elasticsearch单机多实例环境部署
elasticsearch的功能,主要用在搜索领域,这里,我来研究这个,也是项目需要,为公司开发了一款CMS系统,网站上的搜索栏功能,我打算采用elasticsearch来实现。 elasticsearch的高性能,低延时是最大的吸引力。
系统环境:
Centos6.8, X86_64。
Elasticsearch的版本: 2.3.5,下载地址来自官网,选择的是RPM包。
es安装完毕后,默认安装的路径是/usr/share/elasticsearch, 配置文件,默认是在/etc/elasticsearch目录。这里要重点说说配置文件的信息:
[root@CloudGame bin]# cd /etc/elasticsearch/
[root@CloudGame elasticsearch]# ll
total
-rwxr-x---. root elasticsearch Jul : elasticsearch.yml
-rwxr-x---. root elasticsearch Jul : logging.yml
drwxr-x---. root elasticsearch Jul : scripts
[root@CloudGame elasticsearch]# tree
.
├── elasticsearch.yml #es的系统配置文件
├── logging.yml #es的日志配置文件
└── scripts directory, files
单实例的启动很简单,安装完成后,直接service elasticsearch start即可启动,日志在/var/log/elasticsearch目录,数据在/var/lib/elasticsearch目录。
这里重点放在如何配置单机多实例上面。为了简单起见,多实例就选择启动2个实例,更多的实例,和2个实例是一样的配置,只是简单的相应改改参数即可。
1. 在/etc目录下创建esconf目录,然后在esconf下面创建esins1以及esins2目录。将原本/etc/elasticsearch目录的内容copy到esins1以及esins2目录下。
[root@CloudGame esconf]# pwd
/etc/esconf
[root@CloudGame esconf]# tree
.
├── esins1
│ ├── elasticsearch.yml
│ ├── logging.yml
│ └── scripts
├── esins2
├── elasticsearch.yml
├── logging.yml
└── scripts directories, files
2. 修改配置文件elasticsearch.yml,对esins1以及esins2下面的这个文件都做修改。主要是修改其节点信息,网络链接信息,以及日志数据路径信息。下面直接上修改好的配置文件内容。
实例1: esins1目录下的elasticsearch.yml内容
[root@CloudGame esins1]# cat elasticsearch.yml
# ======================== Elasticsearch Configuration =========================
#
# NOTE: Elasticsearch comes with reasonable defaults for most settings.
# Before you set out to tweak and tune the configuration, make sure you
# understand what are you trying to accomplish and the consequences.
#
# The primary way of configuring a node is via this file. This template lists
# the most important settings you may want to configure for a production cluster.
#
# Please see the documentation for further information on configuration options:
# <http://www.elastic.co/guide/en/elasticsearch/reference/current/setup-configuration.html>
#
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#
cluster.name: tksearch #es默认的集群名称是elasticsearch,注意,集群中是以name来区分节点属于那个集群的。
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
node.name: node1 #节点的名称
#
# Add custom attributes to the node:
#
# node.rack: r1
#
node.master: true #是否让这个节点作为默认的master,若不是,默认会选择集群里面的第一个作为master,es有一套选择那个节点作为master的机制
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
path.data: /home/AppData/es/esins1/data #配置节点数据存放的目录
#
# Path to log files:
#
path.logs: /home/AppData/es/esins1/logs #配置节点日志存放的目录
#
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
#
# bootstrap.mlockall: true
#
# Make sure that the `ES_HEAP_SIZE` environment variable is set to about half the memory
# available on the system and that the owner of the process is allowed to use this limit.
#
# Elasticsearch performs poorly when the system is swapping the memory.
#
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: 0.0.0.0 #配置节点绑定的地址,全0表示可以绑定任何地址,当然这里,本机可以是127.0.0.1回还地址,也可以是ifconfig看到的eth1的地址。
#
# Set a custom port for HTTP:
#
http.port: 9200 #配置当前节点对外http访问的端口号,默认是9200,不配的话,es会从9200-9299当中找一个未用过的。
#
# For more information, see the documentation at:
# <http://www.elastic.co/guide/en/elasticsearch/reference/current/modules-network.html>
#
transport.tcp.port: 9300 #es集群节点之间的通信端口号。默认9300.
