使用多层RNN-LSTM网络实现MNIST数据集分类及常见坑汇总
1 前言
循环神经网络(Recurrent Neural Network, RNN)又称递归神经网络,出现于20世纪80年代,其雏形见于美国物理学家J.J.Hopfield于1982年提出的可作联想存储器的互联网络——Hopfield神经网络模型。RNN是一类专门用于处理和预测序列数据的神经网络,其网络结构如下:
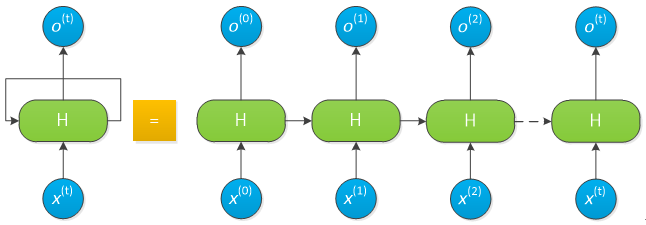 RNN网络结构
RNN网络结构
Sepp Hochreiter教授和Jurgen Schmidhuber教授于1997年提出了长短时记忆网络(Long Short-Term Memory,LSTM),解决了长期依赖问题,主要应用于文本分类、语音识别、机器翻译、自动对话、图片生成标题等问题中。LSTM网络结构如下所示:
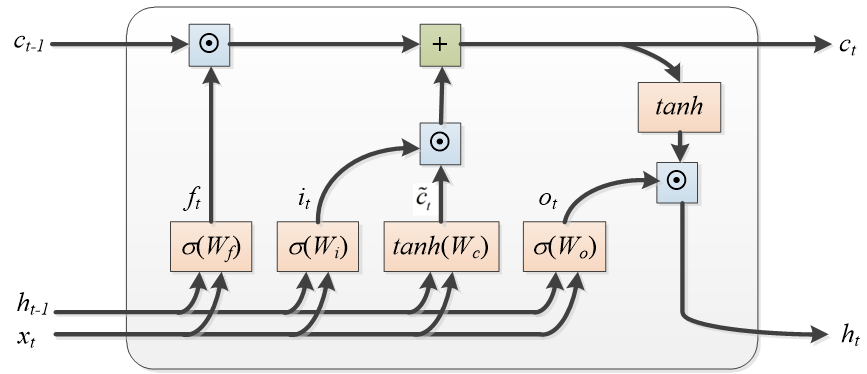 LSTM网络结构
LSTM网络结构
本博客仍采用MNIST数据集做实验,关于MNIST数据集的说明及其配置,见使用TensorFlow实现MNIST数据集分类
RNN采用一行一行地读取图片数据,即每个时刻读取图片一行的28个像素,一共有28个时间序列(28行),最后一个时刻输出汇总了前面所有时刻的信息,因此只用最后一个时刻的输出来判断图片类别。数据转换如下:
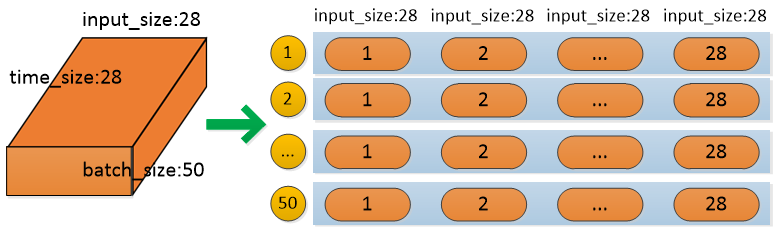 数据转换格式
数据转换格式
2 单层RNN-LSTM网络
数据流如下:
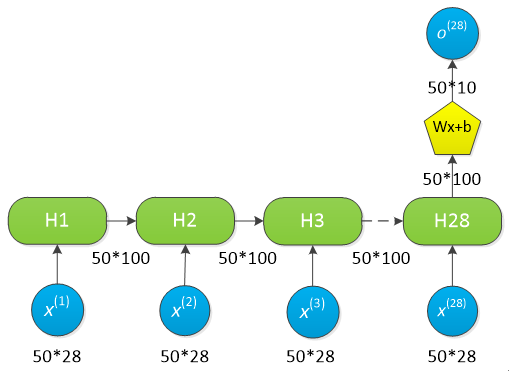 单层RNN-LSTM数据流示意图
单层RNN-LSTM数据流示意图
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
#载入数据集
mnist = input_data.read_data_sets("MNIST_data/",one_hot=True)
#lstm细胞输入向量维度,即每个时刻输入一行,共28个像素
input_size = 28
#时序持续长度,28个时刻,即每做一次预测,需要输入28行
time_size = 28
#每个隐藏层节点数
hidden_size = 100
#10个分类
class_num = 10
#每批次50个样本
batch_size = 50
#计算一共有多少个训练批次
batch_num = mnist.train.num_examples // batch_size
x = tf.placeholder(tf.float32,[None,784])
y = tf.placeholder(tf.float32,[None,10])
weights=tf.Variable(tf.truncated_normal([hidden_size,class_num],stddev=0.1))
biases=tf.Variable(tf.constant(0.1,shape=[class_num,]))
#定义RNN-LSTM网络
def RNN_LSTM(x,weights,biases):
#[batch_size,time_size*input_size]==>[batch_size,time_size,input_size]
inputs=tf.reshape(x,[-1,time_size,input_size])
#定义LSTM基本单元lstm_cell
lstm_cell = tf.contrib.rnn.BasicLSTMCell(num_units=hidden_size,forget_bias=1.0,state_is_tuple=True)
outputs,state = tf.nn.dynamic_rnn(lstm_cell,inputs,dtype=tf.float32,time_major=False)
#输出隐层变换
results = tf.matmul(outputs[:,-1,:],weights)+biases
return results
y_=RNN_LSTM(x,weights,biases)
#交叉熵损失函数
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=y_,labels=y))
#使用AdamOptimizer优化器进行优化
train = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
#初始化
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
test_feed={x:mnist.test.images,y:mnist.test.labels}
for epoch in range(6):
#训练
for batch in range(batch_num):
batch_x,batch_y=mnist.train.next_batch(batch_size)
sess.run(train,feed_dict={x:batch_x,y:batch_y})
#预测
