集成学习与随机森林(二)Bagging与Pasting
Bagging 与Pasting
我们之前提到过,其中一个获取一组不同分类器的方法是使用完全不同的训练算法。另一个方法是为每个预测器使用同样的训练算法,但是在训练集的不同的随机子集上进行训练。在数据抽样时,如果是从数据中重复抽样(有放回),这种方法就叫bagging(bootstrap aggregating 的简称,引导聚合)。当抽样是数据不放回采样时,这个称为pasting。
换句话说,bagging与pasting都允许训练数据条目被多个预测器多次采样,但是仅有bagging允许训练数据条目被同一个预测器多次采样。在pasting中,每个预测器仅能对同一条训练数据条目采样一次。Bagging的采样与训练的过程如下图所示:
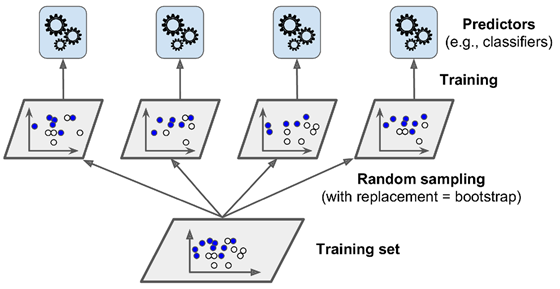
在所有预测器都训练好后,集成器可以对一条新数据做预测,它会简单地聚集所有预测器的预测值。这个聚集方法通常在分类问题中是一个统计模型(也就是说,使用出现最频繁的预测,与投票分类器中的硬投票类似),而在回归问题中是一个平均值。每个单独预测器的bias(偏差值)相对于他们在原始训练集上训练的bias会更高,不过集成会同时减少bias与variance(方差)。一般来说,集成的结果与单个模型,两者的bias值较为接近,但是集成的variance会更低。
在上图中我们也可以看到,模型可以并行进行训练,使用不同的CPU核或是不同的服务器。类似的,预测也可以并行完成。这也是为什么当今bagging与pasting如此令人受欢迎的原因之一:它们的扩展性非常好。
Sk-learn中的Bagging与Pasting
Sk-learn提供了一个简单的API用于bagging与pasting,BaggingClassifier类(或BaggingRegressor类做回归任务)。下面的代码训练一个由500棵决策树组成的集成:每个均在100条随机采样的训练数据条目上进行训练,且数据采样有放回(也就是bagging的例子,如果要用pasting,指定bootstrap=False即可)。n_jobs 参数指定sk-learn在训练与预测时使用的CPU核数(-1表示使用所有可用资源):
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier bag_clf = BaggingClassifier(
DecisionTreeClassifier(), n_estimators=500,
max_samples=100, bootstrap=True, n_jobs=-1) bag_clf.fit(X_train, y_train)
y_pred = bag_clf.predict(X_test)
在BaggingClassifier中,如果基于的基本分类器是可以估计类别概率的话(例如它包含predict_proba() 方法),则BaggingClassifier 会自动执行软投票(soft voting),而不是硬投票。在上面的例子中,基本分类器是决策树,所以它执行的是软投票。
下图对比了单个决策树的决策边界与bagging集成500棵树(上面的代码)的决策边界,两者均在moon数据集上进行训练。我们可以看到,集成预测的泛化性能会更好:集成与单个决策树的bias差不多,但是集成的variance更小。
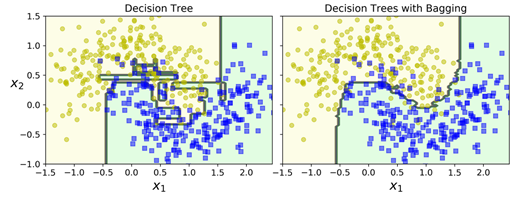
Bootstraping在每个模型使用的训练子集中引入了更多的多样性,所以bagging最终的bias会稍高于pasting一些;但是额外的多样性也意味着最终模型之间的相关性会更小,所以集成的variance会减少。总之,bagging一般相对于pasting会产生更好的模型,这也是为什么我们一般倾向于使用bagging。不够如果有足够的时间和CPU的话,我们可以使用交叉验证来评估bagging与pasting的性能,并选择其中表现最好的那个。
Out-of-Bag评估
