经典排序算法及python实现
今天我们来谈谈几种经典排序算法,然后用python来实现,最后通过数据来比较几个算法时间
选择排序
选择排序(Selection sort)是一种简单直观的排序算法。它的工作原理是每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完。 选择排序是不稳定的排序方法(比如序列[5, 5, 3]第一次就将第一个[5]与[3]交换,导致第一个5挪动到第二个5后面)。(注:选自百度百科)
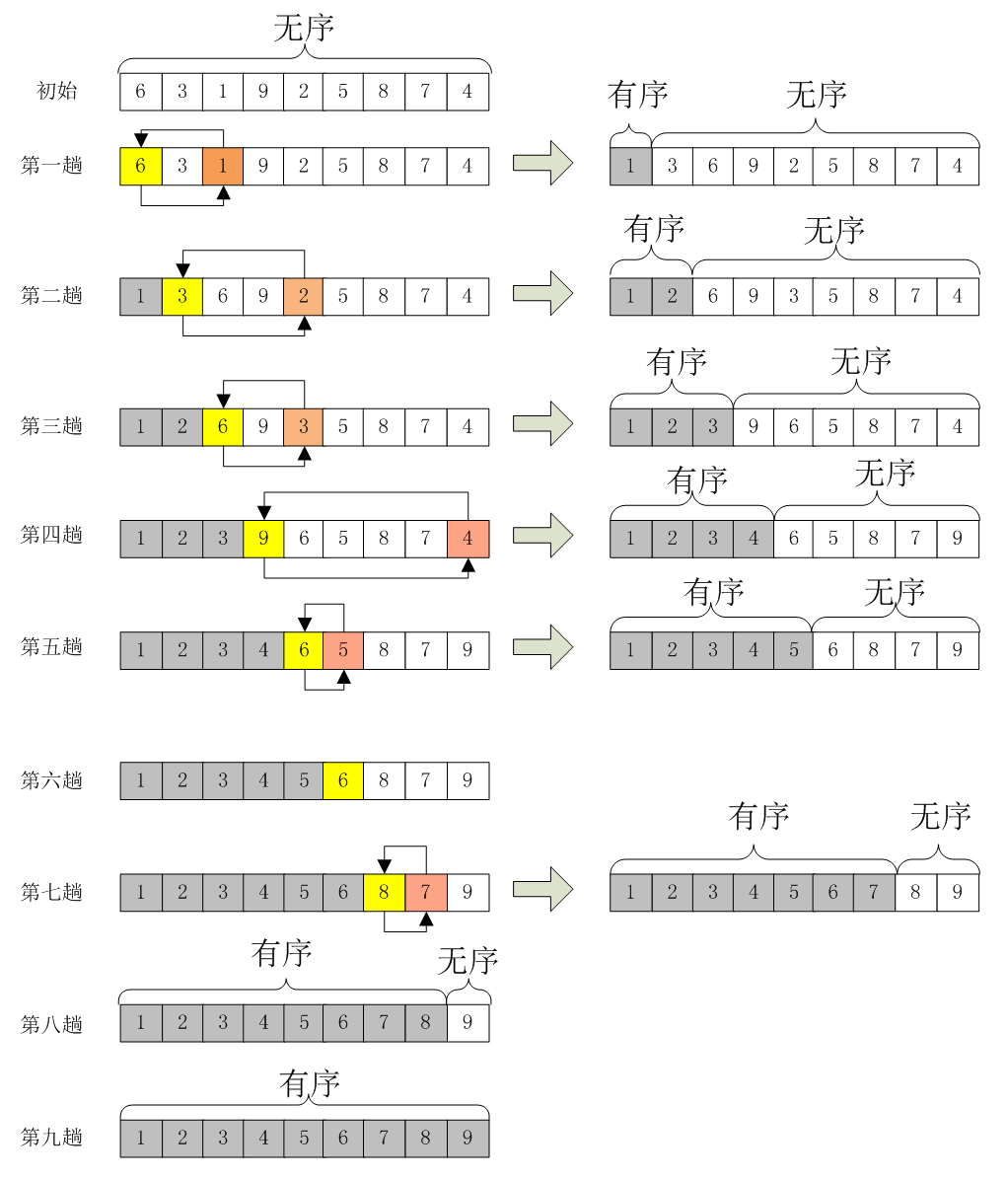
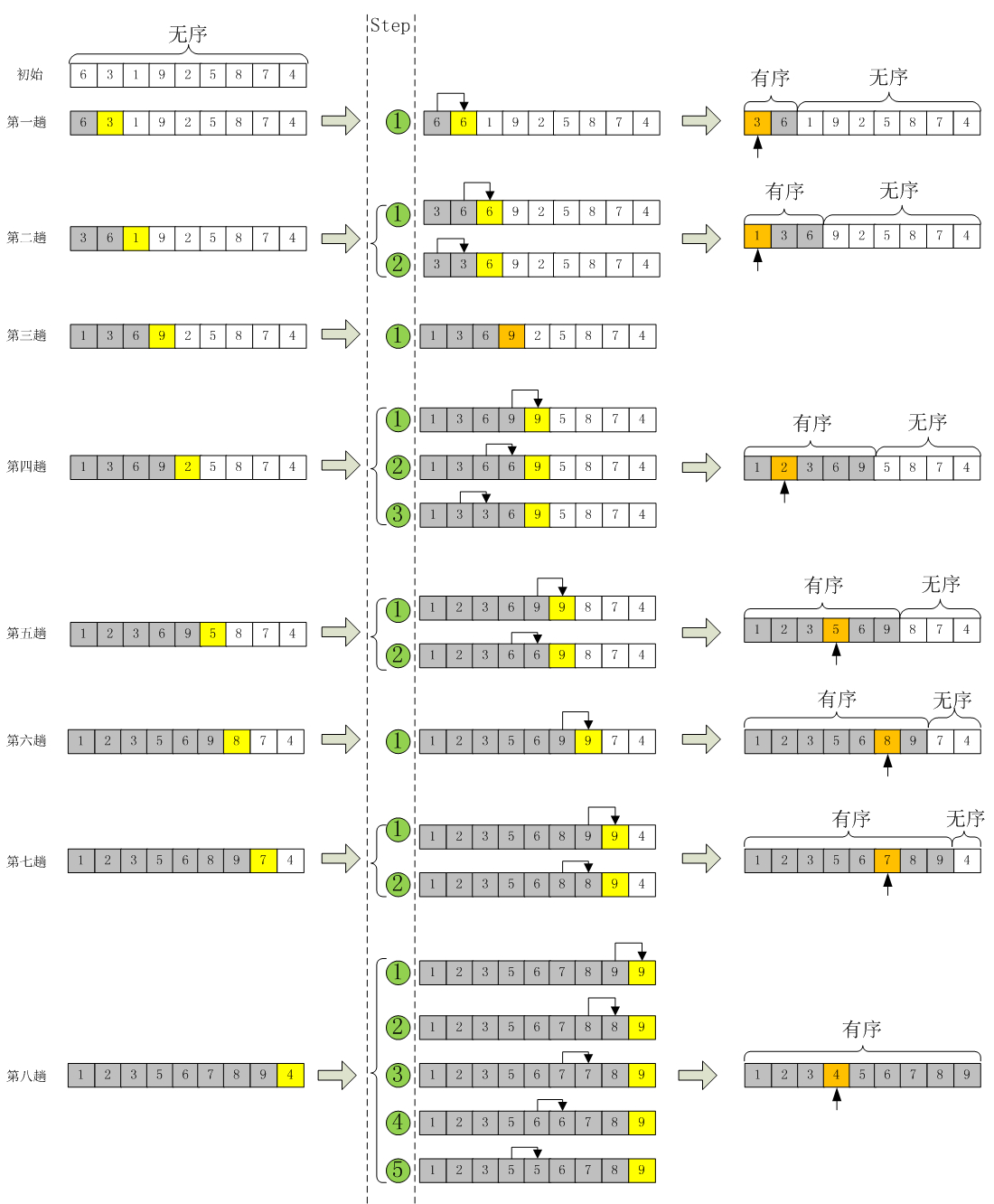
假如,有一个无须序列A={6,3,1,9,2,5,8,7,4},选择排序的过程应该如下:
第一趟:选择最小的元素,然后将其放置在数组的第一个位置A[0],将A[0]=6和A[2]=1进行交换,此时A={1,3,6,9,2,5,8,7,4};
第二趟:由于A[0]位置上已经是最小的元素了,所以这次从A[1]开始,在剩下的序列里再选择一个最小的元素将其与A[1]进行交换。即这趟选择过程找到了最小元素A[4]=2,然后与A[1]=3进行交换,此时A={1,2,6,9,3,5,8,7,4};
第三趟:由于A[0]、A[1]已经有序,所以在A[2]~A[8]里再选择一个最小元素与A[2]进行交换,然后将这个过程一直循环下去直到A里所有的元素都排好序为止。这就是选择排序的精髓。因此,我们很容易写出选择排序的核心代码部分,即选择的过程,就是不断的比较、交换的过程。
整个选择的过程如下图所示:

算法实现:
'''
选择排序
'''
def Selection_sort(a):
for i in range(len(a) - 1):
min = i
for j in range(i + 1, len(a)):
if a[min] > a[j]:
min = j
if min != i:
a[min], a[i] = a[i], a[min]
return a
冒泡排序
介绍:
冒泡排序(Bubble Sort,台湾译为:泡沫排序或气泡排序)是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
步骤:
