果如下:[]
上面之所以得到的结果为空是因为/是用来获取直接子元素的,而span标签并不是li标签的直接子元素,所以应该使用//,如下:
from lxml import etree
# 获取 <li> 标签下的所有 <span> 标签
html = etree.parse('hello.html')
result = html.xpath('//li//span')
print(result) # 结果如下:
(5)获取 <li> 标签下的所有 class,但是不包括 <li>标签的class
from lxml import etree
# (5)获取 <li> 标签下的所有 class,不包括 <li>
html = etree.parse('hello.html')
result = html.xpath('//li/a//@class')
print(result) # 结果如下:
from lxml import etree
#(6)获取最后一个 <li> 的 <a> 的 href
html = etree.parse('hello.html')
result = html.xpath('//li[last()]/a/@href')
print(result) # 结果如下:
# ['link5.html']
(7) 获取 class 为 bold 的标签名
from lxml import etree
# (8)获取 class 为 bold 的标签名,这里没有指定是哪个标签,因此默认就是寻找所有的标签,所以使用*
html = etree.parse('hello.html')
result = html.xpath('//*[@class="bold"]')
print(result)
print(result[0].text) # 结果如下:
print(result[0].tag)
运行结果如下:
[<Element span at 0x20b1325b288>]
third item
span
<Element span at 0x20b1325b288>
五.最后我们来看看Selenium中Xpath表达式的运用
<html>
<head>
<base href='http://example.com/' />
<title>Example website</title>
</head>
<body>
<div id='images'>
<a href='image1.html'>Name: My image 1 <br /><img src='image1_thumb.jpg' /></a>
<a href='image2.html'>Name: My image 2 <br /><img src='image2_thumb.jpg' /></a>
<a href='image3.html'>Name: My image 3 <br /><img src='image3_thumb.jpg' /></a>
<a href='image4.html'>Name: My image 4 <br /><img src='image4_thumb.jpg' /></a>
<a href='image5.html'>Name: My image 5 <br /><img src='image5_thumb.jpg' /></a>
</div>
</body>
</html>
源代码和需求如下:
# Xpath选择器
from selenium import webdriver
import time driver = webdriver.Chrome()
# wait = WebDriverWait(driver, 3)
driver.implicitly_wait(3) try:
driver.get('https://doc.scrapy.org/en/latest/_static/selectors-sample1.html')
# 1、//与/
"""
注意这里不能使用# driver.find_element_by_xpath('//body/a')
因为a标签不是body标签的直接儿子元素,所以找不到
# 开头的//代表从整篇文档中寻找,body之后的/代表body的儿子,这一行找不到就会报错了
"""
# tag = driver.find_element_by_xpath('/html/body/div/a')
# print(tag)
"""
由于使用的是element,所以这里的tag就是一个Selenium对象,如下:
<selenium.webdriver.remote.webelement.WebElement (session="2e1465949860c584e3c5f28671fcff1c", element="0.68193719522997-1")>
"""
# print(tag.tag_name)
# print(tag.text)
# print(tag.get_attribute('href')) """
下面使用find_elements_by_xpath方法,上面是element寻找单个元素
这里是在整篇文档中寻找所有的a标签
"""
