5 Logistic回归(一)
首次接触最优化算法。介绍几个最优化算法,并利用它们训练出一个非线性函数用于分类。
假设现在有一些数据点,我们利用一条直线对这些点进行拟合(该直线为最佳拟合直线),这个拟合过程称作回归。
利用Logistic回归进行分类思想:根据现有数据对分类边界线建立回归公式,以此进行分类。
这里的“回归”一词源于最佳拟合,表示找到最佳拟合参数。训练分类器的做法:寻找最佳拟合参数,使用的是最优化算法(梯度上升法、改进的随机梯度上升法)。
5.1 基于Logistic回归和Sigmoid函数的分类
Logistic回归:优点:计算代价不高,易于理解和实现。缺点:容易欠拟合,分类精度可能不高。适用数据类型:数值型、标称型。
Sigmoid函数:g(z)=1/(1+e-z),也可表示为hΘ(X)=g(ΘTX).
为了实现Logistic回归分类器,我们需要在每个特征上乘以一个回归系数,然后把所有结果值相加,将这个总和代入Sigmoid函数,进而得到0~1之间的数值。
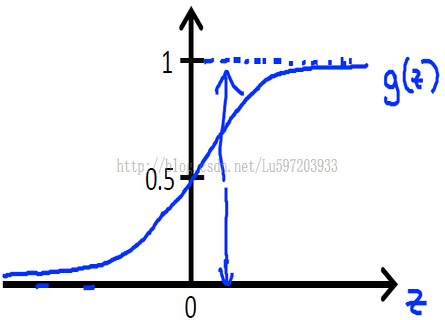
此时就可以对标签y进行分类了:

其中θTx=0 即θ0+θ1*x1+θ2*x2=0 称为决策边界即boundarydecision。
Cost function:
线性回归的cost function依据最小二乘法是最小化观察值和估计值的差平方和。即:

但是对于logistic回归,我们的cost fucntion不能最小化观察值和估计值的差平法和,因为这样我们会发现J(θ)为非凸函数,此时就存在很多局部极值点,就无法用梯度迭代得到最终的参数(来源于AndrewNg video)。因此我们这里重新定义一种cost function

通过以上两个函数的函数曲线,我们会发现当y=1,而估计值h=1或者当y=0,而估计值h=0,即预测准确了,此时的cost就为0,,但是当预测错误了cost就会无穷大,很明显满足cost function的定义。
可以将上面的分组函数写在一起:

这样得到总体的损失函数J(θ)为:

5.2 基于最优化方法的最佳回归系数确定
Sigmoid函数输入记为z, z=w0x0+w1x1+...+wnxn。如果采用向量的写法,z=wTx,表示将这两个数值向量对应的元素相乘然后全部加起来得到z值。
其中向量x是分类器的输入数据,向量w就是我们要找到的最佳参数(系数)。
5.2.1 梯度上升法
梯度上升法思想:要找到某个函数的最大值,最好的方法是沿着该函数的梯度方向探寻。如果梯度记为▽,则函数f(x,y)的梯度由下式表示:
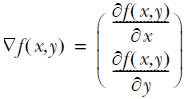 。这个梯度意味着沿x方向移动
。这个梯度意味着沿x方向移动 ,沿y方向移动
,沿y方向移动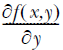 。其中,函数f(x,y)必须在待计算的点上有定义并且可微。
。其中,函数f(x,y)必须在待计算的点上有定义并且可微。
这样我们依据上面的J(θ)就可以得到梯度上升的公式:

当然上图中少了个求和符号。这样就得到

当然对于随机化的梯度迭代每次只使用一个样本进行参数更新,就为:

这也是下面代码中公式的来源。
例如:data=[1,2,3;4,5,6;7,8,9;10,11,12]为4个样本点,3个特征的数据集,,此时标签为[1,0,0,0],
那么用梯度上升
为什么要采用上面的函数作为cost function?
Andrew Ng给的解释是因为最小估计值和观察值的差平方和为非凸函数,通过函数曲线观察得到上面的cost function满足条件。
这里给出另外一种解释——最大似然估计:
我们知道hθ(x)≥0.5<后面简用h>,此时y=1, 小于0.5,y=0. 那么我们就用h作为y=1发生的概率,那么当y=0时,h<0.5,此时不能用h作为y=0的概率,<因为最大似然的思想使已有的数据发生的概率最大化,小于0.5太小了>,我们可以用1-h作为y=0的概率,这样就可以作为y=0的概率了,,然后只需要最大化联合概率密度函数就可以了。
这样联合概率密度函数就可以写成:

