OpenTelemetry 实践指南:历史、架构与基本概念
背景
之前陆续写过一些和 OpenTelemetry 相关的文章:
- 实战:如何优雅的从 Skywalking 切换到 OpenTelemetry
- 实战:如何编写一个 OpenTelemetry Extensions
- 从一个 JDK21+OpenTelemetry 不兼容的问题讲起
这些内容的前提是最好有一些 OpenTelemetry 的背景知识,看起来就不会那么枯燥,为此这篇文章就来做一个入门科普,方便一些对 OpenTelemetry 不是那么熟的朋友快速掌握一些 OpenTelemetry 的基本概念。
历史发展
早在 OpenTelemetry 诞生之前可观测性这个概念就一直存在了,我记得我最早接触到这个概念是在 16 年当时的公司所使用的一个产品:pinpoint
现如今这个项目依然比较活跃。
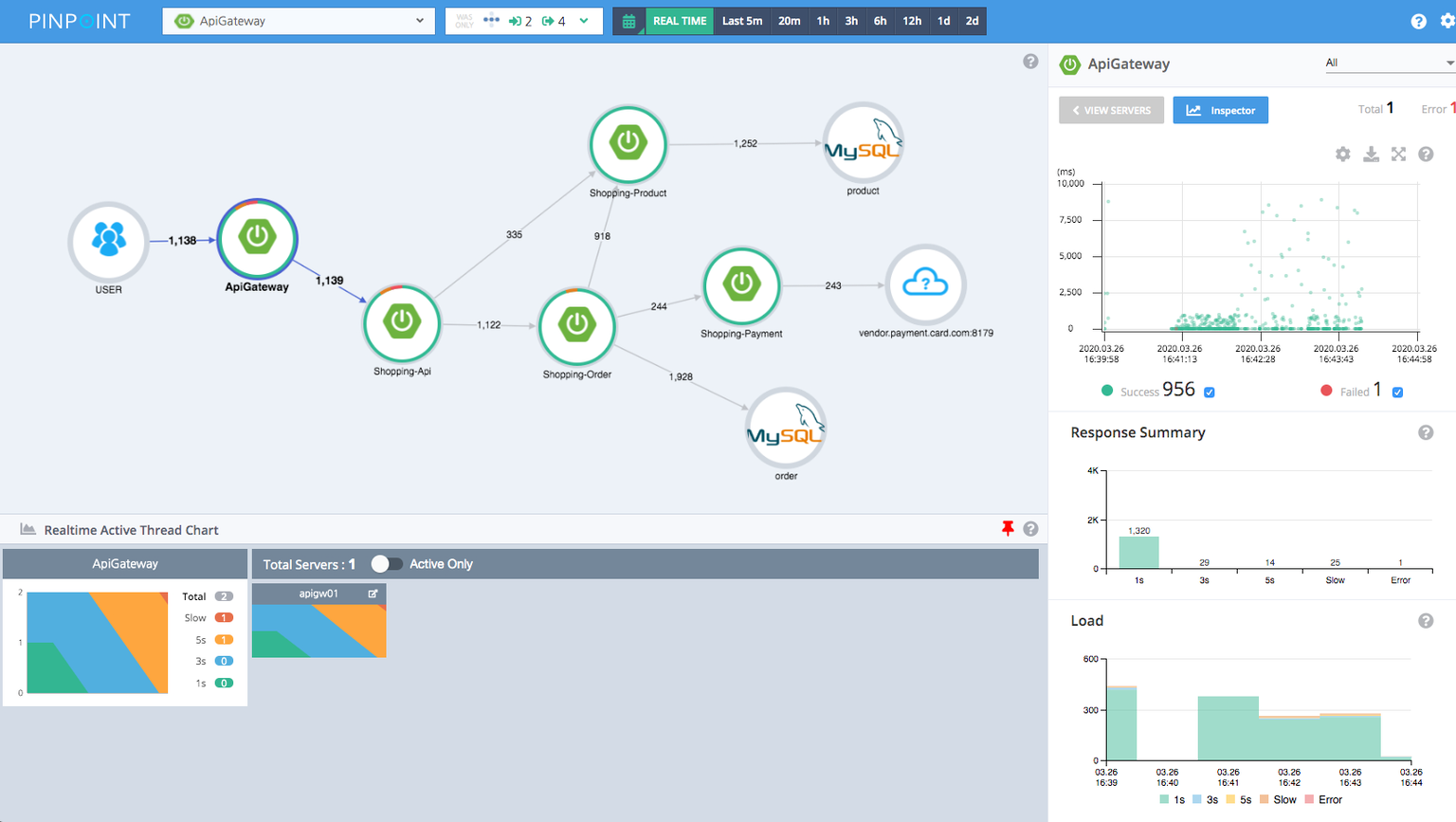
依然还记得当时通过它可以直接看到项目调用的拓扑图,在时间坐标上框出高延迟的点就能列出这些请求,同时还能查看此时的运行日志。
这样强大的功能对于一个刚工作一年的小白来说冲击力实属太大了一点。
后来才了解到 pinpoint 属于 APM 这类产品,类似的产品还有:
- Apache SkyWalking
- 美团的 CAT 等
他们都是可以用于性能分析和链路追踪的产品,到后来公司的运维层面也接入过 Zabbix、open-falcon 之类的产品:
17之后全面切换到 spring boot 时,也用过社区提供的 spring-boot-admin 项目:
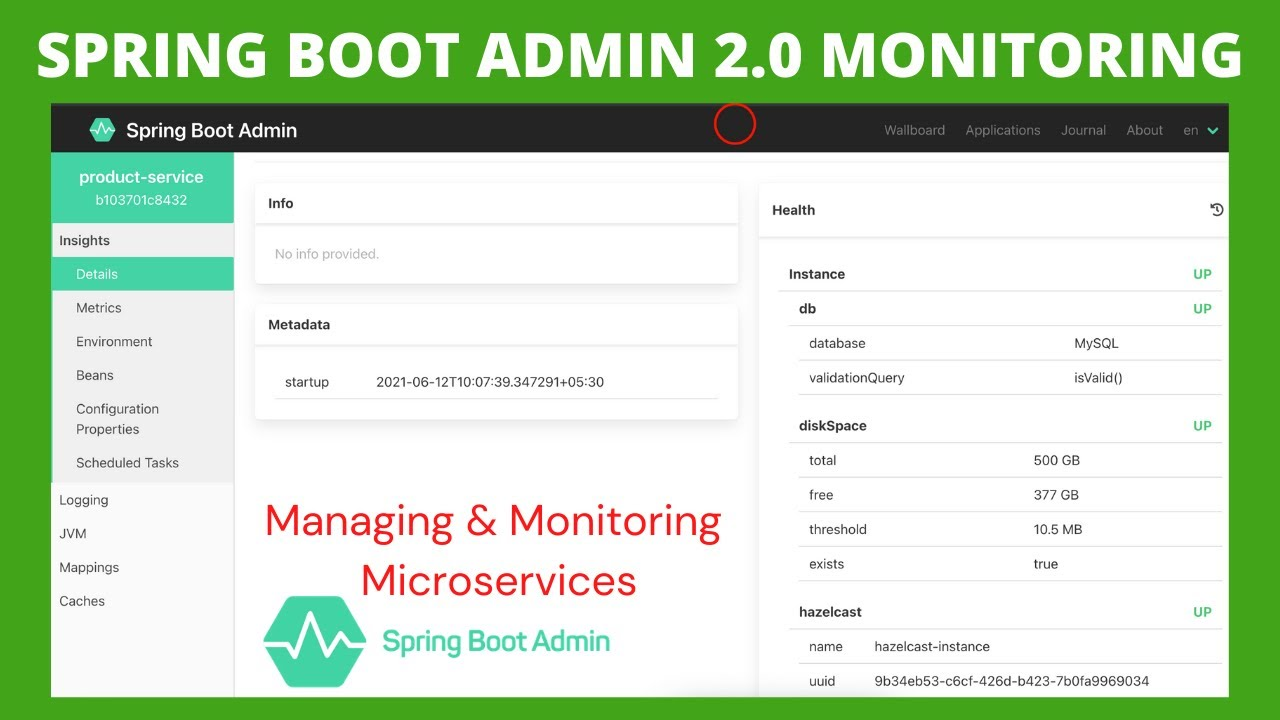
这就是一个简单的可以监控 spring boot 应用的产品,用于展示 JVM 指标,或者自己也可以定义一些健康指标。
再之后进入云原生体系后可观测性的技术栈稍有变化。
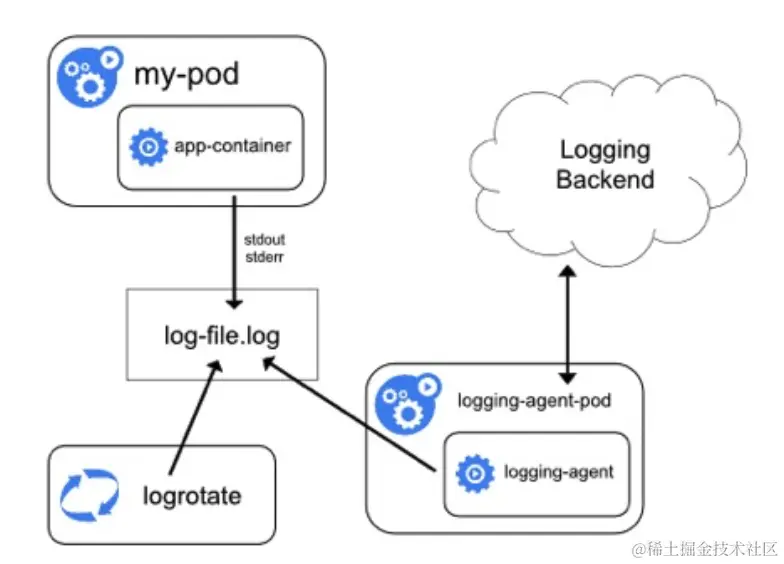
日志使用 Sidecar 代理的方式通过 Agent 将数据写入 ElasticSearch 中。
具体日志采集方式可以参考之前的文章:
而链路追踪则是使用的 skywalking,在 trace 这个领域 skywalking 还是非常受大家喜爱的。
不过最近也从 skywalking 切换到了我们本文所讲到的 OpenTelemetry,具体可以看之前的文章:
指标采集使用的是自然也是 Prometheus 的那一套技术栈,只是 Prometheus 换为了与它完全兼容的 VictoriaMetric 目前是为了更省资源。
客户端使用则是直接使用 Prometheus 的库进行指标暴露:
<dependency>
