Sparsity Invariant CNNs
Abstract
本文研究稀疏输入下的卷积神经网络,并将其应用于稀疏的激光扫描数据的深度信息完成实验。首先,我们表明,即使当丢失数据的位置提供给网络时,传统卷积网络在应用于稀疏数据时性能也很差。为了克服这个问题,我们提出了一个简单而有效的稀疏卷积层,它在卷积运算中明确地考虑了丢失数据的位置。
我们在各种baseline方法的合成和实际实验中证明了所提出的网络架构的好处。与密集型的baseline相比,提出的稀疏卷积网络可以很好地推广到新的数据集,并且对于数据稀疏性水平是不变的。
对于我们的评估,我们从KITTI banecmark中推导出一个新的数据集,其中包含超过94k深度注释(depth annotated)的RGB图像。我们的数据集允许在具有挑战性的现实世界中对深度完成和深度预测技术进行培训和评估,并可通过以下网址在线获取:www.cvlibs.net/datasets/kitti。
1.Introduction
在过去几年中,卷积神经网络(CNN)几乎影响了计算机视觉的所有领域。在大多数情况下,CNN的输入是一个图像或视频,由人口稠密的矩阵或张量表示。通过将卷积层与非线性层和汇聚层相结合,CNN能够学习分布式表示,提取第一层中的低层特征,然后在后续层中依次提供更高层次的特征。然而,当网络的输入是稀疏和不规则的(例如,当只有10%的像素携带信息时),对于每个滤波器位置应如何定义卷积运算变得不太清楚,输入的数量和位置会发生变化。
解决这个问题的一个简单的方法是给所有无信息的位置分配一个默认值[3,32]。不幸的是,这种方法将导致次优的结果,因为学习过滤器必须对所有可能的激活模式保持不变,其数量随着过滤器尺寸呈指数增长。
在本文中,我们调查了一个简单而有效的解决方案,该方法胜过了naive approach and several other baselines。 特别是,我们引入了一个新的稀疏卷积层,它根据输入像素的有效性对卷积核的元素进行加权。另外,第二个stream将关于像素的有效性的信息传送给网络的后续层。
这使我们的方法能够处理大量的稀疏性数据,而不会显着降低准确性。
重要的是,我们的表示对输入的稀疏程度是不变的。正如我们的实验所证明的那样,在稀疏水平上训练我们的网络与测试中的稀疏水平不同,并不会显着恶化结果。这具有重要的应用,例如,在机器人技术中,算法必须对传感器配置的变化具有鲁棒性。
所提出的技术的一个重要应用领域是增强3D激光扫描数据,说明请看图1。 尽管激光扫描仪提供了有关深度和反射率的宝贵信息,但由此产生的点云通常非常稀疏,特别是在考虑使用自主驾驶时使用的Velodyne HDL-64e1等移动扫描仪时[13]。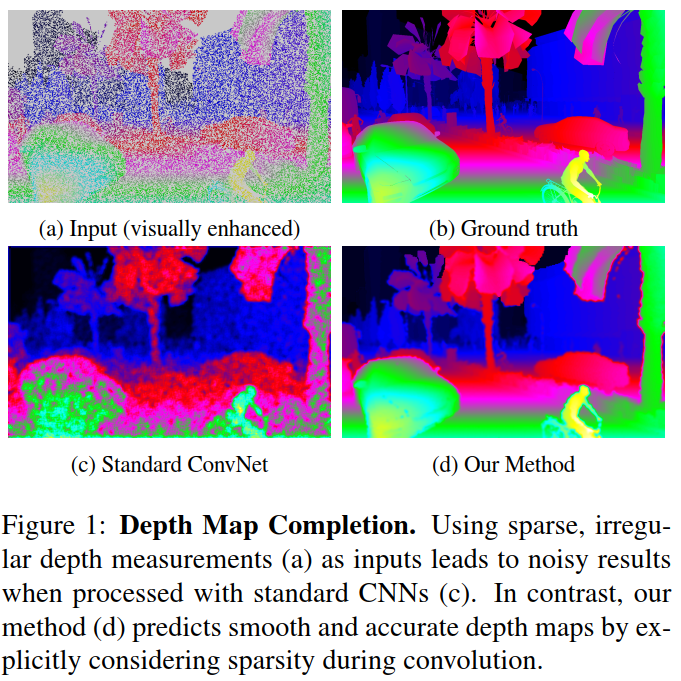
因此,能够增加这种扫描密度的学习模型是非常需要的。不幸的是,不影响精度的条件下直接在3D中处理高分辨率数据是极具挑战性的[44]
我们在本文中采用的另一种方法是将激光扫描投影到虚拟或真实的2D图像平面上,从而产生2.5D的特征表示。除了将深度预测建模为二维回归问题之外,这种表示还具有可以轻松集成更多密集信息的优势(例如,来自彩色相机的RGB值)。但是,投影激光扫描通常非常稀疏,不能保证与常规像素网格对齐,因此在使用标准CNN进行处理时导致效果不佳。相反,使用本文所提出的方法,即使输入是稀疏和不规则分布的,也能产生令人信服的结果。
我们在ablation studies 和一些最先进的baseline上评估我们的方法。对于我们的评估,我们利用Synthia综合数据集[45]以及一个新提出的具有93k深度注释图像的真实世界数据集(KITTI)[12]。我们的数据集是第一个为此场景提供大量高质量深度注释的数据集。 除了在深度和语义方面达到更高的准确度外,我们还展示了我们的方法在不同数据集和稀疏级别之间进行概括的能力。 我们的代码和数据集将在文章发表后公开。
