Python学习【第6篇】:Python之常用模块1
collocations 模块
时间模块
random模块
os模块
sys模块
序列化模块
re模块
常用模块二:这些模块和面向对象有关
hashlib模块
configparse模块
logging模块
三、正则表达式
像我们平常见的那些注册页面啥的,都需要我们输入手机号码吧,你想我们的电话号码也是有限定的吧(手机号码一共11位,并且只以13,14,15,17,18开头的数字这些特点)如果你的输入有误就会提示,那么实现这个程序的话你觉得用While循环so easy嘛,那么我们来看看实现的结果
import re
phone_number=input('请输入你的电话号码:')
if re.match('^(13|14|15|17|18)[0-9]{9}$',phone_number):
'''^这个符号表示的是判断是不是以13|14|15|17|18开头的,
[0-9]: []表示一个字符组,可以表示0-9的任意字符
{9}:表示后面的数字重复九次
$:表示结束符
'''
print('是合法的手机号码')
else:
print('不是合法的手机号码') 判断手机号码输入是否合法
那么什么是正则呢?
首先你要知道的是,谈到正则,就只和字符串相关了。在线测试工具 http://tool.chinaz.com/regex/
比如你要用‘1’去匹配‘1’,或者用‘2’去匹配‘2’,直接就可以匹配上。
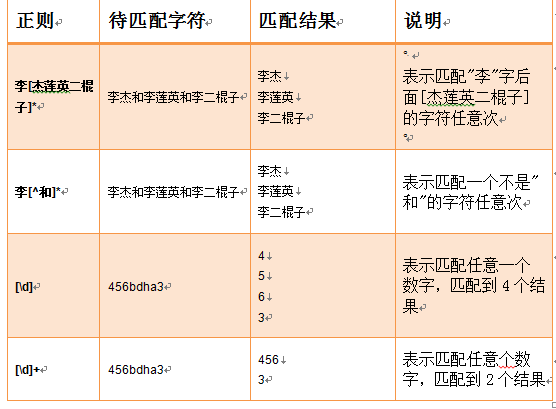
字符组:[字符组]
在同一位置可能出现的各种字符组成了一个字符组,在正则表达式中用[]表示
字符分为很多类,比如数字,字母,标点等登。
假如你现在要求一个位置‘只能出现一个数字’,那么这个位置上的字符只能是0、1、2、3.......9这是个数之一。
字符组:

字符:

量词:
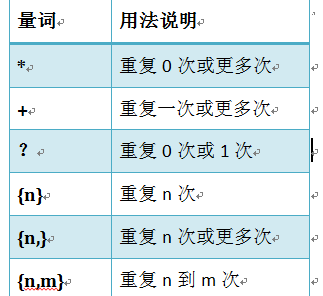
.^$

*+?{}

注意:前面的*,+,?等都是贪婪匹配,也就是尽可能多的匹配,后面加?就变成了非贪婪匹配,也就是惰性匹配。
贪婪匹配:

几个常用的配贪婪匹配
|
1
2
3
4
5
|
*?;重复任意次,但尽可能少重复+?:重复一次或更多次,但尽可能少重复??:重复0次或1次,但尽可能少重复{n,m}:重复n到m次,但尽可能少重复{n,}: 重复n次以上,但尽可能少重复 |
.*?的用法:
|
1
2
3
4
5
6
|
.是任意字符*是取0到无限长度?是非贪婪模式和在一起就是取尽量少的任意字符,一般不会这么单独写,大多用在:.*?x意思就是取前面任意长度的字符,直到一个x出现 |
字符集:

举个例子,比如html源码中有<title>xxx</title>标签,用以前的知识,我们只能确定源码中的<title>和</title>是固定不变的。因此,如果想获取页面标题(xxx),充其量只能写一个类似于这样的表达式:<title>.*</title>,而这样写匹配出来的是完整的<title>xxx</title>标签,并不是单纯的页面标题xxx。
想解决以上问题,就要用到断言知识。
在讲断言之前,读者应该先了解分组,这有助于理解断言。
分组在正则中用()表示,根据小菜理解,分组的作用有两个:
n 将某些规律看成是一组,然后进行组级别的重复,可以得到意想不到的效果。
n 分组之后,可以通过后向引用简化表达式。
先来看第一个作用,对于IP地址的匹配,简单的可以写为如下形式:
\d{1,3}.\d{1,3}.\d{1,3}.\d{1,3}
但仔细观察,我们可以发现一定的规律,可以把.\d{1,3}看成一个整体,也就是把他们看成一组,再把这个组重复3次即可。表达式如下:
\d{1,3}(.\d{1,3}){3}
这样一看,就比较简洁了。
再来看第二个作用,就拿匹配<title>xxx</title>标签来说,简单的正则可以这样写:
<title>.*</title>
可以看出,上边表达式中有两个title,完全一样,其实可以通过分组简写。表达式如下:
<(title)>.*</\1>
这个例子实际上就是反向引用的实际应用。对于分组而言,整个表达式永远算作第0组,在本例中,第0组是<(title)>.*</\1>,然后从左到右,依次为分组编号,因此,(title)是第1组。
用\1这种语法,可以引用某组的文本内容,\1当然就是引用第1组的文本内容了,这样一来,就可以简化正则表达式,只写一次title,把它放在组里,然后在后边引用即可。
以此为启发,我们可不可以简化刚刚的IP地址正则表达式呢?原来的表达式为\d{1,3}(.\d{1,3}){3},里边的\d{1,3}重复了两次,如果利用后向引用简化,表达式如下:
(\d{1,3})(.\1){3}
简单的解释下,把\d{1,3}放在一组里,表示为(\d{1,3}),它是第1组,(.\1)是第2组,在第2组里通过\1语法,后向引用了第1组的文本内容。
经过实际测试,会发现这样写是错误的,为什么呢?
小菜一直在强调,后向引用,引用的仅仅是文本内容,而不是正则表达式!
也就是说,组中的内容一旦匹配成功,后向引用,引用的就是匹配成功后的内容,引用的是结果,而不是表达式。
因此,(\d{1,3})(.\1){3}这个表达式实际上匹配的是四个数都相同的IP地址,比如:123.123.123.123。
至此,读者已经掌握了传说中的后向引用,就这么简单。
对于分组的理解
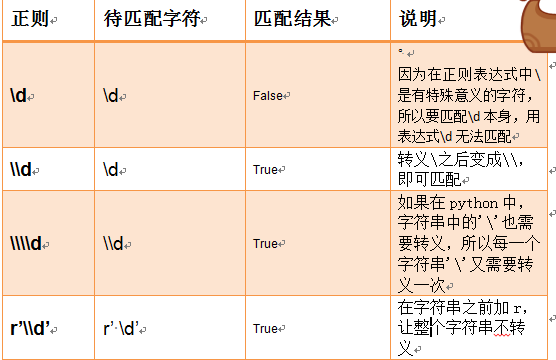
import re