# tags=driver.find_elements_by_xpath('//a')
# print(tags)
# """
# 由于使用的是elements,所以这里的tag就是一个由Selenium对象组成的列表,如下:
# 由于我们是寻找所有的a标签,所以这里的tags是由五个a标签Selenium对象组成的列表
# """
# print(tags[0].tag_name) # 获取标签的名称
# print(tags[0].text) # 获取标签的文本
# print(tags[0].get_attribute('href')) # 获取标签的href属性对应的值 # 找到div标签下面的所有a标签
# tag = driver.find_elements_by_xpath('//div//a')
# tag = driver.find_elements_by_css_selector('div a')
# print(len(tag)) # 2、查找第几个
"""
注意这里不是索引,而是直接从1开始,找第5个a标签就是5,找第一个就是1
"""
# tag=driver.find_elements_by_xpath('//div//a[5]')
# print(tag[0].text) # 3、按照属性查找
# 查找href属性值等于image4.html的a标签
# tag1=driver.find_element_by_xpath('//a[@href="image4.html"]')
# 查找第4个a标签
# tag2=driver.find_element_by_xpath('//a[4]')
# print(tag2.get_attribute("href")) # http://example.com/image4.html # 模糊匹配,查找href属性中包含image4的所有a标签
# tag3=driver.find_element_by_xpath('//a[contains(@href,"image4")]')
# print(tag3.text)
# # 4、获取class属性为xxxxx的所有标签
# driver.find_elements_by_xpath('//*[@class="xxxxx"]')
# 获取class属性为xxxxx而且class属性包含yyyyy的div标签
# driver.find_elements_by_xpath('//div[@class="xxxxx"][@class="yyyyy"]') # 查看属性name为continue且属性type为button的input标签
# print(driver.find_element_by_xpath('//input[@name="continue"][@type="button"]'))
#
# # 查看属性name为continue且属性type为button的所有标签
# print(driver.find_element_by_xpath('//*[@name="continue"][@type="button"]'))
#
# # 找到子标签img的src属性为image3_thumb.jpg的a标签
# print(driver.find_element_by_xpath('//a[img/@src="data:image2_thumb.jpg"]').text) # 查找所有a标签的上级标签的标签名 div
# print(driver.find_element_by_xpath('//a/..').tag_name) # 查找所有img标签的父级标签中的href属性,结果是一个列表
# print([tag.get_attribute("href") for tag in driver.find_elements_by_xpath('//img//..')]) # 寻找所有的img标签
img = driver.find_element_by_xpath('//img')
print(img.location) # {'y': 45, 'x': 8} 图片在整个页面中的x和y坐标
print(img.size) # {'height': 0, 'width': 0} 获取图片的高度和宽度
time.sleep(2)
finally:
driver.close()
注意:在上面我们使用了隐式等待
driver.implicitly_wait(3)
六.等待
#1、selenium只是模拟浏览器的行为,而浏览器解析页面是需要时间的(执行css,js),一些元素可能需要过一段时间才能加载出来,为了保证能查找到元素,必须等待 #2、等待的方式分两种:
隐式等待:在browser.get('xxx')前就设置,针对所有元素有效
显式等待:在browser.get('xxx')之后设置,只针对某个元素有效
示例如下:
百度查找美女关键词,隐式等待:
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys #键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素 browser=webdriver.Chrome() #隐式等待:在查找所有元素时,如果尚未被加载,则等10秒
browser.implicitly_wait(10) browser.get('https://www.baidu.com') input_tag=browser.find_element_by_id('kw')
input_tag.send_keys('美女')
input_tag.send_keys(Keys.ENTER)
# 由于设置了隐式等待,所以这里直接使用brower寻找标签
contents=browser.find_element_by_id('content_left') #没有等待环节而直接查找,找不到则会报错
print(contents) browser.close()
百度查找关键词显示等待
