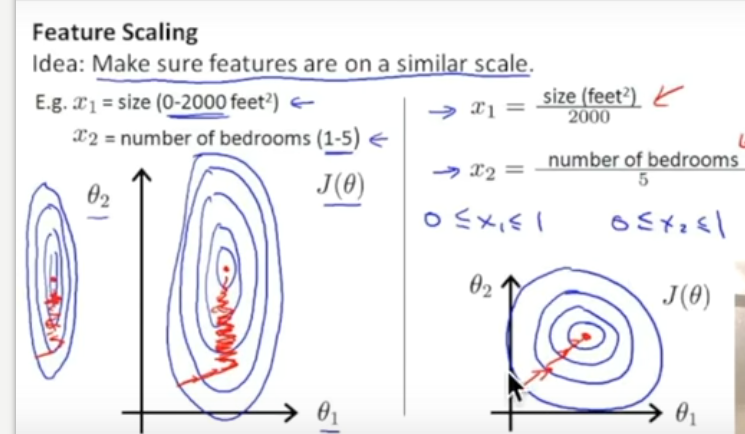
sklearn正规化(Normalization或者scale)
from sklearn import preprocessing
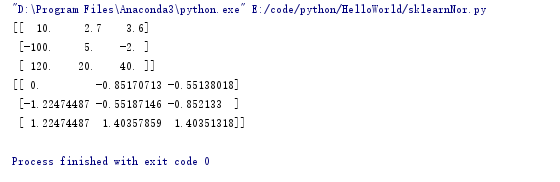
import numpy as np a = np.array([[10,2.7,3.6],[-100,5,-2],[120,20,40]],dtype=np.float64)
print(a)
print(preprocessing.scale(a))
from sklearn import preprocessing
import numpy as np
from sklearn.cross_validation import train_test_split
from sklearn.datasets.samples_generator import make_classification
from sklearn.svm import SVC
import matplotlib.pyplot as plt
# a = np.array([[10,2.7,3.6],[-100,5,-2],[120,20,40]],dtype=np.float64)
# print(a)
# print(preprocessing.scale(a))
X,Y = make_classification(n_samples=300,n_features=2,n_redundant=0,n_informative=2,random_state=22, n_clusters_per_class=1, scale=100)
# plt.scatter(X[:, 0], X[:, 1], c=Y)
# plt.show()
#X=preprocessing.scale(X)
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.3)
clf = SVC()
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))

from sklearn import preprocessing
import numpy as np
from sklearn.cross_validation import train_test_split
from sklearn.datasets.samples_generator import make_classification
from sklearn.svm import SVC
import matplotlib.pyplot as plt
# a = np.array([[10,2.7,3.6],[-100,5,-2],[120,20,40]],dtype=np.float64)
# print(a)
# print(preprocessing.scale(a))
X,Y = make_classification(n_samples=300,n_features=2,n_redundant=0,n_informative=2,random_state=22, n_clusters_per_class=1, scale=100)
# plt.scatter(X[:, 0], X[:, 1], c=Y)
# plt.show()
X=preprocessing.scale(X)
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.3)
clf = SVC()
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))

sklearn正规化(Normalization或者scale)的更多相关文章
- sklearn数据预处理-scale
对数据按列属性进行scale处理后,每列的数据均值变成0,标准差变为1.可通过下面的例子加深理解: from sklearn import preprocessing import numpy as ...
- normalization正规化
用到sklearn模块 from sklearn import preprocessing用preprocessing.scale正规化 print(preprocessing.scale(a))
- 机器学习-Sklearn
Scikit learn 也简称 sklearn, 是机器学习领域当中最知名的 python 模块之一. Sklearn 包含了很多种机器学习的方式: Classification 分类 Regres ...
- Python中常用包——sklearn主要模块和基本使用方法
在从事数据科学的人中,最常用的工具就是R和Python了,每个工具都有其利弊,但是Python在各方面都相对胜出一些,这是因为scikit-learn库实现了很多机器学习算法. 加载数据(Data L ...