import re
ret=re.search('<(\w+)>\w+<(/\w+)>','<h1>hello</h1>')
print(ret.group())
# 给分组起个名字。就用下面的分组命名,上面的方法和下面的分组命名是一样的,只不过就是给命了个名字
ret=re.search('<(?P<tag_name>\w+)>\w+</(?P=tag_name)>','<h1>hello</h1>') #(?P=tag_name)就代表的是(\w+)
print(ret.group()) # 了解(和上面的是一样的,是上面方式的那种简写)
ret=re.search(r'<(\w+)>\w+</\1>','<h1>hello</h1>')
print(ret.group(1))
四、re模块
# 1.re模块下的常用方法
# 1.findall方法
import re
ret = re.findall('a','eva ang egons')
# #返回所有满足匹配条件的结果,放在列表里
print(ret) # 2.search方法
# 函数会在字符串中查找模式匹配,只会找到第一个匹配然后返回
# 一个包含匹配信息的对象,该对象通过调用group()方法得到匹配的
# 字符串,如果字符串没有匹配,则报错
ret = re.search('s','eva ang egons')#找第一个
print(ret.group()) # 3.match方法
print(re.match('a','abc').group())
#同search,只从字符串开始匹配,并且guoup才能找到 # 4.split方法
print(re.split('[ab]','abcd'))
#先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割 # 5.sub方法
print(re.sub('\d','H','eva3sdf4ahi4asd45',1))
# 将数字替换成'H',参数1表示只替换一个 # 6.subn方法
print(re.subn('\d','H','eva3sdf4ahi4asd45'))
#将数字替换成’H‘,返回元组(替换的结果,替换了多少次) # 7.compile方法
obj = re.compile('\d{3}')#将正则表达式编译成一个正则表达式对象,规则要匹配的是三个数字
print(obj)
ret = obj.search('abc12345eeeee')#正则表达式对象调用search,参数为待匹配的字符串
print(ret.group()) #.group一下就显示出结果了 # 8.finditer方法
ret = re.finditer('\d','dsf546sfsc')#finditer返回的是一个存放匹配结果的迭代器
# print(ret)#<callable_iterator object at 0x00000000021E9E80>
print(next(ret).group())#查看第一个结果
print(next(ret).group())#查看第二个结果
print([i.group() for i in ret] )#查看剩余的左右结果 re模块相关的方法
import re
ret = re.findall('www.(baidu|oldboy).com','www.oldboy.com')
print(ret) #结果是['oldboy']这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可 ret = re.findall('www.(?:baidu|oldboy).com','www.oldboy.com')
print(ret) #['www.oldboy.com'
findall高级查询
ret = re.split('\d+','eva123dasda9dg')#按数字分割开了
print(ret) #输出结果:['eva', 'dasda', 'dg']
ret = re.split('(\d+)','eva123dasda9dg')
print(ret) #输出结果:['eva', '123', 'dasda', '9', 'dg']
#
# 在匹配部分加上()之后和不加括号切出的结果是不同的,
# 没有括号的没有保留所匹配的项,但是有括号的却能够保留了
# 匹配的项,这个在某些需要保留匹配部分的使用过程是非常重要的
split的优先级查询
random模块
random.random()#用于生成一个0到1的随机浮点数: 0 <= n < 1.0
random.uniform(a,b) #生成有范围的浮点数
random.randint(a,b)#生成有范围的整数
random.randrange(10, 100, 2),结果相当于从[10, 12, 14, 16, ... 96, 98]序列中获取一个随机数
random.choice从序列中获取一个随机元素
random.shuffle
random.shuffle的函数原型为:random.shuffle(x[, random]),用于将一个列表中的元素打乱。如:
p = ["Python", "is", "powerful", "simple", "and so on..."] random.shuffle(p) print p #---- 结果(不同机器上的结果可能不一样。) #['powerful', 'simple', 'is', 'Python', 'and so on...']