acc=sess.run(accuracy,feed_dict=test_feed)
print("Iter "+str(epoch)+", Testing Accuracy =",acc)
 单层RNN-LSTM运行结果
单层RNN-LSTM运行结果
3 多层RNN-LSTM网络
数据流如下:
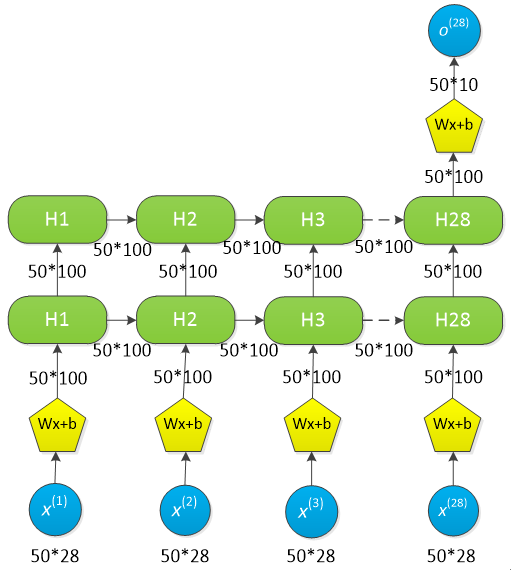 多层RNN-LSTM数据流示意图
多层RNN-LSTM数据流示意图
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
#载入数据集
mnist = input_data.read_data_sets("MNIST_data/",one_hot=True)
#lstm细胞输入向量维度,即每个时刻输入一行,共28个像素
input_size = 28
#时序持续长度,28个时刻,即每做一次预测,需要输入28行
time_size = 28
#每个隐藏层节点数
hidden_size = 100
#LSTM layer的层数
layer_num = 2
#10个分类
class_num = 10
#每批次50个样本
batch_size = 50
#计算一共有多少个训练批次
batch_num = mnist.train.num_examples // batch_size
x = tf.placeholder(tf.float32,[None,784])
y = tf.placeholder(tf.float32,[None,10])
weights={'in':tf.Variable(tf.truncated_normal([input_size,hidden_size],stddev=0.1)),
'out':tf.Variable(tf.truncated_normal([hidden_size,class_num]))}
biases={'in':tf.Variable(tf.constant(0.1,shape=[hidden_size,])),
'out':tf.Variable(tf.constant(0.1,shape=[class_num,]))}
#定义RNN-LSTM网络
def RNN_LSTM(x,weights,biases):
#[batch_size,time_size*input_size]==>[batch_size*time_size,input_size]
x=tf.reshape(x,[-1,input_size])
#输入隐层变换
inputs=tf.matmul(x,weights["in"])+biases["in"]
#[batch_size*time_size,hidden_size]==>[batch_size,time_size,hidden_size]
inputs=tf.reshape(inputs,[-1,time_size,hidden_size])
#定义LSTM基本单元lstm_cell
lstm_cell = tf.contrib.rnn.BasicLSTMCell(num_units=hidden_size,forget_bias=1.0,state_is_tuple=True)
#堆叠多层LSTM单元
mlstm_cell = tf.contrib.rnn.MultiRNNCell([lstm_cell]*layer_num,state_is_tuple=True)
outputs,state = tf.nn.dynamic_rnn(mlstm_cell,inputs,dtype=tf.float32,time_major=False)
#输出隐层变换
results = tf.matmul(outputs[:,-1,:],weights["out"])+biases["out"]
return results
y_=RNN_LSTM(x,weights,biases)
#交叉熵损失函数
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=y_,labels=y))
#使用AdamOptimizer优化器进行优化
train = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
#初始化
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
test_feed={x:mnist.test.images,y:mnist.test.labels}
for epoch in range(6):
#训练
for batch in range(batch_num):
batch_x,batch_y=mnist.train.next_batch(batch_size)
sess.run(train,feed_dict={x:batch_x,y:batch_y})
#预测
acc=sess.run(accuracy,feed_dict=test_feed)
print("Iter "+str(epoch)+", Testing Accuracy =",acc)
 多层RNN-LSTM运行结果
多层RNN-LSTM运行结果
4 常见错误汇总
