map/reduce之间的shuffle,partition,combiner过程的详解
Shuffle的本意是洗牌、混乱的意思,类似于java中的Collections.shuffle(List)方法,它会随机地打乱参数list里的元素顺序。MapReduce中的Shuffle过程。所谓Shuffle过程可以大致的理解成:怎样把map task的输出结果有效地传送到reduce输入端。也可以这样理解, Shuffle描述着数据从map task输出到reduce task输入的这段过程。
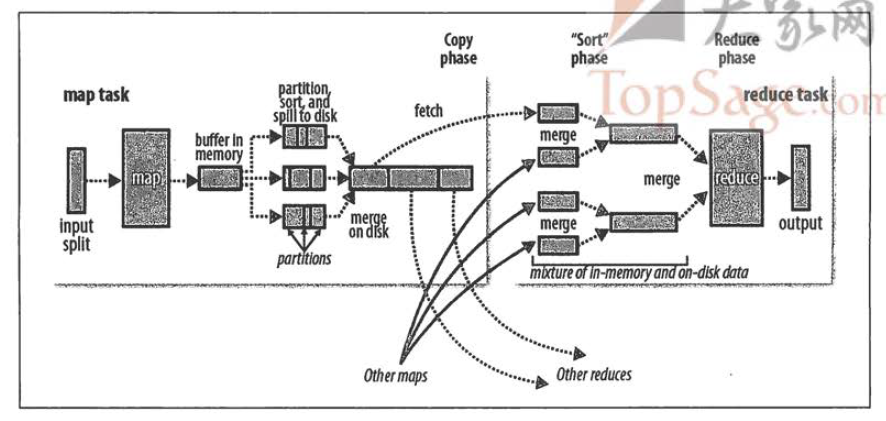
上图表示的是Shuffle的整个过程。在Hadoop这样的集群环境中,大部分map task与reduce task的执行是在不同的节点上。当然很多情况下Reduce执行时需要跨节点去读取其它节点上的map task结果,并存储到本地。如果集群正在运行的job有很多,那么task的正常执行对集群内部的网络资源消耗会很严重。这种网络消耗是正常的,我们不能限制,能做的就是最大化地减少不必要的消耗。另外在节点内,相比于内存,磁盘IO对job完成时间的影响也是比较大的,spark 就是基于这点对hadoop做出了改进,将map和reduce的所有任务都在内存中进行,并且中间接过都保存在内存中,从而比hadoop的速度要快100倍以上。从最基本的要求来说,我们对Shuffle过程希望做到:
- 完整地从map task端读取数据到reduce 端。
- 在跨节点读取数据时,尽可能地减少对带宽的不必要消耗。
- 减少磁盘IO对task执行的影响。
Shuffle实际上包括map端和reduce端的两个过程,在map端中我们称之为前半段,在reduce端我们称之为后半段。
Shuffle前半段过程主要包括:
1、split过程
2、partition过程:partition是分割map每个节点的结果,按照key分别映射给不同的reduce,也是可以自定义的。
3、溢写过程
4、Merge过程
每个map task都有一个内存缓冲区,存储着map的输出结果,当缓冲区快满的时候需要将缓冲区的数据以一个临时文件的方式存放到磁盘,当整个map task结束后再对磁盘中这个map task产生的所有临时文件做合并,生成最终的正式输出文件,然后等待reduce task来读取数据。 下面可以将Shuffle过程主要分为四个步骤:(结合WordCount的例子来进行说明)
1、split过程:在map task执行时,它的输入数据来源于HDFS的block,当然在MapReduce概念中,map task只读取split。Split与block的对应关系可能是多对一,默认是一对一。在WordCount例子里,假设map的输入数据都是像“aaa”这样的字符串。
2、partiton过程:在经过mapper的运行后,我们得知mapper的输出是这样一个key/value对: key是“aaa”, value是数值1。因为当前map端只做加1的操作,在reduce task里才去合并结果集。前面我们知道这个job有3个reduce task,到底当前的“aaa”应该交由哪个reduce去做呢,这个主要有partition来决定。下面就说明如何决定由哪个reduce去做这个事情。
MapReduce提供Partitioner接口,它的作用就是根据key或value及reduce的数量来决定当前的这对输出数据最终应该交由哪个reduce task处理。默认是对key hash后再以reduce task数量取模。默认的取模方式只是为了平均reduce的处理能力,如果用户自己对Partitioner有需求,可以自己重新实现partition的接口并设置到job上即可。
在我们的例子中,“aaa”经过Partitioner后返回0,也就是这对值应当交由第一个reducer来处理。接下来,需要将数据写入内存缓冲区中,缓冲区的作用是批量收集map结果,减少磁盘IO的影响。我们的key/value对以及Partition的结果都会被写入缓冲区。当然写入之前,key与value值都会被序列化成字节数组。