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when new node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300"] #集群多播时发现其他节点的主机列表, 真实多机集群环境下,这里会是多个主机的IP列表,默认格式“host:port”的数组
#
# Prevent the "split brain" by configuring the majority of nodes (total number of nodes / + ):
#
# discovery.zen.minimum_master_nodes:
#
# For more information, see the documentation at:
# <http://www.elastic.co/guide/en/elasticsearch/reference/current/modules-discovery.html>
#
# ---------------------------------- Gateway -----------------------------------
#
# Block initial recovery after a full cluster restart until N nodes are started:
#
# gateway.recover_after_nodes:
#
# For more information, see the documentation at:
# <http://www.elastic.co/guide/en/elasticsearch/reference/current/modules-gateway.html>
#
# ---------------------------------- Various -----------------------------------
#
# Disable starting multiple nodes on a single system:
#
node.max_local_storage_nodes: 2 #默认情况下,是不建议单机启动多个node的,这里这个参数,就是告知es单机上启动了几个实例,这里我们配置2个,若是要配置3个或者更多实例,修改这个数字即可
#
# Require explicit names when deleting indices:
#
# action.destructive_requires_name: true
实例2: esins2目录下的elasticsearch.yml内容,配置和esins1几乎一样。
[root@CloudGame esins2]# cat elasticsearch.yml
# ======================== Elasticsearch Configuration =========================
#
# NOTE: Elasticsearch comes with reasonable defaults for most settings.
# Before you set out to tweak and tune the configuration, make sure you
# understand what are you trying to accomplish and the consequences.
#
# The primary way of configuring a node is via this file. This template lists
# the most important settings you may want to configure for a production cluster.
#
# Please see the documentation for further information on configuration options:
# <http://www.elastic.co/guide/en/elasticsearch/reference/current/setup-configuration.html>
#
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#
cluster.name: tksearch
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
node.name: node2
#
# Add custom attributes to the node:
#
# node.rack: r1
#
node.master: false
# ----------------------------------- Paths ------------------------------------
#
# Path to directory where to store the data (separate multiple locations by comma):
#
path.data: /home/AppData/es/esins2/data
#
# Path to log files:
#
path.logs: /home/AppData/es/esins2/logs
#
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
#
# bootstrap.mlockall: true
#
# Make sure that the `ES_HEAP_SIZE` environment variable is set to about half the memory
# available on the system and that the owner of the process is allowed to use this limit.
#
# Elasticsearch performs poorly when the system is swapping the memory.
#
# ---------------------------------- Network -----------------------------------
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: 0.0.0.0
#
# Set a custom port for HTTP:
#
http.port:
#
# For more information, see the documentation at:
# <http://www.elastic.co/guide/en/elasticsearch/reference/current/modules-network.html>
#
transport.tcp.port:
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when new node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300"]
#
# Prevent the "split brain" by configuring the majority of nodes (total number of nodes / + ):
#
# discovery.zen.minimum_master_nodes:
#
# For more information, see the documentation at:
# <http://www.elastic.co/guide/en/elasticsearch/reference/current/modules-discovery.html>
#
# ---------------------------------- Gateway -----------------------------------
#
# Block initial recovery after a full cluster restart until N nodes are started:
#
# gateway.recover_after_nodes:
#
# For more information, see the documentation at:
# <http://www.elastic.co/guide/en/elasticsearch/reference/current/modules-gateway.html>
#
# ---------------------------------- Various -----------------------------------
#
# Disable starting multiple nodes on a single system:
#
node.max_local_storage_nodes:
#
# Require explicit names when deleting indices:
#
# action.destructive_requires_name: true
3. 由于配置中指定了配置文件和数据的路径了,所以,要在相应的路径下创建所需的目录。
/home/AppData/es/esins1/data
/home/AppData/es/esins1/logs
/home/AppData/es/esins2/data
/home/AppData/es/esins2/logs
4. 启动es, 先启动es实例1. 注意,es启动时指定的配置文件时,要指定配置文件所在的路径,这个路径包含elasticsearch.yml以及logging.yml
[root@CloudGame bin]# ./elasticsearch -d -Des.path.conf=/etc/esconf/esins1 -p /etc/esconf/esins1.pid
[root@CloudGame bin]# Exception in thread "main" java.lang.RuntimeException: don't run elasticsearch as root.
at org.elasticsearch.bootstrap.Bootstrap.initializeNatives(Bootstrap.java:)
at org.elasticsearch.bootstrap.Bootstrap.setup(Bootstrap.java:)
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:)
Refer to the log for complete error details.
