【Support Vector Regression】林轩田机器学习技法
上节课讲了Kernel的技巧如何应用到Logistic Regression中。核心是L2 regularized的error形式的linear model是可以应用Kernel技巧的。

这一节,继续沿用representer theorem,延伸到一般的regression问题。
首先想到的就是ridge regression,它的cost函数本身就是符合representer theorem的形式。
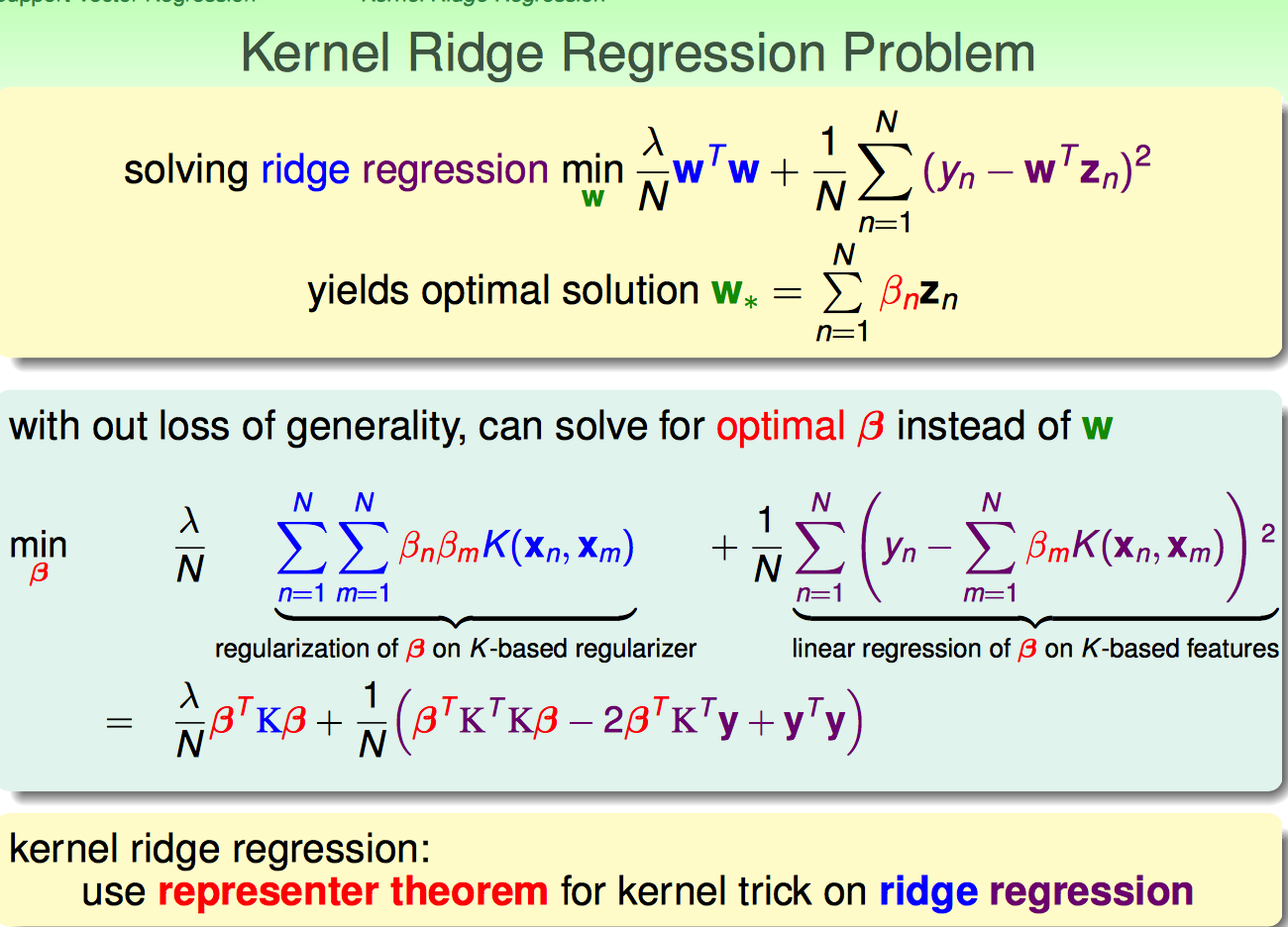
