实时数仓入门训练营:基于 Apache Flink + Hologres 的实时推荐系统架构解析
本文整理自直播《基于 Apache Flink + Hologres 的实时推荐系统架构解析-秦江杰》
视频链接:https://c.tb.cn/F3.0d98Xr
摘要:本文由实时数仓线上课程秦江杰老师演讲内容整理。
内容简要:
一、实时推荐系统原理
二、实时推荐系统架构
三、基于 Apache Flink + Hologres 的实时推荐系统关键技术
实时推荐系统原理
(一)静态推荐系统
在介绍实时推荐系统之前,先看一下静态推荐系统是什么样子的。
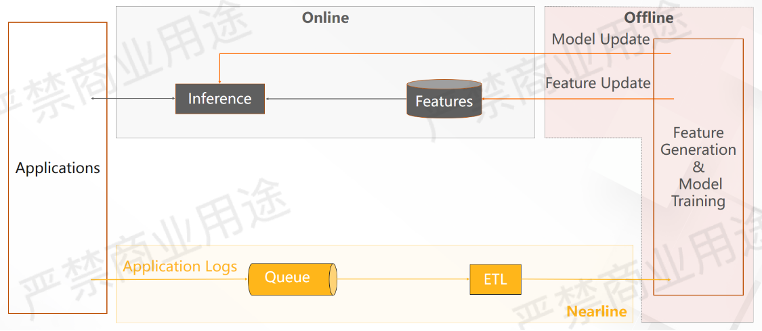

上方是一个非常经典的静态推荐系统的架构图。前端会有很多用户端的应用,这些用户会产生大量用户的行为日志,然后放到一个消息队列里面,进入ETL。接着通过离线系统去做一些特征生成和模型训练,最后把模型和特征推到线上系统中,通过在线的服务就可以去调用在线推理服务去获得推荐结果。
这就是一个非常经典的静态推荐系统运作流程,下面我们举一个具体的例子来看静态推荐系统到底是怎么样工作的。
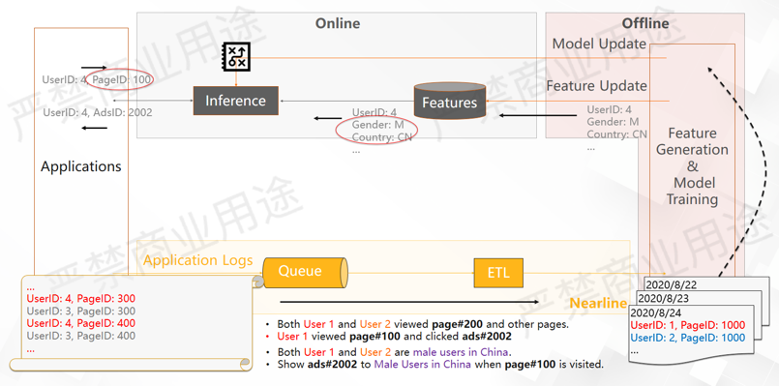
如上图所示,比如在线用户的行为日志可能是一些用户的浏览和广告点击的日志,推荐系统的目的是为了帮用户推荐广告,那么在日志里面可以看到以下用户行为:
用户1和用户2都看了PageID 200和一些其他的页面,然后用户1看了PageID 200并且点了广告2002,那么在用户日志里面通过ETL可以把这样的一系列行为给归纳出来,然后送到模型训练里面去训练模型。在训练模型的过程当中我们会用到一些特征,在这个情况下我们可以发现用户1和用户2都是中国的男性用户,这可能是用户维度的一个特征。
在这种情况下,我们从日志里面看到的结果是用户在看了PageID 100后点了广告2002,并且两个用户都是中国的男性用户。因此,我们的模型就有可能学到当中国的男性用户来看PageID 100的时候,应该要给他展示广告2002,这个行为会被训练到模型里面去。这个时候我们会把一些用户的离线特征都推到特征库,然后把这个模型也推到线上去。
假设这里有一个用户ID4,他正好是中国的男性用户,这个特征就会被推进特征库,那模型也被推到线上。如果用户4来访问的时候看PageID 100,推理服务会先去看用户ID4的特征,然后根据他是一个中国的男性用户,通过训练的模型,系统就会给他推广告2002,这是一个静态推荐系统基本的工作原理。
在这种情况下,如果发生一些变化的时候,我们来看一下静态推荐系统是不是能够继续很好地工作?
