Kafka集群环境搭建
Kafka是一个分布式、可分区、可复制的消息系统。Kafka将消息以topic为单位进行归纳;Kafka发布消息的程序称为producer,也叫生产者;Kafka预订topics并消费消息的程序称为consumer,也叫消费者;当Kafka以集群的方式运行时,可以由一个服务或者多个服务组成,每个服务叫做一个broker,运行过程中producer通过网络将消息发送到Kafka集群,集群向消费者提供消息。
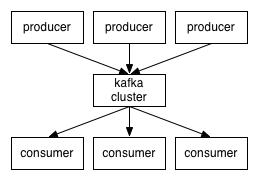
Kafka客户端和服务端基于TCP协议通信,并且提供了Java客户端API,实际上Kafka对多种语言都有支持
接下来访问Apache Kafka官网下载安装包,http://kafka.apache.org/ 网站的界面非常的简洁,下载和文档等分类一目了然
点击左边的download按钮,进入版本选择,这里选择0.8.2.2系列的基于Scala 2.9.2编写的kafka_2.9.2-0.8.2.2.tgz包,
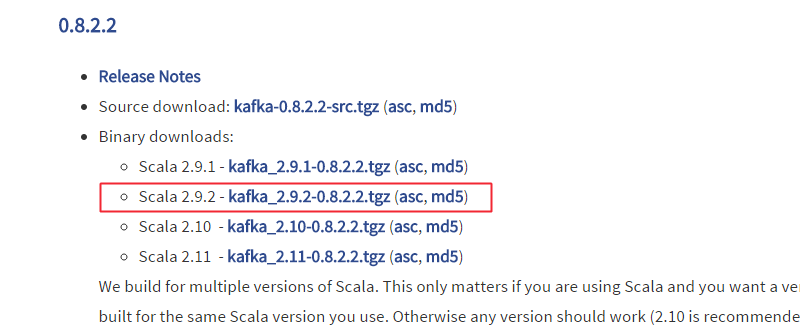
点击会进入下载页面,再次点击下载即可,下载完毕上传至服务器
和之前一样安装kafka集群之前,确保zookeeper服务已经正常运行,3台主机准备工作都以完成,并且通信正常,这些之前都详细说过,这三台主机分别为:linux1,linux2,linux3,接下来在linux1主机上执行释放:
$ tar -xvzf kafka_2.9.2-0.8.2.2.tgz
$ mv kafka_2.9.2-0.8.2.2 /usr/
$ cd /usr/kafka_2.9.2-0.8.2.2
这里相当于把kafka安装到了/usr目录下,接下来编辑配置文件,执行:
vim config/server.properties
修改broker.id=1,默认是0

这个值是集群中唯一的一个整数,每台机器各不相同,这里linux1设置为1其他机器后来再更改
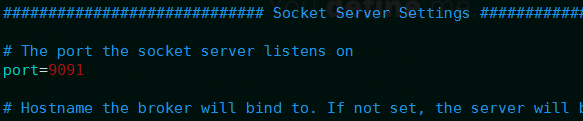
修改port=9091 默认为9092,就是为了方便后来的通信
这里设置log.dirs=/usr/kafka-logs默认为/tmp/kafka-logs,

这个目录可以根据自己习惯定义,意思就是设置Kafka日志存放的目录,这个目录后来我们需要手动建立
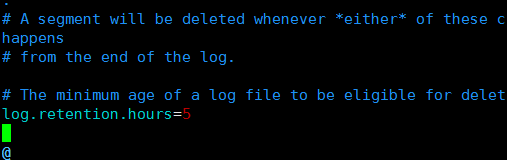
设置log.retention.hours=5 默认是168,代表清理日志的时间,根据实际情况配置即可
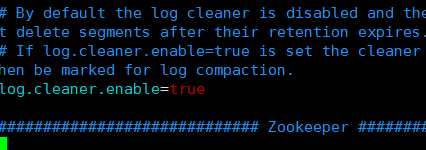
设置log.cleaner.enable=true,默认为false,这里一定要设置为true,否则Kafka不会自动清理日志
设置zookeeper.connect=linux1:2181,linux2:2181,linux3:2181/kafka,配置zookeeper集群的列表,这里就是这三台主机,然后指定了Kafka在zookeeper上创建的目录为/kafka,

最后一项配置,默认即可

表示连接zookeeper服务器的超时时间,以上设置都完毕,没问题保存配置并退出,然后将安装包通过网络发送至其他主机,就避免再次配置了
$ scp -r kafka_2.9.2-0.8.2.2 linux2:/usr/
$ scp -r kafka_2.9.2-0.8.2.2 linux3:/usr/
这样就发送到了linux2和linux3这两台主机,然后分别修改linux2和linux3中config/server.properties配置文件中broker.id分别为2和3,保存
然后集群中三台主机都执行:
mkdir /usr/kafka-logs
这样就创建了日志存放目录,到这里就算配置完毕了,
然后可以启动kafka服务,进入kafka_2.9.2-0.8.2.2目录,运行命令启动服务:
nohup bin/kafka-server-start.sh config/server.properties &
所有主机都要执行上面这条命令,到这里集群都已经启动了Kafka服务
接下来测试Kafka服务是否正常使用,在linux1上创建一个topic消息队列:
bin/kafka-topics.sh --create --replication-factor --partitions --topic dt_test --zookeeper linux1:,linux2:,linux3:/kafka
这里指定了2个副本,2个分区,topic名为dt_test,并且指定zookeeper分布,运行完这个稍等一下,如果卡住再次按回车即可回到命令行界面
然后在linux1上创建一个消费者consumer:
bin/kafka-console-consumer.sh --zookeeper linux1:,linux2:,linux3:/kafka --topic dt_test
这里用--topic指定了刚才刚刚创建的消息队列,现在命令行进入等待,等待生产者生产
现在在linux2上面创建一个生产者producer:
bin/kafka-console-producer.sh --broker-list linux2:,linux3: --topic dt_test
这里--broker-list指定建立生产者服务的节点,可以是本机也可以是指定多台机器,这里指定了linux2和linux3,--topic同样指定消息作业名,需要注意的是端口号这是是9091必须和前面配置文件中的设置一致,否则无法通信,我们前面把端口号改成9091这里必须是9091,如果端口号默认,那么这里一定是9092才可以;命令执行后同样会等待用户输入,我们输入Hello Kafka!