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
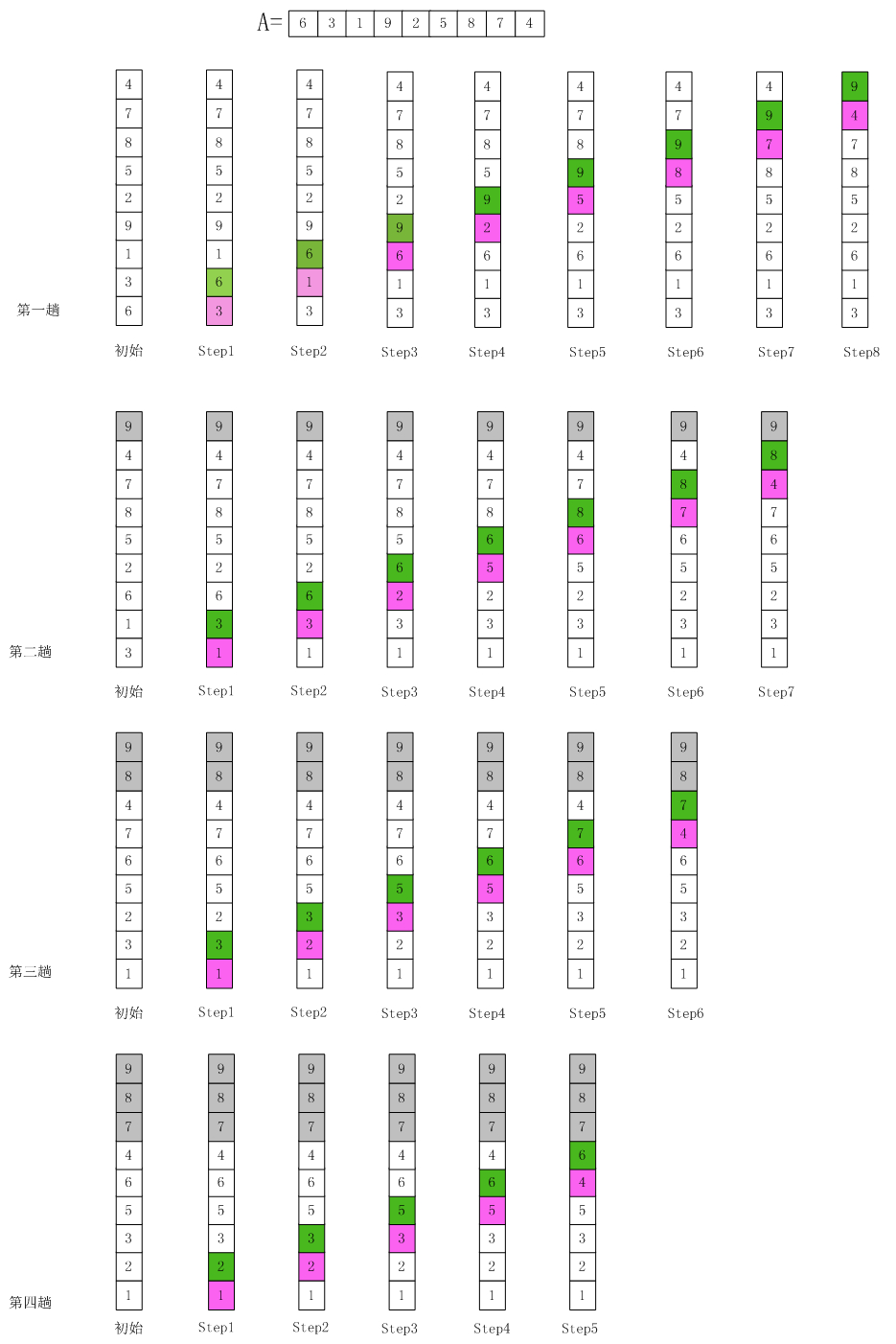
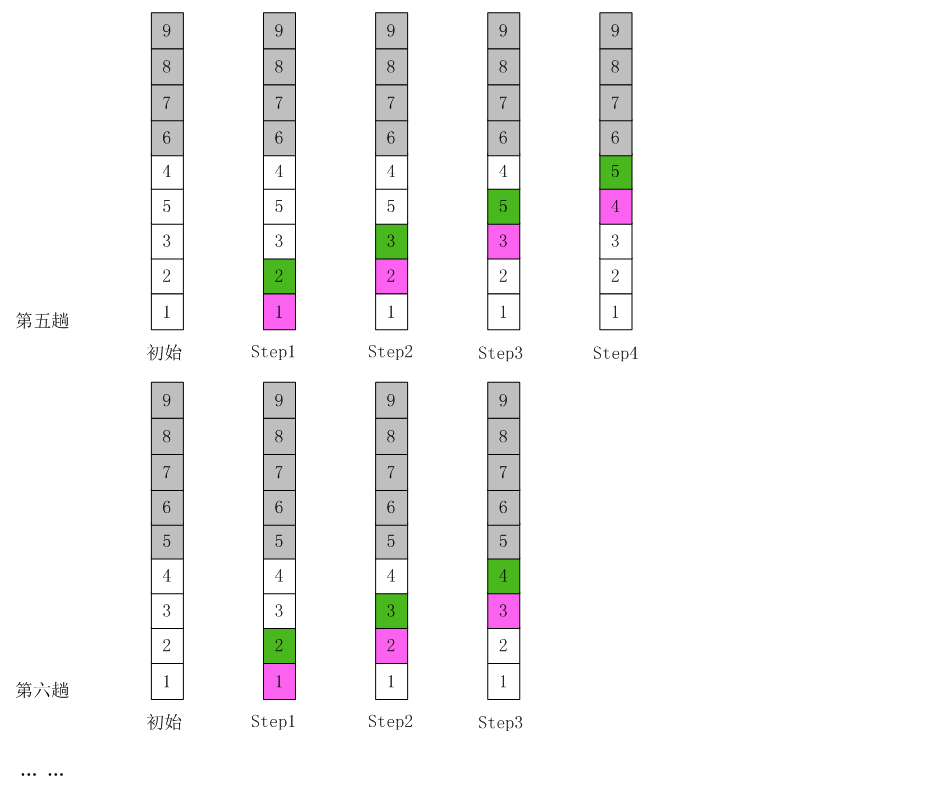

算法实现
'''
冒泡排序
'''
def Dubble_sort(a):
for i in range(len(a)):
for j in range(i+1,len(a)):
if a[i] > a[j]:
a[i],a[j] = a[j],a[i]
return a
插入排序
有一个已经有序的数据序列,要求在这个已经排好的数据序列中插入一个数,但要求插入后此数据序列仍然有序,这个时候就要用到一种新的排序方法——插入排序法,插入排序的基本操作就是将一个数据插入到已经排好序的有序数据中,从而得到一个新的、个数加一的有序数据,算法适用于少量数据的排序,时间复杂度为O(n^2)。是稳定的排序方法。插入算法把要排序的数组分成两部分:第一部分包含了这个数组的所有元素,但将最后一个元素除外(让数组多一个空间才有插入的位置),而第二部分就只包含这一个元素(即待插入元素)。在第一部分排序完成后,再将这个最后元素插入到已排好序的第一部分中。

算法实现:
'''
插入排序
'''
def Insertion_sort(a):
for i in range(1,len(a)):
j = i
while j>0 and a[j-1]>a[i]:
j -= 1
a.insert(j,a[i])
a.pop(i+1)
return a
快速排序
介绍:
快速排序(Quicksort)是对冒泡排序的一种改进。在平均状况下,排序 n 个项目要Ο(n log n)次比较。在最坏状况下则需要Ο(n2)次比较,但这种状况并不常见。事实上,快速排序通常明显比其他Ο(n log n) 算法更快,因为它的内部循环(inner loop)可以在大部分的架构上很有效率地被实现出来,且在大部分真实世界的数据,可以决定设计的选择,减少所需时间的二次方项之可能性。
步骤:
- 从数列中挑出一个元素,称为 “基准”(pivot),
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
排序效果:
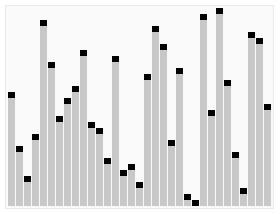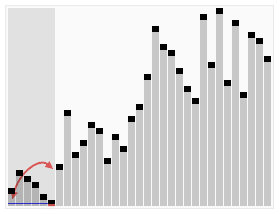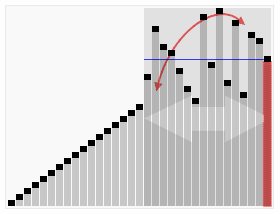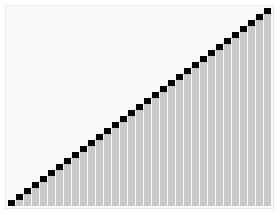
算法实现:
'''
快速排序
'''
def sub_sort(array,low,high):
key = array[low]
while low < high:
while low < high and array[high] >= key:
high -= 1
while low < high and array[high] < key:
array[low] = array[high]
low += 1
array[high] = array[low]
array[low] = key
return low def quick_sort(array,low,high):
if low < high:
key_index = sub_sort(array,low,high)
quick_sort(array,low,key_index)
quick_sort(array,key_index+1,high)
然后我们对上面的算法做一个时间比较:
'''''
随机生成0~10000000之间的数值
'''
def getrandata(num):
a=[]
i=0
while i<num:
a.append(random.randint(0,10000000))
i+=1
return a '''
随机生成20个长度为10000的数组
'''
a = []
for i in range(20):
a.append(getrandata(10000)) '''
测试时间函数
'''
def time_it(f,a):
t = []
for i in range(len(a)):
t1 = time.time()
f(a[i])
t2 = time.time()
t.append(t2-t1)
return t
tt1 = time_it(Selection_sort,copy.deepcopy(a))
tt2 = time_it(Dubble_sort,copy.deepcopy(a))