假使说今天训练了用户1和用户2的特征模型,到第二天发现用户4产生了行为,根据模型里面的内容,模型会认为用户4是中国的男性用户和用户1、用户2行为一致,所以需要给他推的应该是中国男性用户的行为。但这个时候我们发现用户4的行为其实跟用户3更像,而不是跟用户1和用户2更像。
在这种情况下,由于模型和特征都是静态的,所以为了让用户4能够跟用户3得到的行为更像,需要去重新训练模型,这会导致预测的效果被延迟,因为需要重新训练用户4,才能够推荐出跟用户3更像的一些行为。
所以在这种实际操作情况下,可以看到静态推荐模型存在一些问题:
- 静态生成模型和特征;
以分类模型为例,根据用户的相似性进行用户分类,假设同类用户有相似的兴趣和行为
- 例如中国的男性用户有类似行为。
- 一旦用户被划分为某个类别,则他将一直处于这个类别中,直到被新的模型训练重新分类。
这种情况下,比较难去做到很好的推荐,原因是:
- 用户的行为非常多元化,无法划分到某个固定类别
1)上午为父母采购保健品,中午为出差订酒店,晚上给家人买衣服…
2)静态系统无法准确将用户放到当时当刻正确的类别中。 - 某一类别用户的行为相似,但是行为本身可能会发生变化
1)假设用户“随大流“,但是“大流”可能发生变化;
2)历史数据看出来的“大流”可能无法准确反映线上的真实情况。
(二)加入实时特征工程的推荐系统
为了解决上述问题,可以加入动态特征。那么动态特征是什么样的?举个例子说明。
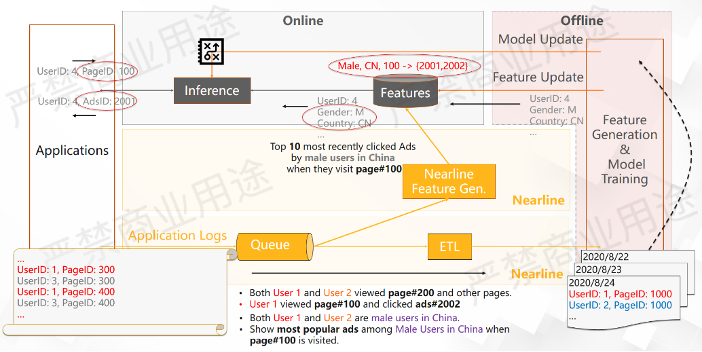
如上图所示,我们以大流发生变化的动态特征举例。之前的模型推荐是如果中国的男性用户访问PageID 100,就给他推荐广告2002,这是一个固定不变的行为。
在此基础上做一些变化,当进行采样实时特征的时候,这个实时特征是最近一段时间内,即当中国的男性用户访问PageID 100的时候,他们点击最多的10个广告。这个特征没有办法在离线的时候计算出来,因为它是一个线上实时发生的用户行为。
那么在产生用户行为之后可以做一件什么事情呢?可以在中国的男性用户访问PageID 100的时候,不单纯给他推广告2002,而是推最近这段时间中国男性用户访问PageID 100时候点击最多的那些广告。
这样的情况下,如果中国男性用户访问PageID 100的时候,最近访问最多的广告是2001和2002。当用户ID来了,我们看到他是一个中国男性用户,就有可能给他推荐广告2001,而不是广告2002了。
上述就是大流发生变化的一个例子。
同样的道理,因为系统可以对用户的实时特征进行采样,所以能更好地判断用户当时当刻的意图。比方说,可以去看用户最近一分钟看了哪些页面,浏览哪些商品,这样的话可以实时判断用户当时当刻的想法,从而给他推荐一个更适合他当下意图的广告。
这样的推荐系统是不是就完全没有问题呢?再看一个例子。
比方说刚才上文提到用户1和用户2都是中国男性用户,之前假设他们的行为是类似的,在之前的历史数据里面也印证了这一点。但是当在线上真正看用户行为的时候,可能会发生什么样的情况?
可能发生用户1和用户2的行为产生分化,分化的原因可能有很多种,但不知道是什么原因。此时给用户1和用户2所推荐的东西可能就完全不一样了,那是什么原因导致分化了?

举个例子来说,如果用户1来自上海,用户2来自北京。某天北京有非常大的降温,这个时候北京用户2可能就开始搜索秋裤,但是上海当天还是很热,上海的用户1在搜索服装的时候,可能还是搜索一些夏装。这个时候,中国的男性用户里面,上海用户1和北京用户2的搜索行为就产生了一些变化。此时就需要给他们推荐不一样的广告,但是静态的模型没有办法很好地做到这一点。
因为这个模型其实是一个静态训练的模型,所以如果是一个分类模型的话,当中能够产生的类别其实是一个固定的类别,为了产生一个新的分类,就需要对模型重新进行训练。由于模型训练是离线进行的,所以可能这个训练的模型需要在第二天才能被更新,这样就会对推荐效果产生影响。
- 通过增加动态 feature
1)实时跟踪一类用户的行为,贴合“大流”;
2)实时追踪用户的行为表现,了解用户当时当刻的意图,并将用户划分到更合适的类别中去。 - 但是当模型的分类方式本身发生变化时,可能无法找到最合适的类别,需要重新训练模型增加分类。
例:新产品上线频繁,业务高速成长,用户行为的分布变化比较快。
当遇到以上问题,需要把考虑的事情加入动态的模型更新,动态模型更新是怎么来做?其实是一样的道理。
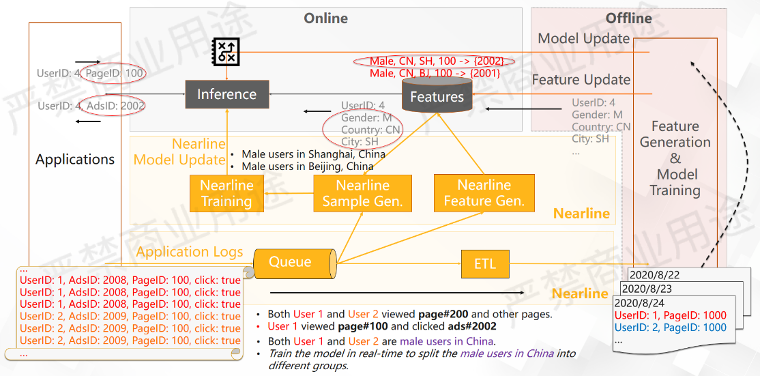
如上图所示,除了把用户的实时行为日志做ETL到离线的地方进行Feature Generation以外,可能还要把用户行为日志在线导出来,然后去做特征生成、样本拼接,然后做进线的模型训练。
这里的模型训练通常都是流式的训练,在一个基础模型之上做增量的训练,来使模型更好地贴合当时当刻用户行为的一些变化。在这种情况下,通过这种实时样本的训练,可以让这个模型产生新的分类,它会知道上海和北京用户的行为可能是不一样的。因此,当用户访问PageID 100的时候,对于上海的用户它可能会推荐广告2002,北京的用户可能推荐的就是广告2011了。
在这样的情况分化下,假设用户4再过来的时候,系统会看他到底是上海的用户还是北京的用户,如果他是上海的用户的话,还是会给他推荐广告2002。
加入实时模型训练的推荐系统特点:
- 在动态特征的基础上,实时训练模型,使模型尽可能贴近此时此刻 用户行为的分布;
- 缓解模型的退化。
实时推荐系统架构
上面的例子是了解实时推荐系统的原理,它为什么会比一般的离线推荐系统做得更好。那么,如何通过Flink加上Hologres和一些其他系统/项目来搭建出这样一套可用的实时推荐系统?