<groupId>io.prometheus</groupId>
<artifactId>prometheus-metrics-core</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>io.prometheus</groupId>
<artifactId>prometheus-metrics-instrumentation-jvm</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>io.prometheus</groupId>
<artifactId>prometheus-metrics-exporter-httpserver</artifactId>
<version>1.0.0</version>
</dependency>
最终通过配置抓取策略,由 VictoriaMetrics 的 scrape 程序来抓取指标最终写入到它自己的存储中:
apiVersion: operator.victoriametrics.com/v1beta1
kind: VMPodScrape
metadata:
name: kubernetes-pod-scrape
namespace: monitoring
spec:
podMetricsEndpoints:
- scheme: http
scrape_interval: "30s"
path: /metrics
relabelConfigs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
separator: ;
regex: "true"
replacement: $1
action: keep
# 端口相同
- action: keep_if_equal
source_labels: [ __meta_kubernetes_pod_annotation_prometheus_io_port, __meta_kubernetes_pod_container_port_number ]
# 过滤INIT容器
- action: drop
source_labels: [ __meta_kubernetes_pod_container_init ]
regex: "true"
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
separator: ;
regex: (.+)
target_label: __metrics_path__
replacement: $1
action: replace
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
separator: ;
regex: ([^:]+)(?::\d+)?;(\d+)
target_label: __address__
replacement: $1:$2
action: replace
- separator: ;
regex: __meta_kubernetes_pod_label_(.+)
replacement: $1
action: labelmap
- source_labels: [__meta_kubernetes_namespace]
separator: ;
regex: (.*)
target_label: kubernetes_namespace
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_pod_name]
separator: ;
regex: (.*)
target_label: kubernetes_pod_name
replacement: $1
action: replace
vm_scrape_params:
stream_parse: true
namespaceSelector:
any: true
以上是 VM 提供的 CRD
OpenTelemetry 诞生
到此铺垫完成,不知道有没有发现在可观测性中关键的三个部分:日志、指标、trace 都是使用不同的开源产品,从而会导致技术栈较多,维护起来自然也是比较麻烦的。
这么一个软件领域的核心能力自然需要提供一个完整方案的,将以上的不同技术栈都整合在一起,更加的方便开发者使用。
在这之前也有两个社区想要做类似的事情:
- OpenTracing
- OpenCensus
不过他们并没有统一整个可观测领域,直到 2019 年 CNCF 社区宣布成立 OpenTelemetry,并且将上述两个社区进行合并共同开发 OpenTelemetry。
背靠 CNCF 云原生社区加上许多知名厂商的支持(Google、Amazon、Redhat 等),现在已经正式成为 CNCF 的顶级项目了。
OpenTelemetry 架构介绍
但我们打开 OpenTelemetry 社区的 GitHub 首页时,会看到有许多项目;第一反应应该是比较蒙的,下面我会着重介绍一些比较重要的项目。
在开始之前还是先简单介绍下 OpenTelemetry 的一些基础组件和概念:
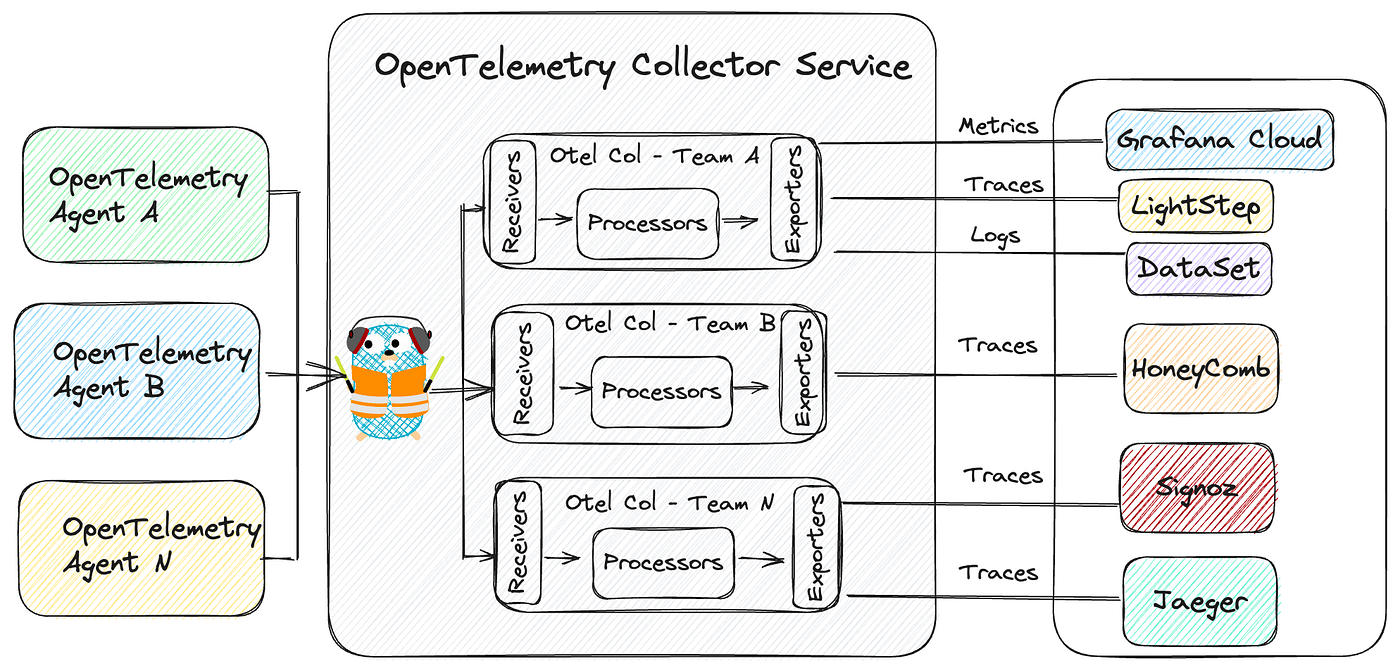
整个 OpenTelemetry 系统其实可以简单分为三个部分:
- 客户端
- OTel collector
- 数据存储
第一个客户端很好理解,也就是我们的业务应用;如果是 Java 应用只需要挂载一个 agent 就可以自动采集系统的指标、链路信息、日志等上传到 Collector 中。
