Convolutional Neural Networks for Visual Recognition 5
Setting up the data and the model
前面我们介绍了一个神经元的模型,通过一个激励函数将高维的输入域权值的点积转化为一个单一的输出,而神经网络就是将神经元排列到每一层,形成一个网络结构,这种结构与我们之前介绍的线性模型不太一样,因此score function也需要重新定义,神经网络实现了一系列的线性映射与非线性映射,这一讲,我们主要介绍神经网络的数据预处理以及score function的定义。
data processing
给定一个训练集,S={xi∈RD|i=1,2,...m},这个训练集含有m个样本,而且每个样本xi的维数为D,那么该训练集的向量均值为:μ=1m∑mi=1xi,而方差为:σ2=1m∑mi=1(xi−μ)2,σ称为标准差。
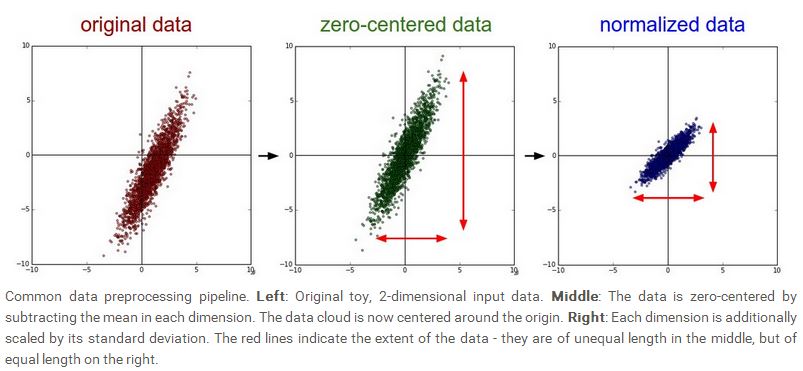
数据的预处理有多种形式,最常见的是去均值,即xi=xi−μ,每一个样本都减去平均值,这样可以保证新的样本均值为0。第二种预处理形式是归一化,这种处理形式将训练样本映射到统一的尺度上来,归一化可以直接用样本除以标准差,即xi=xi/σ;另外一种方法就是将样本的最小值与最大值分别映射到-1与1,然后其他值就取-1到1的中间值。下图给出了去均值与归一化的两种形式:
第三种数据处理形式是PCA,PCA是一种很经典的数据降维算法,可以将高维的数据映射到低维空间,同时保持原始数据的相关特性,利用上面的定义,我们可以得到去均值的训练集,设为X,那么协方差矩阵为:Cov=XtX,通过对协方差矩阵Cov做奇异值分解,我们可以得到[U,S,V]=svd(Cov),其中U是特征向量组成的矩阵,S记录的是特征值,U,S,很显然,X∈RN×D,Cov∈RD×D,U中的向量相当于基础向量,我们用X和U中的前面几个列向量(M≪N)相乘,那么Y=XU∈RN×M,所以原来的训练集X映射到一个更低维的空间,形成一个新的训练集Y,这就是PCA的降维。
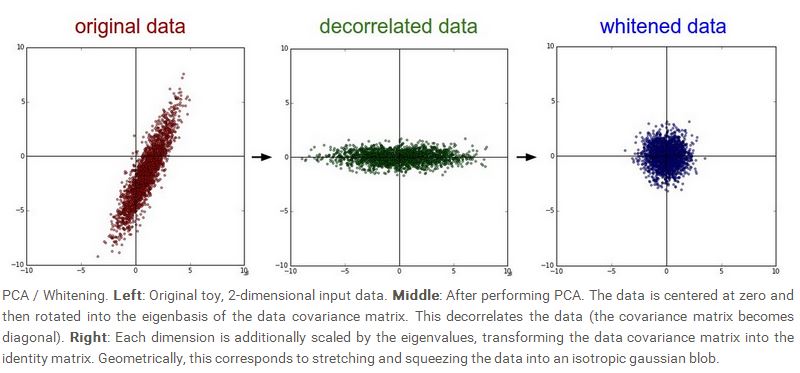
最后一种数据处理方法是whiten,简单来说,就是让训练集除以协方差矩阵Cov的特征值,因为Cov是一个对称的半正定矩阵,所以S是一个D×D的矩阵,S对角线上的值就是特征值,xi=xi/(divg(S)+ϵ),ϵ是一种程序上的技巧,防止分母为0的情况。下图给出了PCA和whiten两种形式:
我们也可以对图像做PCA和whiten处理,如下图所示:

图中最左边一列是从CIFAR-10中提取的一些示意图,CIFAR-10一共有50000张图,每张图的尺寸是48×64,将其展成一个行向量,就是3072维,利用PCA,可以得到该数据库的协方差矩阵Cov为3072×3072这是非常大的一个矩阵,利用奇异值分界,可以得到3072个特征向量,上图的左边第二列给出的就是前144个特征向量,对应最大的144个特征值,我们可以看到,越靠前的特征向量看起来越平滑,意味着前面的特征向量对应的是低频信息。右边的第二列是降维重建的图像,利用Y=XU,可以得到降维后的数据,Y中的每一个行向量记录的是每个特征之前的系数,即:xi=∑Mj=1yijuj,利用这个表达式,可以重建X,所以右边第二列就是利用降维后的数据进行重建得到的图像,可以看到图像比原图要模糊,意味着前面的特征向量记录的都是低频信息,最右边一列记录的就是whiten之后的图像,这里先用得到whiten之后的Y,然后利用这个Y对X进行重建。
在Convolutional Neural Networks 中,PCA和whiten比较少用,而取均值化和归一化两种形式比较常用,这里要注意的一个问题是我们做数据预处理的时候,只能对training set进行处理,不能对validation set 或者 test set进行处理。意味着均值和方差都只能从training set中得到。