(一)经典离线推荐系统架构
首先来看一下上文提到的经典离线推荐系统的架构,如下所示。
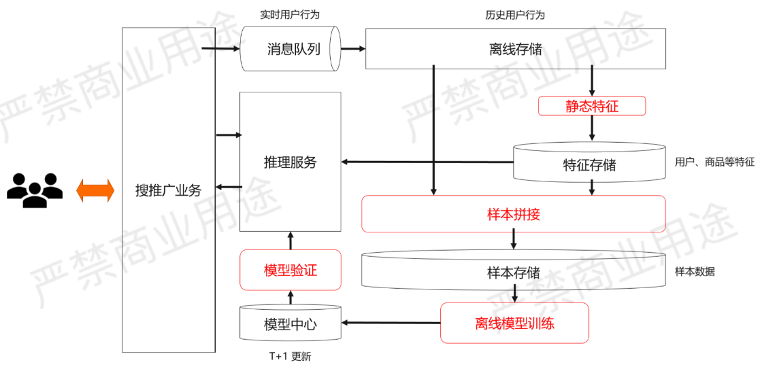
这个架构其实之前讲的架构一样,只是增加了部分细节。
首先,通过消息队列用来采集实时的用户行为,这个消息队列里面的实时用户行为会被导入到一个离线存储来存储历史用户行为,然后每天会做静态特征的计算,最后放到特征存储里面给线上的推理服务用。
与此同时,系统也会做离线的样本拼接,拼接出来的样本会存到样本存储里面给离线的模型训练使用,离线的模型训练每天会产生新的模型去验证,然后给到推理服务使用,这个模型是一个T+1的更新。
以上就是一个经典离线推荐系统的架构。如果要把它推进到实时推荐系统里面,主要要做以下三件事情:
- 特征计算
静态 T+1 特征计算到实时特征计算。 - 样本生成
离线 T+1 样本生成到实时样本生成。 - 模型训练
离线训练 T+1 更新到增量训练实时更新。
(二)阿里巴巴搜推广在线机器学习流程
阿里巴巴搜推广已经上线了这样的实时推荐系统,它的整个流程其实跟离线的推荐系统是类似的,主要区别是整个过程都实时化了。
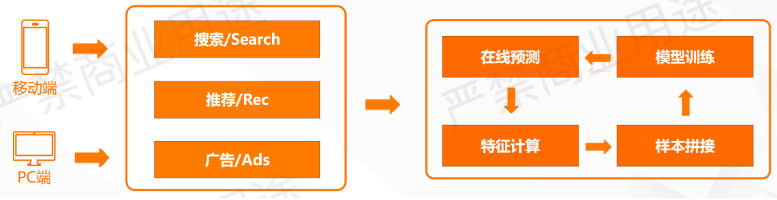
如上所示,这套系统主要有三方面的特性:
时效性:大促期间,全流程实时更新。
灵活性:根据需求,随时调整特征和模型。
可靠性:系统稳定、高可用,上线效果保证。
用户可以做到非常有时效性地更新模型、特征,在大促的期间,可以随时调整特征和模型,表现出来的效果也很好。
(三)实时推荐系统架构
实时推进系统的架构应该长成什么样子?
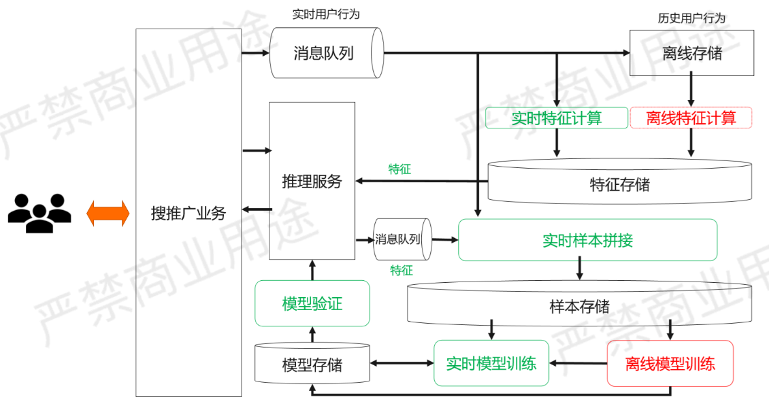
如上图所示,相比于刚才经典的离线推荐系统,实时推荐架构发生了一些变化。首先,消息队列生成的数据,除了进到离线存储保存历史行为以外,系统还会把这个消息队列里面的消息读出来两份,其中一份拿去做实时的特征计算,也是会放到特征存储里面,另外一份是会放到实时样本拼接里面,跟线上的推理服务使用的用户特征进行一个双流Join,这样能够得到一个实时的样本。
在这种情况下,存储到实时系统的样本可以同时被拿来做离线的模型训练,也可以拿来做实时的模型训练。
不管是离线的还是实时的模型训练,它们生成的模型都会被放到模型存储里面,并经过模型验证最后上线。
离线模型训练是天级别的,但实时模型训练可能是分钟级、小时级甚至是秒级的。这个时候离线的模型训练会天级别产生一个Base Model给到实时的模型训练,然后再去做增量的模型更新。
整个的架构里面有一点需要提到的是,推理服务在使用这个特征存储里面拿过来的特征做推理的同时,它还需要把本次做推理所用的特征也加上Request ID送到消息队列里面。这样的话实时样本拼接的时候,当产生一个正样本,比方说用户展示了某一个广告,然后点击了之后它是一个正样本,这时候才能够知道当时用了哪些特征给用户推荐的广告,所以这个特征信息是需要推理服务保留下来,送到实时样本里面做样本拼接,才能生成一个很好的样本。
这个架构里面可以看到,相比于经典的离线推荐系统,在绿色框的部分都是实时的部分,有一些部分是新加的,有一些部分是把原来离线的部分变成了实时的部分。比如实时特征计算是新加的,实时样本拼接是把原来的离线样本拼接的部分变成了实时,实时模型训练是新加的,模型验证也是同样的道理,是把原来的离线模型验证,变成了实时的模型验证。
(四)基于 Flink + Hologres 的实时推荐方案
如果要实现刚才的实时推荐系统架构,会用到一些什么样的系统?