3、溢写过程:这个内存缓冲区是有大小限制的,默认是100MB,也可以通过设置配置文件中的参数mapreduce.task.io.sort.mb来设置。当map task的输出结果很多时,就可能会撑爆内存,所以需要在一定条件下将缓冲区中的数据临时写入磁盘,然后重新利用这块缓冲区。这个从内存往磁盘写数据的过程被称为Spill,中文可译为溢写,字面意思很直观。这个溢写是由单独线程来完成,不影响往缓冲区写map结果的线程。溢写线程启动时不应该阻止map的结果输出,所以整个缓冲区有个溢写的比例spill.percent。这个比例默认是0.8,也就是当缓冲区的数据已经达到阈值(buffer size * spill percent = 100MB * 0.8 = 80MB),溢写线程启动,锁定这80MB的内存,执行溢写过程。Map task的输出结果还可以往剩下的20MB内存中写,互不影响。
当溢写线程启动后,需要对这80MB空间内的key做排序(Sort)。排序是MapReduce模型默认的行为,这里的排序也是对序列化的字节做的排序。
在这里我们可以想想,因为map task的输出是需要发送到不同的reduce端去,而内存缓冲区没有对将发送到相同reduce端的数据做合并,那么这种合并应该是体现是磁盘文件中的。从官方图上也可以看到写到磁盘中的溢写文件是对不同的reduce端的数值做过合并。所以溢写过程一个很重要的细节在于,如果有很多个key/value对需要发送到某个reduce端去,那么需要将这些key/value值拼接到一块,减少与partition相关的索引记录。
在针对每个reduce端而合并数据时,有些数据可能像这样:“aaa”/1, “aaa”/1。对于WordCount例子,就是简单地统计单词出现的次数,如果在同一个map task的结果中有很多个像“aaa”一样出现多次的key,我们就应该把它们的值合并到一块,这个过程叫reduce也叫combine。但MapReduce的术语中,reduce只指reduce端执行从多个map task取数据做计算的过程。除reduce外,非正式地合并数据只能算做combine了。其实大家知道的,MapReduce中将Combiner等同于Reducer。
如果client设置过Combiner,那么现在就是使用Combiner的时候了。将有相同key的key/value对的value加起来,减少溢写到磁盘的数据量。Combiner会优化MapReduce的中间结果,所以它在整个模型中会多次使用。那么哪些场景才能使用Combiner呢?从这里分析,Combiner的输出是Reducer的输入,Combiner绝不能改变最终的计算结果。所以从我的想法来看,Combiner只应该用于那种Reduce的输入key/value与输出key/value类型完全一致,且不影响最终结果的场景。比如累加,最大值等。Combiner的使用一定得慎重,如果用好,它对job执行效率有帮助,反之会影响reduce的最终结果。
4、merge过程:merge是将多个溢写文件合并到一个文件。每次溢写会在磁盘上生成一个溢写文件,如果map的输出结果真的很大,有多次这样的溢写发生,磁盘上相应的就会有多个溢写文件存在。当map task真正完成时,内存缓冲区中的数据也全部溢写到磁盘中形成一个溢写文件。最终磁盘中会至少有一个这样的溢写文件存在(如果map的输出结果很少,当map执行完成时,只会产生一个溢写文件),因为最终的文件只有一个,所以需要将这些溢写文件归并到一起,这个过程就叫做Merge。Merge是怎样的?如前面的例子,“aaa”从某个map task读取过来时值是5,从另外一个map 读取时值是8,因为它们有相同的key,所以得merge成group。什么是group。对于“aaa”就是像这样的:{“aaa”, [5, 8, 2, …]},数组中的值就是从不同溢写文件中读取出来的,然后再把这些值加起来。请注意,因为merge是将多个溢写文件合并到一个文件,所以可能也有相同的key存在,在这个过程中如果client设置过Combiner,也会使用Combiner来合并相同的key。