哟,错了啊,不能用root启动es,见鬼,再来一次吧。
[water@CloudGame bin]$ ./elasticsearch -d -Des.path.conf=/etc/esconf/esins1 -p /etc/esconf/esins1.pid
[water@CloudGame bin]$ Exception in thread "main" SettingsException[Failed to open stream for url [/etc/esconf/esins1/elasticsearch.yml]]; nested: AccessDeniedException[/etc/esconf/esins1/elasticsearch.yml];
Likely root cause: java.nio.file.AccessDeniedException: /etc/esconf/esins1/elasticsearch.yml
at sun.nio.fs.UnixException.translateToIOException(UnixException.java:)
at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:)
at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:)
at sun.nio.fs.UnixFileSystemProvider.newByteChannel(UnixFileSystemProvider.java:)
at java.nio.file.Files.newByteChannel(Files.java:)
at java.nio.file.Files.newByteChannel(Files.java:)
at java.nio.file.spi.FileSystemProvider.newInputStream(FileSystemProvider.java:)
at java.nio.file.Files.newInputStream(Files.java:)
at org.elasticsearch.common.settings.Settings$Builder.loadFromPath(Settings.java:)
at org.elasticsearch.node.internal.InternalSettingsPreparer.prepareEnvironment(InternalSettingsPreparer.java:)
at org.elasticsearch.bootstrap.Bootstrap.initialSettings(Bootstrap.java:)
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:)
Refer to the log for complete error details.
哟嘿,还是错??? 访问etc/esconf/esins1/elasticsearch.yml被阻止了???想起来了,这个文件是在root用户下创建配置的。修改一下用户组吧: chown -R water:water /etc/esconf/esins1。再来一次。。。
[water@CloudGame bin]$ ./elasticsearch -d -Des.path.conf=/etc/esconf/esins1 -p /etc/esconf/esins1.pid
[water@CloudGame bin]$ Exception in thread "main" SettingsException[Failed to open stream for url [/etc/esconf/esins1/elasticsearch.yml]]; nested: AccessDeniedException[/etc/esconf/esins1/elasticsearch.yml];
Likely root cause: java.nio.file.AccessDeniedException: /etc/esconf/esins1/elasticsearch.yml
at sun.nio.fs.UnixException.translateToIOException(UnixException.java:)
at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:)
at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:)
at sun.nio.fs.UnixFileSystemProvider.newByteChannel(UnixFileSystemProvider.java:)
at java.nio.file.Files.newByteChannel(Files.java:)
at java.nio.file.Files.newByteChannel(Files.java:)
at java.nio.file.spi.FileSystemProvider.newInputStream(FileSystemProvider.java:)
at java.nio.file.Files.newInputStream(Files.java:)
at org.elasticsearch.common.settings.Settings$Builder.loadFromPath(Settings.java:)
at org.elasticsearch.node.internal.InternalSettingsPreparer.prepareEnvironment(InternalSettingsPreparer.java:)
at org.elasticsearch.bootstrap.Bootstrap.initialSettings(Bootstrap.java:)
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:)
Refer to the log for complete error details.