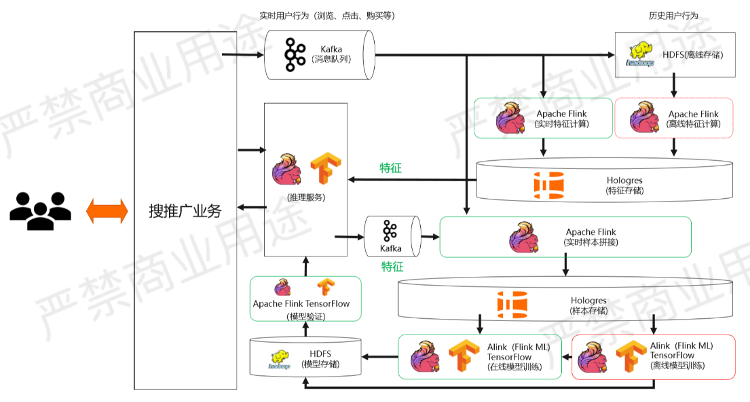
如上图所示,消息队列用的是Kafka,离线的存储假设用的是HDFS。不管是实时特征计算还是离线特征计算,现在都可以用Flink来进行计算,利用Flink流批一体的能力,能够保证实时和离线的特征计算所产生的结果是一致的。
Hologres在这里的作用是特征存储,Hologres特征存储的好处是可以提供非常高效的点查,另一个就是在做实时特征计算的时候,经常会产生一些不准确的特征,需要在后期对这些特征进行一些修正。可以通过Flink加Hologres的机制进行很好的特征的修正。
同样的道理,在推理服务这一侧,通过保留用来做推理的特征,放到后面的样本拼接里面,这里的消息队列也会使用Kafka。样本拼接这个事情会用Flink来做,Flink一个非常经典的应用场景做双流Join。把样本给拼接出来后,在把特征给加上,接着把算好的样本同样也放进Hologres里面做样本的存储。
在样本存储的情况下,Hologres里面的样本既可以拿来做实时的模型训练,通过读取Hologres的Binlog来做实时的模型训练,也可以通过Hologres批量的Scan去做离线的模型训练。
不管是在线还是离线的模型训练,都可以用Flink或者是FlinkML,也就是Alink来做。如果是传统机器学习的话,也可以用TensorFlow来做深度学习的模型训练,这样的模型还是可能会存到HDFS,然后通过Flink和TensorFlow做模型的验证,最后做线上的推理服务。
线上推理服务很多用户会有自己的推理引擎,如果有可以用,如果想用Flink和TensorFlow的话也可以直接使用。
(五)实时特征计算及推理 (Flink + Hologres)
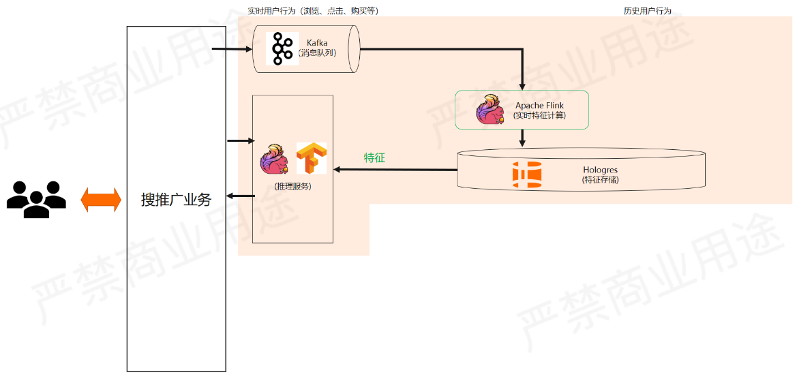
首先我们来看实时特征计算和推理的过程,如上图所示。
刚才提到我们会把实时的用户行为采集下来,送到Flink里面去做实时特征计算,然后存进Hologres里面给线上推理服务使用。
这里的实时特征可能包含:
- 用户最近 5 分钟的浏览记录
1)商品、文章、视频
2)停留时长
3)收藏、加购、咨询,评论 - 最近 10 分钟每个品类中点击率最高的 50 个商品
- 最近 30 分钟浏览量最高的文章、视频、商品
- 最近 30 分钟搜索量最高的 100 个词
对于搜推广业务,都可以用这样的实时特征来更好的获得推荐效果。
(六)实时样本拼接(Flink + Hologres)
再往下我们会看实时样本拼接的部分,如下图所示。
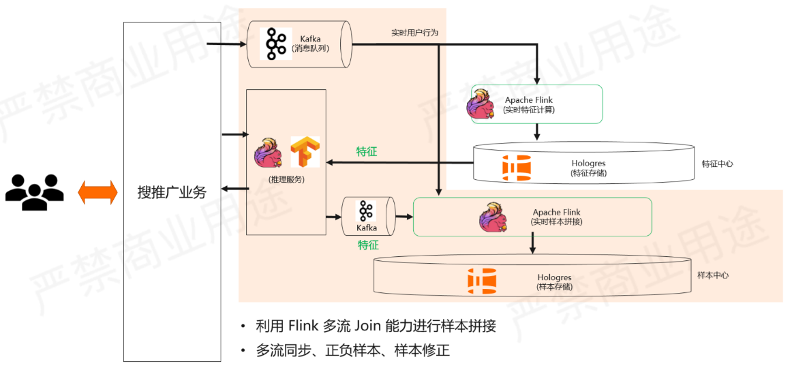
实时用户行为会被采集下来,进到Flink里面去做样本的拼接。这里的样本拼接包含了两个部分,第一个部分是首先要知道这个样本是正样本还是负样本,这是通过分析实时用户行为的日志来的,我们会有展示流、点击流,如果展示流Join点击流,然后发现展示的一个Item被用户点击了,那么这就是正样本。如果我们展示了某个Item用户没有点击,那么就是一个负样本,这就是我们判断正负样本的过程。
