网络爬虫与搜索引擎优化(SEO)
一、网络爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。简单来讲,它是一种可以在无需人类干预的情况下自动进行一系列web事务处理的软件程序。web爬虫是一种机器人,它们会递归地对各种信息性的web站点进行遍历,获取第一个web页面,然后获取那个页面指向的所有的web页面,依次类推。因特网搜索引擎使用爬虫在web上游荡,并把他们碰到的文档全部拉回来。然后对这些文档进行处理,形成一个可搜索的数据库。简单来说,网络爬虫就是搜索引擎访问你的网站进而收录你的网站的一种内容采集工具。
例如:百度的网络爬虫就叫做BaiduSpider。

二、网络爬虫基本原理
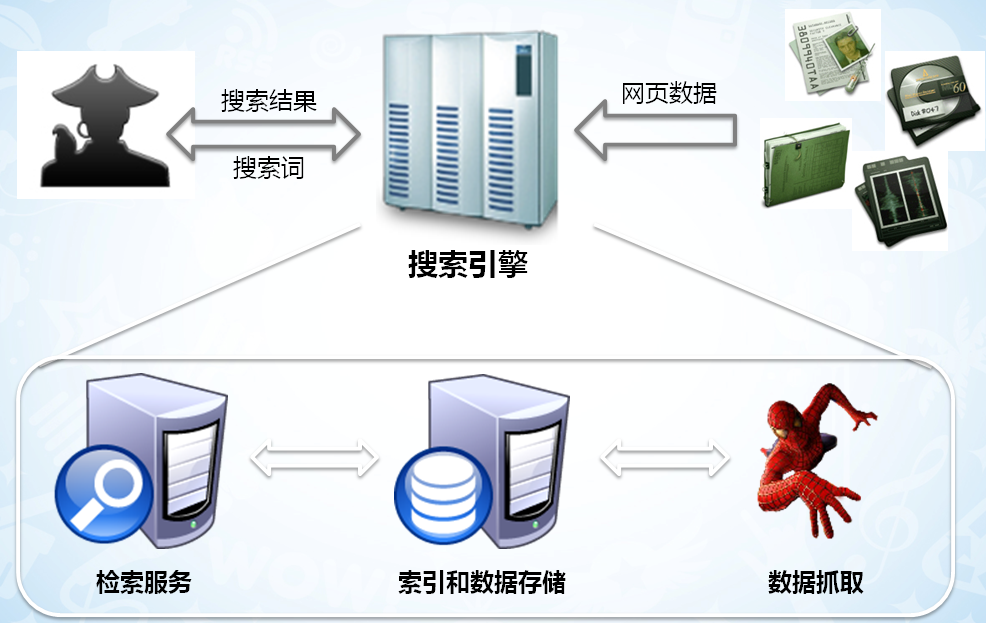
网络 < --- > 爬虫 < --- > 网页内容库 < --- > 索引程序 < --- > 索引库 < --- > 搜索引擎 < --- > 用户
三、爬虫程序需要注意的地方
1、链接提取以及相对链接的标准化
- 爬虫在web上移动的时候会不停的对HTML页面进行解析,它要对所解析的每个页面上的URL链
接进行分析,并将这些链接添加到需要爬行的页面列表中去
2、 避免环路的出现
web爬虫在web上爬行时,要特别小心不要陷入循环之中,至少有以下三个原因,环路对爬虫来说是有害的。
- 他们会使爬虫可能陷入可能会将其困住的循环之中。爬虫不停的兜圈子,把所有时间都耗费在不停获取相同的页面上。
- 爬虫不断获取相同的页面的同时,服务器段也在遭受着打击,它可能会被击垮,阻止所有真实用户访问这个站点。
- 爬虫本身变的毫无用处,返回数百份完全相同的页面的因特网搜索引擎就是这样的例子。
同时,联系上一个问题,由于URL“别名”的存在,即使使用了正确的数据结构,有时候也很难分辨出以前是否访问过这
个页面,如果两个URL看起来不一样,但实际指向的是同一资源,就称为互为“别名”。
3、标记为不爬取
4、避免环路与循环方案
5、规范化URL
6、广度优先的爬行