使用bagging时,有些数据条目可能会被任一模型采样多次,而其他数据条目可能从来都不会被采样。默认情况下,BaggingClassifier会以有放回(bootstrap=True)的方式采样m条训练数据,这里m为训练集的大小。也就是说,对每个模型来说,平均大约仅有63%的训练数据条目会被采样到。剩下大约37% 的(没有被采样的)训练数据条目称为out-of-bag(oob)实例。
由于模型在训练中并不会看到oob实例,所以可以使用这些实例对模型进行评估,而不需要使用额外的验证集。我们可以通过取每个模型的oob评估的平均,作为集成的评估。
在sk-learn 中,我们在创建BagginClassifier时可以设置 oob_score=True,这样可以在训练结束后
启用一个自动的oob评估。下面的代码是展示的这个例子,评估结果分数可以通过oob_score_变量获取:
bag_clf = BaggingClassifier(
DecisionTreeClassifier(), n_estimators=500,
bootstrap=True, n_jobs=-1, oob_score=True
) bag_clf.fit(X_train, y_train)
bag_clf.oob_score_
>0.8986666666666666
根据oob的评估结果,这个BaggingClassfier可能会在测试集上达到89.8%的准确率,下面我们验证一下:
from sklearn.metrics import accuracy_score y_pred = bag_clf.predict(X_test)
accuracy_score(y_test, y_pred)
>0.904
在测试集上的准确度为90.4%,结果比较接近。
对每条训练集的oob决策函数也可以通过oob_decision_funcsion_ 变量获取。在上面的这个例子中(由于base estimator 有 predict_proba() 方法),决策函数会对每条训练数据返回它属于某个类别的概率。例如,oob 评估第一条训练数据有58.6%的概率属于正类,41.4%的概率属于负类。
bag_clf.oob_decision_function_
>array([[0.41361257, 0.58638743],
[0.37016575, 0.62983425],
[1. , 0. ],
[0. , 1. ],
…
集成学习与随机森林(二)Bagging与Pasting的更多相关文章
- 大白话5分钟带你走进人工智能-第二十九节集成学习之随机森林随机方式 ,out of bag data及代码(2)
大白话5分钟带你走进人工智能-第二十九节集成学习之随机森林随机方式 ,out of bag data及代码(2) 上一节中我们讲解了随机森林的基本概念,本节的话我们讲解随机森 ...
- bagging与boosting集成学习、随机森林
主要内容: 一.bagging.boosting集成学习 二.随机森林 一.bagging.boosting集成学习 1.bagging: 从原始样本集中独立地进行k轮抽取,生成训练集.每轮从原始样本 ...
- 第七章——集成学习和随机森林(Ensemble Learning and Random Forests)
俗话说,三个臭皮匠顶个诸葛亮.类似的,如果集成一系列分类器的预测结果,也将会得到由于单个预测期的预测结果.一组预测期称为一个集合(ensemble),因此这一技术被称为集成学习(Ensemble Le ...
- 机器学习之——集成算法,随机森林,Bootsing,Adaboost,Staking,GBDT,XGboost
集成学习 集成算法 随机森林(前身是bagging或者随机抽样)(并行算法) 提升算法(Boosting算法) GBDT(迭代决策树) (串行算法) Adaboost (串行算法) Stacking ...
- 2. 集成学习(Ensemble Learning)Bagging
1. 集成学习(Ensemble Learning)原理 2. 集成学习(Ensemble Learning)Bagging 3. 集成学习(Ensemble Learning)随机森林(Random ...