也就是上图的左边部分。
之后就是非常关键的组件 collector,它可以通过 OTLP 协议接收刚才提到的客户端上传的数据,然后再内部进行处理,最终输出到后续的存储系统中。
Collector
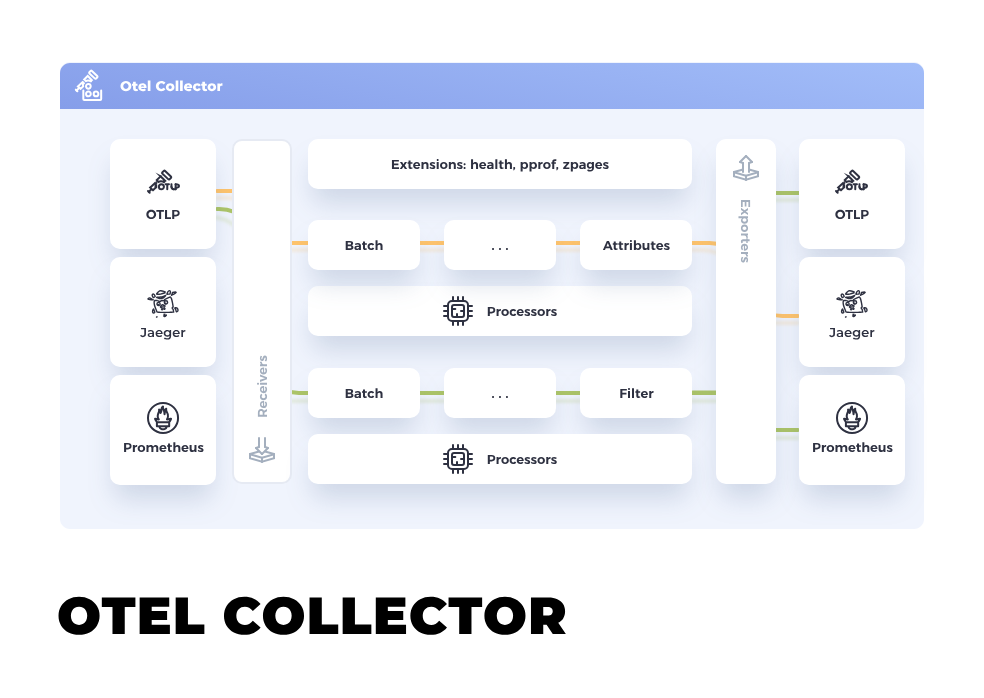
上图是 collector 的架构图
由于 OpenTelemetry 设计之初就是要做到厂商无关,所以它就得做出更高层级的设计。
关键点就是这里的 Receiver 和 Exporter 都是模块化的设计,第三方开发者可以基于它的标准开发不同组件从而兼容不同的产品。
Receiver:用于接收客户端上报的数据,不止是自己 agent 上报的数据,也可能会来自不同的厂商,比如 kubernetes、Kafka 等。
Exporter:同理,可以将 receiver 收到的数据进行处理之后输出到不同的组件中;比如 Kafka/Pulsar/Promethus/Jaeger 等。
比如我们可以使用 Nginx Receiver接收来着 Nginx 上报的数据。
使用 MySQL Receiver接收来自 MySQL 的数据。
当然通常我们使用最多的还是 OTLP Receiver,这是官方的 OTLP 协议的接收器,可以接受官方的一些指标,比如我们只使用了 Java Agent 进行数据上报时。
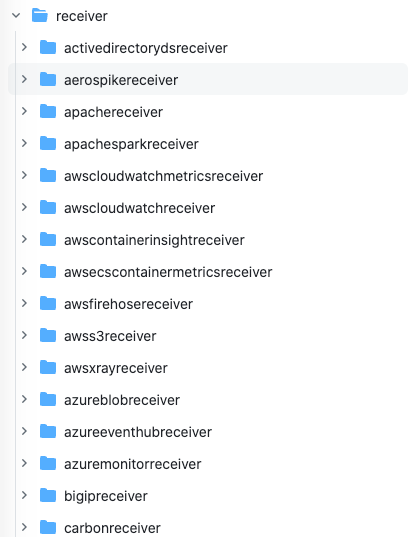
https://github.com/open-telemetry/opentelemetry-collector-contrib/tree/main/receiver
在这里是可以看到目前支持的所有第三方的 Receiver。
OpenTelemetry 所支持的 Exporter 也很多,比如一些常见的存储:
Exporter 的使用场景很多:如果是指标相关的数据可以直接写入 Prometheus,如果是日志数据也可以直接写入 ElasticSearch。
如果还有其他的特殊需求(删减属性等)则可以写入消息队列,自行处理完之后再发往 collector 进行后续的处理。
可能你已经发现了,由于 collector 非常的灵活,所以我们可以像搭积木一样组装我们的 receiver 和 exporter,它会以我们配置的流水线的方式进行调用,这样我们就可以实现任意可定制的处理逻辑。
而这些流水线的组装对于客户端来说都是透明的,也就是说 collector 的更改完全不会影响到业务;业务只需要按照 OTLP 的格式上报数据即可。
在之前的从 Skywalking 切换到 OpenTelemetry 的文章中有人问为什么要切换到 OpenTelemetry?
