python函数入门到高级
函数的定义:
def test(x):
"The function definitions"
x+=1
return x def:定义函数的关键字
test:函数名
():内可定义形参
"":文档描述(非必要,但是强烈建议为你的函数添加描述信息)
x+=1:泛指代码块或程序处理逻辑
return:定义返回值 调用运行:可以带参数也可以不带
函数名()
为什么要定义函数
打个比方。如果公司老板要求你写一个监控程序,当CPU\Memory\Disk等指标超过阈值时即发邮件报警。代码如下
while True:
if cpu利用率 > 90%:
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接 if 硬盘使用空间 > 90%:
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接 if 内存占用 > 80%:
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
虽然说上面的代码实现了功能。但是发现重复的代码写的太多了。就显得很low逼。这样就存在两个问题
1.重复代码太多。不符合高端程序员气质
2.如果日后需要修改发邮件的这段代码,比如加入群发功能,那么就需要在所有发送邮件的位置进行修改
如何解决这个问题呢?
只要将重复部分的代码提出来,放到一个公共的位置,起个名字,以后谁想用这段代码。直接通过这个名字调用一下就可以了
def 发送邮件(内容)
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接 while True: if cpu利用率 > 90%:
发送邮件('CPU报警') if 硬盘使用空间 > 90%:
发送邮件('硬盘报警') if 内存占用 > 80%:
发送邮件('内存报警')
总结使用函数的好处:
1.代码重用
2.保持一致性,易维护
3.可扩展性
python的函数有两种:
内置函数与自定义函数
内置函数:
在文章的最下面
自定义函数:
def funcname(test):
'''
文档注释
:return:
'''
print ('hello',test)
return 123 funcname('lhc') #函数的定义与调用
只有函数名后面有()才会调用函数的内容。如果后面不接()那么这个名字只是显示出这个函数的内存地址
print (funcname) <function funcname at 0x00000000026A7518>
return意义
return代表着返回值,表示在函数运行结束后的一个值。将返回值赋予一个变量,那么可以看到打印结果。在函数中如果出现return,那么就代表这这个函数运行结束,后面的操作将不会在执行例2
def funcname(test):
'''
文档注释
:return:
'''
print ('hello',test)
return 123 res=funcname('lhc')
print (res)
例2
def funcname(test):
'''
文档注释
:return:
'''
print ('hello',test)
return 123
print ('*'*20)
print ('*'*20)
print ('*'*20)
res=funcname('lhc')
print (res)
注意:即使不加返回值的话,那么python也会自动返回一个值为None
返回值:
0个——>None
1个——>该返回什么返回什么
多个——>返回元组形式
返回值可以是任意类型
三种函数的定义:
无参函数
def f1():
'''
文档注释
:return:
'''
print ('In the f1')
f1() 有参函数
def f2(x,y,z):
'''
文档注释
:return:
'''
print ('In the f2',x,y,z)
f2(1,2,3) 空函数
def f3():
'''
文档注释
:return:
'''
pass
f3() #开发工程常用函数
def my_sum2(x,y):
'''
定义两个相加之和
:param x:
:param y:
:return:
'''
# res=x+y
# return res
return x+y #也可以这么写
print (my_sum2(1,2))
#return可以返回任何数据类型,也可以return任何表达式 def my_max(x,y):
'''
比较两个数字最小值
:param x:
:param y:
:return:
'''
# if x>y:
# return x
# else:
# return y
return x if x>y else y
print (my_max(1,2))
三种函数的调用形式:
def my_max(x,y):
return x if x>y else y # print (my_max(1,2))
#语句形式
my_max(1,2)
# 常用语没有返回值的函数 #表达式形式
res=my_max(1,2)
print (res)
# 需要拿到返回值 #作为参数
res=my_max(10,my_max(11,12))
print (res)
形式参数与实际参数:
这个就是形式参数
只有在被调用(或者被传值)才会暂用内存空间

这个就是实际参数。真实占用内存空间

PS:在python中名字没有任何的储值功能,任何的赋值都是绑定一个名字到一个值
参数的动态性:
#参数的动态性
def foo(x,y):
return x+y
print (foo(1.2,3))
print (foo('a','b'))
print (foo(1,'a'))
这样做有好处也有坏处,同类型想加没有问题,但是像print(foo(1,'a'))那么就会报错。怎么解决请往下看
解决方法:
1
def foo(x,y):
''' :param x: int
:param y: int
:return: int
'''
return x+y
定义文档注释,但是起不到限定作用
2
def foo(x,y):
if type(x) is int and type(y) is int:
return x+y
print (foo(1,2))
进行判断
3
def foo(x:int,y:int)->int:
return x+y
print(foo(1,2))
实际参数与形式参数的调用:
#实参:按位置传值(受位置影响)
def foo(x,y):
print (x)
print (y)
foo(1,2) #实参:安关键字传值(不受位置影响)
def foo(x,y):
print (x)
print (y)
foo(y=1,x=2) # 注意问题一:针对同一个形式参数,你可以按照位置或者按照关键字传值,但是只能用一种方式
foo(1,x=1,y=2) #报错
#注意问题二:按关键字传值,必须在按位置传值的右边
foo(x=1,2) #报错
#位置参数,默认参数,*args可变参数,**kwargs def foo(x,y,z):
print (x)
print (y)
print (z)
#位置参数,必须要传值