- 集成学习算法汇总----Boosting和Bagging(推荐AAA)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- 机器学习:集成学习(OOB 和 关于 Bagging 的更多讨论)
一.oob(Out - of - Bag) 定义:放回取样导致一部分样本很有可能没有取到,这部分样本平均大约有 37% ,把这部分没有取到的样本称为 oob 数据集: 根据这种情况,不对数据集进行 t ...
- 集成学习算法总结----Boosting和Bagging
1.集成学习概述 1.1 集成学习概述 集成学习在机器学习算法中具有较高的准去率,不足之处就是模型的训练过程可能比较复杂,效率不是很高.目前接触较多的集成学习主要有2种:基于Boosting的和基于B ...
- 集成学习算法总结----Boosting和Bagging(转)
1.集成学习概述 1.1 集成学习概述 集成学习在机器学习算法中具有较高的准去率,不足之处就是模型的训练过程可能比较复杂,效率不是很高.目前接触较多的集成学习主要有2种:基于Boosting的和基于B ...
- 【机器学习实战】第7章 集成方法(随机森林和 AdaBoost)
第7章 集成方法 ensemble method 集成方法: ensemble method(元算法: meta algorithm) 概述 概念:是对其他算法进行组合的一种形式. 通俗来说: 当做重 ...
随机推荐
- Mac Docker 挂载数据卷失败
问题描述: docker: Error response from daemon: Mounts denied: The path /srv/docker/bind is not shared fro ...
- postgresql 主键id配序列
一.手动创建序列 1.表格id字段,设置主键(PRIMARY KEY),类型为int4 2.创建序列 CREATE SEQUENCE public.moni_wzhour_warn_id_seq IN ...
- Linux(一):Linux操作系统
Linux(一):Linux操作系统 对于我们编程人员来讲,linux对于我们几乎已经是像windows对于普通用户一样,好像和同行交流说不会linux就像说不会用计算机一样羞耻.这里打算从头开始温故 ...
- 移动端termux安装kali
1.相关准备一部安卓手机,termux,NVAC,浏览器2.安装kali首先进入kali的官网选择文档找到Android手机上的kali找到NetHunter-Rootless找到kali安装命令:t ...
- C语言(较深入原理):%s通过字符串首元素地址输出,用指针数组来作示例
首先,我们输出一个字符串都知道是用%s来输出,但是我们并没有多想是通过什么方式来输出的. 今天我在看指针数组的时候发现了一个问题,按就是定义一个字符类型的指针数组, /*字符串的输出本身就需要他的地址 ...
- PageOffice在线打开编辑Word文件获取指定区域的数据并且保存整篇文件
一.首先在word文件中给需要在后台获取数据的区域设置以PO_开头的书签. 二.通过pageoffice在线打开文件并编辑保存.有两种打开文件的模式 1.普通编辑模式(docNormalEdit) 普 ...
- beego go mod 模式下无法生成注解路由的问题 解决方法
执行 go get github.com/beego/bee 命令时将bee 命令一定要安装在gopath目录下.有idea或者goland编辑器是最方便的,只需要复制这条命令,然后进入编辑器会提示你 ...
- 机器学习策略篇:详解可避免偏差(Avoidable bias)
可避免偏差 如果希望学习算法能在训练集上表现良好,但有时实际上并不想做得太好.得知道人类水平的表现是怎样的,可以确切告诉算法在训练集上的表现到底应该有多好,或者有多不好,让我说明是什么意思吧. 经常使 ...
- linux开机出现initramfs无法进入系统
linux开机出现initramfs无法进入系统 开机后进入initramfs模式,无法进入系统时不要慌: 想一想自己根分区的文件系统名是什么,有的人的是/dev/sda1,有的人的是/dev/sda ...
- H5图片预览
官方链接下载示例项目需要注册账号,似乎有点不友好,不想注册账号的可以去gitee上下载示例项目 如果你上来就是把previewImg.js 放在head中可能会出现意想不到的错误,比如下面这样子,遇到 ...