Python常用模块(三)
一.shelve模块
shelve也是一种序列化方式,在python中shelve模块提供了基本的存储操作,shelve中的open函数在调用的事和返回一个shelf对象,通过该对象可以存储内容,即像操作字典一样进行存储操作.当在该对象中查找元素时,对象会根据已经存储的内容重新构建,当给某个键赋值的时候,元素会被存储.
下图为实现序列化:
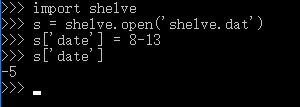
下图为发序列化
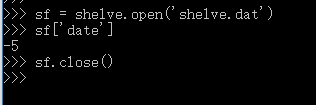
shelve模块特点:使用比较简单,提供一个文件名就可以进行读写操作,读写的方式与字典一致,非常方便,可以将它当作带有自动持久化的字典
shelve的内部使用的是pickle,所以存在跨平台性差的问题
二.XML模块
XML又称可扩展标记语言,可扩展标记语言是一种很像超文本标记语言的标记语言,它的设计宗旨是传输数据,而不是显示数据,它的标签没有被预定义,需要自行定义标签,它被设计为具有自我描述性,它是W3C的推荐标准.
XML语法格式:
一、任何的起始标签都必须有一个结束标签。
二、可以采用另一种简化语法,可以在一个标签中同时表示起始和结束标签。这种语法是在大于符号之前紧跟一个斜线(/),
例如<百度百科词条/>。XML解析器会将其翻译成<百度百科词条></百度百科词条>。
三、标签必须按合适的顺序进行嵌套,所以结束标签必须按镜像顺序匹配起始标签,例如这是一串百度百科中的样例字符串。
这好比是将起始和结束标签看作是数学中的左右括号:在没有关闭所有的内部括号之前,是不能关闭外面的括号的。
四、所有的特性都必须有值。
五、所有的特性都必须在值的周围加上双引号。
注意:最外层必须有且只有一个标签,这个标签称为根标签
第一行应该又文档注释 例如:<?xml version="1.0" encoding "utf-8"?>
python对XML的解析:
python有三种方法解析XML:SAX,DOM以及ElementTree
1.SAX(simple API for XML)
python标准库包含SAX解析器,SAX用事件驱动模型,通过在解析XML的过程中触发一个个的事件并调用用户定义的回调函数来处理XML文件.
2.DOM(Document Object Model)
将XML数据在内存中解析成一个树,通过对树的操作来操作XML
3.ElementTree
ElementTree就像一个轻量级的DOM,具有方便友好的API,代码可用性好,速度快,消耗内存少.
与json的区别:
都是一种数据交互处理方式,只是xml比json诞生的更早,json的数据容量比xml小
python中的xml处理:
ElmentTree表示整个文件的元素树
Elment表示一个节点
属性:
1.text:开始标签与结束标签中间的文本
2.attrib:所有的属性
3.tag:标签的名字
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2012</year>
<gdppc>141100</gdppc>
<neighbor direction="E" name="Austria" />
<neighbor direction="W" name="Switzerland" />
<newTag name="宇宙无敌帅">楼帅哥</newTag>
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2015</year>
<gdppc>59900</gdppc>
<neighbor direction="N" name="Malaysia" />
<newTag name="宇宙无敌帅">楼帅哥</newTag>
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2015</year>
<gdppc>13600</gdppc>
<neighbor direction="W" name="Costa Rica" />
<neighbor direction="E" name="Colombia" />
<newTag name="宇宙无敌帅">楼帅哥</newTag>
</country>
</data>
test.xml
import xml.etree.ElementTree as et
# 读取xml文档到内存中 得到一个包含所有数据的节点树
# 每一个标签就称为一个节点或元素
a = et.parse('text.xml')
# 获取根标签
root = a.getroot()
# 获取子标签 找的是第一个
print(root.find('country'))
# 获取所有同级子标签
print(root.findall('country'))
# 获取year
print(root.iter('year'))
for i in root.iter('year'):
print(i)
# 遍历整个xml
for country in root:
print(country.tag,country.attrib,country.text)
for tag in country:
print(tag.tag, tag.attrib, tag.text) print(root.find('country').get('name')) # =============================================
tree = et.parse('text.xml')
for country in tree.findall('country'):
# 修改所有country的year文本 改成加1
yeartag = country.find('year')
yeartag.text = str(int(yeartag.text)+1)
# 删除所有country的rank元素
country.remove(country.find('rank'))
# 添加子标签
newtag = et.Element('newTag')
# 文本
newtag.text = '楼帅哥'
# 属性
newtag.attrib["name"] = '宇宙无敌帅'
# 添加
country.append(newtag) # 写回文件中
tree.write('text.xml',encoding='utf-8')
三.configparser模块
configparser模块是配置解析模块,用于提供程序运行所需要的一些信息文件
配置文件的格式如下:
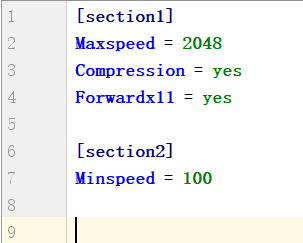
''[]''包含的为section,section下面为类似于key-value的配置内容,configparser默认支持'='或者':'两种分隔
实例代码如下:
import configparser
# 得到配置文件对象
cfg = configparser.ConfigParser()
# 读取配置文件
cfg.read('download.ini',encoding='utf-8')
print(cfg.get('section1','maxspeed'))
print(cfg.get('section2','minspeed')) # 修改最大速度为2048
cfg.set('section1','maxspeed','')
cfg.write(open('download.ini','w',encoding='utf-8'))
四.hashlib模块
hash是一种算法,用于将任意长度的数据映射到一段固定长度的字符
hash的特点:
1.输入数据不同得到的hash值可能相同
2.不能通过hash值来得到输入的值
3.如果算法相同,无论输入的数据长度是多少,得到的hash值长度相同
因为以上特点:常将hash算法用于加密和文件校验
输入用户名和密码 在代码中与数据库中的判断是否相同
思考当你的数据需要在网络中传递时,会受到威胁,黑客通过抓包工具就能截获你发送和接收的数据
所以你的数据如果涉及到隐私 就应该加密发送和接收的数据
常用的md5就是一种hash算法,常用提升安全性的手段就是加盐,就是指在把加密前的数据做一些改动再进行加密
实例代码如下:
import hashlib
md = hashlib.md5()
# 破解MD5可以尝试撞库,原理:有一个数据库,里面存放了常见的明文和密文的对应关系
# 所以可以拿着一个秘闻 去数据库中查找,有没有已经存在的明文
# 假设我已经拿到了一个众多账号中的以恶密码,可以拿这个密码,挨个测试所有账号
md.update(''.encode('utf-8'))
print(md.hexdigest()) # 今日在写一些需要网络传输程序时如果要进行加密,最好把加密的过程搞得复杂
# 密码长度为6位
# 在前面加一个abc 在后面加一个cba 之后再加密
pwd = 'abcdef'
pwd = 'abc'+pwd+'cba'
md2 = hashlib.md5()
md2.update(pwd.encode('utf-8'))
print(md2.hexdigest())
Python常用模块(三)的更多相关文章
- python——常用模块
python--常用模块 1 什么是模块: 模块就是py文件 2 import time #导入时间模块 在Python中,通常有这三种方式来表示时间:时间戳.元组(struct_time).格式化的 ...
- python常用模块之时间模块
python常用模块之时间模块 python全栈开发时间模块 上次的博客link:http://futuretechx.com/python-collections/ 接着上次的继续学习: 时间模块 ...
- python常用模块之subprocess
python常用模块之subprocess python2有个模块commands,执行命令的模块,在python3中已经废弃,使用subprocess模块来替代commands. 介绍一下:comm ...