至此,map端的所有工作都已结束,最终生成的这个文件也存放在TaskTracker够得着的某个本地目录内。每个reduce task不断地通过RPC从JobTracker那里获取map task是否完成的信息,如果reduce task得到通知,获知某台TaskTracker上的map task执行完成,Shuffle的后半段过程开始启动。
简单地说,reduce task在执行之前的工作就是不断地拉取当前job里每个map task的最终结果,然后对从不同地方拉取过来的数据不断地做merge,也最终形成一个文件作为reduce task的输入文件。
Shuffle在reduce端的过程也能用三点来概括。当前reduce copy数据的前提是它要从JobTracker获得有哪些map task已执行结束。Reducer真正运行之前,所有的时间都是在拉取数据,做merge,且不断重复地在做。如前面的方式一样,下面我也分段地描述reduce 端的Shuffle细节:
1. Copy过程,简单地拉取数据。Reduce进程启动一些数据copy线程(Fetcher),通过HTTP方式请求map task所在的TaskTracker获取map task的输出文件。因为map task早已结束,这些文件就归TaskTracker管理在本地磁盘中。
2. Merge阶段。这里的merge如map端的merge动作,只是数组中存放的是不同map端copy来的数值。Copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比map端的更为灵活,它基于JVM的heap size设置,因为Shuffle阶段Reducer不运行,所以应该把绝大部分的内存都给Shuffle用。这里需要强调的是,merge有三种形式:1)内存到内存 2)内存到磁盘 3)磁盘到磁盘。默认情况下第一种形式不启用,让人比较困惑,是吧。当内存中的数据量到达一定阈值,就启动内存到磁盘的merge。与map 端类似,这也是溢写的过程,这个过程中如果你设置有Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件。第二种merge方式一直在运行,直到没有map端的数据时才结束,然后启动第三种磁盘到磁盘的merge方式生成最终的那个文件。
3. Reducer的输入文件。不断地merge后,最后会生成一个“最终文件”。为什么加引号?因为这个文件可能存在于磁盘上,也可能存在于内存中。对我们来说,当然希望它存放于内存中,直接作为Reducer的输入,但默认情况下,这个文件是存放于磁盘中的。当Reducer的输入文件已定,整个Shuffle才最终结束。然后就是Reducer执行,把结果放到HDFS上。
Shuffle产生的意义是什么?
Shuffle过程的期望可以有:
完整地从map task端拉取数据到reduce 端。
在跨节点拉取数据时,尽可能地减少对带宽的不必要消耗。
减少磁盘IO对task执行的影响。
每个map task都有一个内存缓冲区,存储着map的输出结果,当缓冲区快满的时候需要将缓冲区的数据该如何处理?
每个map task都有一个内存缓冲区,存储着map的输出结果,当缓冲区快满的时候需要将缓冲区的数据以一个临时文件的方式存放到磁盘,当整个map task结束后再对磁盘中这个map task产生的所有临时文件做合并,生成最终的正式输出文件,然后等待reduce task来拉数据。
MapReduce提供Partitioner接口,它的作用是什么?
MapReduce提供Partitioner接口,它的作用就是根据key或value及reduce的数量来决定当前的这对输出数据最终应该交由哪个reduce task处理。默认对key hash后再以reduce task数量取模。默认的取模方式只是为了平均reduce的处理能力,如果用户自己对Partitioner有需求,可以订制并设置到job上。
什么是溢写?