2.Related Work
在本节中,我们将讨论在稀疏输入上操作的方法,然后讨论考虑CNN中稀疏性的技术。我们简要讨论了不变表示学习(invariant representation learning)中的最新技术,并结合相关的深度完成技术进行了综述。
CNNs with Sparse Inputs:
处理稀疏输入的简单方法是将无效值归零或为编码每个像素有效性的网络创建额外的输入通道。为了在激光扫描中检测物体,Chen et al. [3] and Li et al. [32]将激光扫描仪扫描的三维点云投影到低分辨率图像上,将缺失值归零并在这个输入上运行标准的CNN。对于光流插值和修补,Zweig et al. [59] and Koehler et al. [28]将额外的二进制有效性掩码传递给网络。但正如我们的实验所证明的那样,这两种策略与明确考虑卷积层内部的稀疏性相比而言,其结果是次优的。
Jampani et al. [25]使用双边滤波器作为CNN内部的层,并学习相应的超平面卷积核的参数。虽然他们的图层也处理稀疏不规则输入,但它需要引导信息来构建有效的超平面表示,并且对于大型网格来说在计算上是昂贵的。 与他们的方法相比,我们的稀疏卷积网络在深度完成时产生明显更好的结果,同时与常规CNN一样有效。
Graham [15, 16] and Riegler et al. [44]考虑了稀疏的3D输入。与我们的工作相反,他们的重点是通过根据输入划分空间来提高计算效率和内存需求。 然而,采用常规的卷积层,其具有与上述方法相同的缺点。
Sparsity in CNNs:
论文[17,33,41,54,10]也考虑卷积神经网络中的稀疏性。Liu et al. [33]展示了如何使用稀疏分解来减少参数中的冗余。他们的方法消除了超过90%的参数,在ILSVRC2012实验的精度下降不到1%。Wen et al. [54]提出正则化深层神经网络的结构(即滤波器,通道和层深度)以获得硬件层面友好的表示。他们报告说,对于常规卷积神经网络,加速因数为3到5。虽然这些工作着眼于通过利用网络内的稀疏性来提高神经网络的效率,但我们认为稀疏输入的问题并且不能解决效率问题。 两条线的组合将成为未来研究的有趣方向。
Invariant Representations:
学习模型对输入变化的稳健性是计算机视觉的长期目标。确保健壮性的最常用解决方案是数据增强[50,30,31]。最近,几何不变量(例如旋转,透视变换)已直接纳入CNN滤波器[4,55,58,24,20]。在本文中,我们认为学习表示的问题对输入的稀疏性水平是不变的。 正如我们的实验所证明的那样,即使训练和测试集之间的稀疏水平显着不同,我们的模型也表现良好。这具有重要的意义,因为它允许替换传感器(例如,激光扫描仪)而不重新训练网络。
…………
4.Large-Scale Dataset
对提出的深度完成方法进行培训和评估需要大量带注释的数据集。虽然对合成数据集[45,11,39]的评估是可能的,但这些数据集的真实水平用以挑战的现实世界情况下是否还能保持算法的性能,仍然是一个悬而未决的问题。
不幸的是,所有具有纯净深度groundtruth的现实世界数据集规模都很小。The Middlebury benchmark [48, 47] provides depth estimates only fora dozen images and only in controlled laboratory conditions. While the Make3D dataset [46] considers more realistic scenarios, only 500 images of small resolution are provided. Besides, KITTI [13, 37] provides 400 images of street scenes with associated depth ground truth. 然而,这些数据集都不足以进行高容量的深度神经网络的端到端训练。