tt3 = time_it(Insertion_sort,copy.deepcopy(a))
tt4 = time_it(Quick_sort,copy.deepcopy(a))
print np.mean(tt1),tt1
print np.mean(tt2),tt2
print np.mean(tt3),tt3
print np.mean(tt4),tt4
在我电脑运行结果如下:
3.53101536036 [3.1737868785858154, 3.2235000133514404, 3.296314001083374, 3.3746020793914795, 3.6942098140716553, 3.6844170093536377, 3.3293440341949463, 3.6262528896331787, 3.577023983001709, 3.4677979946136475, 3.5323100090026855, 3.3574531078338623, 3.4525561332702637, 3.4662599563598633, 3.8701679706573486, 3.719839096069336, 3.7798891067504883, 3.6078600883483887, 3.803921937942505, 3.582801103591919]
7.22842954397 [7.1081390380859375, 7.365921974182129, 6.666350841522217, 7.258342027664185, 6.8559088706970215, 6.805047035217285, 7.230466842651367, 7.948682069778442, 7.901662111282349, 7.448035955429077, 8.134574890136719, 7.731559991836548, 7.3559558391571045, 6.80467414855957, 7.227035999298096, 6.987092018127441, 6.9657158851623535, 6.997059106826782, 6.9417431354522705, 6.834623098373413]
