爬虫实战【13】获取自己的动态代理ip池
在爬取一些比较友好的网站时,仍然有可能因为单位时间内访问次数过多,使服务器认定为机器访问,导致访问失败或者被封。如果我们使用不同的ip来访问网站的话,就可以绕过服务器的重复验证,使服务器以为使不同的人在访问,就不会被封了。
如何获取动态ip
网络上有很多提供代理ip的网站,我们经常使用的一个是西刺免费代理ip,url='http://www.xicidaili.com/'
我们来看一下这个网站的构成:
【插入图片,西刺代理页面】
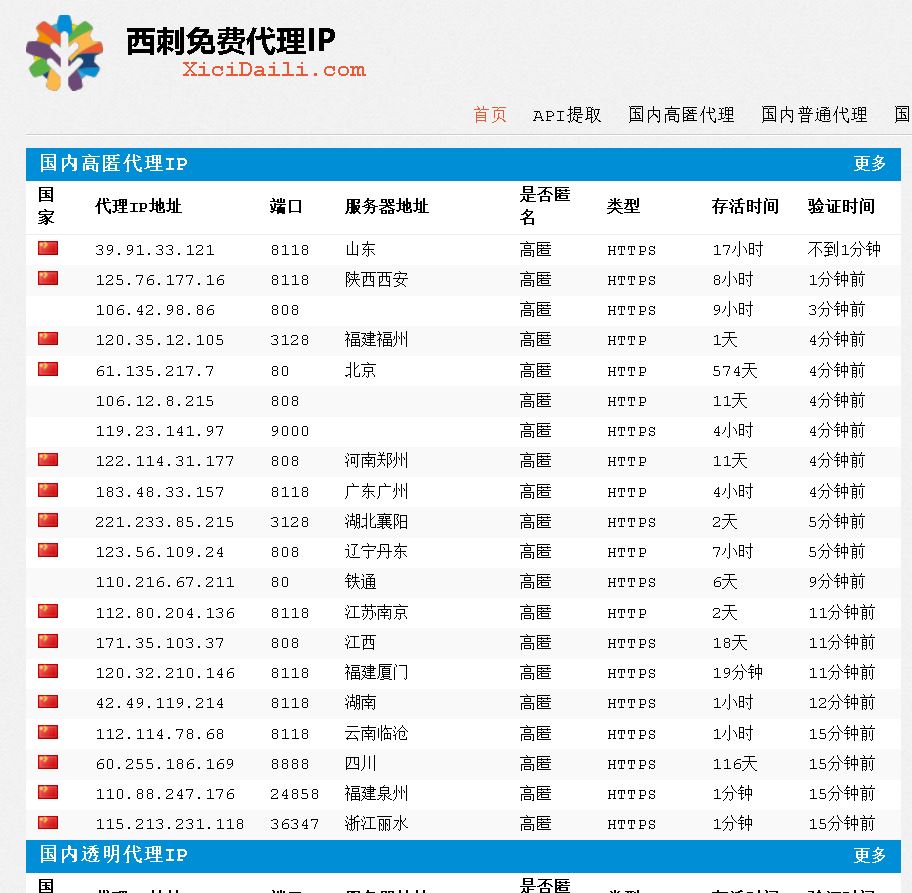
我们获取这个页面上的所有ip即可。
一个合理的代理ip的格式是这样的:
{'http':'http://106.46.136.112:808'}
也就是说每个代理是一个字典,这个字典中可以有很多个ip,每个代理ip都是以http为key。当然考虑到字典的特性,如果我们只获取http为key的代理,那么这个字典中只能有一个元素。
我们就简单点,只考虑http的情况。
通过PyQuery来解析西刺的源代码,所有的ip都在一个tr里面,但是有些tr是标题,我们过滤一下就可以了。
由于页面比较简单,这里就不做介绍了。
如何使用代理ip
我们以requests库为例:
import requests
#这个字典可以只有一个键值对,如果只考虑http的情况
proxies = {
"http": "http://10.10.1.10:3128",
"https": "http://10.10.1.10:1080"
}
requests.get("http://example.org", proxies=proxies)
全部代码
西刺也是有访问限制的,短时间内多次访问会被封锁,所以最好的办法是每个一个小时访问一下,将所有的代理ip保存到本地。
每次需要ip的时候从本地获取。
在下面的例子中,我们先获取到一个ip池,当然是文本格式的,然后短时间内访问了200次豆瓣主页,都成功了。
import requests
from pyquery import PyQuery
import random
def get_ip_page():
url = 'http://www.xicidaili.com/'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0'
} # 不加请求头信息还不能获取到源代码信息
response = requests.get(url, headers=headers)
try:
if response.status_code == 200:
# print(response.text)
return response.text
except Exception:
print('获取ip出错!')
def parse_save_ip():
html = get_ip_page()
doc = PyQuery(html)
even_ips = doc('tr').items()
result = []
try:
for item in even_ips:
ip = item.find('td').eq(1).text()
port=item.find('td').eq(2).text()
# http=item.find('td').eq(5).text()
# proxy_ip={http:ip}
# result.append(proxy_ip)
if ip != '':
# print(ip)
result.append('http://'+ip+':'+port)
except Exception:
pass
with open('proxy.csv','w') as f:
for item in result:
f.write(item)
def get_random_ip():
#短时间内连续访问多次会被封住,将获取的代理ip存到本地,每个小时获取1次即可。
with open('proxy.csv','r') as f:
ips=f.readlines()
random_ip = random.choice(ips)
proxy_ip = {'http': random_ip}
return proxy_ip
def how_to_use_proxy(proxy):
url='https://www.douban.com/'
webdata=requests.get(url=url,proxies=proxy)
print(webdata)
def main():
proxy = get_random_ip()
print(proxy)
how_to_use_proxy(proxy)
if __name__ == '__main__':
parse_save_ip()
for i in range(200):
main()
print('第%d次访问成功!'%(i+1,))
爬虫实战【13】获取自己的动态代理ip池的更多相关文章
- 做了一个动态代理IP池项目,邀请大家免费测试~
现在出来创业了,目前公司在深圳. 做了啥呢, 做了一个动态代理 IP 池项目 现在邀请大家免费测试体验! 免费激活码:关注微信公众号:2808proxy (每人每天限领一次噢~) 网站:https:/ ...