仅仅有正负样本的判断显然不够,因为在做训练的时候还需要这个特征,这些特征是从推理服务过来的,当展示某一个Item的时候,推理服务就使用了某一些特征来判断用户是否会对这个东西感兴趣。这些特征会放到Kafka里面留存下来,进到Flink里面。做样本拼接的过程当中,会通过Request ID Join上当时去做推荐的所用到这些特征,然后生成一个完整的样本放到Hologres里面。
这里会利用 Flink 多流 Join 能力进行样本拼接,与此同时也会做多流同步、正负样本、样本修正。
(七)实时模型训练 / 深度学习 ( PAI-Alink / Tensorflow)
在样本生成了以后,下一个步骤就是实时的模型训练或者深度学习。

如上图所示,在这种情况下,刚才说到样本是存在Hologres里面的,Hologres里面的样本可以用作两个用途,既可以用做在线的模型训练,也可以用做离线的模型训练。
在线的模型训练和离线的模型训练可以分别利用Hologres的Binlog和批量Scan的功能去做。从性能上来讲,其实跟一般的消息队列或者文件系统去扫描相差并不大。
这里如果是深度模型的话,可以用TensorFlow来做训练。如果是传统机器学习模型的话,我们可以用Alink或者说FlinkML来做训练,然后进到HDFS存储,把模型给存储起来,接着再通过Flink或者TensorFlow来做模型的验证。
上述过程是实际搭建实时模型和深度模型训练可以用到的一些技术。
(八)Alink–Flink ML(基于Flink的机器学习算法)
这里简单的介绍一下Alink,Alink是基于Flink的一个机器学习算法库,目前已经开源,正在向 Apache Flink 社区进行贡献中。
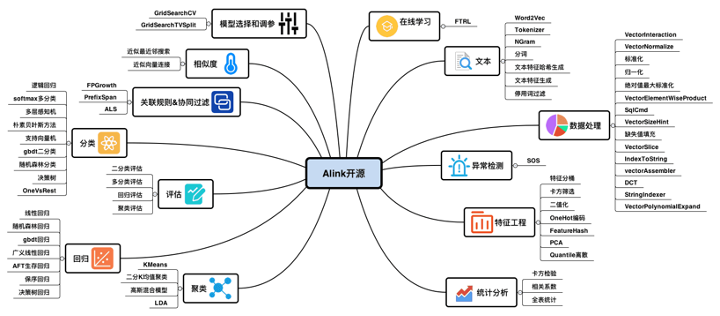
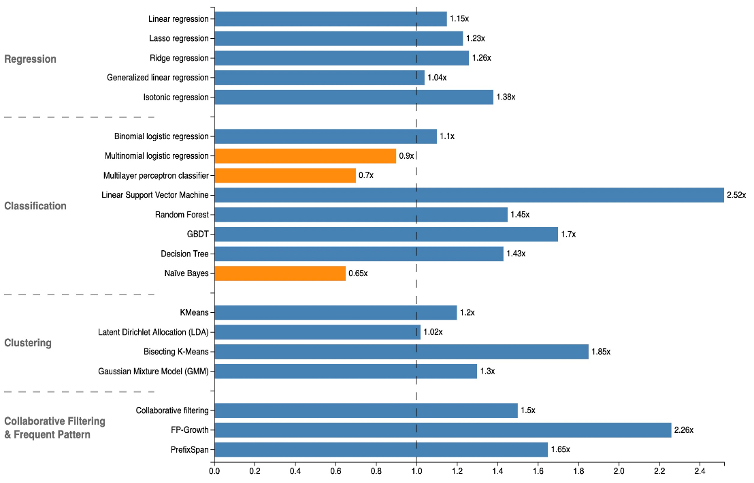
如上图所示,Alink (Flink ML)相比于Spark ML来讲有两个特色:
- Spark ML 仅提供批式算法,Alink 提供批流一体算法;
- Alink 在批式算法上和 Spark ML 相当。
(九)离线特征回填 (Backfill)
介绍完训练部分,再来看离线特征回填。这个过程其实是说在上线实时特征以后,需要上线新的特征,应该怎么做?
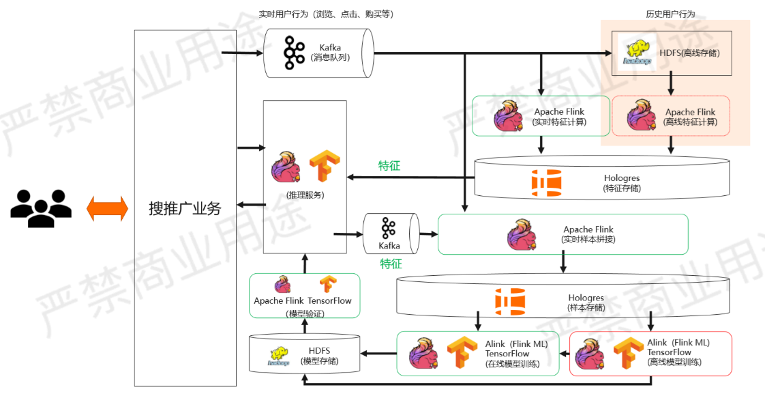
如上图所示,一般会分成两步。第一步会在实时的系统里面先把新的特征给加上,那么从某一个时刻开始,Hologres里面存储生成的特征都是有新的特征了。对于那些历史数据怎么办?这个时候就需要重新做一个特征回填,用HDFS里面存的历史行为数据跑一个批量的任务,然后把历史上的一些特征给补上。
所以离线特征回填在这个架构图里面也是由Flink的离线特征计算来完成的,从HDFS里面把历史行为数据读出来,然后去算一些离线的特征,把过去的历史消息里面的特征给补上。
基于Apache Flink + Hologres的实时推荐系统关键技术
刚才的架构里面所用到的关键技术比较多,接下来主要讲两个点。
(一)可撤回订正的特征和样本
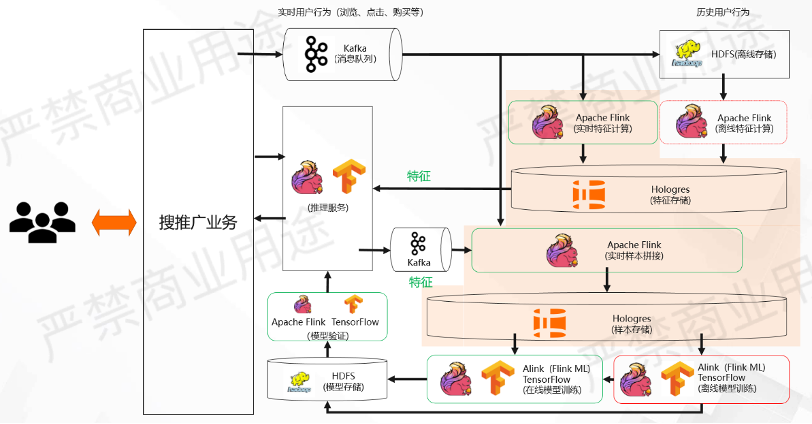
第一个点是可撤回订正的特征和样本,如上图所示。
图中有下部阴影的区域里面,通过Flink和Hologres配合,会进行一些样本和特征的撤回和订正。
为什么需要特征和样本的订正?