foo(1,2,3) #默认参数,在定义参数的时候给一个默认的值。
def foo(x,y=10):
print (x)
print (y)
foo(1)
foo(1,3)
foo(1,y=1)
#默认参数通常是把那种变化比较小的参数定义成默认参数。
#默认参数一定要定义成一个不可变的类型 #注意默认参数必须要写的位置参数右边
def foo(x=1,y):
pass #报错 #默认参数在定义时就已经被赋了一个明确的值。后期的变化对其无效
name=123
def foo(x,y=name):
print (x)
print (y)
name='abc'
foo(1)
# 注意针对任何形式的参数都有两种传值操作(位置与关键字)
总结默认参数的好处:
1.降低了函数调用的复杂性
2.可用来扩展函数功能
*args
def foo(x,y,*args):
print(x)
print(y)
print(args)
foo(1,2,3,4)
将函数剩余的参数变成元组,即使函数与参数相等,那么将会输出一个空元组
def foo(x,y,*args):
print(x)
print(y)
print(args)
foo(1,2,*[3,4,5])
*的作用是‘监听’位置参数,*args等待接收的参数必须是按位置来的
凡事遇到带*的参数,那么我们就把它看着是位置参数
例如:
def foo(x,y,a,b,c):
print(x)
print(y)
print(a,b,c)
foo(*[1,2,3,4,5])
如果多一个参数或者少一个参数 那么就会报错
如果*的后面参数是一个数据类型,而不是一个具体的参数名,那么就把那个数据类型打散
**kwargs
def foo(x,y,**kwargs):
print(x)
print(y)
print(kwargs)
foo(1,y=2,z=1,b=2,c=5)
**kwargs会将多的关键字参数组合成一个字典格式,与上面的*args作用一样。但是,要在*args后面。因为*args可以看做一个位置参数,而**kwargs可以看成一个关键字参数。基于我们上面说的,关键字参数要在位置参数的后面。它们两个可以一起组合使用。
组合使用后,后期函数的扩展性将会很好
def foo(x,y,z):
print(x)
print(y)
print(z)
foo(**{'x':1,'z':3,'y':2})
在实参上操作:看到实参前面有**后面接入一个字典{'x':1,'z':3,'y':2},那么就把它看做x=1,z=3,y=2.就变成了关键字传值了,那么如果多一个值或者少一个值的话会报错
def foo(x,y,z=3):
print(x)
print(y)
print(z) def bar(*args,**kwargs): #args=(1,2,3) kwargs={'x':1,'y':2,'z':3}
foo(*args,**kwargs) #foo(*(1,2,3),**{'x':1,'y':2,'z':3})
#foo(1,2,3,x=1,y=2,z=3)
bar(1,2,3,x=1,y=2,z=3)
test
函数是第一类对象(函数对象)
在python中所有的名字都没有储值功能,什么是名字,比如说定义函数的名字,定义变量的名字等等。
概念:指的是函数可以被当做数据来处理。
数据值的处理方式:
可以被引用
def foo():
print('foo')
f1=foo
f1()
可以当做另外一个参数的值
def foo():
print('foo') def bar(func):
print(func)
bar(foo)
可以当做返回值
def foo():
print('foo') def bar(func):
return func
f=bar(foo)
print(f)
f()
*注意:如果函数当做参数,或者返回值当做参数,满足了其中一个,这个函数可以称作为高级函数
一个值可以当做容器类型的一个元素
def foo():
print('foo')
func_dic={
'foo':foo
}
func_dic['foo']()
函数嵌套
1.函数的嵌套调用
在一个函数内部调用另一个函数
面向过程的编程 def my_max2(x,y):
if x>y:
return x
else:return y def my_max4(a,b,c,d):
res1=my_max2(a,b)
res2=my_max2(res1,c)
res3=my_max2(res2,d)
return res3
print(my_max4(1,23423,5435,0)) def my_max2(x,y):
return x if x>y else y def my_max4(a,b,c,d):
return my_max2(my_max2(my_max2(a,b),c),d)
print(my_max4(1,23423,54353,0))
函数的可读性很差 不推荐
e,g
2.函数的嵌套定义
在函数内部再定义一个函数
def f1():
def f2():
print('in the f2')
f2()
f1()
e,g
命名空间(Namespaces)
命名空间即名称空间,存放名字的地方,反映的是名字与值的绑定
x=1
#就是将x与1绑定
del x
#则是将x与1的绑定删除
在Python中分三种命名空间
1.局部命名空间
def foo():
x=1
def bar():pass
#foo()函数中的定义就说局部命名空间,可以理解为有缩进的
2.全局命名空间
import time
x=1
class ClassName:pass
def foo():pass
#顶头写,没有缩进,只要Python这个代码一执行,他们就会放到全局命名空间中
3.內建命名空间
python程序要想运行,需要靠python解释器来执行,解释器属于一个软件,而解释器中写好的名字就叫內建名字,比如:sum,print 等等。
Python加载名字顺序
內建命名空间-->全局命名空间-->局部命名空间(在函数名被调用的时候才会加载,执行完毕后进行释放)
globals() 与 locals()
使用上面两个函数可以查看全局名称与局部名称
x=1
def func():
y=2
x=3
print('in the func') print(globals())
print(locals()) 执行结果:
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x0043A410>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'C:/Users/Administrator/PycharmProjects/untitled/day5/命名空间与作用域.py', '__cached__': None, 'x': 1, 'func': <function func at 0x006567C8>}