由于optimal solution一定可以表示成输入数据的线性组合,再配合Kernel Trick,可以获得ridge regression的kernel trick形式。

这样就获得了kernel ridge regression的analytic solution形式。
但是这样算出来的beita是非常dense的。
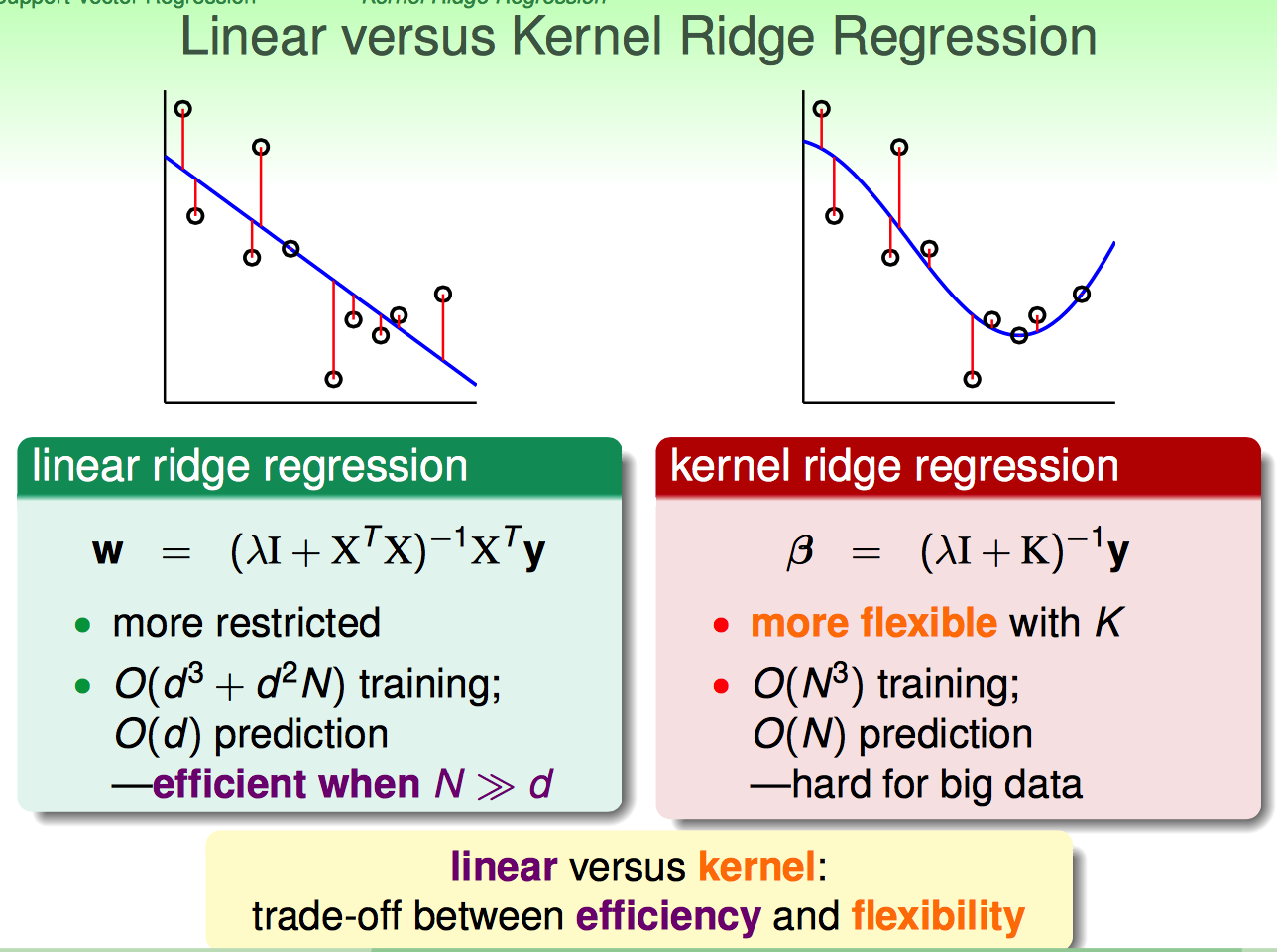
因此,对比linear和kernel ridge regression:
(1)linear的效率可能要比kernel的高,尤其是N很大的时候
(2)kernel的灵活性要好(弯弯曲曲的),但是一旦N很大基本就废了