回车之后查看linux1的等待窗口:

可以看到这里将之前的输入消费输出了,这说明Kafka服务运行正常
以上就是Kafka集群搭建和测试的最基本的内容,另外运行bin/kafka-server-stop.sh脚本可以停止Kafka服务,重启Kafka时先停止再启动即可
Kafka集群环境搭建的更多相关文章
- kafka 集群环境搭建 java
简单记录下kafka集群环境搭建过程, 用来做备忘录 安装 第一步: 点击官网下载地址 http://kafka.apache.org/downloads.html 下载最新安装包 第二步: 解压 t ...
- 数据源管理 | Kafka集群环境搭建,消息存储机制详解
本文源码:GitHub·点这里 || GitEE·点这里 一.Kafka集群环境 1.环境版本 版本:kafka2.11,zookeeper3.4 注意:这里zookeeper3.4也是基于集群模式部 ...
- 大数据 -- zookeeper和kafka集群环境搭建
一 运行环境 从阿里云申请三台云服务器,这里我使用了两个不同的阿里云账号去申请云服务器.我们配置三台主机名分别为zy1,zy2,zy3. 我们通过阿里云可以获取主机的公网ip地址,如下: 通过secu ...
- kafka集群环境搭建(Linux)
一.准备工作 centos6.8和jvm需要准备64位的,如果为32位,服务启动的时候报java.lang.OutOfMemoryError: Map failed 的错误. 链接:http://pa ...
- Kafka集群环境搭建(2.9.2-0.8.2.2)
Kafka是一个分布式.可分区.可复制的消息系统.Kafka将消息以topic为单位进行归纳:Kafka发布消息的程序称为producer,也叫生产者:Kafka预订topics并消费消息的程序称为c ...
- 【Kafka】Kafka集群环境搭建
目录 一.初始环境准备 二.下载安装包并上传解压 三.修改配置文件 四.启动ZooKeeper 五.启动Kafka集群 一.初始环境准备 必须安装了JDK和ZooKeeper,并保证Zookeeper ...
- Ubuntu下kafka集群环境搭建及测试
kafka介绍: Kafka[1是一种高吞吐量[2] 的分布式发布订阅消息系统,有如下特性: 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能 ...
- 大数据 -- Hadoop集群环境搭建
首先我们来认识一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.它其实是将一个大文件分成若干块保存在不同服务器的多个节点中.通过联网 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十一)NIFI1.7.1安装
一.nifi基本配置 1. 修改各节点主机名,修改/etc/hosts文件内容. 192.168.0.120 master 192.168.0.121 slave1 192.168.0.122 sla ...
随机推荐
- 深入浅出的javascript的正则表达式学习教程
深入浅出的javascript的正则表达式学习教程 阅读目录 了解正则表达式的方法 了解正则中的普通字符 了解正则中的方括号[]的含义 理解javascript中的元字符 RegExp特殊字符中的需要 ...
- 密码学初级教程(三)公钥密码RSA
密码学家工具箱中的6个重要的工具: 对称密码 公钥密码 单向散列函数 消息认证码 数字签名 伪随机数生成器 公钥密码(非对称密码) 问题: 公钥认证问题 处理速度是对称密码的几百分之一 求离散对数非常 ...
- sqlserver中将某数据库下的所有表字段名称为小写的改为大写
declare @name varchar(50), @newname varchar(50),@colname varchar(50) declare abc cursor for select ( ...
- 同一个解决方案"引用"其他的项目出现感叹号...
项目A是自己新建的... 但是项目B是"添加"→"现有项目"添加的... 所以项目B引用项目A的时候,引用的项目A显示感叹号... 项目A右击"属性& ...
- 第三天 moyax
struct Blog { static let BaseURL = NSURL(string: "http://192.168.1.103/blog")! } extension ...
- Hello 畅连·西瓜 帮助与更新
无感认证很好用,软件不再更新, 感谢每一位朋友的陪伴,谢谢! (2016.12.15) 百度云:点击下载 ------------旧版更新日志------------- Hello 畅连·西瓜 官网: ...
- Java 的printf(转)
出处:http://blog.csdn.net/swandragon/article/details/4653600 public class TestPrintf{public static voi ...
- Unity手游之路<四>3d旋转-四元数,欧拉角和变幻矩阵
http://blog.csdn.net/janeky/article/details/17272625 今天我们来谈谈关于Unity中的旋转.主要有三种方式.变换矩阵,四元数和欧拉角. 定义 变换矩 ...
- NSFileManager
//返回一个字符串数组(子路径), 并且不包含文件夹 [[NSFileManager defaultManager] contentsOfDirectoryAtPath:folderPath erro ...
- leetcode 33. Search in Rotated Sorted Array
Suppose a sorted array is rotated at some pivot unknown to you beforehand. (i.e., 0 1 2 4 5 6 7 migh ...