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys #键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素 browser=webdriver.Chrome()
browser.get('https://www.baidu.com') input_tag=browser.find_element_by_id('kw')
input_tag.send_keys('美女')
input_tag.send_keys(Keys.ENTER) #显式等待:显式地等待某个元素被加载
wait=WebDriverWait(browser,10)
wait.until(EC.presence_of_element_located((By.ID,'content_left'))) contents=browser.find_element(By.CSS_SELECTOR,'#content_left')
print(contents)
browser.close()
模拟浏览器的行动链,破解滑动验证码有效,来看下面的代码:
最终的实现效果如下图所示:

代码如下所示,首先分析网页:
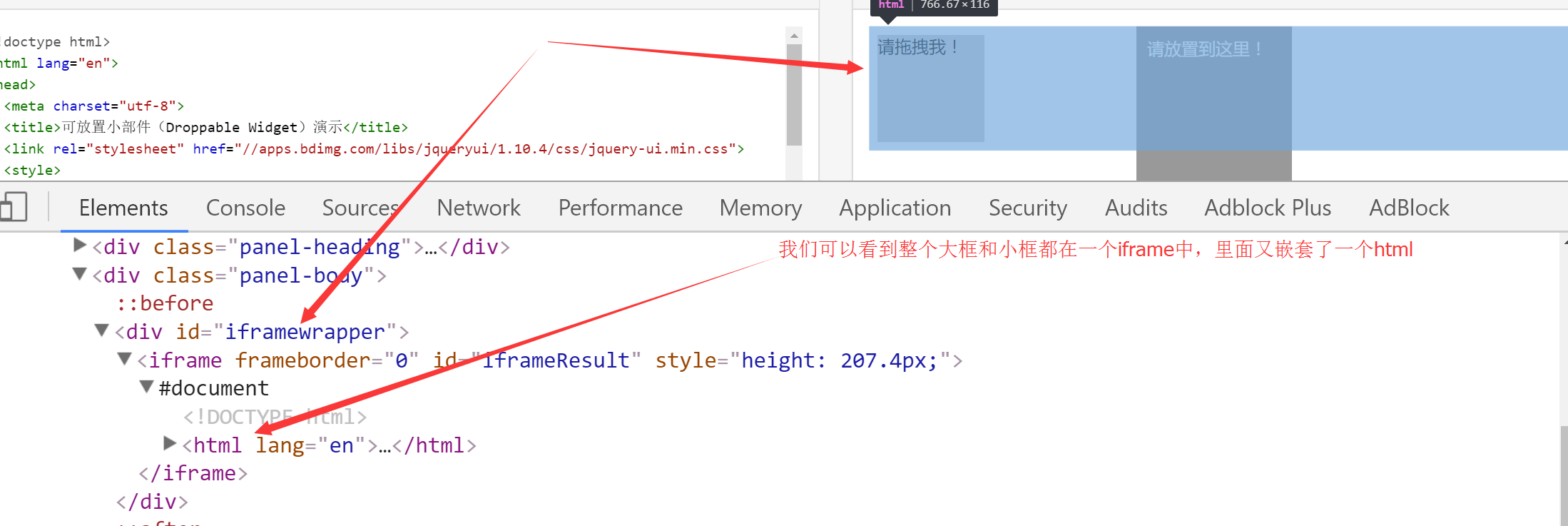
因此最终的代码如下所示:
# _*_ coding:utf-8 _*_ from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By # 按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys # 键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait # 等待页面加载某些元素
import time driver = webdriver.Chrome()
driver.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
wait = WebDriverWait(driver, 3)
# driver.implicitly_wait(3) # 使用隐式等待 try:
# 首先定位到大框和小框,它们都位于一个iframe中
driver.switch_to.frame('iframeResult') ##切换到iframeResult
# 找到滑动验证的原始框:source
sourse = driver.find_element_by_id('draggable')
# 找到滑动验证的目标框:大框
target = driver.find_element_by_id('droppable') # 方式一:基于同一个动作链串行执行
# actions=ActionChains(driver) #拿到动作链对象
# actions.drag_and_drop(sourse,target) #把动作放到动作链中,准备串行执行
# actions.perform() # 方式二:不同的动作链,每次移动的位移都不同
"""
点击,并且按住,然后拖动,所以这里是click_and_hold,然后perform """
ActionChains(driver).click_and_hold(sourse).perform()
"""
使用目标大框的x坐标-原始小框的x坐标得到的就是小框要移动的距离
"""
distance = target.location['x'] - sourse.location['x'] """
定义一个移动距离,从0开始,每次x轴的水平移动距离xoffset=2
因此这里是通过move_by_offset按照步长来移动,然后执行perform
一定要执行perform,表示从源头向目标端移动
当最终的移动距离大于小框要移动的距离时,意味着小框已经在大框里面
然后释放鼠标
"""
track = 0
while track < distance:
ActionChains(driver).move_by_offset(xoffset=2, yoffset=0).perform()
track += 2 # 释放鼠标
ActionChains(driver).release().perform() time.sleep(10) finally:
driver.close()
七.模拟浏览器的前进和后退
# _*_ coding:utf-8 _*_ # 模拟浏览器的前进后退
import time
from selenium import webdriver browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.get('https://www.taobao.com')
browser.get('http://www.sina.com.cn/') browser.back()
time.sleep(10)
browser.forward()
browser.close()
网络爬虫之Selenium模块和Xpath表达式+Lxml解析库的使用的更多相关文章
- python爬虫中XPath和lxml解析库
什么是XML XML 指可扩展标记语言(EXtensible Markup Language) XML 是一种标记语言,很类似 HTML XML 的设计宗旨是传输数据,而非显示数据 XML 的标签需要 ...
- 爬虫之selenium模块
Selenium 简介 selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟 ...
- 三: 爬虫之selenium模块
一 selenium模块 什么是selenium?selenium是Python的一个第三方库,对外提供的接口可以操作浏览器,然后让浏览器完成自动化的操作. selenium最初是一个自动化测试工具, ...
- 3、爬虫之selenium模块
一 selenium模块 什么是selenium?selenium是Python的一个第三方库,对外提供的接口可以操作浏览器,然后让浏览器完成自动化的操作. selenium最初是一个自动化测试工具, ...
- 06.Python网络爬虫之requests模块(2)
今日内容 session处理cookie proxies参数设置请求代理ip 基于线程池的数据爬取 知识点回顾 xpath的解析流程 bs4的解析流程 常用xpath表达式 常用bs4解析方法 引入 ...
- Python网络爬虫之requests模块(2)
session处理cookie proxies参数设置请求代理ip 基于线程池的数据爬取 xpath的解析流程 bs4的解析流程 常用xpath表达式 常用bs4解析方法 引入 有些时候,我们在使用爬 ...
- Python网络爬虫之requests模块
今日内容 session处理cookie proxies参数设置请求代理ip 基于线程池的数据爬取 知识点回顾 xpath的解析流程 bs4的解析流程 常用xpath表达式 常用bs4解析方法 引入 ...
- 爬虫之 selenium模块
selenium模块 阅读目录 一 介绍 二 安装 三 基本使用 四 选择器 五 等待元素被加载 六 元素交互操作 七 其他 八 项目练习 一 介绍 selenium最初是一个自动化测试工具,而爬 ...
- 动态渲染页面爬取(Python 网络爬虫) ---Selenium的使用
Selenium 的使用 Selenium 是一个自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击.下拉等操作,同时还可以获取浏览器当前呈现的页面的源代码,做到可见即可爬.对于一些JavaS ...
随机推荐
- Solidworks做镜像 导致厚度为零的几何体怎么办
如下图所示,我想把1,2,3,4架子做一个镜像,但是提示错误 貌似只能用镜像实体,并且取消勾选"合并实体"
- android menu事件
@Override public boolean onCreateOptionsMenu(Menu menu) { menu.add(0,1,1,R.string.exit); menu.add(0, ...
- 【转载】java sleep和wait的区别的疑惑?
首先,要记住这个差别,"sleep是Thread类的方法,wait是Object类中定义的方法".尽管这两个方法都会影响线程的执行行为,但是本质上是有区别的. Thread.sle ...
- 【转载】轻松搞懂WebService工作原理
用更简单的方式给大家谈谈WebService,让你更快更容易理解,希望对初学者有所帮助. WebService是基于网络的.分布式的模块化组件. 我们直接来看WebService的一个简易工作流程: ...
- extjs 4 checkboxgroup Panel的简单用法
Ext.require([ 'Ext.tree.*', 'Ext.data.*', 'Ext.window.MessageBox', 'Ext.tip.*' ]); Ext.onReady(funct ...
- 超全!整理常用的iOS第三方资源(转)
超全!整理常用的iOS第三方资源 一:第三方插件 1:基于响应式编程思想的oc 地址:https://github.com/ReactiveCocoa/ReactiveCocoa 2:hud提示框 地 ...
- Mac OS X 开发环境搭建之利用 Parallel Desktop 安装 CentOS 7 [转载]
背景 在企业级软件系统中,数据库的地位是比较高的,而且一般都要求支持多种数据库,如 Oracle. DB2.MySQL 等,它们的最新版本大多都不再支持 Mac OS X 系统,所以装一个 Linux ...
- YTU 2578: 分数减法——结构体
2578: 分数减法--结构体 时间限制: 1 Sec 内存限制: 128 MB 提交: 522 解决: 399 题目描述 分数可以看成是由字符'/'分割两个整数构成,可以用结构体类型表示.请用结 ...
- java基础知识一
1.计算机基础知识概述 (1) 计算机 计算机(computer)俗称电脑,是一种用于高速计算的电子计算机器,可以进行数值计算,又可以进行逻辑计算,还具有存储记忆功能.是能够按照程序运行,自动.高速处 ...
- poj 2771 Guardian of Decency 解题报告
题目链接:http://poj.org/problem?id=2771 题目意思:有一个保守的老师要带他的学生来一次短途旅行,但是他又害怕有些人会变成情侣关系,于是就想出了一个方法: 1.身高差距 ...