从这里也能看得出来,OpenTelemetry 的灵活度非常高,借助于 Exporter 可以任意的更换后端存储,或者增加/删减一些不需要的指标数据等。
当然我们也可以统一的在这里进行搜索,可以列出所有的第三方集成的组件:
https://opentelemetry.io/ecosystem/registry/
OpenTelemetry 项目介绍
opentelemetry-java
介绍完基本的概念后,我们可以看看 OTel 社区的一些主要开源项目。
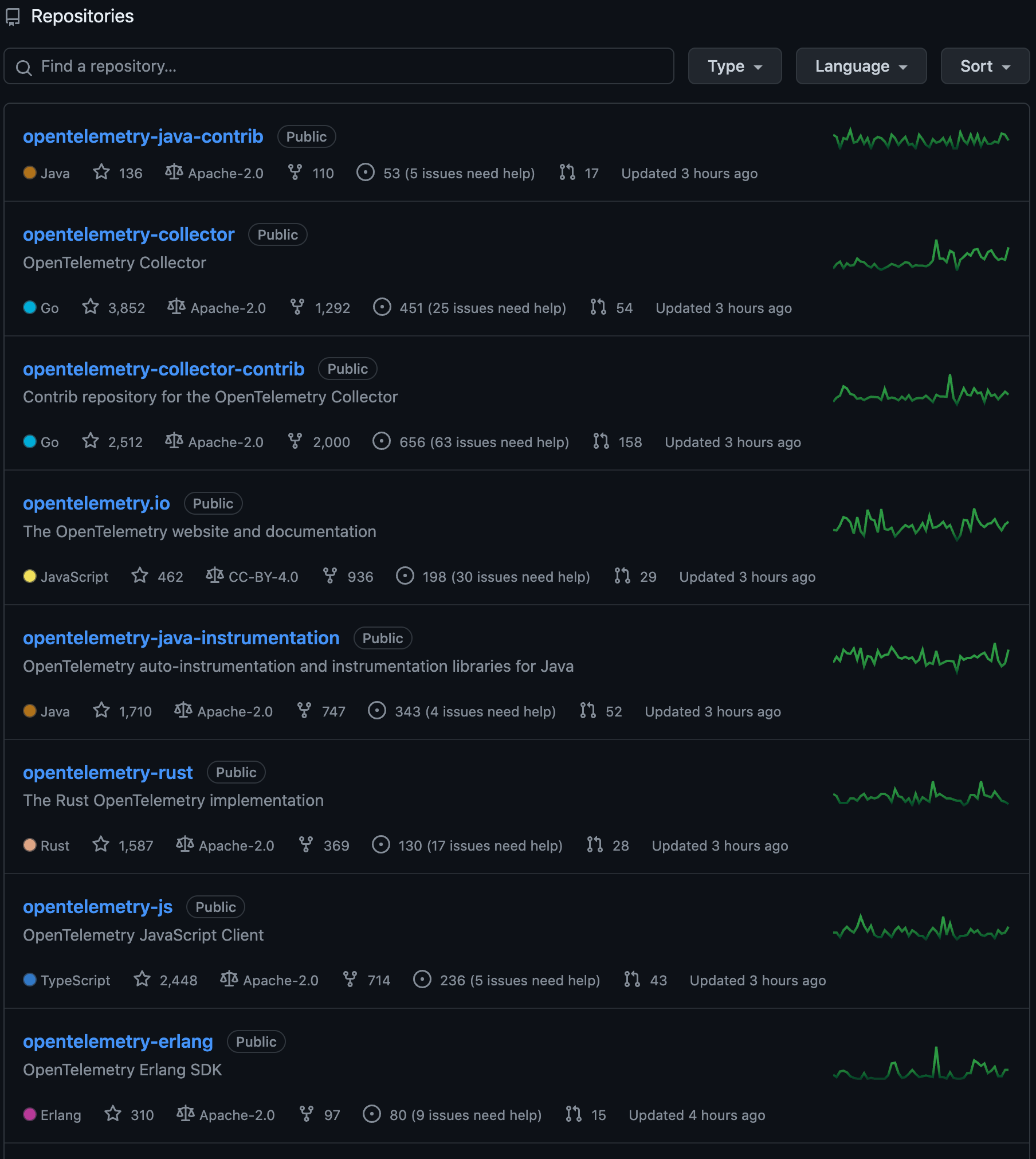
这里我们还是以刚才的那个架构图从作往右讲起,也就是主要分为客户端和 collector 端。
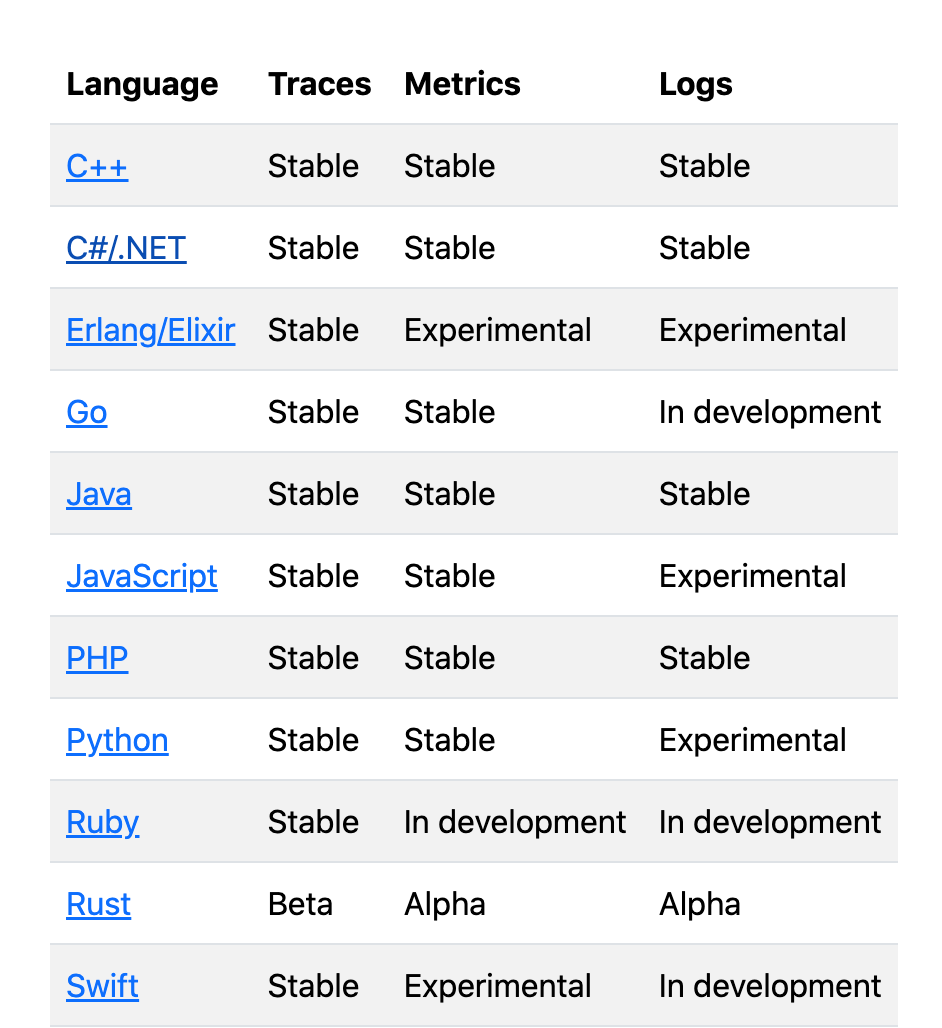
目前官方支持的客户端语言已经非常齐全了,大部分的版本都已经是 Stable 稳定版,意味着可以进入生产环境。
这里我们以 Java 客户端为例:
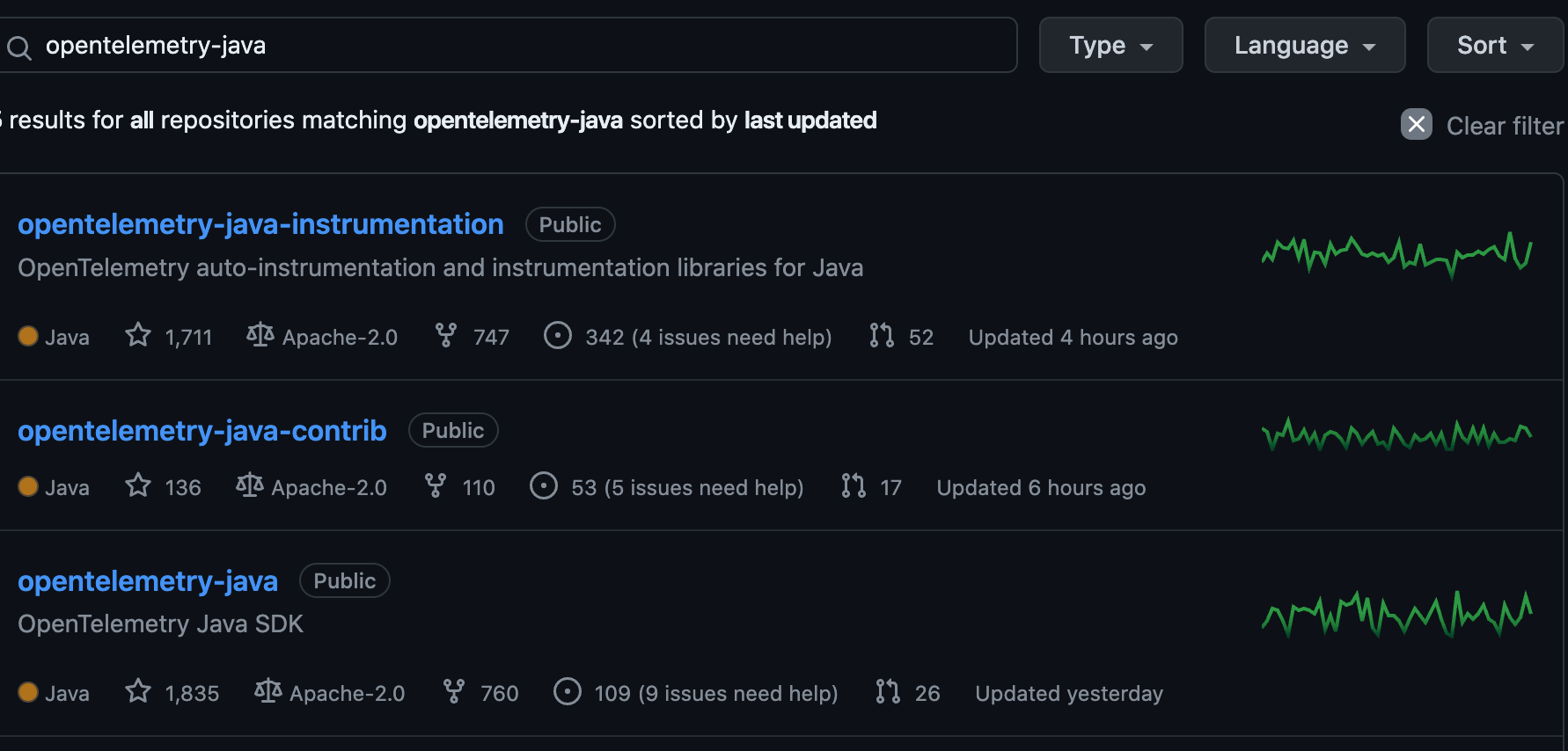
其中我们重点关注下 opentelemetry-java 和 opentelemetry-java-instrumentation 这两个项目。
我们用的最多的会是 opentelemetry-java-instrumentation,它会给我们提供一个 java agent 的 JAR 包:
java -javaagent:path/to/opentelemetry-javaagent.jar \
-jar myapp.jar
我们只需要在 Java 应用中加上该 agent 就可以实现日志、指标、trace 的自动上报。