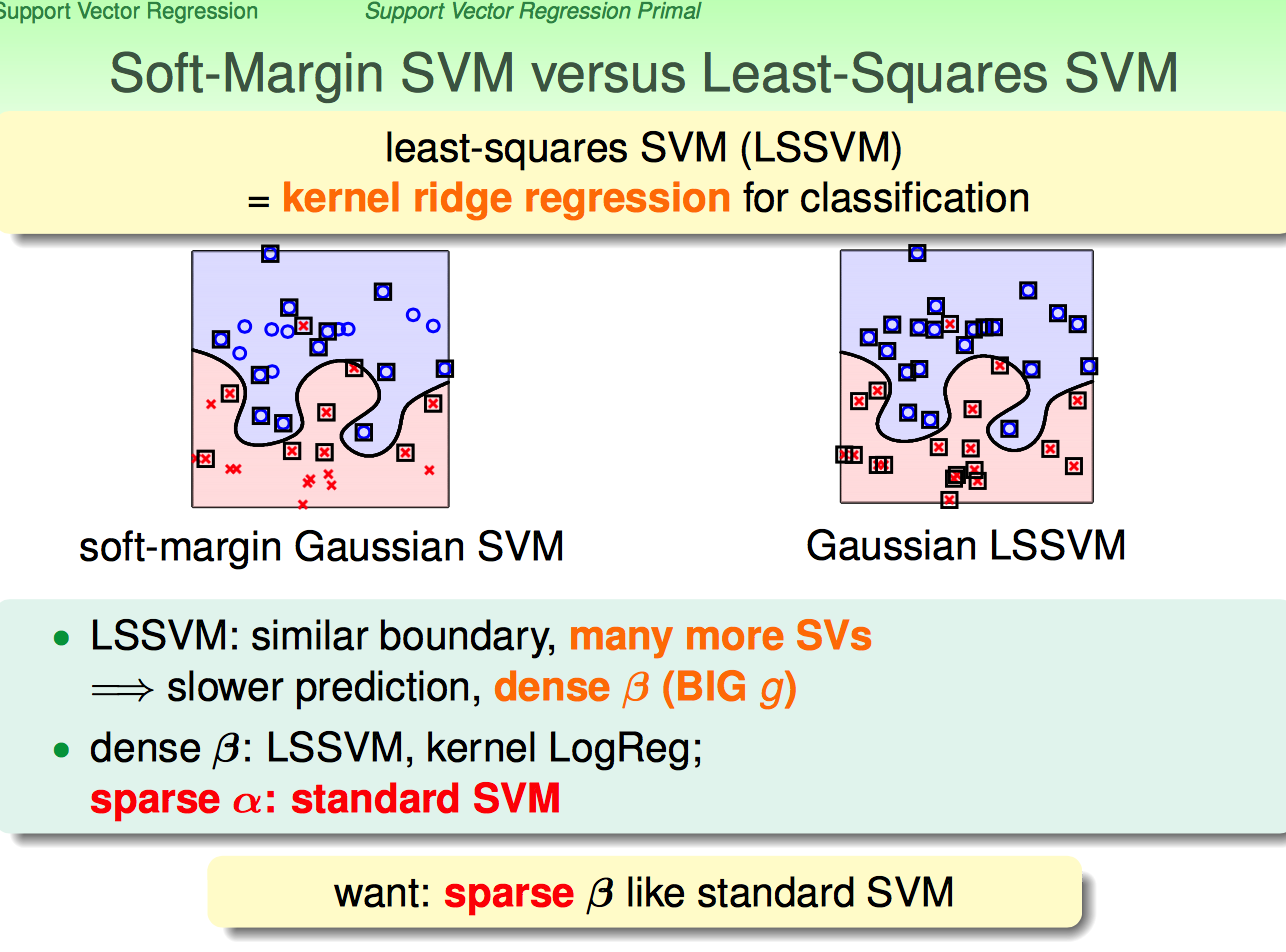
上面个说的这种kernel ridge regression for classification有个正式的名称叫“least-squares SVM (LSSVM)”
对比原来的Soft-Margin SVM,LSSVM的support vectors多了很多;再由于W是Support Vectors的线性组合,这就意味这在predict的时候要耗费更多的时间。
现在问题来了,能否用什么方法,把这种一般的regression for classification问题转换成SVM那种sparse support vectors的形式呢?