random.sample
从指定序列中随机获取指定长度的片断。sample函数不会修改原有序列。
list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] slice = random.sample(list, 5) #从list中随机获取5个元素,作为一个片断返回 print slice print list #原有序列并没有改变。
随机整数:
随机选取0到100间的偶数:
随机浮点数:
随机字符:
多个字符中选取特定数量的字符:
多个字符中选取特定数量的字符组成新字符串:
随机选取字符串:
洗牌:
随机生成一个手机号
import random
a=random.choice(['','','','','','',''])
b=random.sample('',8)
print a+''.join(b)
随机生成一个字符串
b=random.sample('abcdefjhigklmnopqrstuvwxyz',5)
print 'HS'+''.join(b)
生成身份证
def gennerator():
listcode=['','','','','','','','','']#山西省的部分BM
#id = codelist[random.randint(0,len(codelist))]['code'] #地区项
id=random.choice(listcode)
id = id + str(random.randint(1930,2013)) #年份项
da = date.today()+timedelta(days=random.randint(1,366)) #月份和日期项
id = id + da.strftime('%m%d')
id = id+ str(random.randint(100,999))#,顺序号简单处理
i = 0
count = 0
weight = [7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2] #权重项
checkcode ={'':'','':'','':'X','':'','':'','':'','':'','':'','':'','':'','':''} #校验码映射
for i in range(0,len(id)):
count = count +int(id[i])*weight[i]
id = id + checkcode[str(count%11)] #算出校验码
return id
Time
获取当前时间
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
例子
import datetime def get_currentdate(fmt="%Y-%m-%d"): return datetime.datetime.now().strftime(fmt) print(get_currentdate() )
例子
def get_timestamp(str_len=13):
print("get_timestamp")
if isinstance(str_len, int) and 0 < str_len < 17:
return str(time.time()).replace(".", "")[:str_len]
获取随机字符串
def gen_random_string(str_len):
""" generate random string with specified length
"""
print("gen_random_string")
return ''.join(
random.choice(string.ascii_letters + string.digits) for _ in range(str_len))
OS
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.popen("bash command) 运行shell命令,获取执行结果
os.environ 获取系统环境变量 os.path
os.path.abspath(path) 返回path规范化的绝对路径 os.path.split(path) 将path分割成目录和文件名二元组返回 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。
即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) 返回path的大小 os模块常用方法
os用法
注意:os.stat('path\filename') 获取文件\目录信息的结构说明
stat 结构: st_mode: inode 保护模式
st_ino: inode 节点号。
st_dev: inode 驻留的设备。
st_nlink: inode 的链接数。
st_uid: 所有者的用户ID。
st_gid: 所有者的组ID。
st_size: 普通文件以字节为单位的大小;包含等待某些特殊文件的数据。
st_atime: 上次访问的时间。
st_mtime: 最后一次修改的时间。
st_ctime: 由操作系统报告的"ctime"。在某些系统上(如Unix)是最新的元数据更改的时间,<br>在其它系统上(如Windows)是创建时间(详细信息参见平台的文档)。 ststat 结构
os 用于操作系统相关