而且它还实现了不同框架、库的指标采集与 trace。
在这里可以查到支持的库与框架列表:
总之几乎就是你能想到和不能想到的都支持了。
而 opentelemetry-java 我们直接使用的几率会小一些,opentelemetry-java-instrumentation 本身也是基于它创建的,可以理解为是 Java 版本的核心基础库,一些社区支持的组件就可以移动到 instrumentation 这个库中。
比如我在上篇文章:从一个 JDK21+OpenTelemetry 不兼容的问题讲起中涉及到的 HostResourceProvider 资源加载就是从 opentelemetry-java 中移动到了 opentelemetry-java-instrumentation。
具体可以参考:https://github.com/open-telemetry/opentelemetry-java/issues/4701
collector
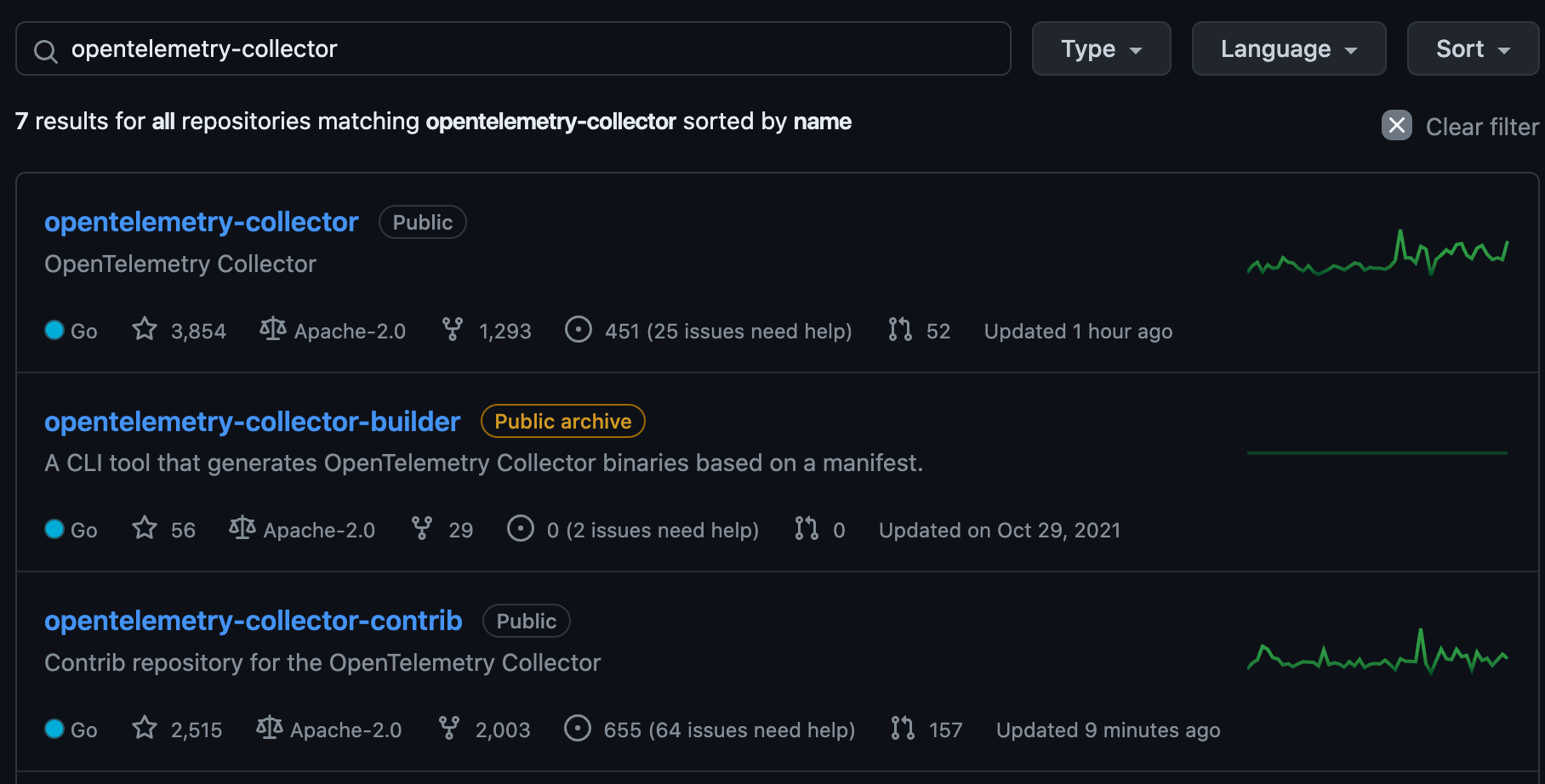
之后就是 collector 的组件了,它同样的也有两个库:
OpenTelemetry Collector 和 OpenTelemetry Collector Contrib
其实通过他们的名字也可以看得出来,他们的作用与刚才的 Java 库类似:
- opentelemetry-collector:由官方社区维护,提供了一些核心能力;比如只包含了最基本的 otlp 的 receiver 和 exporter。