- 【机器学习学习】SKlearn + XGBoost 预测 Titanic 乘客幸存
Titanic 数据集是从 kaggle下载的,下载地址:https://www.kaggle.com/c/titanic/data 数据一共又3个文件,分别是:train.csv,test.csv, ...
- 【机器学习】SKlearn + XGBoost 预测 Titanic 乘客幸存
Titanic 数据集是从 kaggle下载的,下载地址:https://www.kaggle.com/c/titanic/data 数据一共又3个文件,分别是:train.csv,test.csv, ...
- 复盘一篇讲sklearn库的文章(下)
skleran-处理流程 获取数据 以用sklearn的内置数据集, 先导入datasets模块. 最经典的iris数据集作为例子. from sklearn import datasets iris ...
- Scikit-learn:数据预处理Preprocessing data
http://blog.csdn.net/pipisorry/article/details/52247679 本blog内容有标准化.数据最大最小缩放处理.正则化.特征二值化和数据缺失值处理. 基础 ...
- 采用梯度下降优化器(Gradient Descent optimizer)结合禁忌搜索(Tabu Search)求解矩阵的全部特征值和特征向量
[前言] 对于矩阵(Matrix)的特征值(Eigens)求解,采用数值分析(Number Analysis)的方法有一些,我熟知的是针对实对称矩阵(Real Symmetric Matrix)的特征 ...
随机推荐
- js常用方法(。。。。不完整)
lastIndexOf();substring();split();slice();splice(); var s="http://www.baidu.com"; var unit ...
- 【leetcode刷题笔记】Maximal Rectangle
Given a 2D binary matrix filled with 0's and 1's, find the largest rectangle containing all ones and ...
- <HTTP协议详解>由浅入深看HTTP
一. HTTP协议的应用简单概况 HTTP协议的主要特点可概括如下: 1.支持客户/服务器模式.2.简单快速:客户向服务器请求服务时,只需传送请求方法和路径.请求方法常用的有GET.HEAD.POST ...
- 系统安装记录 install OS
上个系统很乱,基本系统是lfs7.7,上面应用都是基于lfs7.9,基本系统是才接触lfs时搭建的,打包保存后一直没怎么使用过,到lfs7.10快出来的时候有段时间有空就拿出来跑了一下,安装了一些软件 ...
- Exception in thread "main" java.io.IOException: Mkdirs failed to create /var/folders/q0/1wg8sw1x0dg08cmm5m59sy8r0000gn/T/hadoop-unjar6090005653875084137/META-INF/license at org.apache.hadoop.util.Run
在使用hadoop运行jar时出现. 解决方法 zip -d Test.jar LICENSE zip -d Test.jar META-INF/LICENSE 完美解决.
- 分享知识-快乐自己:Shiro 退出登陆清空缓存实现
shiro是一个被广泛使用的安全层框架,通过xml配置方式与spring无缝对接,用户的登陆/退出/权限控制/Cookie等管理系统基础功能交给shiro来管理. 一般,在JavaWEB管理平台系统时 ...
- 分享知识-快乐自己:Java中各种集合特点
Java中各种集合特点: Collection[单列集合]: List(有序,可重复): ArrayList: 底层数据结构是数组,查询快,增删慢.线程不安全,效率高. Vector: 底层数据结构是 ...
- Selenium-几种元素定位方式
#识别元素并操作#一般有如下几种方法,其中id最为常用.这里需要注意识别元素一定要用唯一id 1.find_element_by_id("value") #! /usr/bin/e ...
- CSS cursor 属性--css html 鼠标手型,鼠标形状,鼠标效果,样式
css鼠标手型cursor中hand与pointer Example:CSS鼠标手型效果 <a href="#" style="cursor:hand"& ...
- bootstrap-自定义导航栏隐藏参数@screen-sm
导航菜单默认在屏幕小于768px的时候自动折叠,怎么自定义这个大小? 需要重新编译bootstrap 编译 CSS 和 JavaScript 文件 问题解决!