怎么还是一样的错啊,去看看日志吧,靠,/home/AppData/es/esins1/logs下面什么也没有啊???????倒,这个目录也是在root权限下创建的,water没有写的权限。。。。。。再给这数据和日志目录改属组。。。。。
[root@CloudGame es]# ll
total
drwxr-xr-x. root root Oct : esins1
drwxr-xr-x. root root Oct : esins2
[root@CloudGame es]# chown -R water:water *
[root@CloudGame es]# ll
total
drwxr-xr-x. water water Oct : esins1
drwxr-xr-x. water water Oct : esins2
[root@CloudGame es]# cd esins1/
[root@CloudGame esins1]# ll
total
drwxr-xr-x. water water Oct : data
drwxr-xr-x. water water Oct : logs
再来启动一次,应该可以了吧。。。。
[water@CloudGame bin]$ ./elasticsearch -d -Des.path.conf=/etc/esconf/esins1 -p /etc/esconf/esins1.pid
[water@CloudGame bin]$ Exception in thread "main" java.nio.file.AccessDeniedException: /etc/esconf/esins1.pid
at sun.nio.fs.UnixException.translateToIOException(UnixException.java:)
at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:)
at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:)
at sun.nio.fs.UnixFileSystemProvider.newByteChannel(UnixFileSystemProvider.java:)
at java.nio.file.spi.FileSystemProvider.newOutputStream(FileSystemProvider.java:)
at java.nio.file.Files.newOutputStream(Files.java:)
at org.elasticsearch.common.PidFile.create(PidFile.java:)
at org.elasticsearch.common.PidFile.create(PidFile.java:)
at org.elasticsearch.bootstrap.Bootstrap.init(Bootstrap.java:)
at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:)
Refer to the log for complete error details.
去你的,怎么还是权限的问题,来pid文件没有办法写入。。。。。再搞一次权限配置。。。。
[root@CloudGame etc]# chown -R water:water esconf
再启动,再不好,是不是就不玩了。。。。
[water@CloudGame bin]$ ./elasticsearch -d -Des.path.conf=/etc/esconf/esins1 -p /etc/esconf/esins1.pid
[water@CloudGame bin]$
哈哈哈,很好,这次启动不错了,说明八九不离十了。
同样的,参照启动esins1的过程,启动esins2.一切都ok。 esconf下面有两个pid文件
[root@CloudGame esconf]# ll -al
total
drwxr-xr-x. water water Oct : .
drwxr-xr-x. root root Oct : ..
drwxr-xr-x. water water Oct : esins1
-rw-rw-r--. water water Oct : esins1.pid
drwxr-xr-x. water water Oct : esins2
-rw-rw-r--. water water Oct : esins2.pid
到此,单机双实例的启动完成。。。
真的完成了么?要不访问看看,那就验证一下吧,下面来几张截图demo一下最后的结果!
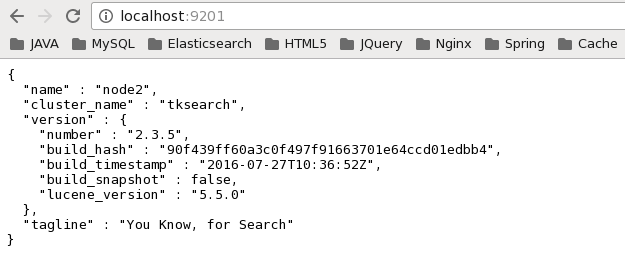
esins1的基本信息:

esins2的基本信息:
esins1的健康状态:

esins2的健康状态:

elasticsearch单机多实例环境部署的更多相关文章
- 分布式搜索ElasticSearch单机与服务器环境搭建
从上方插件官网中下载适合的dist包,然后解压.进入bin目录,可以看到一堆sh脚本.在bin目录下创建一个test.sh: bin=/home/csonezp/Dev/elasticsearch-j ...
- elasticsearch 单机多实例
elasticsearch 配置单机器多实例 host: - - path data: /opt/elasticsearch/data/node1 /opt/elasticsearch/data/no ...
- 单机多实例Tomcat部署
单机单用户基础上, 如何运行多个tomcat实例. 首先是tomcat的目录结构 bin – 包含所有运行tomcat的二进制和脚本文件 lib – 包含tomcat使用的所有共享库 c ...
- 单机多实例mysq 8.0l部署安装
单机多实例mysql部署安装 目的需求 在单台虚拟机部署部署多实例mysql,用于配置mysql replication,MHA等. 思路 多实例安装mysql可以参考<源编译MySQL8.0的 ...