单层RNN-LSTM网络一般不会犯错,这里主要介绍多层RNN-LSTM网络中的常见错误。
4.1 输入隐层没有进行维数变换
错误提示:
ValueError: Dimensions must be equal, but are 200 and 128 for 'rnn/while/rnn/multi_rnn_cell/cell_0/
basic_lstm_cell/MatMul_1' (op: 'MatMul') with input shapes: [?,200], [128,400].
在LSTM内部有遗忘门、输入门、输出门,每个时刻权值和偏值共享。如果不对输入隐层进行维数变换,第一层的输入向量为28+100=128维,第二层的输入向量为100+100=200维。所以,在输入前需要将28维的向量映射到100维,这样两层的输入都是200维。
4.2 训练batch_size和预测batch_size不一致
很多博客和视频将如下代码
outputs,state = tf.nn.dynamic_rnn(mlstm_cell,inputs,dtype=tf.float32,time_major=False)
写为:
#用全零来初始化state
init_state = mlstm_cell.zero_state(batch_size,dtype=tf.float32)
outputs,state=tf.nn.dynamic_rnn(mlstm_cell,inputs,initial_state=init_state,time_major=False)
它将batch_size与RNN-LSTM绑定在一起了,然而训练时的batch_size和预测时的batch_size不一致(巨坑),导致出现如下报错提示:
InvalidArgumentError: ConcatOp : Dimensions of inputs should match: shape[0] = [10000,100] vs. shape[1] = [50,100]
[[node rnn/while/rnn/multi_rnn_cell/cell_0/basic_lstm_cell/concat (defined at G:/Anaconda/Spyder/lstm.py:44) ]]
这里的10000是指预测数据集的batch_size。在不删除init_state的情况下,有如下两种解决方案:
(1)将测试集的batch_size和训练集的batch_size保持一致
#预测
total_acc=0.0
for batch in range(test_batch_num):
batch_x,batch_y=mnist.test.next_batch(batch_size)
total_acc+=sess.run(accuracy,feed_dict={x:batch_x,y:batch_y})
acc=total_acc/test_batch_num
print("Iter "+str(epoch)+", Testing Accuracy =",acc)
(2)使用placeholder定义batch_size
.................
#每个训练批次50个样本
train_batch_size = 50
#计算一共有多少个训练批次
batch_num = mnist.train.num_examples//train_batch_size
batch_size = tf.placeholder(tf.int32,[])
.................
with tf.Session() as sess:
sess.run(init)
test_feed={x:mnist.test.images,y:mnist.test.labels,batch_size:mnist.test.num_examples}
for epoch in range(6):
#训练
for batch in range(batch_num):
batch_x,batch_y=mnist.train.next_batch(train_batch_size)
sess.run(train,feed_dict={x:batch_x,y:batch_y,batch_size:train_batch_size})
#预测
acc=sess.run(accuracy,feed_dict=test_feed)
print("Iter "+str(epoch)+", Testing Accuracy =",acc)
5 参考文献
tensorflow使用多层RNN(lstm)预测手写数字实现部分细节及踩坑总结
LSTM的训练和测试长度(batch_size)不一样报错的解决方案
声明:本文转自使用多层RNN-LSTM网络实现MNIST数据集分类及常见坑汇总
使用多层RNN-LSTM网络实现MNIST数据集分类及常见坑汇总的更多相关文章
- 6.keras-基于CNN网络的Mnist数据集分类
keras-基于CNN网络的Mnist数据集分类 1.数据的载入和预处理 import numpy as np from keras.datasets import mnist from keras. ...