os.system()
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.path.abspath(path):返回path的绝对路径
BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
获取最新文件
import os
def new_file(test_dir):
#列举test_dir目录下的所有文件(名),结果以列表形式返回。
lists=os.listdir(test_dir)
#sort按key的关键字进行升序排序,lambda的入参fn为lists列表的元素,获取文件的最后修改时间,所以最终以文件时间从小到大排序
#最后对lists元素,按文件修改时间大小从小到大排序。
lists.sort(key=lambda fn:os.path.getmtime(test_dir+'\\'+fn))
#获取最新文件的绝对路径,列表中最后一个值,文件夹+文件名
file_path=os.path.join(test_dir,lists[-1])
return file_path #返回D:\pythontest\ostest下面最新的文件
print new_file('D:\\system files\\workspace\\selenium\\email126pro\\email126\\report')
根据日期获取最新的文件
import os import datetime import time def read(result_dir): l=os.listdir(result_dir) l1=[] l2=[] for i in l: print(i) l1.append(i) st = l.sort(key=lambda fn: os.path.getmtime(result_dir+"\\"+fn) if not os.path.isdir(result_dir+"\\"+fn) else 0) #第二句 d=datetime.datetime.fromtimestamp(os.path.getmtime(result_dir+"\\"+i)) print(d) time_end=time.mktime(d.timetuple()) print(time_end) l2.append(time_end) print (l1[l2.index(max(l2))])
SYS
sys 用于解释器的相关操作
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
sys.stdout.write('please:')
val = sys.stdin.readline()[:-1]
XLRD
导入模块:import
xlrd
打开excel文件读取数据data=xlrd.open_workbook(‘excelfile.xls’)
获取工作表
table=data.sheets()[0]#通过索引顺序获取
table=data.sheet_by_index(0)#通过索引顺序
table=data.sheet_by_name(u’sheet1’)#通过名称
获取整行和整列的值(数组)
table.row_values(i)#行
table.col_values(i)#列
获取行数和列数
nrows=table.nrows#行数
ncols=table.ncols#列数
循环行列表数据
for
i in range(nrows):
print
table.row_values(i)
单元格
cell_A1=table.cell(0,0).value
cell_C4=table.cell(2,3).value
五、序列化模块
1.什么是序列化-------将原本的字典,列表等内容转换成一个字符串的过程就叫做序列化
2.序列化的目的
1.以某种存储形式使自定义对象持久化
2.将对象从一个地方传递到另一个地方
3.使程序更具维护性
json
Json模块提供了四个功能:dumps、loads、dump、load
import json
dic={'k1':'v1','k2':'v2','k3':'v3'}
print(type(dic))
str_dic = json.dumps(dic) #将字典转换成字符串,转换后的字典中的元素是由双引号表示的
print(str_dic,type(str_dic))#{"k1": "v1", "k2": "v2", "k3": "v3"} <class 'str'> dic2 = json.loads(str_dic)#将一个字符串转换成字典类型
print(dic2,type(dic2))#{'k1': 'v1', 'k2': 'v2', 'k3': 'v3'} <class 'dict'> list_dic = [1,['a','b','c'],3,{'k1':'v1','k2':'v2'}]
str_dic = json.dumps(list_dic) #也可以处理嵌套的数据类型
print(type(str_dic),str_dic) #<class 'str'> [1, ["a", "b", "c"], 3, {"k1": "v1", "k2": "v2"}]
list_dic2 = json.loads(str_dic)
print(type(list_dic2),list_dic2) #<class 'list'> [1, ['a', 'b', 'c'], 3, {'k1': 'v1', 'k2': 'v2'}] dumps和loads