对于我们的评估,我们基于KITTI原始数据集[12]创建了一个新的大规模数据集,该数据集包含超过94k的半密集深度groundtruth。虽然KITTI原始数据集以原始Velodyne扫描的形式提供深度信息,但通常需要进行人工工作来消除激光扫描中的噪声(例如,由于激光扫描器和相机的投影中心不同)或场景中的反射/透明表面造成的伪影[13]。 因此非常希望自动执行此任务。
在本文中,我们建议通过比较扫描深度与使用半全局匹配(SGM)的立体重建方法的结果来去除激光扫描中的异常值[21]。立体重建通常会导致物体边界出现深度渗漏伪影,同时LiDaR传感器也会沿着它们的运动方向创造出条纹伪影。为了消除这两种异常值,我们强化激光扫描和立体重建之间的一致性,并移除表现出相对较大误差的所有LiDaR点。为了比较两种测量结果,我们使用KITTI提供的校准文件将SGM视差图转换为深度值。我们进一步遵循[13]的方法并累积11次激光扫描来增加生成的深度图的密度。尽管环境大多是静态的,但一些KITTI序列包含动态对象,其中激光扫描累积会在动态对象上产生许多异常值。因此,我们仅使用SGM深度图一次来清洁积累的激光扫描投影(而不是单独清洁每个激光扫描),以便一步移除所有异常值:遮挡,动态运动和测量伪像。我们还观察到,由于反射和透明表面造成的大多数误差可以通过这种简单的技术来消除,因为SGM和LiDaR在这些地区很少达成一致。
…………
5.Experiments
5.1 Depth Upsampling
我们研究了深度完成任务,以评估稀疏输入数据对稀疏卷积模块的影响。 对于这项任务,从投影激光扫描得到的稀疏的、不规则填充的深度图‘完成’到全分辨率的图像,其中没有任何RGB图像的指引。
我们首先在具有不同程度稀疏性的输入中评估我们方法的性能。为了达到这个目标,我们利用了Ros et al. [45]的Synthia数据集。这使我们可以完全控制稀疏度。为了人为地调整输入的稀疏性,我们在训练期间将提供的稠密深度图随机丢失一部分数据, 像素被丢弃的概率设置为从0%到95%的不同水平。
Sparsity Invariant CNNs的更多相关文章
- (转)The 9 Deep Learning Papers You Need To Know About (Understanding CNNs Part 3)
Adit Deshpande CS Undergrad at UCLA ('19) Blog About The 9 Deep Learning Papers You Need To Know Abo ...
- React-Native坑:Invariant Violation:Application 项目名 has not been registered.
前言 在学习一门新技术的你也许有跟我一样的困惑,照着书上或者视频上的敲了.但是就是有各种问题没有出来自己想要的结果.我会将自己在这个过程中遇到的坑都记录下来,不一定全覆盖,但希望这些文章可以解决你的问 ...
- No Entity Framework provider found for the ADO.NET provider with invariant
在使用EF的时候,我把EF的EDMX放在单独的一个project中,UI中引用这个project的dll, 运行的时候就是提示No Entity Framework provider found fo ...