- 实时日志存在乱序
例如某个用户点击事件由于系统延迟晚到产生 False Negative 样本。 - 一般通过离线作业重新计算离线样本
重新跑整个离线样本计算 - 通过 Apache Flink + Hologres 撤回机制点更新
仅更新需要更正的特征和样本
实时日志有可能会存在一些乱序,有些流可能到得早一些,有些流可能到得晚一些。在这种情况下,在做多流Join的时候就有可能会由于系统的延迟、晚到而产生一些False Negative样本。
举个例子,比如在做展示和点击流Join的时候,可能一开始认为用户并没有点击某一个广告,后来发现用户点击了,但是这条事件到的时间晚了。在这种情况中,一开始会告诉下游用户没有点击,这是一个False Negative,后面发现用户其实点击了,因此需要对 False Negative做修正。当发生这种情况,需要对之前的样本做撤回或者更新,去告诉它之前的样本不是负样本,而是正样本。
基于上述这种情况,我们需要整套链路上面有一个撤回的能力,需要逐级告诉下游之前的错误,需要把它给修正,通过Apache Flink + Hologres配合可以完成这样一个机制。
为什么要做这样一件事情?
以前产生这种False Negative样本的时候,一般都是通过离线作业重新计算离线样本进行更正。这种方式的代价是可能需要重新跑整个离线的样本计算,但最终目的其实仅仅是修正所有样本里其中很小的一部分样本,因此这个代价是比较高昂的。
通过Apache Flink + Hologres实现的机制,可以做到对False Negative样本进行点状的更新,而不是重新跑整个样本,这种情况下,更正特征和样本的代价就会小很多。
(二)基于事件的流批混合工作流
在这个架构里另一个关键技术是基于事件的流批混合工作流,它是什么意思?
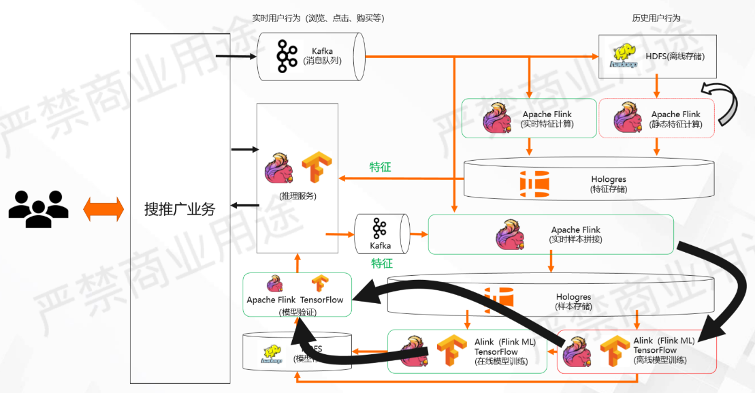
看这个图,除了刚才所示那些系统之外,这也是一个非常复杂的工作流。因为不同的系统之间,它可能存在依赖关系和调度关系,有的时候是数据依赖,有的时候是控制依赖。
例如,我们可能会周期性或者定期去跑一些离线的静态特征计算,有可能是做特征回填,也有可能是更正实时特征产生的问题,但可能是默认周期性地跑,也有可能是手动触发地跑。还有的时候是当离线模型训练生成之后,需要去触发在线模型验证的动作,也有可能是在线的模型训练生成以后要去触发在线模型训练的动作。
还有可能是样本拼接到了某一个点,比如上午10点样本拼接完成之后,想要告诉模型训练说,上午10点之前的样本都拼接好了,希望想跑一个批量离线训练的任务,把昨天早上10点到今天早上10点的数据做离线的模型训练。这里它是由一个流任务触发一个批任务的过程。在刚才提到的批量模型训练生成之后,需要放到线上做模型验证的过程当中,它其实是一个批任务触发流任务的过程,也会线上模型训练产生的模型,需要去线上模型训练进行验证,这是流任务触发流任务的过程。
所以在这个过程当中,会涉及到很多不同任务之间的交互,这里叫做一个比较复杂的工作流,它既有批的任务又有流的任务,所以它是一个流批混合的工作流。
(三)Flink AI Flow
如何做到流批混合的工作流实现?