再转换成对数似然函数,就和上面给出的似然函数一致了。


图5-2 梯度上升算法到达每个点后都会重新估计移动的方向
图5-2中的梯度上升算法沿梯度方向移动了一步。梯度算子总是指向函数值增长最快的方向。这里说的移动方向,而未提到移动量的大小。该量值称为步长,记做α。用向量来表示的话,梯度上升算法的迭代公式如下: w:=w+α▽wf(w).
该公式将一直进行迭代,直到达到某个停止条件为止,比如迭代次数达到某个指定值或算法达到某个可以允许的误差范围。
5.2.2 训练算法:使用梯度上升找到最佳参数
训练样本:100个样本点,每个点包含两个数值型特征:x1和x2.
#coding:utf-8
from numpy import * def loadDataSet():#便利函数:打开文件并逐行读取
dataMat = []; labelMat = []
fr = open('testSet.txt')
for line in fr.readlines():
lineArr = line.strip().split()
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])#为方便计算,将x0值设为1.0
labelMat.append(int(lineArr[2]))
return dataMat, labelMat def sigmoid(inX):
return 1.0/(1+exp(-inX)) def gradAscent(dataMatIn, classLabels):#梯度上升:dataMatIn:2维NumPy数组,100*3矩阵;classLabels:类别标签,1*100行向量
dataMatrix = mat(dataMatIn)#特征矩阵
labelMat = mat(classLabels).transpose()#类标签矩阵:100*1列向量
m,n = shape(dataMatrix)
alpha = 0.001#向目标移动的步长
maxCycles = 500#迭代次数
weights = ones((n,1))#n*1列向量:3行1列
for k in range(maxCycles):
h = sigmoid(dataMatrix*weights)#100*3*3*1=100*1,dataMatrix * weights代表不止一次乘积计算,事实上包含了300次乘积
error = (labelMat - h)#真实类别与预测类别的差值
weights = weights + alpha * dataMatrix.transpose()* error#w:=w+α▽wf(w)
return weights

注:倒数第二行代码
weights = weights + alpha * dataMatrix.transpose()* error#w:=w+α▽wf(w)



5.2.3 分析数据:画出决策边界
上面已经解出一组回归系数,它确定了不同类别数据之间的分隔线。如何画出分隔线,从而使得优化过程便于理解?
#5-2:画出数据集和Logistic回归最佳拟合直线的函数
def plotBestFit(weights):
import matplotlib.pyplot as plt
dataMat, labelMat = loadDataSet()
dataArr = array(dataMat)
n = shape(dataArr)[0]#n=100
xcord1 = []; ycord1 = []
xcord2 = []; ycord2 = []
for i in range(n):
if int(labelMat[i]) == 1:
xcord1.append(dataArr[i, 1]); ycord1.append(dataArr[i, 2])
else:
xcord2.append(dataArr[i, 1]); ycord2.append(dataArr[i, 2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=30, c='red', marker='s')
ax.scatter(xcord2, ycord2, s=30, c='green')
x = arange(-3.0, 3.0, 0.1)#arange创建等差数组,-3.0起始点,3.0终止点(不包含3.0),间隔为0.1
y = (-weights[0] - weights[1] * x)/weights[2]#最佳拟合直线,设置sigmoid函数为0,0是两个分类(类别1和类别0)的分界处。因此设定0=w0x0+w1x1+w2x2,解出x1和x2关系(即分割线的方程,x0=1)。
ax.plot(x, y)
plt.xlabel('X1');plt.ylabel('X2');
plt.show()

