Kafka实战系列--Kafka API使用体验
前言:
kafka是linkedin开源的消息队列, 淘宝的metaq就是基于kafka而研发. 而消息队列作为一个分布式组件, 在服务解耦/异步化, 扮演非常重要的角色. 本系列主要研究kafka的思想和使用, 本文主要讲解kafka的一些基本概念和api的使用.
*) 准备工作
1) 配置maven依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.9.2</artifactId>
<version>0.8.1.1</version>
</dependency>
2).配置hosts
vim /etc/hosts
把kafka集群相关的ip及其hostname, 配置到kafka客户端的本地机器
*) Kafka的基础知识
1). Broker, Zookeeper, Producer, Consumer
Broker具体承担消息存储转发工作, Zookeeper则用与元信息的存储(topic的定义/消费进度), Producer则是消息的生产者, Consumer则是消息的消费者.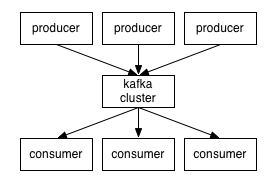
2). Topic, Partition, Replication, Consumer Group
Topic对应一个具体的队列, 在Kafka的概念中, 一个应用一个队列. 应用数据往往呈现部分有序的特点, 因此对kafka的队列, 引入partition的概念, 即可topic划分为多个partition. 单个Partition内保证有序, Partition间不保证. 这样作的好处, 是充分利用了集群的能力, 均匀负载和提高性能.
Replication主要为了高可用性, 保证部分节点失效的恶劣情况下, 队列数据能不丢.
Consumer Group的概念的引入, 很有创新性, 把以往传统队列(topic模式, queue模式)的属性从队列本身挪到了消费端. 若要使用queue模式, 则所有的消费端都采用统一个consumer group, 若采用topic模式, 则所有的客户端都设置为不同的consumer group. 其partition的消费进度在zookeeper有所保存.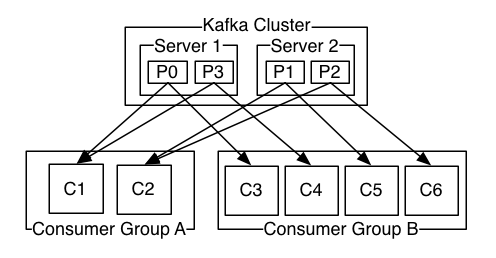
*) Kafka API的简单样列代码
1). 生产者代码
分区类代码片段
public class SimplePartitioner implements Partitioner {
public SimplePartitioner (VerifiableProperties props) {
}
public int partition(Object key, int numPartitions) {
return (key.hashCode() & 0x0FFFFFFF) % numPartitions;
}
}
评注: SimplePartitioner用于对消息进行分发到具体的partition中, 有消息的key来决定, 这个有点像map/reduce中的partition机制.
生产者代码片段
Properties props = new Properties();
// 配置metadata.broker.list, 为了高可用, 最好配两个broker实例
props.put("metadata.broker.list", "127.0.0.1:9092");
// serializer.class为消息的序列化类
props.put("serializer.class", "kafka.serializer.StringEncoder");
// 设置Partition类, 对队列进行合理的划分
props.put("partitioner.class", "mmxf.kafka.practise.SimplePartitioner");
// ACK机制, 消息发送需要kafka服务端确认
props.put("request.required.acks", "1"); ProducerConfig config = new ProducerConfig(props);
Producer<String, String> producer = new Producer<String, String>(config); // KeyedMessage<K, V>
// K对应Partition Key的类型
// V对应消息本身的类型
// topic: "test", key: "key", message: "message"
KeyedMessage<String, String> message = new KeyedMessage<String, String>("test", "key", "message");
producer.send(message); // 关闭producer实例
producer.close();
2). 消费者代码
使用High Level Consumer的API 线程模型和Partition数最好能保持一致, 即One Thread For Partition
参考sample样例: https://cwiki.apache.org/confluence/display/KAFKA/Consumer+Group+Example
代码片段如下:
public static void main(String[] args) {
// *) 创建ConsumerConfig
Properties props = new Properties();
// 设置zookeeper的链接地址
props.put("zookeeper.connect", "127.0.0.1:2181");
// 设置group id
props.put("group.id", "group_id");
// kafka的group 消费记录是保存在zookeeper上的, 但这个信息在zookeeper上不是实时更新的, 需要有个间隔时间更新
props.put("auto.commit.interval.ms", "1000");
ConsumerConfig consumerConfig = new ConsumerConfig(props);
ConsumerConnector consumer = (ConsumerConnector) Consumer.createJavaConsumerConnector(consumerConfig);
String topic = "test";
int threadNum = 1;
// *) 设置Topic=>Thread Num映射关系, 构建具体的流
Map<String, Integer> topicCountMap = new HashMap<String, Integer>();
topicCountMap.put(topic,threadNum);
Map<String, List<KafkaStream<byte[], byte[]>>> consumerMap = consumer.createMessageStreams(topicCountMap);
List<KafkaStream<byte[], byte[]>> streams = consumerMap.get(topic);
// *) 启动线程池去消费对应的消息
ExecutorService executor = Executors.newCachedThreadPool();
for ( final KafkaStream<byte[], byte[]> stream : streams ) {
executor.submit(new Runnable() {
public void run() {
ConsumerIterator<byte[], byte[]> iter = stream.iterator();
while ( iter.hasNext() ) {
MessageAndMetadata<byte[] , byte[]> mam = iter.next();
System.out.println(
String.format("thread_id: %d, key: %s, value: %s",
Thread.currentThread().getId(),
new String(mam.key()),
new String(mam.message())
)
);
}
}
});
}
try {
Thread.sleep(1000 * 10);
} catch (InterruptedException e) {
e.printStackTrace();
}
// *) 优雅地退出
consumer.shutdown();
executor.shutdown();
while ( !executor.isTerminated() ) {
try {
executor.awaitTermination(1, TimeUnit.SECONDS);
} catch (InterruptedException e) {
}
}
}
结果输出:
thread_id: 18, key: key, value: message
Kafka实战系列--Kafka API使用体验的更多相关文章
- Kafka实战系列--Kafka的安装/配置
*) 安装和测试 cd /path/to/server#) 下载kafka二进制包wget http://apache.fayea.com/apache-mirror/kafka/0.8.1.1/ka ...