使用的是Flink AI Flow,它是一个大数据加AI顶层工作流抽象。
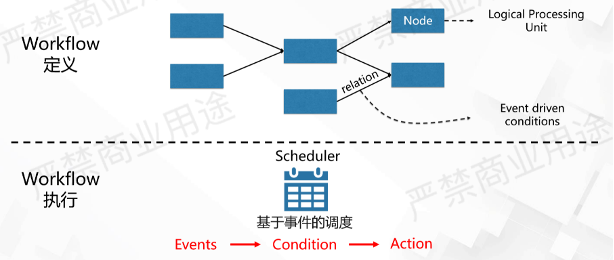
如上图所示,一个工作流通常可以分为Workflow定义和Workflow执行这两个步骤。
Workflow定义会定义Node和Relation,即定义节点和节点之间的关系。在Flink AI Flow里面,我们把一个节点定义成一个Logical Processing Unit,然后把这个节点之间的关系定义成Event driven conditions。在这样的抽象下面,在Workflow执行层面做了一个基于事件的调度。
抽象严格来,在一个系统里面会有很多的事件,把这些事件组合到一起,可能会满足某一些条件,当满足一个条件的时候,会产生一些动作。
例如,一个工作流中可能有一个任务A,它可能会监听这个系统里面各种各样的事件。当事件1发生,然后发生了事件2,接着发生了事件3,当事件按照这么一个序列发生之后,需要做启动任务A的动作,事件123按序发生是条件。
通过这样的抽象,可以很好地把以前传统工作流和带有流作业的工作流整合起来。因为以前传统的工作流里都是基于作业状态发生变化进行调度,一般是作业跑完了,然后去看怎么跑下一个作业。这个方式的问题是如果作业是一个流作业,那么这个作业永远跑不完,这个工作流无法正常工作。
在基于事件的调度里面,很好地解决了这个问题。将不再依赖作业的状态发生变化来进行工作流调度,而是基于事件来做。这样的话即使是一个流作业,它也可以产生一些事件,然后告诉调度器做一些其他的事情。
为了完成整个调度语义,还需要一些支持服务,协助完成整个调度语义的支持服务包括:
- 元数据服务(Metadata Service)
- 通知服务(Notification Service)
- 模型中心(Model Center)
下面来分别看一下这些支持服务的内容。
(四)元数据服务/Metadata Service

元数据服务是管理数据集,在工作流里面希望用户不用非常繁琐地找到自己的数据集,可以帮用户管理数据集,用户要用的时候给一个名字就可以。
元数据服务也会管理项目(Project),这里的Project是指Flink AI Flow里面的Project,一个Project里面可以含有多个工作流,管理Project最主要的目的是为了保证工作流能够被复现。
在元数据服务里面,还会管理工作流和作业,每个工作流里面可能会涉及到很多的作业。除此之外,也会管理模型血缘,可以知道模型的版本是由哪一个工作流当中的哪一个作业生成的,最后也支持用户定义一些自定义实体。
(五)通知服务/Notification Service
第二个服务是通知服务,它是一个带主键的事件和事件监听。

举个例子,如上图所示。一个客户端希望监听一个事件,这个事件的Key是模型。如果 Key被更新的时候,监听的用户就会收到一个call back,会告诉他有一个事件被更新了,那个事件的主键是模型,Value是模型的URI,版本号是1。
这里能够起到的一个作用就是如果验证一个作业,它可以去监听Notification Service。当有一个新模型生成的时候,需要被通知然后对这个模型进行验证,所以通过Notification Service就可以做这样的事情。
(六)模型中心/Model Center
模型中心做的是模型多版本的管理,参数的记录,包括模型指标的追踪和模型生命周期的管理,还有一些模型可视化的工作。

举个例子阐述Flink AI Flow是如何把实时推荐系统里面复杂的工作流,用一个完整的工作流描述出来。
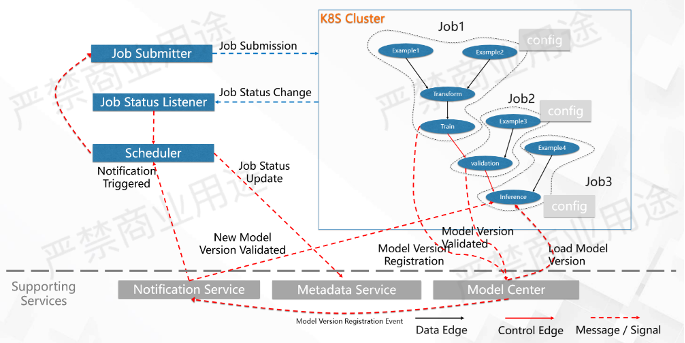
如上所示,假如有一个DAG,它里面包含了模型的训练,模型的验证以及在线推理这三个作业。
首先,通过Scheduler模型训练的作业,在提交上去之后,Scheduler会到Metadata Service里面去更新作业的状态,变成一个待提交的状态。假设环境是K8S Cluster,那么它会提交到Kubernetes上去跑这样一个训练作业。
训练作业跑起来之后,可以通过作业状态监听器去更新作业的状态。假使这个作业是一个流式的训练作业,跑了一段时间以后会生成一个模型,这个模型会注册到模型中心。注册完了以后,模型中心会发出一个事件,表示有一个新的模型版本被注册了,这个事件会到Scheduler, Scheduler会监听这些事件。
之后Scheduler就会去看,当收到这个事件的时候,有没有一些条件被满足了,然后需要做一些什么样的动作。有一个模型生成的时候,Scheduler需要去对这个模型进行验证,这个条件被满足以后,需要去拉起一个作业,这个作业就是一个模型验证的作业。
模型验证作业被拉起之后,它会到模型中心找到最新被生成的一个模型版本,然后对它去进行模型的验证。假设模型验证通过了,这个模型验证是个批作业,它会告诉Model Center模型被Validated了,这个时候模型中心就会发送一条Model Validated Version Event给Scheduler,模型被更新了以后,Scheduler会去看Model Validated,触发拉起线上的推理服务。推理服务拉起之后,它会到模型中心里面把刚刚被Validated过的模型拉过来做推理。
假设推理服务也是一个流的作业,也是一直跑在那里。过了一段时间之后,线上的流的训练作业又生成了一个新的模型,刚才那条路又会再走一遍,它会有一个模型生成的一个New Model Version Validated,它又会被Scheduler听到,Scheduler又拉起一个Validated作业,Job2又会被拉起,拉起之后Validated作业又会去验证模型,有可能这个模型验证又通过了,又会发送一条模型New Model Version Validated给模型中心,模型中心会把这个Event又给到 Scheduler。这个时候,Scheduler会看到推理作业其实已经起在那里了,可能就什么都不做。
推理作业同时也在监听着Model Version Validated事件,当它收到这个事件的时候,会去做的一件事情就是到模型中心里面重新加载最新的被Validated过的事件。
通过这个例子,解释了为什么需要流批混合的调度器和工作流,来实现端到端的实时推荐系统架构里所有作业、工作流的串联。
本文为阿里云原创内容,未经允许不得转载。
实时数仓入门训练营:基于 Apache Flink + Hologres 的实时推荐系统架构解析的更多相关文章
- flink实时数仓从入门到实战
第一章.flink实时数仓入门 一.依赖 <!--Licensed to the Apache Software Foundation (ASF) under oneor more contri ...