- 以广度优先的方式去访问就可以将环路的影响最小化。
7、节流
- 限制一段时间内爬虫可以从一个web站点获取的页面数量,也可以通过节流来限制重复页面总数和对服务器访问的总数。
8、限制URL的大小
- 如果环路使URL长度增加,长度限制就会最终终止这个环路
9、URL黑名单
10、人工监视
四、搜索引擎优化(SEO)
1、内部优化
- META标签优化:例如:TITLE,KEYWORDS,DESCRIPTION等的优化
- 内部链接的优化,包括相关性链接(Tag标签),锚文本链接,各导航链接,及图片链接
- 语义化书写HTML代码,符合W3C标准
- 网站内容更新:每天保持站内的更新(主要是文章的更新等)
2、外部优化
- 外部链接类别:博客、论坛、B2B、新闻、分类信息、贴吧、知道、百科、相关信息网等尽量保持链接的多样性
- 外链运营:每天添加一定数量的外部链接,使关键词排名稳定提升。
- 外链选择:与一些和你网站相关性比较高,整体质量比较好的网站交换友情链接,巩固稳定关键词排名
- 提升网站速度等
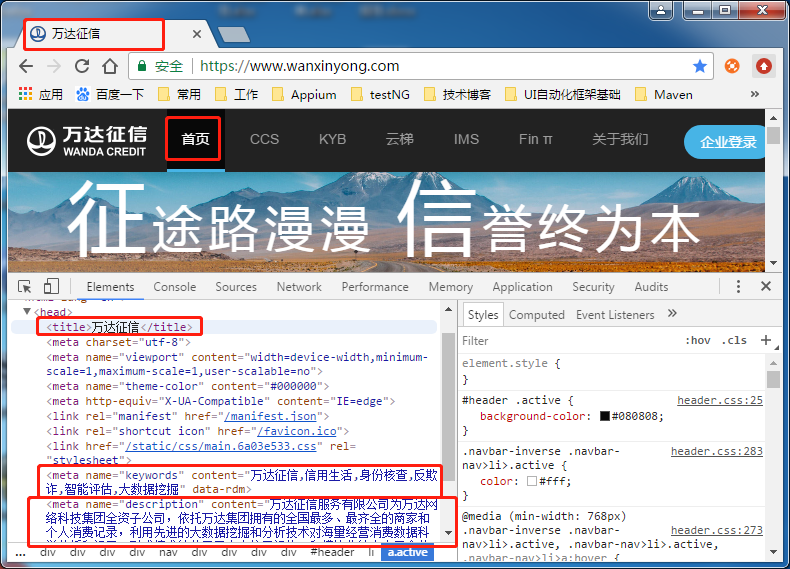
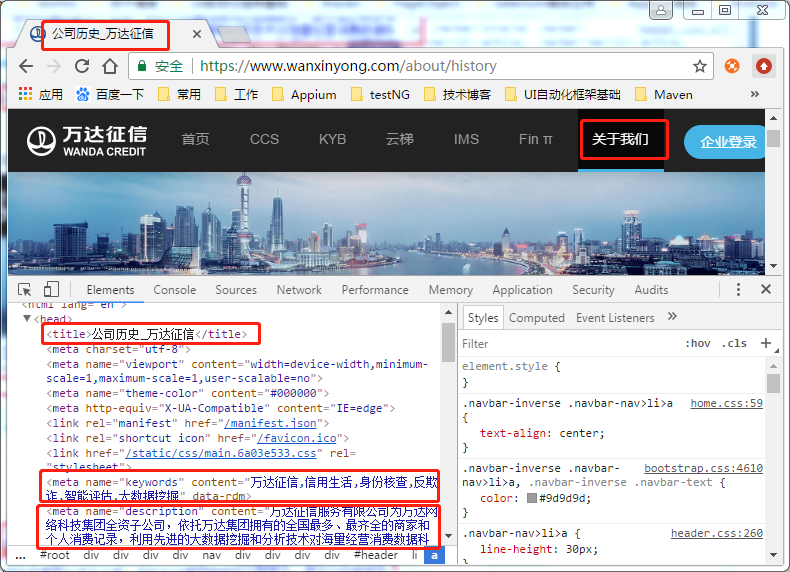
以内部优化中META标签优化举例(下图为万达征信官网),下图为不同页面的title、keywords、description都不一样,
易于爬虫,提升网站的访问量。
网络爬虫与搜索引擎优化(SEO)的更多相关文章
- 网络爬虫与搜索引擎优化(SEO)
爬虫及爬行方式 爬虫有很多名字,比如web机器人.spider等,它是一种可以在无需人类干预的情况下自动进行一系列web事务处理的软件程序.web爬虫是一种机器人,它们会递归地对各种信息性的web站点 ...
- 基于Nutch+Hadoop+Hbase+ElasticSearch的网络爬虫及搜索引擎
基于Nutch+Hadoop+Hbase+ElasticSearch的网络爬虫及搜索引擎 网络爬虫架构在Nutch+Hadoop之上,是一个典型的分布式离线批量处理架构,有非常优异的吞吐量和抓取性能并 ...