- tomcat单机多实例部署
最近在面试的过程中,一家公司在面试时提到了有关tomcat单机多实例部署的提问, 正好, 之前使用IntelliJ IDEA 13.1.4这款IDE开发web项目,在开发的过程中,因为有多个web项目 ...
- ELK实时日志分析平台环境部署--完整记录
在日常运维工作中,对于系统和业务日志的处理尤为重要.今天,在这里分享一下自己部署的ELK(+Redis)-开源实时日志分析平台的记录过程(仅依据本人的实际操作为例说明,如有误述,敬请指出)~ ==== ...
- ELK实时日志分析平台环境部署--完整记录(转)
在日常运维工作中,对于系统和业务日志的处理尤为重要.今天,在这里分享一下自己部署的ELK(+Redis)-开源实时日志分析平台的记录过程(仅依据本人的实际操作为例说明,如有误述,敬请指出)~ ==== ...
- Tomcat学习总结(10)——Tomcat多实例冗余部署
昨天在跟群友做技术交流的时候,了解到,有很多大公司都是采用了高可用的,分布式的,实例沉余1+台.但是在小公司的同学也很多,他们反映并不是所有公司都有那样的资源来供你调度.往往公司只会给你一台机器,因为 ...
- tomcat单机多实例
catalina.home指向公用信息的位置,就是bin和lib的父目录. catalina.base指向每个Tomcat目录私有信息的位置,就是conf.logs.temp.webapps和work ...
随机推荐
- MySQL限时解答
MySQL在国内各个行业的使用率越来越高,使用场景也越多,相应的遇到的疑惑也越来越多.在遇到这些问题之后,目前已有的解决途径有 1.培训(这是从长计议的方式,不能解决燃眉之急) 2.BBS(目前BBS ...
- 超级迷宫 nabc
特点之一:益智模式 N 我们的游戏需要一点点益智答题使其精彩 A 在走迷宫的过程中,会遇到某一个点,出现一个益智小问题,答对即可通过 B 增加游戏的趣味性,吸引用户 C 答题游戏不少,前不久腾讯的手 ...
- bzoj题解汇总(1052~1061)
bzoj1052: 贪心 bzoj1053: DFS bzoj1054: 加深迭代搜索 bzoj1055:区间判定性dp bzoj1056: Treap bzoj1057: 二分,单调队列 / ST表 ...
- HTML 认识
1.1认识什么是纯文本文件 Window 自带的一个软件,叫做记事本,记事本保存的格式就是TXT,就是英文text的缩写,术语上称呼为"纯文本文件". 注意: TXT文件,只 ...
- Flume使用小结
本文介绍初次使用Flume传输数据到MongoDB的过程,内容涉及环境部署和注意事项. 1 环境搭建 需要jdk.flume-ng.mongodb java driver.flume-ng-mongo ...
- K2 BPM打造企业新门户,步入移动办公时代
公司介绍步步高教育电子有限公司(前身为步步高电脑电玩厂)是广东步步高电子工业有限公司属下的三个分公司之一,一直致力于面向广大学生的教育电子产品的研发与生产,主要产品有视频学习机.点读机.学生电脑.语言 ...
- enmo_day_04
数据库名称 : PROD1 update employees set salary = salary + 1000 where LAST_NAME = ‘Bell’; select LAST_NAME ...
- Ubuntu下Speedtest的安装
要安装Speedtest,需要先安装apache,参见<Ubuntu下Apache的安装>一文:*(再安装LAMP server,参见<Ubuntu下快速安装LAMP server& ...
- SharePoint 2016 Beta 2 使用体验
博客地址:http://blog.csdn.net/FoxDave 上一篇主要描述了安装SharePoint 2016的过程,本篇写一些概览性的东西. 首先打开管理中心(依然是在安装完会有Issue ...
- python3 reqeuests给OSC全站用户刷积分
严格来讲是给在OSC上贡献过内容的OSC用户刷积分. OSC很多操作都需要消耗积分,很多人给OSC贡献了内容, 但是却没有人点赞,所以有些人在OSC混了很多年也没有积分. 本文中使用到的工具有gifc ...