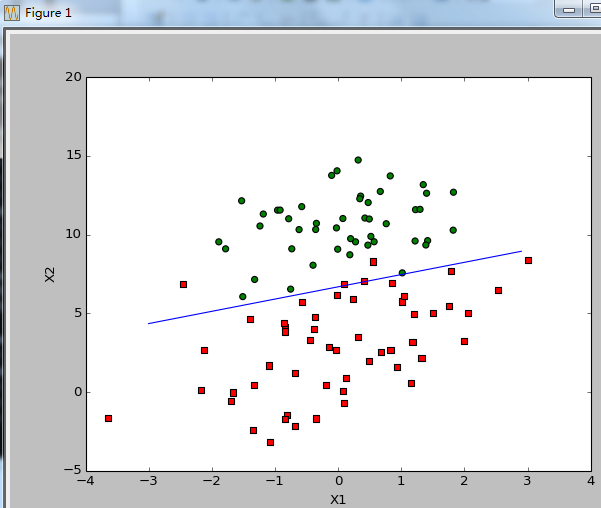
这个分类结果相当不错,尽管例子简单且数据集很小,这个方法却需要大量的计算(300次乘法)。
因此下一节将对该算法稍作改进,从而使它可以用在其他真是数据上。
注明:5.1参考下面链接
作者:小村长 出处:http://blog.csdn.net/lu597203933
5 Logistic回归(一)的更多相关文章
- 神经网络、logistic回归等分类算法简单实现
最近在github上看到一个很有趣的项目,通过文本训练可以让计算机写出特定风格的文章,有人就专门写了一个小项目生成汪峰风格的歌词.看完后有一些自己的小想法,也想做一个玩儿一玩儿.用到的原理是深度学习里 ...
- 机器学习——Logistic回归
1.基于Logistic回归和Sigmoid函数的分类 2.基于最优化方法的最佳回归系数确定 2.1 梯度上升法 参考:机器学习--梯度下降算法 2.2 训练算法:使用梯度上升找到最佳参数 Logis ...
- logistic回归
logistic回归 回归就是对已知公式的未知参数进行估计.比如已知公式是$y = a*x + b$,未知参数是a和b,利用多真实的(x,y)训练数据对a和b的取值去自动估计.估计的方法是在给定训练样 ...
- Logistic回归 python实现
Logistic回归 算法优缺点: 1.计算代价不高,易于理解和实现2.容易欠拟合,分类精度可能不高3.适用数据类型:数值型和标称型 算法思想: 其实就我的理解来说,logistic回归实际上就是加了 ...
- Logistic回归的使用
Logistic回归的使用和缺失值的处理 从疝气病预测病马的死亡率 数据集: UCI上的数据,368个样本,28个特征 测试方法: 交叉测试 实现细节: 1.数据中因为存在缺失值所以要进行预处理,这点 ...
- 如何在R语言中使用Logistic回归模型
在日常学习或工作中经常会使用线性回归模型对某一事物进行预测,例如预测房价.身高.GDP.学生成绩等,发现这些被预测的变量都属于连续型变量.然而有些情况下,被预测变量可能是二元变量,即成功或失败.流失或 ...
- SPSS数据分析—配对Logistic回归模型
Lofistic回归模型也可以用于配对资料,但是其分析方法和操作方法均与之前介绍的不同,具体表现 在以下几个方面1.每个配对组共有同一个回归参数,也就是说协变量在不同配对组中的作用相同2.常数项随着配 ...
- SPSS数据分析—多分类Logistic回归模型
前面我们说过二分类Logistic回归模型,但分类变量并不只是二分类一种,还有多分类,本次我们介绍当因变量为多分类时的Logistic回归模型. 多分类Logistic回归模型又分为有序多分类Logi ...
- SPSS数据分析—二分类Logistic回归模型
对于分类变量,我们知道通常使用卡方检验,但卡方检验仅能分析因素的作用,无法继续分析其作用大小和方向,并且当因素水平过多时,单元格被划分的越来越细,频数有可能为0,导致结果不准确,最重要的是卡方检验不能 ...
- Logistic回归分类算法原理分析与代码实现
前言 本文将介绍机器学习分类算法中的Logistic回归分类算法并给出伪代码,Python代码实现. (说明:从本文开始,将接触到最优化算法相关的学习.旨在将这些最优化的算法用于训练出一个非线性的函数 ...
随机推荐
- J2EE监听器和过滤器基础
Servlet程序由Servlet,Filter和Listener组成,其中监听器用来监听Servlet容器上下文. 监听器通常分三类:基于Servlet上下文的ServletContex监听,基于会 ...
- Kurskal算法(克鲁斯卡尔算法)
特点:适用于稀疏图,边比较少的图.如果顶点较少,且为稠密图,则用Prim算法.跟Prim算法的用途相同.时间复杂度为O(e*loge),其中e为边数. 代码: #include <stdio.h ...
- mysql优化(3) 集群配置
两台服务器 192.168.187.131 192.168.187.132 1.主从配置 131为主 132为从 在131下 vim /etc/my.cnf [mysqld] datadir=/var ...
- Flink Program Guide (2) -- 综述 (DataStream API编程指导 -- For Java)
v\:* {behavior:url(#default#VML);} o\:* {behavior:url(#default#VML);} w\:* {behavior:url(#default#VM ...
- SQL字符型字段按数字型字段排序实现方法(转)
由于是按字母顺序排列,所以123排在了2的前面,显然不符合我们的要求,那么怎样才能按照我们预想的数字顺序排序呢 ORDER BY `meta_value` 那么按得分排序得到的结果可能是:1101 ...
- Python之路第五天,基础(6)-模块
模块 模块,用一砣代码实现了某个功能的代码集合. 类似于函数式编程和面向过程编程,函数式编程则完成一个功能,其他代码用来调用即可,提供了代码的重用性和代码间的耦合.而对于一个复杂的功能来,可能需要多个 ...
- System V 机制(转)
引言 UNIX 内核管理的进程自主地操作,从而产生更稳定的系统.然而,每个开发人员最终都会遇到这样的情况,即其中一组进程需要与另一组进程通信,也许是为了交换数据或发送命令.这种通信称为进程间通信(In ...
- Amazon MWS 上传数据 (二) 构造请求
上一篇文章提到了Amazon 上传数据有三个步骤,但是每个步骤都需要构造服务和构造请求,服务是一样的,请求各不相同:这个很容易理解,这三个步骤都需要和Amazon服务器交互,所以他们的服务构造是一样的 ...
- rageagainstthecage 源代码
//头文件包含 #include <stdio.h> #include <sys/types.h> #include <sys/time.h> #include & ...
- 行变列 拼接字符串 MSSQL 一个超级搞的问题
由数据 ThreeLevelSortID KeyWordID KeyWordName key1 key2 key3 key4 得到数据大 ThreeLevelSortID KeyWordName ke ...