- Python爬虫代理IP池
目录[-] 1.问题 2.代理池设计 3.代码模块 4.安装 5.使用 6.最后 在公司做分布式深网爬虫,搭建了一套稳定的代理池服务,为上千个爬虫提供有效的代理,保证各个爬虫拿到的都是对应网站有效的代 ...
- scrapy-redis+selenium+webdriver解决动态代理ip和user-agent的问题(全网唯一完整代码解决方案)
问题描述:在爬取一些反爬机制做的比较好的网站时,经常会遇见一个问题就网站代码是通过js写的,这种就无法直接使用一般的爬虫工具爬取,这种情况一般有两种解决方案 第一种:把js代码转为html代码,然后再 ...
- 【python3】如何建立爬虫代理ip池
一.为什么需要建立爬虫代理ip池 在众多的网站防爬措施中,有一种是根据ip的访问频率进行限制的,在某段时间内,当某个ip的访问量达到一定的阀值时,该ip会被拉黑.在一段时间内被禁止访问. 这种时候,可 ...
- 建立爬虫代理IP池
单线程构建爬虫代理IP池 #!/usr/bin/python3.5 # -*- coding:utf-8 -*- import time import tempfile from lxml impor ...
- 构建一个给爬虫使用的代理IP池
做网络爬虫时,一般对代理IP的需求量比较大.因为在爬取网站信息的过程中,很多网站做了反爬虫策略,可能会对每个IP做频次控制.这样我们在爬取网站时就需要很多代理IP. 代理IP的获取,可以从以下几个途径 ...
- python爬虫构建代理ip池抓取数据库的示例代码
爬虫的小伙伴,肯定经常遇到ip被封的情况,而现在网络上的代理ip免费的已经很难找了,那么现在就用python的requests库从爬取代理ip,创建一个ip代理池,以备使用. 本代码包括ip的爬取,检 ...
- 爬虫入门到放弃系列05:从程序模块设计到代理IP池
前言 上篇文章吧啦吧啦讲了一些有的没的,现在还是回到主题写点技术相关的.本篇文章作为基础爬虫知识的最后一篇,将以爬虫程序的模块设计来完结. 在我漫(liang)长(nian)的爬虫开发生涯中,我通常将 ...
- 如何建立自己的代理IP池,减少爬虫被封的几率
如何建立自己的代理IP池,减少爬虫被封的几率 在爬虫过程中,难免会遇到各种各样的反爬虫,运气不好,还会被对方网站给封了自己的IP,就访问不了对方的网站,爬虫也就凉凉. 代理参数-proxies 首先我 ...
随机推荐
- unity3d创建window
unity3d创建windwo的方法如下: GUILayout.Window (, new Rect (50, 50, 200, 100), Func1, "窗口1"); 第一个参 ...
- 电子商务(电销)平台中用户模块(User)数据库设计明细(转载)
电子商务(电销)平台中用户模块(User)数据库设计明细 以下是自己在电子商务系统设计中的订单模块的数据库设计经验总结,而今发表出来一起分享,如有不当,欢迎跟帖讨论~ 用户基础表(user_base) ...
- js 判断是否为mac电脑 、还是windows操作系统
/** * 是否为mac系统(包含iphone手机) * */ var isMac = function() { return /macintosh|mac os x/i.test(navigator ...
- [git]git命令行自动补齐
1. 下载Git-completion.bash github地址:https://github.com/markgandolfo/git-bash-completion.git 2. copy到用户 ...
- Android开发-状态栏着色原理和API版本号兼容处理
介绍 先上实际效果图,有三个版本号请注意区分API版本号 API>=20 API=19 API<19 watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZX ...
- django rest framework(10)
1.权限 2.认证 3.访问频率限制 4.序列化 5.路由 6.视图 7.分页 8.解析器 9.渲染器 10.版本 面试题:你写的类都继承过哪些类? class Vive(object): class ...
- The Way to Go读书笔记_第4章_基本结构和基本数据类型
“_”标识符 _ 本身就是一个特殊的标识符,被称为空白标识符.它可以像其他标识符那样用于变量的声明或赋值(任何类型都可以赋值给它),但任何赋给这个标识符的值都将被抛弃,因此这些值不能在后续的代码中使用 ...
- Tomcat下配置多个Project的虚拟主机
server.xml中,添加<Context path="/project2" docBase="D:\MyProjects\project2\WebContent ...
- 质问微软 WP8.1开发HTTPS 真费劲
本人用C#多年,WPF2年,一直想做点应用为WP生态贡献一点力量,最近终于有机会接触了 家里的本子是2年前的低压I3,不支持虚拟化,一直没有真机.最近同事妈妈换下来一个820给我拿来做开发用,非常感谢 ...
- spring security 一个能够为基于Spring的企业应用系统提供声明式的安全访问控制解决方案的安全框架
Spring Security是一个能够为基于Spring的企业应用系统提供声明式的安全访问控制解决方案的安全框架.它提供了一组可以在Spring应用上下文中 配置的Bean,充分利用了Spring ...