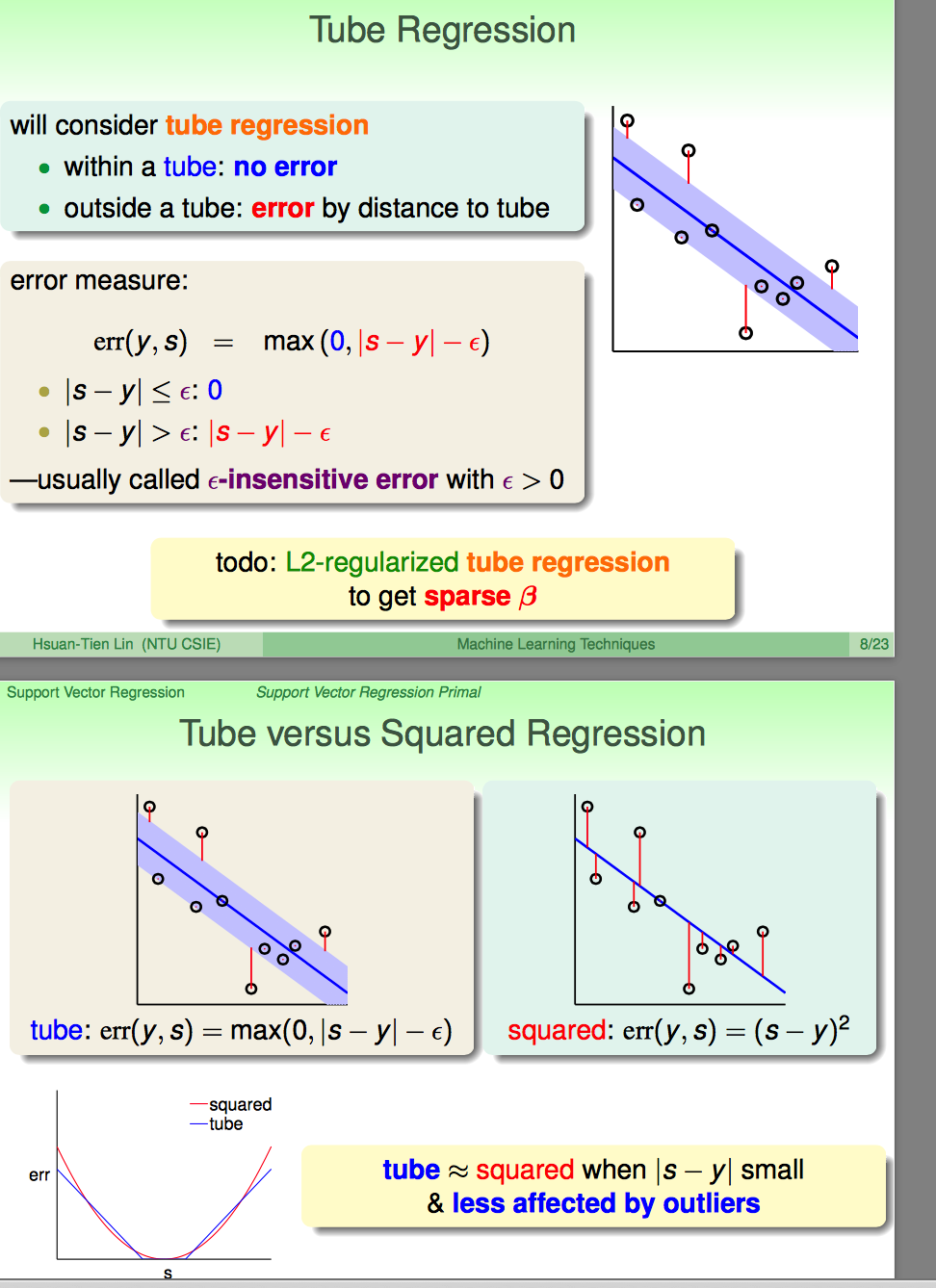
这里引入了一种新的regression叫tube regression的方式:
(1)tube的核心在于error measure的方式:epsilon insensitive error的方式
(2)引入L2 regularized tube regression来实现sparse support vectors
(3)对比这种epsilon insensitive error和square error,可以看score与y相差较远时,tube似乎受到outliers的影响更小一些
更进一步,把L2-Regularized用到Tube Regression上面就形成了如下的cost function。

L2-Regularized Tube Regression的cost function虽然是无约束的,但是是不可导的,并且也看不出来啥sparsity的可能。
那么,能否模仿standard SVM的技巧,换成有约束但是可导的cost function呢?