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x0043A410>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'C:/Users/Administrator/PycharmProjects/untitled/day5/命名空间与作用域.py', '__cached__': None, 'x': 1, 'func': <function func at 0x006567C8>} 可以发现上面两行一模一样,因为gloabls在全局中输出,所以全局的局部还是全局
在局部中打印
x=1
def func():
y=2
x=3
def bar():pass
print(locals())
print(globals()) func() {'bar': <function func.<locals>.bar at 0x003FD780>, 'x': 3, 'y': 2}
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x0043A410>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'C:/Users/Administrator/PycharmProjects/untitled/day5/命名空间与作用域.py', '__cached__': None, 'x': 1, 'func': <function func at 0x004C6738>} 同样的在局部中打印局部变量。
特殊的if
x=1
if 1:
aaaaaaaaaaaaaaaaaaaaaaa=1
def func():
y=2
x=3
def bar():pass
print(locals())
print(globals())
func() {'bar': <function func.<locals>.bar at 0x0041D780>, 'x': 3, 'y': 2}
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x0045A410>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'C:/Users/Administrator/PycharmProjects/untitled/day5/命名空间与作用域.py', '__cached__': None, 'x': 1, 'aaaaaaaaaaaaaaaaaaaaaaa': 1, 'func': <function func at 0x004967C8>}
虽然if下面的子代码没有顶头写,但是也属于全局变量
查看內建名称
作用域
按照作用范围以及产生消亡的时间,可以把这三个命名空间分成两个区域

反映就是一种查找顺序,比如说在局部域查找名字,局部域没有,查找全局,全局没有查找內建
定义在全局的变量为全局变量。全局变量全局有效。
定义在局部的变量为局部变量,局部变量局部有效,函数执行的时候存活,函数结束后被释放
x=1
def f1():
x=10
def f2():
x=20000
print (x)
return f2
f=f1()
print(f)
x=20
f() x=1
def f1():
x=10
def f2():
# x=20000
print (x)
return f2
f=f1()
print(f)
x=20
f()
e,g
闭包
定义函数其实就是命名一个名字,然后把函数的代码打包赋值给这个名字,定义函数就是一个打包的过程。
而闭包的概念是:本质就是一个内部函数。特点,必须包含对外部函数作用域(非全局作用域)名字的引用
def f1():
x=1
def f2():
print(x)
return f2
func=f1()
x=10
func()
e,g
也就是f2函数打包了一段代码,特殊之处是,他是一个包含对外部函数状态引用的函数。在返回f2的时候,并不是单纯的再返回里面的代码,是返回这个代码并且把这个代码外面想要的值一并返回。如果自己的函数体内有值,那么它就不是闭包函数。
如何查看是不是闭包函数
def f1():
x=1
y=2
def f2():
print(x)
print(y)
return f2
func=f1()
print(func.__closure__[0].cell_contents)
print(func.__closure__[1].cell_contents)
e,g
闭包的厉害之处——惰性计算
from urllib.request import urlopen
def page(url):
def get():
return urlopen(url).read()
return get #通常来说闭包函数定义完后应该返回来 baidu=page('http://www.baidu.com')
print(baidu())
e,g
什么时候调用,直接就加括号可以
装饰器
比如公司写入一个软件后,稳定后就要遵循开放封闭原则。(就是开放了就要关闭,类似于上线后,项目的源代码就不能再更改了,能不动就净量别动。可能会导致连锁反应,进而导致程序崩溃),但是上线后不可能就不扩展,扩展还不能修改源代码包括函数的调用方式,那么就出现了'装饰器'
装饰器:本身功能是装饰别人,被装饰着可以是任何可调用对象。装饰器本身也可以是任何可调用对象
#需求,统计函数执行时间
#装饰器需要遵循的原则:1:不能修改源代码
#2:不能修改调用方式
#装饰器功能是在遵循1和2的前提下为被装饰对象添加新功能
import time
def timer(func): #2.这一步是把下面的index给了func,而这一步index是属于最原始的,最原始的意思就是还没装饰的
def wapper():
start_time=time.time()
func()
time.sleep(3)
stop_time=time.time()
print('run time is %s' %(start_time -start_time))
return wapper @timer #1.index=timer(index) 3.最后闭包函数执行结束后,会return返回一个wapper,这个wapper就是此时的index
def index():
print('welcome to index')
index() # 4最后这里index的调用就是在调用wapper
添加功能后的结果
#无参装饰器
@timer #@后面跟一个新名字。timer()是装饰器,就是一个函数。
#@timer就是把正下方的函数名传进去‘@timer(index)'执行后会得到一个结果,这个结果重新赋值给index 'index=@timer(index)'
def index():
print('welcome to index')
index() #有参数装饰器
@auth(auth_type='file') #只要是名字加括号,第一件事就是立马执行,有返回值则返回值,没有则返回None
#auth(auth_type='file')会的到一个结果 --->比如 func --->在转换成上面的@func ---> 会读正下方的函数名 index=func(index)
def index():
print('welcome to index')
index()
import time
def timer(func): #这一步是把下面的home给了func,而这一步home是属于最原始的,最原始的意思就是还没装饰的