- opentelemetry-collector-contrib:包含了官方的 collector,同时更多的维护了社区提供的各种 receiver 和 exporter;就如上文提到的,一些社区组件(pulsar、MySQL、Kafka)等都维护在这个仓库。
而我们生产使用时通常也是直接使用 opentelemetry-collector-contrib,毕竟它所支持的社区组件更多。
总结
因为 OpenTelemetry 想要解决的是整个可观测领域的所有需求,所以仓库非常多,社区也很开放,感兴趣的朋友可以直接参与贡献,这么多 repo 总有一个适合你的。
后续会继续讲解如何安装以及配置我们的 OpenTelemetry。
参考链接:
- https://github.com/pinpoint-apm/pinpoint
- https://github.com/codecentric/spring-boot-admin
- https://github.com/open-telemetry/opentelemetry-java
- https://github.com/open-telemetry/opentelemetry-java-instrumentation
- https://github.com/open-telemetry/opentelemetry-java/issues/4701
OpenTelemetry 实践指南:历史、架构与基本概念的更多相关文章
- App架构师实践指南四之性能优化一
App架构师实践指南四之性能优化一 1.性能维度常见用来衡量App性能的维度如图9-1所示.其中,性能指标包括电池(电量/温度).流量(上行流量/下行流量等).CPU(平均/最大/最小).内存 ...