(1)如果直接模仿SVM的cost function形式:引入一个kesin;貌似长得很像SVM了,但是由于带了个绝对值,所以还是不能求导
(2)这时候,前人的智慧就派上用场了:
a. 引入kesin up代表score比yn大出epsilon的容忍范围
b. 再引入kesin down代表score比yn小出epsilon的容忍范围
c. 修改cost function的形式:把kesin up和kesin down都放到里面

总的来说,就是引多引入了N个变量,多了N个constraints;结果最终把L2-regularized Tube Regression的cost function转化成了Quadratic Programming的问题。
紧接着,能否再转化为dual问题求解呢?(引入kernel容易一些?)

引入两套Lagrange Multipliers。
再配合上KKT条件,就可以得到dual形式的Quadratic Programming的问题形式。
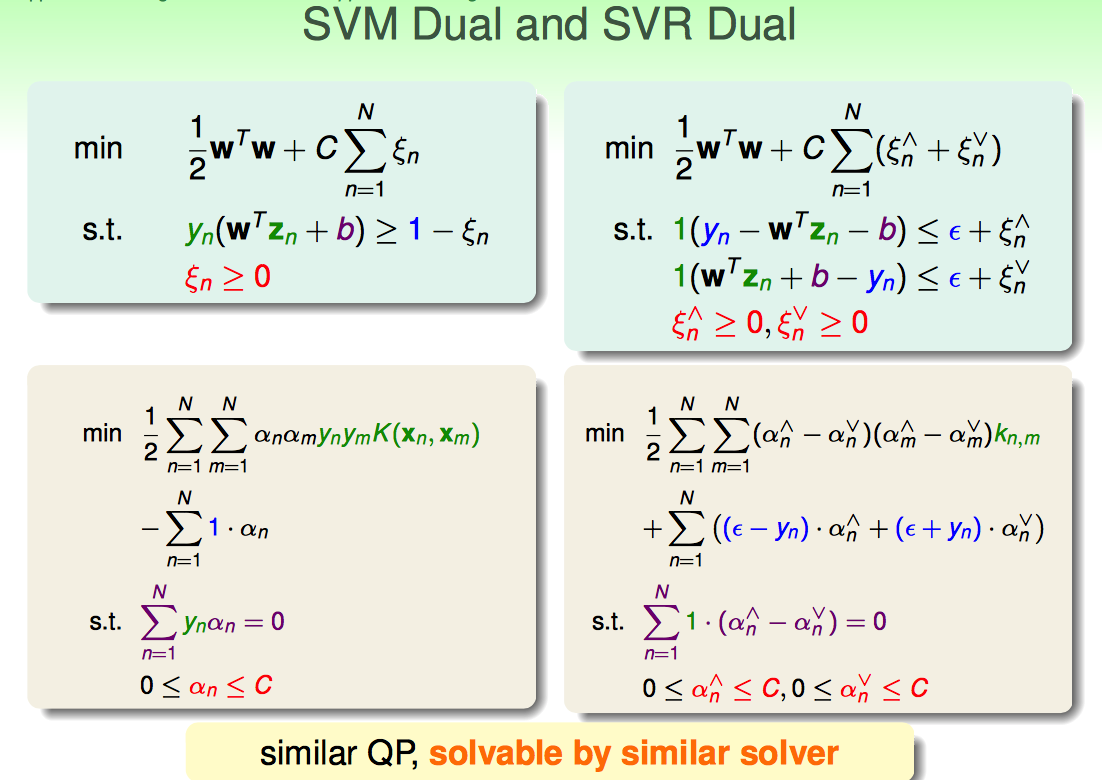
最终dual形式与soft-margin形式的svm非常类似。

根据representer theorem,只有outside tube或者on tube上的点才是支撑向量。虽说这种sparsity感觉怪怪的,但毕竟已经比原来的LLSVM好很多了。
【Support Vector Regression】林轩田机器学习技法的更多相关文章
- 【Linear Support Vector Machine】林轩田机器学习技法
首先从介绍了Large_margin Separating Hyperplane的概念. (在linear separable的前提下)找到largest-margin的分界面,即最胖的那条分界线.下 ...
- 【Dual Support Vector Machine】林轩田机器学习技法
这节课内容介绍了SVM的核心. 首先,既然SVM都可以转化为二次规划问题了,为啥还有有Dual啥的呢?原因如下: 如果x进行non-linear transform后,二次规划算法需要面对的是d`+1 ...