在一定条件下将缓冲区中的数据临时写入磁盘,然后重新利用这块缓冲区。这个从内存往磁盘写数据的过程被称为Spill,中文可译为溢写。
溢写是为什么不影响往缓冲区写map结果的线程?
溢写线程启动时不应该阻止map的结果输出,所以整个缓冲区有个溢写的比例spill.percent。这个比例默认是0.8,也就是当缓冲区的数据已经达到阈值(buffer size * spill percent = 100MB * 0.8 = 80MB),溢写线程启动,锁定这80MB的内存,执行溢写过程。Map task的输出结果还可以往剩下的20MB内存中写,互不影响。
当溢写线程启动后,需要对这80MB空间内的key做排序(Sort)。排序是MapReduce模型默认的行为,这里的排序也是对谁的排序?
当溢写线程启动后,需要对这80MB空间内的key做排序(Sort)。排序是MapReduce模型默认的行为,这里的排序也是对序列化的字节做的排序。
溢写过程中如果有很多个key/value对需要发送到某个reduce端去,那么如何处理这些key/value值?
如果有很多个key/value对需要发送到某个reduce端去,那么需要将这些key/value值拼接到一块,减少与partition相关的索引记录。
哪些场景才能使用Combiner呢?
Combiner的输出是Reducer的输入,Combiner绝不能改变最终的计算结果。所以从我的想法来看,Combiner只应该用于那种Reduce的输入key/value与输出key/value类型完全一致,且不影响最终结果的场景。比如累加,最大值等。Combiner的使用一定得慎重,如果用好,它对job执行效率有帮助,反之会影响reduce的最终结果。
Merge的作用是什么?
最终磁盘中会至少有一个这样的溢写文件存在(如果map的输出结果很少,当map执行完成时,只会产生一个溢写文件),因为最终的文件只有一个,所以需要将这些溢写文件归并到一起,这个过程就叫做Merge
每个reduce task不断的通过什么协议从JobTracker那里获取map task是否完成的信息?
每个reduce task不断地通过RPC从JobTracker那里获取map task是否完成的信息
reduce中Copy过程采用是什么协议?
Copy过程,简单地拉取数据。Reduce进程启动一些数据copy线程(Fetcher),通过HTTP方式请求map task所在的TaskTracker获取map task的输出文件。
reduce中merge过程有几种方式?
merge有三种形式:1)内存到内存 2)内存到磁盘 3)磁盘到磁盘。默认情况下第一种形式不启用,让人比较困惑,是吧。当内存中的数据量到达一定阈值,就启动内存到磁盘的merge。与map 端类似,这也是溢写的过程,这个过程中如果你设置有Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件。第二种merge方式一直在运行,直到没有map端的数据时才结束,然后启动第三种磁盘到磁盘的merge方式生成最终的那个文件。
map/reduce之间的shuffle,partition,combiner过程的详解的更多相关文章
- 【Big Data - Hadoop - MapReduce】通过腾讯shuffle部署对shuffle过程进行详解
摘要: 通过腾讯shuffle部署对shuffle过程进行详解 摘要:腾讯分布式数据仓库基于开源软件Hadoop和Hive进行构建,TDW计算引擎包括两部分:MapReduce和Spark,两者内部都 ...
- Tomcat启动过程原理详解 -- 非常的报错:涉及了2个web.xml等文件的加载流程
Tomcat启动过程原理详解 发表于: Tomcat, Web Server, 旧文存档 | 作者: 谋万世全局者 标签: Tomcat,原理,启动过程,详解 基于Java的Web 应用程序是 ser ...
- Ubuntu 16.04.3 Server 版安装过程图文详解
Ubuntu 16.04.3 Server 版安装过程图文详解 首先,我们会进入系统安装的第一个界面,开始系统的安装操作.每一步的操作,左下角都会提示操作方式! 1.选择系统语言-English2.选 ...
- Map/Reduce之间的Partitioner接口
一.Partitioner介绍 Partitioner的作用是对Mapper产生的中间结果进行分片,以便将同一分组的数据交给同一个Reduce处理,它直接影响Reduce阶段的负载均衡(个人理解:就是 ...