Weight Initialization
接下来要介绍的就是权值的初始化,虽然我们不知道网络最终的权值会取什么值,但是认为它们一半大于0,一半小于0是一个合理的假设,如果因此而将权值的初始值都
设为0,却是一个错误,因为权值的初始值为0,意味着每个神经元的输出都是一样的,这样计算的梯度也是一样的,根本无法体现最开始的假设。
一般来说,我们会让权值接近于0,但不是完全等于0,所以我们会取很小的接近于0的随机数来初始化这些权值,不过神经网络是带有某种随机性的学习模型,不一定权值的初始值越小越好,权值的设定,最好是可以让梯度能够有效地传递,这是神经网络里比较关键的一点。
有的时候,对于权值的设定,还要做进一步的处理,一个神经元的输出分布的方差,会随着输入个数的增大而增大,换句话说,神经元的输出,会随着输入个数的增加抖动地更加剧烈,为了减少这种抖动,可以对权值做一个如下的处理:w=w/(√n),其中n表示输入神经元的个数。这个可以保证网络中的每个神经元输出大致一样。
偏移量bias一般设为0。
Regularization
下面介绍几种控制神经网络overfitting的方法。
L2 regularization:这大概是目前最常用的一种方法,通过在目标函数中引入12λw2,其中λ表示regularization的强度,
L2 regularization 直观上的解释就是对于出现极端分布的权值进行惩罚,而偏好于呈扩散分布的权值,这样可以保证网络里的每个输入都能发挥作用,而不至于让
网络只关注少部分的输入。
L1 regularization:是另外一种常见的方法,通过在目标函数中引入λw,也有人考虑综合L1 和L2 regularization,这个称为Elastic net Regularization,L1 regularization 会使得权值在优化的过程中逐渐层稀疏分布,并且权值非常靠近0,这使得这种神经网络对噪声不敏感,而且会倾向于利用输入
中比较重要的一些分量,一般情况下,L2 regularization的权值分布更加扩散,而且学习性能比L1 regularization要好。
Max norm constraints:这种方法是通过控制权值的上限来调整权值,一般来说,就是在正常的权值更新之后,利用一个约束条件,∥w∥2<c,对权值进行“挤压”,这样可以保证权值不会更新的幅度不会太大。
Drop out:这是目前非常流行的一种方法,而且很有效,是对前面几种方法的一种补充,在前面几种方法的基础上,在训练阶段,通过对某些神经元进行抑制,减少神经元的个数来到达控制的目的,下图给出了drop out的示意图:

在程序的设计上,就是对该神经元的输出强制变为0,使得该神经元不再发挥作用。
但是需要注意的一点是,一般情况下,drop out只会在训练的时候执行,而在测试的时候,所有的神经元都将发挥作用,也就是训练的时候不会做drop out,但是为了保证训练与测试时神经元输出的尺度要一样,以保证输出的期望一样,一种解决方法是在测试的时候对神经元的输出乘以概率p,另外一种解决方法是在训练的时候对神经元的输出除以概率p,一般来说p=0.5,实际使用中,我们会采用第二种解决方案。
Drop out向我们展示了神经网络前向传递时的一种随机机制,这种机制可以让噪声在测试的时候被边缘化,Convolutional Neural Networks 也可以利用drop out的这一性质,采用随机pooling, fractional pooling等。