import json
f=open('json_file','w')
dic = {'k1':'v1','k2':'v2','k3':'v3'}
json.dump(dic,f)# #dump方法接收一个文件句柄,直接将字典转换成json字符串写入文件
f.close() f = open('json_file')
dic2 = json.load(f) #load方法接收一个文件句柄,直接将文件中的json字符串转换成数据结构返回
f.close()
print(type(dic2),dic2) dump和load
dump和load
pickle
json 和 pickle 模块
json:用于字符串和python数据类型之间进行转换
pickle:用于python特有的类型和python的数据类型进行转换
# --------------------------
import pickle
# dic= {'k1':'v1','k2':'v2','k3':'v3'}
# str_dic=pickle.dumps(dic)
# print(str_dic) #打印的是bytes类型的二进制内容
#
# dic2 = pickle.loads(str_dic)
# print(dic2) #有吧字典给转换回来了 import time
struct_time = time.localtime(1000000000)
print(struct_time)
f = open('pickle_file','wb')
pickle.dump(struct_time,f)
f.close() f = open('pickle_file','rb')
struct_time2 = pickle.load(f)
print(struct_time.tm_year) pickle的dumps,sump和loads,load方法
shelve
shelve也是python提供给我们的序列化工具,比pickle用起来更简单一些。
shelve只提供给我们一个open方法,是用key来访问的,使用起来和字典类似
import shelve
f = shelve.open('shelve_file')
f['key'] = {'int':10, 'float':9.5, 'string':'Sample data'} #直接对文件句柄操作,就可以存入数据
f.close() import shelve
f1 = shelve.open('shelve_file')
existing = f1['key'] #取出数据的时候也只需要直接用key获取即可,但是如果key不存在会报错
f1.close()
print(existing) shelve shelve
这个模块有个限制,它不支持多个应用同一时间往同一个DB进行写操作。所以当我们知道我们的应用如果只进行读操作,我们可以让shelve通过只读方式打开DB
1 import shelve
2 f = shelve.open('shelve_file', flag='r')
3 existing = f['key']
4 f.close()
5 print(existing)
由于shelve在默认情况下是不会记录待持久化对象的任何修改的,所以我们在shelve.open()时候需要修改默认参数,否则对象的修改不会保存。

import shelve
f1 = shelve.open('shelve_file')
print(f1['key'])
f1['key']['new_value'] = 'this was not here before'
f1.close() f2 = shelve.open('shelve_file', writeback=True)
print(f2['key'])
f2['key']['new_value'] = 'this was not here before'
f2.close() 设置writeback
writeback方式有优点也有缺点。优点是减少了我们出错的概率,并且让对象的持久化对用户更加的透明了;但这种方式并不是所有的情况下都需要,首先,使用writeback以后,shelf在open()的时候会增加额外的内存消耗,并且当DB在close()的时候会将缓存中的每一个对象都写入到DB,这也会带来额外的等待时间。因为shelve没有办法知道缓存中哪些对象修改了,哪些对象没有修改,因此所有的对象都会被写入。
Python学习【第6篇】:Python之常用模块1的更多相关文章
- 老男孩python学习自修第十六天【常用模块之sys和os】
例子: sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0) sys.version 获取Python解释程序的版本信息 sys. ...
- Python学习笔记基础篇——总览
Python初识与简介[开篇] Python学习笔记——基础篇[第一周]——变量与赋值.用户交互.条件判断.循环控制.数据类型.文本操作 Python学习笔记——基础篇[第二周]——解释器.字符串.列 ...
- Python 学习 第十篇 CMDB用户权限管理
Python 学习 第十篇 CMDB用户权限管理 2016-10-10 16:29:17 标签: python 版权声明:原创作品,谢绝转载!否则将追究法律责任. 不管是什么系统,用户权限都是至关重要 ...