def wapper(user):
start_time=time.time()
func(user) #2.这个func就是下面的home源代码,给一个参数user,但是func属于wapper 所以还要给wapper一个参数
stop_time=time.time()
print('run time is %s' %(start_time -start_time))
return wapper @timer
def home(user):
time.sleep(2)
print('home %s'%user)
home('lhc') #1.运行home就是运行装饰后的home即上面的wapper 即wapper('lhc').但是运行会报错,因为上面的装饰器函数中没有定义参数
#所以就要变成有参的装饰器
#3.最后home执行就变成了wapper执行
有参函数添加功能后的结果
整合有参与无参
import time
def timer(func):
def wapper(*args,**kwargs):
start_time=time.time()
func(*args,**kwargs)
stop_time=time.time()
print('run time is %s'%(start_time-stop_time))
return wapper @timer
def index():
print('welcome index')
index() @timer
def home(user):
print('welecome to home %s'%user)
home('lhc')
有参与无参之*args **kwargs
如果一个装饰器装饰了两个函数,那么都没偶参数或者都有参数,那么很简单,但是其中一个有参另一个无参,那么就无法写死了,这时候就可以用*args和**kwargs 通过*args来接受位置参数,**kwargs来接受关键字参数,在
定义wapper参数为*args和**kwargs那么不论你之前传入的参数是什么样的wapper都会将你原封不动的打开。
认证装饰器
user_l=[
{'user':'lhc','passwd':''},
{'user':'zxb','passwd':''},
{'user':'hj','passwd':''},
] def auth(func):
# def func(func):
def wapper(*args,**kwargs):
name=input('name').strip()
passwd=input('passwd').strip()
for i in user_l:
if name != i['user'] or passwd != i['passwd']:
print('gun')
break
res = func(*args, **kwargs)
else:
print('auth successful')
res = func(*args, **kwargs)
return res
return wapper @auth
def home(user):
print('welcome to home %s'%user)
return user+''
res=home(user='lhc')
print(res)
e,g
认证装饰器2
#!/usr/bin/env python
#coding=utf-8 import time
user_l=[
{'user':'lhc','passwd':''},
{'user':'zxb','passwd':''},
{'user':'hj','passwd':''},
]
login_user={'username':None,'login':False} def auth(auth_type):
def deco(func):
def wapper(*args,**kwargs):
# print('====================',auth_type)
if auth_type =='file':
if login_user['username'] and login_user['login']:
res = func(*args, **kwargs)
return res
name=input('name:').strip()
passwd=input('passwd:').strip()
for i in user_l:
if name == i['user'] and passwd == i['passwd']:
print('auth successful')
print('auth type is file')
login_user['username'] = name
login_user['login'] = True
res = func(*args, **kwargs)
return res elif auth_type=='ladp':
print('login type is ladp successfull')
res=func(*args,**kwargs)
return wapper
return deco @auth(auth_type='ladp') #func---->@func---->index=func(index)
def index():
print('welcome index')
index() @auth(auth_type='file')
def home(user):
print('welecome to home %s'%user)
return user+''
res=home('lhc')
print(res)
e,g
注意:如果原函数里面有文档注释信息的话,那么要导入一个functools模块中的functools.wraps(func)并装饰到wrapper函数上面
import functools
def temer(func):
@functools.wraps(func)
def wrapper(*args,**kwargs):
'这是wrapper函数'
g=func(*args,**kwargs)
return g
return wrapper @temer
def index():
'这是index函数'
print('welcome')
# index()
print(help(index))
e,g
上面中装饰器的意思就是让wrapper保持原函数的注释信息.记住就行
迭代器
迭代:更新换代,描述的是一种重复的过程,在Python中跟重复动作有关的关键字有for,while。
l=[1,2,3,4]
for i in range(len(l)):
print(l[i]) i=0
while i <len(l):
print(l[i])
i+=1
e,g
按照上面的方法进行循环的通过下标来实现的
但是针对没有下标的数据类型,我们再想迭代他们的,就必须提供一种不按下标取值的方式,针对这种情况,python已经为很多数据类型内置了一个叫__iter__的方法
例
d={'a':1,'b':2}
print(d.__iter__)
print([].__iter__)