一般来不会对bias做regularization,因为bias相对于权值来说,数目要少。对于整个网络的影响没有权值那么大。而且做regularization的时候,不会每一层都做,一般来说,我们会在网络的输出层做regularization。在实际的应用中,我们会采用单一的L2 regularization,结合drop out,一般来说概率取p=0.5。
Loss function
前面我们已经讨论了目标函数的 regularization loss部分,现在我们还要探讨一下data loss,data loss我们定义为预测值与目标值之间的偏差,一个训练集整体的
data loss是每个训练样本的偏差之和的平均值,即:L=1N∑iLi,其中N表示样本个数,我们用一个简单的函数表示网络的输出f=f(xi,W),
神经网络可以解决如下的几类问题:
第一个是分类问题,这个也是目前我们一直在讨论的问题,这里我们假设每个样本只属于某一类,即每个样本只有一个类标签,那么cost function可以写成如下的形式:
或者用softmax 的形式表示:
这些适用于类别较少的情况,如果类别很多的话,比如有几千类,这样的话,就要考虑用hierarchical softmax。上面的两种形式都是针对样本属于一个类别的情况,还有更复杂的情况是一个样本可能属于多个类别,这样的话,一种可行的方法是为每个类别都建立一个二元分类器,用来判断某个样本是否属于该类,那么其loss function
可以表示成:
yij表示第i个样本是否属于第j类,如果是,则yij=1,否则 yij=−1,fj表示对样本的预测,是否属于第j类。
另外一种方法是建立一个二元的logistic regression 分类器,这种分类器计算的是概率,如:
因为概率之和为1,所以P(y=0|x;w,b)=1−P(y=1|x;w,b),那么,利用这种分类器建立的多类别loss function为:
类似地,yij表示第i个样本是否属于第j类,如果是,则yij=1,否则 yij=0,fj表示对样本的预测,是否属于第j类。 可以证明,∂Li/∂fj=yij−σ(fj)
除了分类问题,神经网络也可以解决回归问题,回归问题的目标值和预测值都是连续的实数,而分类问题的目标值和预测值是离散的。回归问题常用的loss function是L2-norm,或者L1-norm,如下式所示:
L2-norm:
L1-norm:
不过要注意的是,L2-norm的优化比起其它的分类器要困难的多,它有一个非常脆弱而特殊的性质,就是希望网络的输出与目标值要完全一样,因为预测的是连续值,而分类问题就好的多,因为只有一个值是我们需要的,其它值的分布,大小并不会影响网络的性能。所以L2-norm不太稳健,当我们面对一个回归问题的时候,尽可能将其转化为分类问题。
声明:lecture notes里的图片都来源于该课程的网站,只能用于学习,请勿作其它用途,如需转载,请说明该课程为引用来源。 http://cs231n.stanford.edu/
Convolutional Neural Networks for Visual Recognition 5的更多相关文章
- Convolutional Neural Networks for Visual Recognition 1
Introduction 这是斯坦福计算机视觉大牛李菲菲最新开设的一门关于deep learning在计算机视觉领域的相关应用的课程.这个课程重点介绍了deep learning里的一种比较流行的模型 ...
- Convolutional Neural Networks for Visual Recognition
http://cs231n.github.io/ 里面有很多相当好的文章 http://cs231n.github.io/convolutional-networks/ Table of Cont ...