- python常用模块-调用系统命令模块(subprocess)
python常用模块-调用系统命令模块(subprocess) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. subproces基本上就是为了取代os.system和os.spaw ...
- python常用模块-配置文档模块(configparser)
python常用模块-配置文档模块(configparser) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. ConfigParser模块用于生成和修改常见配置文档,当前模块的名称 ...
- Python常用模块-摘要算法(hashlib)
Python常用模块-摘要算法(hashlib) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MD5算法参数详解 1.十六进制md5算法摘要 #!/usr/bin/env p ...
- Python常用模块-时间模块(time&datetime)
Python常用模块-时间模块(time & datetime) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.初始time模块 #!/usr/bin/env pyth ...
- python 常用模块 time random os模块 sys模块 json & pickle shelve模块 xml模块 configparser hashlib subprocess logging re正则
python 常用模块 time random os模块 sys模块 json & pickle shelve模块 xml模块 configparser hashlib subprocess ...
- Python常用模块小结
目录 Python常用模块小结 一.Python常用模块小结 1.1 time模块 1.2 datetime模块 1.3 random模块 1.4 os模块 1.5 sys模块 1.6 json模块 ...
随机推荐
- Linux文件属性用户、组、权限
Linux系统中的用户是分角色的,用户的角色是由UID和GID来识别的(也就是说系统识别的是用户的UID.GID,而非用户用户名),有个UID是唯一的(系统中唯一如同身份证一样)用来标识系统的用户账号 ...
- luogu1891 疯狂lcm ??欧拉反演?
link 给定正整数N,求LCM(1,N)+LCM(2,N)+...+LCM(N,N). 多组询问,1≤T≤300000,1≤N≤1000000 \(\sum_{i=1}^nlcm(i,n)\) \( ...
- JavaScript小技巧随笔
1. 在用||做条件判断时,如果情况较多,我们可以考虑是否能够用Array.includes()方法代替 var conditionArray = [ test1, test2, test3 ]; i ...
- PAT - 1067 试密码 (20 分)
当你试图登录某个系统却忘了密码时,系统一般只会允许你尝试有限多次,当超出允许次数时,账号就会被锁死.本题就请你实现这个小功能. 输入格式: 输入在第一行给出一个密码(长度不超过 20 的.不包含空格. ...
- 关于Django在写小项目的一些小注意事项
个人常踩的坑的小问题: . 在筛选元素的时候,及时queryset里面只有一个元素,取值还是要用方法取出来 例:#当狗指定pd时候已经唯一,还是要加fir()方法,本人经常忘记了 models.Boo ...
- Linux 网络配置及常用服务配置(Redhat 6)
一.网络配置 1. VMWare 提供了三种网络工作模式供用户选择,他们分别是, ①Bridged(桥接模式): 如果网络中能提供多个IP地址,则使用桥接方式 ②NAT(网络地址转换模式): 如果网络 ...
- 安装tomcat时遇到的问题
1.刚开始在eclipse配置的tomcat是免安装的,后来提示 所以后来配置了一个安装版的. 2.后来运行server发现报错:8080,8005,端口被占用,然后关闭xammp上的server,然 ...
- File "<ipython-input-20-ac8d4b51998e>"
环境:Python 3.6 word = "Jesse" ") File "<ipython-input-20-ac8d4b51998e>" ...
- 前后端分离之JWT用户认证
在前后端分离开发时为什么需要用户认证呢?原因是由于HTTP协定是不储存状态的(stateless),这意味着当我们透过帐号密码验证一个使用者时,当下一个request请求时它就把刚刚的资料忘了.于是我 ...
- 单例模式+volatile禁止指令重排序
单例模式: 单例,顾名思义就是只能有一个.不能再出现第二个.就如同地球上没有两片一模一样的树叶一样. 在这里就是说:一个类只能有一个实例,并且整个项目系统都能访问该实例. 单例模式共分为两大类: 懒汉 ...