2.64084545374 [2.6150870323181152, 2.567375898361206, 2.7965359687805176, 2.616096019744873, 2.561455011367798, 2.76595401763916, 2.603566884994507, 2.542672872543335, 2.783787965774536, 2.643486976623535, 2.5308570861816406, 2.764592170715332, 2.6237199306488037, 2.508751153945923, 2.766709089279175, 2.603114128112793, 2.528198003768921, 2.812356948852539, 2.651564836502075, 2.53102707862854]
0.0346855401993 [0.03456306457519531, 0.0337519645690918, 0.03569507598876953, 0.034551143646240234, 0.03506588935852051, 0.03456687927246094, 0.0352480411529541, 0.03591203689575195, 0.03380298614501953, 0.03402996063232422, 0.034184932708740234, 0.03434491157531738, 0.034864187240600586, 0.035611867904663086, 0.03429007530212402, 0.034512996673583984, 0.03453683853149414, 0.03406691551208496, 0.033792972564697266, 0.036318063735961914]
可以看出,快速排序在随机生成的数组中速度上十分有优势。
经典排序算法及python实现的更多相关文章
- 十大经典排序算法(python实现)(原创)
个人最喜欢的排序方法是非比较类的计数排序,简单粗暴.专治花里胡哨!!! 使用场景: 1,空间复杂度 越低越好.n值较大: 堆排序 O(nlog2n) O(1) 2,无空间复杂度要求.n值较大: 桶排序 ...