数据类型凡是有__iter__方法都是可迭代的iterable,执行这个方法得到的结果就是迭代器iterator
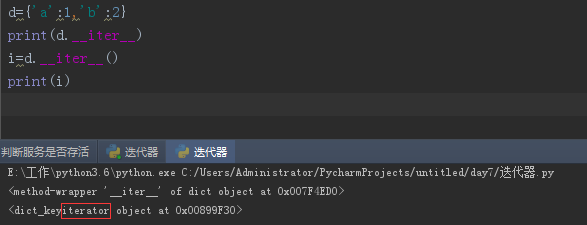
只要是迭代器,他下面内置一个__next__方法
通过执行这个__next__方法得到的结果

循环字典的key值,
如果再次循环一次会出现一个叫StopIteration的“错误”,但是这个StopIteration并不是报错,是代表一种结束的标志。
代表字典没有值了

包括列表也是一样的
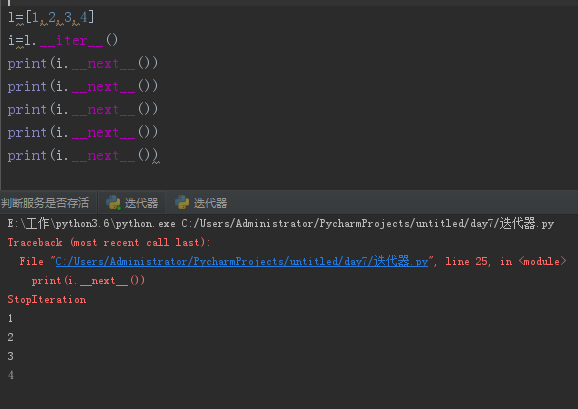
l=[1,2,3,4]
i=iter(l) #1.__iter__()
while l:
print(next(i)) #i.__next__()
列表迭代
l=[1,2,3,4]
i=iter(l) #1.__iter__()
while l:
try:
print(next(i)) #i.__next__()
except StopIteration as e:
break
异常处理
dict={'a':1,'b':2,'c':3}
d=iter(dict)
while 1:
try:
# print(next(d))
print(dict[next(d)])
except StopIteration:
break
while迭代字典
迭代器的厉害之处就是对于那种没有下标的数据类型进行循环,包括文件
dict={'a':1,'b':2,'c':3}dict={'a':1,'b':2,'c':3}dict={'a':1,'b':2,'c':3}dict={'a':1,'b':2,'c':3}dict={'a':1,'b':2,'c':3}
dict={'a':1,'b':2,'c':3}dict={'a':1,'b':2,'c':3}dict={'a':1,'b':2,'c':3}
dict={'a':1,'b':2,'c':3}dict={'a':1,'b':2,'c':3}dict={'a':1,'b':2,'c':3}dict={'a':1,'b':2,'c':3}
dict={'a':1,'b':2,'c':3}
test
with open('test') as f:
print (f)
print(f.__iter__)
for line in f:
print(line)
for循环迭代文件
前提是必须是可迭代的,也就是__iter__方法
这样做的好处是
1:提供了一种同意的迭代方式,(之前只能按照下标去迭代,现在可以用next方法来执行)
2:惰性计算:可以省内存。对比列表来说,迭代器是一次取一个值读到内存中,而列表是将列表中所有的元素都读到内存中。
有好就有坏,他的缺点是
1:迭代器看起来就像一个序列,但是你永远无法预知迭代器的长度。因为它一次取一次值,永远不知它取多少次值,因为它每次只取一个值
2:不能倒着迭代,更像是一次性的,只能有一遍
可迭代的:只要有__iter__方法,都是可迭代的,只要能被for循环迭代的都是可迭代的对象
迭代器:既有__iter__方法又有__next__
验证是否可迭代
from collections import Iterable,Iterator
print(isinstance('abcsdad',Iterable))
from collections import Iterable,Iterator
print(isinstance('[]',Iterable))
from collections import Iterable,Iterator
print(isinstance('()',Iterable))
from collections import Iterable,Iterator
print(isinstance('{}',Iterable))
#通过上面的命令可以查看是否可迭代 print(isinstance({}.__iter__(),Iterator))
print(isinstance(().__iter__(),Iterator))
print(isinstance([].__iter__(),Iterator))
print(isinstance('asdasd'.__iter__(),Iterator))
#通过使用__iter__变成迭代器 with open('test') as f:
print(f.__next__())
print(isinstance(f,Iterable))
print(isinstance(f,Iterator))
#文件就是一个迭代器
生成器
凡事在函数内部有yield关键字,那么这个函数就是一个生成器
def foo():
print('第一次执行')
yield 1
print('第二次执行')
yield 2
print('第三次执行')
yield 3
print('第四次执行')
yield 4
g=foo()
print(g)
e,g
得到的结果是
<generator object foo at 0x0065A030> #generator就是生成器
函数加括号调用首相会检查语法有没有错误,其次是执行 然后检查函数当中有没有yield 于是这个执行会变成一个生成器
print(isinstance(g,Iterator))
#通过这个命令来查看发现生成器就是一个迭代器,那么它就是一个序列,跟字典列表..一样 也就可以用next取值
例子中的函数加括号并不会执行,而是通过next来执行
注意:这个执行并不会全部执行,而是遇到一个yield后停止执行,通过next进行执行,然后继续执行,直到遇到一个新的yield后又会停止,再通过next来执行。下一次的执行基于上一次执行的位置开始
如果函数中有yield那么就可以把函数当成序列来看(迭代器来看)
def foo():
print('第一次执行')
yield 1
print('第二次执行')
yield 2
print('第三次执行')
yield 3
print('第四次执行')
yield 4
g=foo()
for i in g:
print(i) #通过生成器来for循环函数
这个的厉害之处就是函数已经不是函数了 而是一段数据流 ,取一个值,然后暂停,下一次在取一个值...。(节约内存)
yield的功能:
1.yield是为函数定制__iter__和__next__方法,这就提供了一种自定义迭代器的优雅的方法
2.yield就像于return,return可以返回什么yield也可以。但是可以返回多次
3.生成器本质就是一个数据流,next(生成器)才会触发生成器函数的一次执行,下一次next会从上次暂停的位置继续执行,直到重新遇到一个yield
协程函数
协助程序函数,本质就是生成器(包含yield)
def eater():
print('start to eat')
while True:
food=yield
print('is eating food:%s' %food) test=eater()
next(test) #先next一次 来"唤醒"协成函数
#然后下面的操作都是test.send(值)
test.send('bread')#将值发给yield
...