- 3.keras-简单实现Mnist数据集分类
keras-简单实现Mnist数据集分类 1.载入数据以及预处理 import numpy as np from keras.datasets import mnist from keras.util ...
- 机器学习与Tensorflow(3)—— 机器学习及MNIST数据集分类优化
一.二次代价函数 1. 形式: 其中,C为代价函数,X表示样本,Y表示实际值,a表示输出值,n为样本总数 2. 利用梯度下降法调整权值参数大小,推导过程如下图所示: 根据结果可得,权重w和偏置b的梯度 ...
- 【TensorFlow/简单网络】MNIST数据集-softmax、全连接神经网络,卷积神经网络模型
初学tensorflow,参考了以下几篇博客: soft模型 tensorflow构建全连接神经网络 tensorflow构建卷积神经网络 tensorflow构建卷积神经网络 tensorflow构 ...
- 深度学习(一)之MNIST数据集分类
任务目标 对MNIST手写数字数据集进行训练和评估,最终使得模型能够在测试集上达到\(98\%\)的正确率.(最终本文达到了\(99.36\%\)) 使用的库的版本: python:3.8.12 py ...
- 81、Tensorflow实现LeNet-5模型,多层卷积层,识别mnist数据集
''' Created on 2017年4月22日 @author: weizhen ''' import os import tensorflow as tf import numpy as np ...
- MNIST数据集分类简单版本
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data #载入数据集 mnist = ...
- 神经网络MNIST数据集分类tensorboard
今天分享同样数据集的CNN处理方式,同时加上tensorboard,可以看到清晰的结构图,迭代1000次acc收敛到0.992 先放代码,注释比较详细,变量名字看单词就能知道啥意思 import te ...
- 6.MNIST数据集分类简单版本
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data # 载入数据集 mnist = i ...
- Tensorflow学习教程------普通神经网络对mnist数据集分类
首先是不含隐层的神经网络, 输入层是784个神经元 输出层是10个神经元 代码如下 #coding:utf-8 import tensorflow as tf from tensorflow.exam ...
随机推荐
- Vue - 父子级的相互调用
父级调用子级 父级: <script> this.$refs.child.load(); 或 this.$refs.one.load(); </script> 子级: < ...
- Mygin实现简单的路由
本文是Mygin第二篇 目的: 实现路由映射 提供了用户注册静态路由方法(GET.POST方法) 基于上一篇 Mygin 实现简单Http 且参照Gin 我使用了map数组实现简单路由的映射关系 不同 ...
- [转帖]jmeter编写测试脚本大全
目录 一.背景 二.按照功能划分 2.1 加密处理.验签处理 2.2 jmeter 使用beanshell 编写脚本 2.3 jmeter脚本报错大全 2.4 jmeter打印log 2.5 jmet ...
- 【转帖】eBay 云计算“网”事:网络超时篇
https://www.infoq.cn/article/JmCbkA0XX9NqrcX6loIo eBay技术荟 2020-06-19 本文字数:5508 字 阅读完需:约 18 分钟 导读 eBa ...
- [转帖]【JVM】G1垃圾收集器的关键技术
前言 G1 GC,全称Garbage-First Garbage Collector,通过-XX:+UseG1GC参数来启用,作为体验版随着JDK 6u14版本面世,在JDK 7u4版本发行时被正式推 ...
- 截止2021年linux发行版
- [转贴]Kubernetes之修改NodePort对外映射端口范围
https://www.cnblogs.com/minseo/p/12606326.html k8s默认使用NodePort对外映射端口范围是30000-50000可以通过修改kube-apiserv ...
- VScode中下载了插件但是无法找到SSH Target连接服务器的解决方法(CANNOT find SSH Target in remote explorer)
VSCode版本vscode version:(version 1.82) 已下载扩展installed extensions: Remote - SSH v0.106.4 Remote - SSH: ...
- docker上部署启动RabbitMQ
在docker上部署启动RabbitMQ及使用 一.docker上部署启动RabbitMQ 1.查询rabbitmq镜像 docker search rabbitmq:management 2.拉取r ...
- 在Unity中使用SQLite保存配置表数据(For Lua)
在Lua中使用sqlite Lua版本Sqlite文档:http://lua.sqlite.org/index.cgi/doc/tip/doc/lsqlite3.wiki sqlite官网:https ...