- 基于 Kafka 的实时数仓在搜索的实践应用
一.概述 Apache Kafka 发展至今,已经是一个很成熟的消息队列组件了,也是大数据生态圈中不可或缺的一员.Apache Kafka 社区非常的活跃,通过社区成员不断的贡献代码和迭代项目,使得 ...
- (转)用Flink取代Spark Streaming!知乎实时数仓架构演进
转:https://mp.weixin.qq.com/s/e8lsGyl8oVtfg6HhXyIe4A AI 前线导读:“数据智能” (Data Intelligence) 有一个必须且基础的环节,就 ...
- 基于 Flink 的实时数仓生产实践
数据仓库的建设是“数据智能”必不可少的一环,也是大规模数据应用中必然面临的挑战.在智能商业中,数据的结果代表了用户反馈.获取数据的及时性尤为重要.快速获取数据反馈能够帮助公司更快地做出决策,更好地进行 ...
- 美团点评基于 Flink 的实时数仓建设实践
https://mp.weixin.qq.com/s?__biz=MjM5NjQ5MTI5OA==&mid=2651749037&idx=1&sn=4a448647b3dae5 ...
- 基于Flink构建全场景实时数仓
目录: 一. 实时计算初期 二. 实时数仓建设 三. Lambda架构的实时数仓 四. Kappa架构的实时数仓 五. 流批结合的实时数仓 实时计算初期 虽然实时计算在最近几年才火起来,但是在早期也有 ...
- 基于 ByteHouse 构建实时数仓实践
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 随着数据的应用场景越来越丰富,企业对数据价值反馈到业务中的时效性要求也越来越高,很早就有人提出过一个概念: 数据的 ...
- 大数据之Hudi + Kylin的准实时数仓实现
问题导读:1.数据库.数据仓库如何理解?2.数据湖有什么用途?解决什么问题?3.数据仓库的加载链路如何实现?4.Hudi新一代数据湖项目有什么优势? 在近期的 Apache Kylin × Apach ...
- 实时数仓(二):DWD层-数据处理
目录 实时数仓(二):DWD层-数据处理 1.数据源 2.用户行为日志 2.1开发环境搭建 1)包结构 2)pom.xml 3)MykafkaUtil.java 4)log4j.properties ...
- Clickhouse实时数仓建设
1.概述 Clickhouse是一个开源的列式存储数据库,其主要场景用于在线分析处理查询(OLAP),能够使用SQL查询实时生成分析数据报告.今天,笔者就为大家介绍如何使用Clickhouse来构建实 ...
随机推荐
- 大年学习linux(第五节---目录结构)
五.目录结构 可以用ls / 查看linux的目录结构 bin data etc lib media opt root sbin sys usr boot dev home lib64 mnt pro ...
- 浅析三维模型3DTile格式轻量化处理常见问题与处理措施
浅析三维模型3DTile格式轻量化处理常见问题与处理措施 三维模型3DTile格式的轻量化处理是大规模三维地理空间数据可视化的关键环节,但在实际操作过程中,往往会遇到一些问题.下面我们来看一下这些常见 ...
- 记录--微信小程序获取用户信息的最新方法记录
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 微信小程序获取用户信息的几种方式 以下三种方式都无法获取到用户的openID 1. 开放组件获取用户信息<open-data> ...
- KingbaseES V8R6 运维案例之---数据库连接访问故障分析
KingbaseES V8R6运维案例之---数据库连接访问故障分析 案例说明: 在部署KingbaseES V8R6后,正常启动数据库服务,但是通过ksql连接数据库服务访问时,出现连接到postg ...
- https://codeforces.com/gym/496962
A略. B最大最小即为答案. C略. DE记录 t 的每个字母 在 s 中出现的最左和最右,特判端点. FG先贪心后反悔 or 背包. *H:不会.AC自动机.
- 学习Source Generators之输出生成的文件
上一篇文章学习了通过获取和解析swagger.json的内容,来生成API的请求响应类. 但是其中无法移动与编辑. 那么本文将介绍如何输出生成的文件. EmitCompilerGeneratedFil ...
- .NET Emit 入门教程:第六部分:IL 指令:3:详解 ILGenerator 指令方法:参数加载指令
前言: 在上一篇中,我们介绍了 ILGenerator 辅助方法. 本篇,将详细介绍指令方法,并详细介绍指令的相关用法. 在接下来的教程,关于IL指令部分,会将指令分为以下几个分类进行讲解: 1.参数 ...
- #随机#CF1198F GCD Groups 2
题目 将 \(n\) 个数分为两组,使得两组的GCD都为1,求具体的分组情况 分析 考虑直接打乱 \(n\) 个数,如果能使第一组GCD减小就减小,否则丢到第二组, 由于打乱后出错的概率会减小,所以r ...
- Arm架构下麒麟操作系统安装配置Mariadb数据库
1.安装配置JDK (1)检查机器是否已安装JDK 执行 java -version命令查看机器是否安装JDK,一般麒麟操作系统默认安装openjdk 1.8. (2)安装指定版本JDK 如果麒麟操作 ...
- ES6中模块化详解
前言 因为ES6中的模块化是将来,所以就必须有必要好好的了解一下,学习一下,这篇文章就简单总结一下ES6中模块的概念,语法和用法.纯属个人总结,不喜勿喷. 下面我将通过a.js.b.js和c.js三个 ...