例子
函数间交互
def eater():
print('start to eat')
while True:
food=yield
print('is eating food:%s' %food) def Send():
test = eater()
next(test) #这函数中的这个操作触发上面的函数
test.send('bread') #send操作传值给上面函数
test.send('milk')
Send()
#区别在于两个函数间的交互
两个函数的交互
函数交互的关键就是第一步唤起操作,有的时候很多人都容易忘记这步操作。
所以定义为成一个装饰器,那样可以通过装饰器直接唤起初始化操作
def init(func):
def wapper(*args,**kwargs):
g=func(*args,**kwargs)
next(g)
return g
return wapper @init
def eater():
print('start to eat')
while True:
food=yield
print('is eating food:%s' %food)
e=eater()
e.send('')
e,g
协程函数模仿grep -rl '想要查问的字符串'
首先在E盘下面建立一个test文件夹,然后在test下面递归的创建几个文件夹和文件进行测试
import os
import functools
def init(func):
@functools.wraps(func)
def wapper(*args,**kwargs):
'这是wrapper'
g=func(*args,**kwargs)
next(g)
return g
return wapper def get_file(abs_path,target):
'生产一个个的文件绝对路径'
g=os.walk(abs_path)
for topdir,cdir,files in g:
for file in files:
abs_file_path=r'%s\%s' %(topdir,file)
target.send(abs_file_path)
@init
def opener(target):
'打开文件获取句柄'
while True:
abs_file_path=yield
with open(abs_file_path) as f:
target.send((f,abs_file_path))
@init
def get_lines(target):
'读取文件每一行'
while True:
f,abs_file_path=yield
for line in f:
target.send((line,abs_file_path))
@init
def grep(pattern,target):
'过滤行得到想要的信息'
while True:
line,abs_file_path=yield
if pattern in line:
target.send((abs_file_path))
@init
def printer():
while True:
abs_file_path=yield
print(abs_file_path) file_name=get_file(r'E:\test',opener(get_lines(grep('python',printer()))))
e,g
上面这种方法属于一种面向过程的编写思路。核心就面向过程,将大问题分成多个小步骤,然后一步一步的进行执行,最后再穿插起来。
面向过程包括(liunx内核c语言写的,c语言就是典型的面向过程,github,apache等等都是典型的代表)。最开始编程就是面向过程。
凡事必有好坏
优势:
将复杂的问题变得清晰。解决程序复杂度
劣势:
可扩展性极其差,无法修改。这个过程建成后,无法执行别的操作,只能执行grep -rl
基本不变的场景最适合面向过程(例如操作系统,数据库这种软件)
对于现在的互联网状况,需求经常改变的情况,出现了另外一种编程思想:面向对象
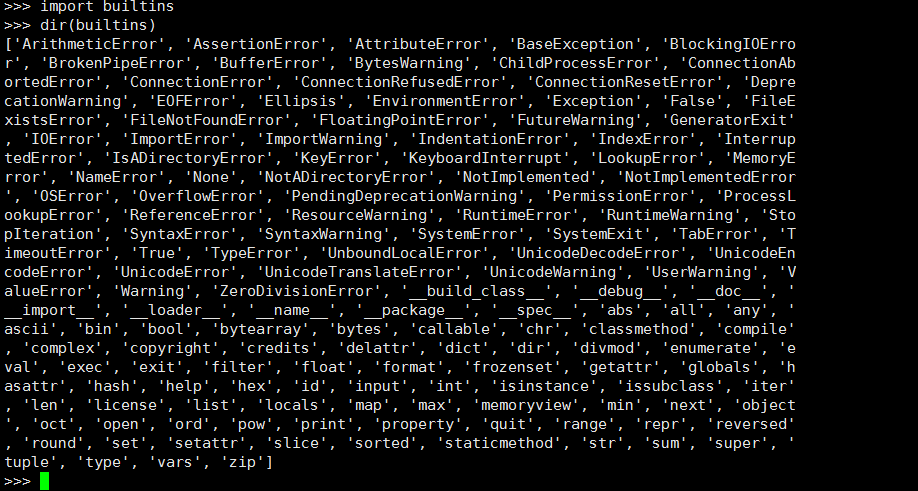
在python中还有一种函数就是內建函数

內建函数随着解释器的启动而启动
print(abs(-1)) #求绝对值 print(all([1,2,3,'a',0,[]])) #for循环查看迭代器中所有的元素,如果有一个元素为False那么则为Flash,除非所有元素都为True则为True,或者迭代器为空
print(all(''))#for循环查看迭代器中所有的元素,如果有一个元素为False那么则为Flash,除非所有元素都为True则为True,或者迭代器为空 print(any([1,2,3,'a',0,[]])) #同上面一样,但是迭代器中有一个元素是True则返回Ture
print(any('')) print(bin(123)) #10进制转二进制 print(bytes('你好',encoding='utf-8')) #将字符串转行成二进制,后面要指定一个编码格式 s='你好'
print(bytes(s,encoding='utf-8'))
print(s.encode(encoding='utf-8'))
print(s.encode(encoding='utf-8').decode(encoding='utf-8')) print(callable(all)) #是否可调用,只要名字加()就是可调用 print(chr(123)) #字符编码表:一张表中数字所对应的字符串
print(ord('{')) #字符编码表:将字符串转换成数字 compile。#python的执行过程是通过解释器,在解释之前会进行一个编译过程。
s='for i in range(10):print("i")'
code=compile(s,'','exec') #'' 可以指定代码来自哪个文件,加不加都行。exec代表着一组语句