- 卷积神经网络用于视觉识别Convolutional Neural Networks for Visual Recognition
Table of Contents: Architecture Overview ConvNet Layers Convolutional Layer Pooling Layer Normalizat ...
- Convolutional Neural Networks for Visual Recognition 8
Convolutional Neural Networks (CNNs / ConvNets) 前面做了如此漫长的铺垫,现在终于来到了课程的重点.Convolutional Neural Networ ...
- Convolutional Neural Networks for Visual Recognition 2
Linear Classification 在上一讲里,我们介绍了图像分类问题以及一个简单的分类模型K-NN模型,我们已经知道K-NN的模型有几个严重的缺陷,第一就是要保存训练集里的所有样本,这个比较 ...
- Convolutional Neural Networks for Visual Recognition 7
Two Simple Examples softmax classifier 后,我们介绍两个简单的例子,一个是线性分类器,一个是神经网络.由于网上的讲义给出的都是代码,我们这里用公式来进行推导.首先 ...
- Convolutional Neural Networks for Visual Recognition 4
Modeling one neuron 下面我们开始介绍神经网络,我们先从最简单的一个神经元的情况开始,一个简单的神经元包括输入,激励函数以及输出.如下图所示: 一个神经元类似一个线性分类器,如果激励 ...
- cs231n spring 2017 lecture1 Introduction to Convolutional Neural Networks for Visual Recognition 听课笔记
1. 生物学家做实验发现脑皮层对简单的结构比如角.边有反应,而通过复杂的神经元传递,这些简单的结构最终帮助生物体有了更复杂的视觉系统.1970年David Marr提出的视觉处理流程遵循这样的原则,拿 ...
- Stanford CS231n - Convolutional Neural Networks for Visual Recognition
网易云课堂上有汉化的视频:http://study.163.com/course/courseLearn.htm?courseId=1003223001#/learn/video?lessonId=1 ...
随机推荐
- Linux Samba文件共享服务配置
http://blog.csdn.net/xht555/article/details/4631063
- Zabbix 监控tomcat web
个人博客:https://blog.sharedata.info/ 在zabbix监控web,web容器是tomcat 默认的端口是8080导致web监控失败!不能找到主机因此在修改tomcat 端口 ...
- 【BZOJ3707】圈地 几何
[BZOJ3707]圈地 Description 2维平面上有n个木桩,黄学长有一次圈地的机会并得到圈到的土地,为了体现他的高风亮节,他要使他圈到的土地面积尽量小.圈地需要圈一个至少3个点的多边形,多 ...
- oracle 如何完全删除干净
在安装oracle的时候如果出现了,指定的SID在本机上已经存在.这样的报错的话.这边你肯定是第二次在安装你的oracle了,这里出现这样的错误是你没有吧原先的那些关于oracle的东西给清理干净,这 ...
- zookeeper curator CRUD
目录 Curator客户端的基本操作 写在前面 1.1.1. Curator客户端的依赖包 1.1.2. Curator 创建会话 1.1.3. CRUD 之 Create 创建节点 1.1.4. C ...
- PAT 1058. 选择题(20)
批改多选题是比较麻烦的事情,本题就请你写个程序帮助老师批改多选题,并且指出哪道题错的人最多. 输入格式: 输入在第一行给出两个正整数N(<=1000)和M(<=100),分别是学生人数和多 ...
- Django安装debug tool bar
1.安装Django Debug Toolbarpip install django-debug-toolbar 2.设置项目的DEBUG属性DEBUG = True 3.INSTALLED_APPS ...
- The path "fos_user.from_email.address" cannot contain an empty value, but got null.
The path "fos_user.from_email.address" cannot contain an empty value, but got null.. 修改 pa ...
- 关于Unicode转为str的方法
unicode_a=u'\u810f\u4e71' str_a=unicode_a.encode('unicode-escape').decode('string_escape')
- Python:笔记(1)——基础语法
Python:笔记(1)——基础语法 我很抱歉有半年没有在博客园写过笔记了,客观因素有一些,但主观原因居多,再多的谴责和批判也都于事无补,我们能做的就是重振旗鼓,继续出发! ——写在Python之前 ...