sharding-JDBC 实现读写分离
需求
- 一主两从,做读写分离。
- 多个从库之间实现负载均衡。
- 可手动强制部分读请求到主库上。(因为主从同步有延迟,对实时性要求高的系统,可以将部分读请求也走主库)
本次不讨论 MySQL如何配置主从同步相关问题
库表SQL
-- 主库
CREATE DATABASE `master`;
CREATE TABLE `t_order` (
`order_id` int(11) NOT NULL,
`user_id` int(11) NOT NULL,
`business_id` int(4) DEFAULT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `t_order` VALUES (1,1,112);
-- 从库1
CREATE DATABASE `slave1` ;
CREATE TABLE `t_order` (
`order_id` int(11) NOT NULL,
`user_id` int(11) NOT NULL,
`business_id` int(4) DEFAULT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 ;
INSERT INTO `t_order` VALUES (2,2,112);
-- 从库2
CREATE DATABASE `slave2` ;
CREATE TABLE `t_order` (
`order_id` int(11) NOT NULL,
`user_id` int(11) NOT NULL,
`business_id` int(4) DEFAULT NULL,
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `t_order` VALUES (3,3,112);
pom.xml
<!-- https://mvnrepository.com/artifact/io.shardingjdbc/sharding-jdbc-core -->
<dependency>
<groupId>io.shardingjdbc</groupId>
<artifactId>sharding-jdbc-core</artifactId>
<version>2.0.0.M2</version>
</dependency>
<dependency>
<groupId>io.shardingjdbc</groupId>
<artifactId>sharding-jdbc-spring-namespace</artifactId>
<version>2.0.0.M2</version>
</dependency>
spring配置文件
<bean id="master" class="com.alibaba.druid.pool.DruidDataSource" init-method="init"
destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="${jdbc.url.master}"></property>
<property name="username" value="${jdbc.username.master}"></property>
<property name="password" value="${jdbc.password.master}"></property>
<property name="maxActive" value="100"/>
<property name="initialSize" value="10"/>
<property name="maxWait" value="60000"/>
<property name="minIdle" value="5"/>
</bean>
<bean id="slave1" class="com.alibaba.druid.pool.DruidDataSource" init-method="init"
destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="${jdbc.url.slave1}"></property>
<property name="username" value="${jdbc.username.slave1}"></property>
<property name="password" value="${jdbc.password.slave1}"></property>
<property name="maxActive" value="100"/>
<property name="initialSize" value="10"/>
<property name="maxWait" value="60000"/>
<property name="minIdle" value="5"/>
</bean>
<bean id="slave2" class="com.alibaba.druid.pool.DruidDataSource" init-method="init"
destroy-method="close">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="${jdbc.url.slave2}"></property>
<property name="username" value="${jdbc.username.slave2}"></property>
<property name="password" value="${jdbc.password.slave2}"></property>
<property name="maxActive" value="100"/>
<property name="initialSize" value="10"/>
<property name="maxWait" value="60000"/>
<property name="minIdle" value="5"/>
</bean>
<bean id="randomStrategy" class="io.shardingjdbc.core.api.algorithm.masterslave.RandomMasterSlaveLoadBalanceAlgorithm" />
<master-slave:data-source id="shardingDataSource" master-data-source-name="master" slave-data-source-names="slave1,slave2" strategy-ref="randomStrategy" />
单测
写:
@Test
public void insert() throws Exception {
Order record = new Order();
record.setBusinessId(112);
record.setUserId(111);
record.setOrderId(12212121);
int result = orderMapper.insertSelective(record) ;
System.out.println( result > 0 ? "插入成功" : "插入失败");
}
运行结果:
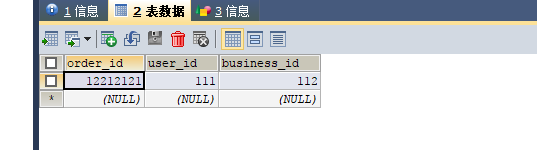
查:
slave1 只有1条数据,主键order_id = 2 ; slave2 也只有1条数据,主键order_id = 3 。所以,如果查询到的结果orderId等于1就说明读请求进入到slave1,同理,如果查询出来的orderId等于0 就说明读请求进入到slave2。
public void selectByExample3() throws Exception {
final int[] slave1 = {0};
final int[] slave2 = {0};
for (int i = 0; i < 100; i++) {
((Runnable) () -> {
OrderExample example = new OrderExample();
example.createCriteria().andBusinessIdEqualTo(112);
List<Order> orderList = orderMapper.selectByExample(example);
if (orderList.get(0).getOrderId() == 2) {
System.out.printf("读到slave1 读到的数据是{}", JSONObject.toJSONString(orderList.get(0)));
slave1[0]++;
} else if (orderList.get(0).getOrderId() == 3) {
System.out.printf("读到slave2 读到的数据是{}", JSONObject.toJSONString(orderList.get(0)));
slave2[0]++;
}
System.out.println(JSONObject.toJSONString(orderList));
}).run();
}
System.out.println("+++++++++++++++++++++++++++++++++++++++");
System.out.println("+++++++++++++++++++++++++++++++++++++++");
System.out.println("slave1读到的次数-->" + slave1[0]);
System.out.println("slave2读到的次数-->" + slave2[0]);
System.out.println("+++++++++++++++++++++++++++++++++++++++");
System.out.println("+++++++++++++++++++++++++++++++++++++++");
}
运行截图:

强制路由
通常做读写分离,都会遇到的一个问题就是主从同步延迟。有时,为了简单解决主从同步问题,我们会想强制部分读请求到主库上,而非从库上。
HintManager 分片键值管理器
官方文档的解释:
基于暗示(Hint)的分片键值管理器
但是对于读写分离这种形式的强制路由 , 其实官方文档说的几个方法都不适用. 我们可使用hintManager.setMasterRouteOnly() .