- 网站优化不等于搜索引擎优化SEO
对于SEO相信搞网络营销的人基本上都知道这个名词,英文全称为search engine optimization,中文一般叫搜索引擎优化,也有的叫搜索引擎定位(Search Engine Positi ...
- 一个大数据方案:基于Nutch+Hadoop+Hbase+ElasticSearch的网络爬虫及搜索引擎
网络爬虫架构在Nutch+Hadoop之上,是一个典型的分布式离线批量处理架构,有非常优异的吞吐量和抓取性能并提供了大量的配置定制选项.由于网络爬虫只负责网络资源的抓取,所以,需要一个分布式搜索引擎, ...
- 网站搜索引擎优化SEO策略及相关工具资源
网站优化的十大奇招妙技 1. 选择有效的关键字: 关键字是描述你的产品及服务的词语,选择适当的关键字是建立一个高排名网站的第一步.选择关键字的一个重要的技巧是选取那些常为人们在搜索时所用到的关键字. ...
- 【架构】基于Nutch+Hadoop+Hbase+ElasticSearch的网络爬虫及搜索引擎
网络爬虫架构在Nutch+Hadoop之上,是一个典型的分布式离线批量处理架构,有非常优异的吞吐量和抓取性能并提供了大量的配置定制选项.由于网络爬虫只负责网络资源的抓取,所以,需要一个分布式搜索引擎, ...
- WordPress博客系统搜索引擎优化seo全攻略方法
WordPress的文章.评论等很多数据都是存放在数据库的,所以搭建wordpress网站的时间,网站的空间不需要多大,而数据库一定要充足,而在WordPress数据库中主要使用 wp_posts 表 ...
- 网站搜索引擎优化(SEO)的18条守则
1.永远不要放过网页的title,这个地方应该是你每次优化的重点. 2.请不要在title,deion,keyword里写太多东西,越是贪婪,得到的就越少. 3.网页的头部和底部是很重要的,对于搜索引 ...
- 前端里面如何进行搜索引擎优化(SEO)
如何进行SEO优化: (1) 避免head标签js堵塞: 所有放在head标签里面的js和css都会堵塞渲染:如果这些css和js需要加载很久的话,那么页面就空白了: 解决办法:一是把script放到 ...
随机推荐
- 【linux高级程序设计】(第十一章)System V进程间通信 4
共享内存 共享内存主要用于实现进程间大量数据传输. 共享内存的数据结构定义: 系统对共享内存的限制: 共享内存与管道的对比: 可以看到,共享内存的优势: 1.共享内存只需复制2次,而管道需要4次 2. ...
- hihocoder1236(2015长春网赛J题) Scores(bitset && 分块)
题意:给你50000个五维点(a1,a2,a3,a4,a5),50000个询问(q1,q2,q3,q4,q5),问已知点里有多少个点(x1,x2,x3,x4,x5)满足(xi<=qi,i=1,2 ...
- ubuntu16下安装telnet和opensshserver
安装了虚拟机,使用的是ubuntu 16,server版本. 启动后发现没有telnet和ssh,就安装了(netstat -a|grep telnet). apt-get install openb ...
- AC日记——数颜色 bzoj 2120
2120 思路: 带修改的莫队: 对于离线排序询问的算法,如何修改呢? 每个询问添加一个修改标记: 表示当前询问在第几个修改之后: 然后把修改标记作为第三关键字来排序: 每次更新端点,先更新时间: 块 ...
- HDU 1171.Big Event in HDU-动态规划0-1背包
Big Event in HDU Time Limit: 10000/5000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others ...
- Codeforces 839 B. Game of the Rows-贪心
最近太zz了,老是忘记带脑子... 补的以前的cf,发现脑子不好使... B. Game of the Rows time limit per test 1 second memory lim ...
- Kali Linux Wine32英文字体不显示问题
Kali Linux Wine32英文字体不显示问题 Kali Linux提供了Wine32工具.在运行Wine32后,界面可以显示中文,但不能显示英文文字.英文文字均显示为方块.这是由于缺少对应的 ...
- Oracle PL/SQL DBA 编程实践基础
[附:一文一图]
- 【报错】spring boot启动 报错 找不到实体类Not a managed type: class com.pisen.cloud.luna.feign.ten.beans.SysUser
Caused by: java.lang.IllegalArgumentException: Not a managed type: class com.pisen.cloud.luna.feign. ...
- [置顶]
kubernetes资源对象--ConfigMap
原理 很多生产环境中的应用程序配置较为复杂,可能需要多个config文件.命令行参数和环境变量的组合.使用容器部署时,把配置应该从应用程序镜像中解耦出来,以保证镜像的可移植性.尽管Secret允许类似 ...