- Python学习笔记进阶篇——总览
Python学习笔记——进阶篇[第八周]———进程.线程.协程篇(Socket编程进阶&多线程.多进程) Python学习笔记——进阶篇[第八周]———进程.线程.协程篇(异常处理) Pyth ...
- 进击的Python【第五章】:Python的高级应用(二)常用模块
Python的高级应用(二)常用模块学习 本章学习要点: Python模块的定义 time &datetime模块 random模块 os模块 sys模块 shutil模块 ConfigPar ...
- python学习第八讲,python中的数据类型,列表,元祖,字典,之字典使用与介绍
目录 python学习第八讲,python中的数据类型,列表,元祖,字典,之字典使用与介绍.md 一丶字典 1.字典的定义 2.字典的使用. 3.字典的常用方法. python学习第八讲,python ...
- python学习第七讲,python中的数据类型,列表,元祖,字典,之元祖使用与介绍
目录 python学习第七讲,python中的数据类型,列表,元祖,字典,之元祖使用与介绍 一丶元祖 1.元祖简介 2.元祖变量的定义 3.元祖变量的常用操作. 4.元祖的遍历 5.元祖的应用场景 p ...
- python学习第六讲,python中的数据类型,列表,元祖,字典,之列表使用与介绍
目录 python学习第六讲,python中的数据类型,列表,元祖,字典,之列表使用与介绍. 二丶列表,其它语言称为数组 1.列表的定义,以及语法 2.列表的使用,以及常用方法. 3.列表的常用操作 ...
- python学习第四讲,python基础语法之判断语句,循环语句
目录 python学习第四讲,python基础语法之判断语句,选择语句,循环语句 一丶判断语句 if 1.if 语法 2. if else 语法 3. if 进阶 if elif else 二丶运算符 ...
- Python学习笔记——基础篇【第五周】——常用模块学习
模块介绍 本节大纲: 模块介绍 time &datetime模块 (时间模块) random (随机数模块) os (系统交互模块) sys shutil (文件拷贝模块) j ...
随机推荐
- 一个unity3d lightmap问题
上周美术同学在使用unity3d制作lightmap的过程中,发现部分被lightmap影响的模型在移动端上效果与pc端不一致.当时我大概看了下,分析后,得到一个结论是“在移动端上lightmap的h ...
- Boost Replaceable by C++11 language features or libraries
Replaceable by C++11 language features or libraries Foreach → Range-based for Functional/Forward → P ...
- 由文字生成path后制作写字的动画
在看以下这个开源组件的时候,发现一个非常棒的方法,能够将文字生成path,这样就能够作出用笔写字的效果了. https://github.com/MP0w/MPParallaxCollection 关 ...
- DIV+CSS在不同浏览器中的表现
在给员工培训DIV+CSS的过程中.他们向我提出了非常多问题,有些问题我自己也没有想到过于是抽了些时间自己进行了一番实验,所有实验在IE7和Firefox中进行: 实验一.假设一个div没有指定 ...
- ubuntu系统jdk安装及环境变量配置
一.安装jdk 1.下载linux版本jdk,我用的是最新版本1.8.0_102 2.打开终端,进入jdk的存放路径 3.解压.tar.gz文件 sudo tar zxvf jdk-8u102-lin ...
- 读取Excel文件到DataTable中
private static string[] GetExcelSheetNames(OleDbConnection conn) { DataTable dtbSh ...
- JavaGraphics类的绘图方法
Graphics类提供基本绘图方法,Graphics类提供基本的几何图形绘制方法,主要有:画线段.画矩形.画圆.画带颜色的图形.画椭圆.画圆弧.画多边形.画字符串等. 1. 画线段:在窗口中画一条线段 ...
- Scala 返回多个值
class A{ var c var d def return={ (c,d,"soyo") //以元组形式返回 }}调用: val s=new A var(a1,a2,a3)=s ...
- 04、抽取BaseActivity
// 在使用SDK各组件之前初始化context信息,传入ApplicationContext // 注意该方法要再setContentView方法之前实现 // SDKInitializer.ini ...
- bzoj2730矿场搭建(Tarjan割点)
2730: [HNOI2012]矿场搭建 Time Limit: 10 Sec Memory Limit: 128 MBSubmit: 1771 Solved: 835[Submit][Statu ...