print(code)
exec(code)
模拟语句 s='1+2+3'
code=compile(s,'','eval')
eval(code)
print(eval(code))
模拟表达式 exec跟eval都是在字符串中提取有用的信息 b=complex(1-2j)
print(b,type(b))
print(b.real,b.imag) #实部运算与需部运算 dir() #查看函数下面方法 print(divmod(10,3)) #得到元组,前面为余数,后面为商,前端分页功能 format() #格式化字符串和数字
print('{}::::::::{}'.format(1,2))
print('{1}::::{1}::::{0}'.format(1,2))
frozenset #定义集合 print(globals()) #查看全局变量
print(locals()) #查看局部变量 res='123abc'
print(hash(res)) #生成hash值 print(max(1,2,3,4)) #比较最大值 比较类型为可迭代,只能同类型比较
print(min(1,2,3,4)) #比较最大值 比较类型为可迭代,只能同类型比较
lambda
sorted print(pow(2,3,3)) #第一个数字代表一个数字,后面的数字代表他的几次方,最后一个数为前两个数的结果取余 a=[1,2,3]
print(reversed(a))
for i in reversed(a):
print(i) #取反 print(round(3.5)) #四舍五入 l=[1,2,3,4,5,6,7]
print(l[2:5:2])
s=slice(2,5,2)
print(l[s]) #大量列表都用切割[2:5:2]那样可以使用slice,节约代码。没啥软用 print(sum([-1,2,3,4])) #只能接受纯数字的迭代器,可以设定初始值 zip #拉链
name=['tom','jack','lucy']
age=['','','']
a=zip(name,age)
for i in a:
print(i) #一一对应,组成一个个元组,如果无法对应,将停止zip,不会报错
内建函数详细讲解1
# salaries={
# 'lhc':3000,
# 'hj':100000000,
# 'dh':10000,
# 'ys':2000
# }
#取出工资最高的人名
# d=zip(salaries.values(),salaries.keys())
# print(max(d)[1]) #虽然可以这么实现但是,但是用下面的方法更好些
# def get_val(k):
# return salaries[k]
# print(max(salaries,key=get_val)) #max salaries就是在for循环salaries 将key传给上面的函数,然后返回一个value进行对比,得出的结果输出key值
#这么虽然实现了,但是特别麻烦不能每次都顶一个函数,特别的low
#后来有个新的方法,如果定义的函数的函数体就是一条return(一次性函数)就是lambda(匿名函数)
# func=lambda k:salaries[k]
# lambda 的参数不需要括号,return也不需要写
# print(func('lhc'))
# 这么玩就没意思了,lmabda本身的含义就是没有名字
# print(max(salaries,key=lambda k:salaries[k]))
#最终的结果
# min与max是一样的
#排序
# print(sorted(salaries))
# print(sorted(salaries,key=lambda x:salaries[x])) #从小到大排序
# print(sorted(salaries,key=lambda x:salaries[x],reverse=True)) #从大到小
内建函数详细讲解lambda
salaries={
'lhc':8000,
'hj':100000000,
'dh':10000,
'ys':1000
}
# filter 过滤
res=filter(lambda k:salaries[k] > 3000,salaries) #两个参数第二个属于一个可迭代对象,前面是一个函数名,这个函数的返回值一定是True或者False,
for i in res:
print(i)
内建函数详解filter
l=['lhc','hj','dh','ys']
#给其他人都加上123
# 正常定义
# n_l=[]
# for i in l:
# i+='123'
# n_l.append(i)
# print(n_l)
#代码非常冗长,所以请看下面
res=map(lambda i:i+'_123',l) #通过map函数可也用一行代码写出结果,首先后面还是传入一个列表,然后for循环一次取值赋给i,i加上123返回 最后输出
print(res) 在lambda中无法加入if判断,只能全部都加123
内建函数详解map
from functools import reduce
#需求1加到一百
res=reduce(lambda x,y:x+y,range(101),10) #后面的10 位初始值因为for循环相加就是通过一个初始值然后依次循环相加,所以可以指定初始值也可以不指定初始值
print(res) #在python2.7中可以直接调用reduce,但是在python3.0中将reduce添加到functools模块中
内建函数详解reduce
python函数入门到高级的更多相关文章
- Python函数装饰器高级用法
在了解了Python函数装饰器基础知识和闭包之后,开始正式学习函数装饰器. 典型的函数装饰器 以下示例定义了一个装饰器,输出函数的运行时间: 函数装饰器和闭包紧密结合,入参func代表被装饰函数,通过 ...