- EntityFrame Work:No Entity Framework provider found for the ADO.NET provider with invariant name 'System.Data.SqlClient'
今天试着学习了Entity Frame Work遇到的问题是 The Entity Framework provider type 'System.Data.Entity.SqlServer.SqlP ...
- (转)Image Segmentation with Tensorflow using CNNs and Conditional Random Fields
Daniil's blog Machine Learning and Computer Vision artisan. About/ Blog/ Image Segmentation with Ten ...
- BRISK: Binary Robust Invariant Scalable Keypoints
注意:本文含有一些数学公式,如果chrome不能看见公式的话请用IE打开网站 1.特征点提取 特征点提取有以下几个步骤: a.尺度空间金字塔结构的构造 和SIFT类似,尺度空间金字塔是由不同的尺度 ...
- 循环不变量loop invariant 与 算法的正确性
在论述插入排序的正确性的时候, 书中引入了循环不变量的概念, 刚开始稍微有点不太明白, 早上查了一波资料之后决定把自己的理解记录下来. 什么是循环不变量 ? 在我看来, 所谓循环不变量的就是一个在循环 ...
- 不变(Invariant), 协变(Covarinat), 逆变(Contravariant) : 一个程序猿进化的故事
阿袁工作的第1天: 不变(Invariant), 协变(Covarinat), 逆变(Contravariant)的初次约 阿袁,早!开始工作吧. 阿袁在笔记上写下今天工作清单: 实现一个scala类 ...
- ADO.NET provider with invariant name 'System.Data.SqlClient' could not be loaded
The Entity Framework provider type 'System.Data.Entity.SqlServer.SqlProviderServices, EntityFramewor ...
随机推荐
- react-router-dom实现全局路由登陆拦截
相比与vue的路由集中式管理,能够很好的进行统一的路由操作,react的路由看起来更乱,想要进行像vue的全局路由管理不是那么得心应手.在我们的项目中,有很多页面是需要登陆权限验证的,最好的方式就是能 ...
- FireDAC的SQLite初探
// uses FireDAC.VCLUI.Wait 之后, 可不用添加 TFDGUIxWaitCursor TFDConnection // 数据连接 TFDQuery ...
- spark成长之路(1)spark究竟是什么?
今年6月毕业,来到公司前前后后各种事情折腾下来,8月中旬才入职.本以为终于可以静下心来研究技术了,但是又把我分配到了一个几乎不做技术的解决方案部门,导致现在写代码的时间都几乎没有了,所以只能在每天下班 ...
- Spark在实际项目中分配更多资源
Spark在实际项目中分配更多资源 Spark在实际项目中分配更多资源 性能调优概述 分配更多资源 性能调优问题 解决思路 为什么调节了资源以后,性能可以提升? 性能调优概述 分配更多资源 性能调优的 ...
- Drill-On-YARN
1. Drill-On-YARN介绍 功能 启动 停止 扩容 缩容 failover 启动流程 下载drill的社区包,进行必要的配置,执行drill-on-yarn.sh start命令,启动dri ...
- 报错: Name node is in safe mode
将本地文件拷贝到hdfs上去,结果上错误:Name node is in safe mode 这是因为在分布式文件系统启动的时候,开始的时候会有安全模式,当分布式文件系统处于安全模式的情况下,文件系统 ...
- django的验证码
pip install Pillow==3.4.1在views.py中创建一个视图函数 from PIL import Image, ImageDraw, ImageFont from django. ...
- java中有关Volatile的几个小题
1.java中能创建volatile数组吗? 能,java中可以创建volatile数组,不过只是一个指向数组的引用,而不是整个数组,如果改变引用指向的数组,将会受到volatile的保护,但是如果多 ...
- 成都Uber优步司机奖励政策(4月2、3日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- LeetCode: 59. Spiral Matrix II(Medium)
1. 原题链接 https://leetcode.com/problems/spiral-matrix-ii/description/ 2. 题目要求 给定一个正整数n,求出从1到n平方的螺旋矩阵.例 ...