- Kafka实战-Kafka到Storm
1.概述 在<Kafka实战-Flume到Kafka>一文中给大家分享了Kafka的数据源生产,今天为大家介绍如何去实时消费Kafka中的数据.这里使用实时计算的模型——Storm.下面是 ...
- Kafka实战-Kafka Cluster
1.概述 在<Kafka实战-入门>一篇中,为大家介绍了Kafka的相关背景.原理架构以及一些关键知识点,本篇博客为大家来赘述一下Kafka Cluster的相关内容,下面是今天为大家分享 ...
- Kafka科普系列 | Kafka中的事务是什么样子的?
事务,对于大家来说可能并不陌生,比如数据库事务.分布式事务,那么Kafka中的事务是什么样子的呢? 在说Kafka的事务之前,先要说一下Kafka中幂等的实现.幂等和事务是Kafka 0.11.0.0 ...
- Kafka实战-Flume到Kafka
1.概述 前面给大家介绍了整个Kafka项目的开发流程,今天给大家分享Kafka如何获取数据源,即Kafka生产数据.下面是今天要分享的目录: 数据来源 Flume到Kafka 数据源加载 预览 下面 ...
- 【转】Kafka实战-Flume到Kafka
Kafka实战-Flume到Kafka Kafka 2015-07-03 08:46:24 发布 您的评价: 0.0 收藏 2收藏 1.概述 前面给大家介绍了整个Kafka ...
- Kafka实战-数据持久化
1.概述 经过前面Kafka实战系列的学习,我们通过学习<Kafka实战-入门>了解Kafka的应用场景和基本原理,<Kafka实战-Kafka Cluster>一文给大家分享 ...
- Kafka实战-实时日志统计流程
1.概述 在<Kafka实战-简单示例>一文中给大家介绍来Kafka的简单示例,演示了如何编写Kafka的代码去生产数据和消费数据,今天给大家介绍如何去整合一个完整的项目,本篇博客我打算为 ...
- Kafka实战-Flume到Kafka (转)
原文链接:Kafka实战-Flume到Kafka 1.概述 前面给大家介绍了整个Kafka项目的开发流程,今天给大家分享Kafka如何获取数据源,即Kafka生产数据.下面是今天要分享的目录: 数据来 ...
随机推荐
- Maven学习(三) -- 仓库
标签(空格分隔): 学习笔记 坐标和依赖时任何一个构件在Maven世界中的逻辑表示方式:而构件的物理表示方式是文件,Maven通过仓库来同意管理这些文件. 任何一个构件都有其唯一的坐标,根据这个坐标可 ...
- Linux下内存占用和CPU占用的计算
->使用free命令查看内存使用情况: 1.echo 3 > /proc/sys/vm/drop_caches 2.free 或者使用cat /proc/yourpid/status 来查 ...
- touch穿透
出现穿透的前提:上层绑定touch事件,下层绑定click事件. 解决方案:touchend绑定: e.preventDefault();$(下层).css("pointer-events& ...
- U9单据UI开发--单据类型UI开发
1.在解决方案下新建UI界面项目,命名以UI作为后缀 2.先删除系统默认新建的UI界面数据模型,并新建界面数据 3.新建单据类型UIModel(界面数据),以model作为界面数据后缀名 4.修改单据 ...
- sqlloader导出数据和导入数据
分类: Oracle 忙了一天终于把sqlloader导出数据和导入数据弄清楚了,累死俺了... 这个总结主要分为三个大部分,第一部分(实例,主要分两步),第二部分(参数小总结),第三部分(完全参数总 ...
- 【CSU1812】三角形和矩形 【半平面交】
检验半平面交的板子. #include <stdio.h> #include <bits/stdc++.h> using namespace std; #define gg p ...
- python 安装模块步骤
1.下载 pyocr-0.4.1.tar.gz tar.gz文件 解压 放到 c:/python27 文件夹下面 C:\Python27\pyocr-0.4.1 直接 cmd 命令 进入 ...
- 安装Composer 步骤
Composer 是 PHP 的一个依赖管理工具.它允许你申明项目所依赖的代码库,它会在你的项目中为你安装他们.Composer 不是一个包管理器.是的,它涉及 "package ...
- 关于如何来构造一个String类
今天帮着一位大二的学弟写了一个String的类,后来一想这个技术点,也许不是什么难点,但是还是简单的记录一些吧! 为那些还在路上爬行的行者,剖析一些基本的实现..... 内容写的过于简单,没有涉及到其 ...
- 手动实现WCF[转]
由于应用程序开发中一般都会涉及到大量的增删改查业务,所以这个程序将简单演示如何在wcf中构建简单的增删改查服务.我们知道WCF是一组通讯服务框架,我将解决方案按大范围划分为服务端,客户端通过服务寄宿程 ...