- hadoop的mapReduce和Spark的shuffle过程的详解与对比及优化
https://blog.csdn.net/u010697988/article/details/70173104 大数据的分布式计算框架目前使用的最多的就是hadoop的mapReduce和Spar ...
- Linux进程上下文切换过程context_switch详解--Linux进程的管理与调度(二十一)
1 前景回顾 1.1 Linux的调度器组成 2个调度器 可以用两种方法来激活调度 一种是直接的, 比如进程打算睡眠或出于其他原因放弃CPU 另一种是通过周期性的机制, 以固定的频率运行, 不时的检测 ...
- web.xml的加载过程配置详解
一:web.xml加载过程 简单说一下,web.xml的加载过程.当我们启动一个WEB项目容器时,容器包括(JBoss,Tomcat等).首先会去读取web.xml配置文件里的配置,当这一步骤没有 ...
- 全网最详细的HA集群的主节点之间的双active,双standby,active和standby之间切换的解决办法(图文详解)
不多说,直接上干货! 1. HA集群的主节点之间的双standby的解决办法: 全网最详细的Hadoop HA集群启动后,两个namenode都是standby的解决办法(图文详解) 2. HA集群的 ...
- Spark API 之 map、mapPartitions、mapValues、flatMap、flatMapValues详解
原文地址:https://blog.csdn.net/helloxiaozhe/article/details/80492933 1.创建一个RDD变量,通过help函数,查看相关函数定义和例子: & ...
随机推荐
- 深搜(DFS)与广搜(BFS)区别
最近做了不少的搜索题,时而用到DFS时而用到BFS,这里对两种搜索方法做一个总结. 广度优先搜索算法(Breadth-First-Search,缩写为 BFS),是一种利用队列实现的搜索算法.简单来说 ...
- C语言文件进阶操作
Description文件a.dic.b.dic.c.dic中分别存有张三的三科成绩,每个文件都是16字节:前8个字节存储其英文名字zhangsan,后面是一个空格,其后的2个字节存储其年龄(文本方式 ...
- 浏览器中event.srcElement和event.target的兼容性问题
在IE下,event对象有srcElement属性,但是没有target属性:Firefox下,even对象有target属性,但是没有srcElement属性.. 解决方法:使用obj(obj = ...
- python学习笔记04:安装pip
如果是从python官网下载的python版本(2.7.9或3.4)的安装包,其中已经内置了pip工具.那么只需要升级pip即可. 检测是否已安装pip: python -m pip --versio ...
- 《Debian标准教程》摘录2则
1.克隆Debian系统 如果使用的Debian系统只有使用apt安装的软件包,可以使用下面的脚本来安装一个完全一样的新系统. #在源主机上 dpkg --get-selections > se ...
- 在mysql启用远程连接
1.在ubuntu下面安装mysql. apt-get install mysql-server mysql-client -y 2.修改/etc/mysql/my.cnf文件. #bind-addr ...
- phpcms找不到模板、空白模板的解决办法
有时候会出现这个问题,尤其是在调试模板的过程中,不知道别的朋友的操作习惯.我的习惯是,先保留一份原始的模板.比如: index原版.html. 以便对比之用.但是呢,这样,往往会造成 找不到模板的情况 ...
- vue-cli2使用cdn方式引入cytoscape
1. index.html头部引用 <script src="https://cdnjs.cloudflare.com/ajax/libs/cytoscape/3.2.19/cytos ...
- memcached安装与启动
windows 安装1.4.4版本 https://pan.baidu.com/s/1xX1NThLqeq2zNMaqONFgkQ 解压,“以管理员身份” 运行cmd,切换到memcached根目录, ...
- [剑指Offer] 64.滑动窗口的最大值
题目描述 给定一个数组和滑动窗口的大小,找出所有滑动窗口里数值的最大值.例如,如果输入数组{2,3,4,2,6,2,5,1}及滑动窗口的大小3,那么一共存在6个滑动窗口,他们的最大值分别为{4,4,6 ...