- Python函数(入门6)
转载请标明出处: http://www.cnblogs.com/why168888/p/6407970.html 本文出自:[Edwin博客园] Python函数 1. Python之调用函数 pri ...
- python函数入门
知识内容: 1.函数的作用 2.函数的定义与调用 3.函数的返回值 4.函数的参数 5.局部变量与全局变量 6.作用域 一.函数的作用 1.复用代码 将可能重复执行的代码封装成函数,并在需要执行的地方 ...
- Python——函数入门(三)
一.变量作用域 当程序定义一个变量时,这个变量是有它的作用范围的,变量的作用范围称为变量的作用域.根据变量的位置,分为两种: 局部变量:局部变量就是在函数中定义的变量,包括参数,都是局部变量,局部离开 ...
- Python——函数入门(二)
一.函数的参数 我们在定义函数时,可以定义形式参数(简称形参),这些形参的值在函数调用的时候才会确定,形参的值由调用者负责传入. 1.关键字参数 在Python中,函数的参数名并不是没有意义的,在调用 ...
- Python——函数入门(一)
一.理解函数 举一个例子,当我们需要重复使用一个功能的时候,不可能每次都去复制一次代码,这个时候就需要用到函数了,所谓的函数,简单来说就是给函数取一个名字,当需要用到这个功能的时候,就可以通过这个名字 ...
- 实验与作业(Python)-02 Python函数入门与温度转换程序
截止日期 实验目标 学会定义函数,使用函数.学会导入在某个文件中定义的函数. input获得值,然后通过eval或者int.float将其转换为相应的类型. 学会使用列表:访问列表.append.遍历 ...
- 实验与作业(Python)-02 Python函数入门与温度转换程序(函数、input、eval、int、float、列表)
截止日期 实验目标 学会定义函数,使用函数.学会导入在某个文件中定义的函数. input获得值,然后通过eval或者int.float将其转换为相应的类型. 学会使用列表:访问列表.append.遍历 ...
- Python爬虫入门之Urllib库的高级用法
1.设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Headers 的属性. 首先,打开我们的浏览 ...
随机推荐
- 成都Uber优步司机奖励政策(2月16日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- 武汉Uber优步司机奖励政策(12月28日到1月3日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- dva webpack 利用require.context加载多个model
dva redux数据管理都在models,根据业务不同models可能会有几十甚至上百的 [模块.js], 每次在index.js使用 app.model(require('./models/exa ...
- WEB安全--高级sql注入,爆错注入,布尔盲注,时间盲注
1.爆错注入 什么情况想能使用报错注入------------页面返回连接错误信息 常用函数 updatexml()if...floorextractvalue updatexml(,concat() ...
- List和String数组相互转化
在工作中经常会遇到需要String[] 参数的地方,我们可以先定义一个list,再转成String[] 来使用,使用list的好处自然是可以随时方便的添加删除元素,下面是方法: List list = ...
- leetcode-打家劫舍(动态规划)
你是一个专业的小偷,计划偷窃沿街的房屋.每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警. 给定一个代表每 ...
- STM32F4编程手册学习2_内存模型
STM32F4编程手册学习2_内存模型 1. 内存映射 MCU将资源映射到一段固定的4GB可寻址内存上,如下图所示. 内存映射将内存分为几块区域,每一块区域都有一个定义的内存类型,一些区域还有一些附加 ...
- STM32F4 编程手册学习1_编程模型
STM32F4 programming manual_1 1. 处理器模式与特权等级 处理器模式分为以下两种: 线程模式: 用来执行应用软件: 处理器从reset出来时,进入线程模式: CONTROL ...
- 浅谈CPU、内存、硬盘之间的关系
计算机,大家都知道的,就是我们日常用的电脑,不管台式的还是笔记本都是计算机.那么这个看着很复杂的机器由哪些组成的呢,今天就简单的来了解一下. 先放图: 图上展示的就是计算机的基本组成啦. 首先是输入设 ...
- “Hello world!”团队—文案+美工
★★★本次采访我们随机选取5位不同的潜在用户,随机选取地点进行了本次采访. (一)项目有关内容: 大家好,我们是Hello World团队.我们组目前正在开发一个飞机大战的小游戏大家应该在小时候都玩过 ...