单测
@Test
public void HintManagerTest() {
HintManager hintManager = HintManager.getInstance() ;
hintManager.setMasterRouteOnly();
OrderExample example = new OrderExample();
example.createCriteria().andBusinessIdEqualTo(112);
List<Order> orderList = orderMapper.selectByExample(example);
System.out.println(JSONObject.toJSONString(orderList));
hintManager.close();
}
sharding-JDBC 实现读写分离的更多相关文章
- Sharding+SpringBoot+Mybatis 读写分离
基于Sharding JDBC的读写分离 1.引入pom.xml <dependencies> <!-- mybatis --> <dependency> < ...
- java环境下的数据库读写分离
方案很多:阿里的中间件cobar.aop注解方式.com.mysql.jdbc.ReplicationDriver读写分离驱动MySQL数据库的同步. MySQL是开源的关系型数据库系统.主从同步复制 ...
- MySQL中间件之ProxySQL(10):读写分离方法论
返回ProxySQL系列文章:http://www.cnblogs.com/f-ck-need-u/p/7586194.html 1.不同类型的读写分离 数据库中间件最基本的功能就是实现读写分离,Pr ...
- ProxySQL(10):读写分离方法论
文章转载自:https://www.cnblogs.com/f-ck-need-u/p/9318558.html 不同类型的读写分离 数据库中间件最基本的功能就是实现读写分离,ProxySQL当然也支 ...
- sharding sphere 分表分库 读写分离
sharding jdbc: sharding sphere 的 一部分,可以做到 分表分库,读写分离. 和 mycat 不同的 是 sharding jdbc 是 一个 jdbc 驱动 在 驱动这个 ...
- sharding demo 读写分离 U (分库分表 & 不分库只分表)
application-sharding.yml sharding: jdbc: datasource: names: ds0,ds1,dsx,dsy ds0: type: com.zaxxer.hi ...
- DB层面上的设计 分库分表 读写分离 集群化 负载均衡
第1章 引言 随着互联网应用的广泛普及,海量数据的存储和访问成为了系统设计的瓶颈问题.对于一个大型的 互联网应用,每天几十亿的PV无疑对数据库造成了相当高的负载.对于系统的稳定性和扩展性造成了极大的 ...
- DBA 小记 — 分库分表、主从、读写分离
前言 我在上篇博客 "Spring Boot 的实践与思考" 中比对不同规范的 ORM 框架应用场景的时候提到过主从与读写分离,本篇随笔将针对此和分库分表进行更深入地探讨. 1. ...
- spring boot sharding-jdbc实现分佈式读写分离和分库分表的实现
分布式读写分离和分库分表采用sharding-jdbc实现. sharding-jdbc是当当网推出的一款读写分离实现插件,其他的还有mycat,或者纯粹的Aop代码控制实现. 接下面用spring ...
- SpringBoot使用Sharding-JDBC读写分离
本文介绍SpringBoot使用当当Sharding-JDBC进行读写分离. 1.有关Sharding-JDBC 本文还是基于当当网Sharding-Jdbc的依赖,与上一篇使用Sharding-Jd ...
随机推荐
- BZOJ1014:[JSOI2008]火星人prefix——题解
http://www.lydsy.com/JudgeOnline/problem.php?id=1014 Description 火星人最近研究了一种操作:求一个字串两个后缀的公共前缀.比方说,有这样 ...
- BZOJ1027 [HNOI2004]打鼹鼠 【dp】
1207: [HNOI2004]打鼹鼠 Time Limit: 10 Sec Memory Limit: 162 MB Submit: 3647 Solved: 1746 [Submit][Sta ...
- 洛谷 P2324 [SCOI2005]骑士精神 解题报告
P2324 [SCOI2005]骑士精神 题目描述 输入输出格式 输入格式: 第一行有一个正整数T(T<=10),表示一共有N组数据.接下来有T个5×5的矩阵,0表示白色骑士,1表示黑色骑士,* ...
- Navicat新建查询快捷键
在Navicat中,我们选中一个表,双击打开,这是如果要新建查询这个表的sql语句,可以直接用快捷键 ctrl+q 会自动打开查询窗口,并直接写好 sql:select * from (当前打开的表 ...
- 洛谷:P2922 [USACO08DEC]秘密消息(Trie树)
P2922 [USACO08DEC]秘密消息Secret Message 题目链接:https://www.luogu.org/problemnew/show/P2922 题目描述 贝茜正在领导奶牛们 ...
- C#学习之泛型
//主函数//主函数里面调用的类都在后面有具体描述 using System; using System.Collections.Generic; using System.Linq; using S ...
- HDU 2639 背包第k优解
Bone Collector II Time Limit: 5000/2000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others ...
- HDU3336 KMP+DP
Count the string Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) ...
- 单例 ------ JAVA实现
单例:只能实例化一个对象,使用场景比如打印机. 最推荐的是采用饿汉式:双重校验锁用到了大量的语法,不能保证这些语法在所用场合一定没问题,所以不是很推荐:总之简单的才是最好的,就饿汉式!!! C++ 创 ...
- HDU 1874 SPFA/Dijkstra/Floyd
这题作为模板题,解法好多... 最近周围的人都在搞图论阿,感觉我好辣鸡,只会跟风学习. 暂时只有SPFA和Dijkstra的 SPFA (邻接表版.也可以写成临接矩阵存图,但题目可能给出平行边的,所以 ...