- 【Matrix Factorization】林轩田机器学习技法
在NNet这个系列中讲了Matrix Factorization感觉上怪怪的,但是听完第一小节课程就明白了. 林首先介绍了机器学习里面比较困难的一种问题:categorical features 这种 ...
- 【Radial Basis Function Network】林轩田机器学习技法
这节课主要讲述了RBF这类的神经网络+Kmeans聚类算法,以及二者的结合使用. 首先回归的了Gaussian SVM这个模型: 其中的Gaussian kernel又叫做Radial Basis F ...
- 【Deep Learning】林轩田机器学习技法
这节课的题目是Deep learning,个人以为说的跟Deep learning比较浅,跟autoencoder和PCA这块内容比较紧密. 林介绍了deep learning近年来受到了很大的关注: ...
- 【Neural Network】林轩田机器学习技法
首先从单层神经网络开始介绍 最简单的单层神经网络可以看成是多个Perception的线性组合,这种简单的组合可以达到一些复杂的boundary. 比如,最简单的逻辑运算AND OR NOT都可以由多 ...
- 【Decision Tree】林轩田机器学习技法
首先沿着上节课的AdaBoost-Stump的思路,介绍了Decision Tree的路数: AdaBoost和Decision Tree都是对弱分类器的组合: 1)AdaBoost是分类的时候,让所 ...
- 【Adaptive Boosting】林轩田机器学习技法
首先用一个形象的例子来说明AdaBoost的过程: 1. 每次产生一个弱的分类器,把本轮错的样本增加权重丢入下一轮 2. 下一轮对上一轮分错的样本再加重学习,获得另一个弱分类器 经过T轮之后,学得了T ...
- 【Random Forest】林轩田机器学习技法
总体来说,林对于random forest的讲解主要是算法概况上的:某种程度上说,更注重insights. 林分别列举了Bagging和Decision Tree的各自特点: Random Fores ...
随机推荐
- nodejs+MQTT协议实现远程主机控制
摘抄自百度:MQTT(MessageQueuing Telemetry Transport,消息队列遥测传输)是IBM开发的一个即时通讯协议,有可能成为物联网的重要组成部分. 所谓物联网,就是“万物互 ...
- Python OOP 面向对象
1.Python实现OOP可以概括为三个概念: 继承:基于Python属性查找 多态:在x.method中,method的意义取决于x的类型 封装:方法和运算符实现行为,数据隐藏是一种惯例 2.委托: ...
- Buffer的使用
虽然知道了怎么实例化Buffer,但这还远远不够,因为Buffer类使随nodejs一起发布的核心库,Buffer不仅能处理tcp连接中发送接收的数据,也能处理图像或者是压缩文件,甚至说文件系统里面的 ...
- Linux 初学者:移动文件
你学习了有关目录和访问目录的权限是如何工作的.你在这些文章中学习的大多数内容都可应用于文件 -- Paul Brown 在之前的该系列的部分中, 你学习了有关目录 和 访问目录 的权限 是如何工作的. ...
- BeanNameAware接口和BeanFactoryAware接口(转)
迄今为止,所接触到的Bean都是“无知觉”的,就像黑客帝国中机械工厂里面“养殖”的人类,他们虽然能完成一定的功能,但是根本不知道自己在工厂(BeanFactory)中的代号(id) ...
- parameter server
http://zeromq.org ZeroMQ \zero-em-queue\, \ØMQ\: Ø Connect your code in any language, on any platfo ...
- MySQL为何不建议使用null列
Preface Null is a special constraint of columns.The columns in table will be added null cons ...
- IDEA工具配置weblogic
1.首先打开IDEA,点击Run-Edit Configurations… 2.配置weblogic页面 2.1点击“+”号,选WeblogicServer-local 2.2红框的是新添加的服务,起 ...
- hive_异常_01_(未解决)FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. org.apache.hadoop.hbase.HTableDescriptor.addFamily(Lorg/apache/hadoop/hbase/HColumnDescriptor;)V
一.如果出现如下错误需要编译源码 需要重新编译Hbase-handler源码 步骤如下: 准备Jar包: 将Hbase 中lib下的jar包和Hive中lib下的jar包全部导入到一起. 记得删除里面 ...
- Linux相关常用命令
1.XShell中上传文件命令 首先需要安装rz文件上传工具: yum -y install lrzsz 然后执行以下命令,可打开本地系统的选择文件窗口:(或者直接把本地的文件拖动到SSH Shell ...