- 十大经典排序算法总结 (Python)
作业部落:https://www.zybuluo.com/listenviolet/note/1399285 以上链接是自己在作业部落编辑的排序算法总结- Github: https://github ...
- 十大经典排序算法的python实现
十种常见排序算法可以分为两大类: 非线性时间比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此称为非线性时间比较类排序.包括:冒泡排序.选择排序.归并排序.快速 ...
- 经典排序算法总结与实现 ---python
原文:http://wuchong.me/blog/2014/02/09/algorithm-sort-summary/ 经典排序算法在面试中占有很大的比重,也是基础,为了未雨绸缪,在寒假里整理并用P ...
- 经典排序算法的总结及其Python实现
经典排序算法总结: 结论: 排序算法无绝对优劣之分. 不稳定的排序算法有:选择排序.希尔排序.快速排序.堆排序(口诀:“快速.选择.希尔.堆”).其他排序算法均为稳定的排序算法. 第一趟排序后就能确定 ...
- python 经典排序算法
python 经典排序算法 排序算法可以分为内部排序和外部排序,内部排序是数据记录在内存中进行排序,而外部排序是因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存.常见的内部排序算 ...
- 经典排序算法及总结(python实现)
目录 1.排序的基本概念和分类 排序的稳定性: 内排序和外排序 影响内排序算法性能的三个因素: 根据排序过程中借助的主要操作,可把内排序分为: 按照算法复杂度可分为两类: 2.冒泡排序 BubbleS ...
- python实现十大经典排序算法
Python实现十大经典排序算法 代码最后面会给出完整版,或者可以从我的Githubfork,想看动图的同学可以去这里看看: 小结: 运行方式,将最后面的代码copy出去,直接python sort. ...
- 用Python实现十大经典排序算法-插入、选择、快速、冒泡、归并等
本文来用图文的方式详细讲解了Python十大经典排序算法 —— 插入排序.选择排序.快速排序.冒泡排序.归并排序.希尔排序.插入排序.桶排序.基数排序.计数排序算法,想要学习的你们,继续阅读下去吧,如 ...
随机推荐
- 1 2 5 10 20 --> 800
用1元 2元 5元 10元 20元的钞票凑成800元的方法种数计算,使用了动态规划. 结果没打出来,只是保留在函数里各个vector中,调试可看所有结果. 优点:快 缺点:占空间占内存 耗时时间测试: ...
- SeaJS 简单试用
http://seajs.org/docs/#quick-start 感觉seajs的语法有点罗嗦... 它既有RequireJS的特点也有NodeJS引入模块的特点 例子是抄的官方的例子 在官方的 ...
- 脑波设备mindwave二次开发框架
神念科技提供的mindwave提供了脑波耳机和相应的游戏,这些游戏你可以通过购买神念科技的mindwave耳机来获取,这里不多作介绍. 我们作为程序员,如果有了相应的创意,也可以通过他们提供的二次开发 ...
- 【C/C++多线程编程之九】pthread读写锁
多线程编程之读写锁 Pthread是 POSIX threads 的简称,是POSIX的线程标准. pthread读写锁把对共享资源的訪问者分为读者和写者,读者仅仅对共享资源 ...
- [置顶] .NET下枚举类型的Save和Load分析
今天在写代码的时候,心血来潮对原来的字符串保存状态位的方式很不满意,对于代码里出现了 state == "1" 这样的状态判断很是不爽.那么理想中的判断是怎样的呢?很简单如你所想枚 ...
- asp.net发布网站(转)
1. 在Web项目中点击发布网站,如图1所示 图1 2. 选择要发布的路径——>“确定”,如果项目显示发布成功就可以了.如图2所示 图2 3. 打 ...
- django datetime format 日期格式化
django datetime format 日期格式化 www.jx-lab.com python 中 date,datetime,time对象都支持strftime(format)方法,但有一些区 ...
- 【Web】十步教你搭建完整免费的个人网站(花生壳+XAMPP+WordPress)
1.从花生壳官网(http://www.oray.com/peanuthull/download.php)下载最新版本的客户端. 下载完成后安装,注册护照(需手机验证码验证),注册完成后获取免费域名并 ...
- SQL Server和MySql获取当前数据库每个表的列数
Sql server:(连接数据库后,点击当前数据库再新建查询) select count(c.name),o.name from syscolumns c left join sysobjects ...
- BZOJ 1050: [HAOI2006]旅行comf( 并查集 )
将edge按权值排序 , O( m² ) 枚举边 , 利用并查集维护连通信息. ------------------------------------------------------------ ...