- App架构师实践指南五之性能优化二
App架构师实践指南五之性能优化二 2018年07月30日 13:08:44 nicolelili1 阅读数:214 从UI和CPU方面来说App流畅体验优化,核心为流畅度/卡顿性能优化. 1.基 ...
- App架构师实践指南三之基础组件
App架构师实践指南三之基础组件 1.基础组件库随着时间的增长,代码量的逐渐积累,新旧项目之间有太多可以服用的代码.下面是整理的公共代码库. 2.关于加密密钥的保护以及网络传输安全是移动应用安全最关键 ...
- 《App架构实践指南》
推荐书籍 <App 架构实践指南>
- App架构师实践指南六之性能优化三
App架构师实践指南六之性能优化三 2018年08月02日 13:57:57 nicolelili1 阅读数:190 内存性能优化1.内存机制和原理 1.1 内存管理内存时一个基础又高深的话题,从 ...
- App架构师实践指南二之App开发工具
App架构师实践指南二之App开发工具 1.Android Studio 2.编译调试---条件断点.右键单击断点,在弹出的窗口中输入Condition条件.---日志断点.右键单击断点,在弹 ...
- 转载:Google 官方应用架构的最佳实践指南 赞👍
官方给的实践指南,很有实际的指导意义, 特别是对一些小公司,小团队,给了很好的参考意义. 原文地址: https://developer.android.com/topic/libraries/ar ...
- 基于 Spring Cloud 的微服务架构实践指南(下)
show me the code and talk to me,做的出来更要说的明白 本文源码,请点击learnSpringCloud 我是布尔bl,你的支持是我分享的动力! 一.引入 上回 基于 S ...
- [CoreOS 转载] CoreOS实践指南(七):Docker容器管理服务
转载:http://www.csdn.net/article/2015-02-11/2823925 摘要:当Docker还名不见经传的时候,CoreOS创始人Alex就预见了这个项目的价值,并将其做为 ...
- OpenGL ES应用开发实践指南:iOS卷
<OpenGL ES应用开发实践指南:iOS卷> 基本信息 原书名:Learning OpenGL ES for iOS:A Hands-On Guide to Modern 3D Gra ...
随机推荐
- 一图速览 | DTCC 2021大会,阿里云数据库技术大咖都聊了些什么?
简介: 3天9场干货分享,快来收藏吧! 10月18日~10月20日, 由国内知名IT技术社区主办的数据库技术交流盛会--DTCC 2021 (第十一届中国数据库技术大会)在京圆满落幕.大会以&quo ...
- Mybatis学习五($和#区别以及其他tips)
1.$和#区别 1 #是将传入的值当做字符串的形式,eg:select id,name,age from student where id =#{id},当前端把id值1,传入到后台的时候,就相当于 ...
- 数据库—安全性控制DCL
文章目录 授予数据库权限 授予用户能够授予其他用户的权限 收回权限 数据库的权限(特殊) 授予数据库权限 这里的用户是指数据库DBMS中创建的用户,而不是程序中的账户用户. 授予某个/多个表的某一个/ ...
- Angular快速生成文件基本命令
ng new 作用:创建一个已被初始化的Angular应用 命令选项 参数 说明 --collection -c 指定工程模板 属于高阶操作,暂不知道如何使用 --directory 指定新项目创建的 ...
- mybaits-plus实现自定义字典转换
需求:字典实现类似mybatis-plus中@EnumValue的功能,假设枚举类中应用使用code,数据库存储对应的value 思路:Mybatis支持对Executor.StatementHand ...
- python377和python27的区别?
python27无法解释print(1,2,3,sep="*"),Windows命令行窗口运行会报语法错误:无效语法 SyntaxError:invalid syntax pyt ...
- MyBatis反射模块源码分析
说明:本文参考至https://www.jianshu.com/p/baba62bbc107 MyBatis 在进行参数处理.结果映射时等操作时,会涉及大量的反射操作.为了简化这些反射相关操作,MyB ...
- Flutter(三):Flutter App 可行性分析
一.生态建设 第三方Package https://pub.dev/packages?sort=popularity 截止2021年4月,第三方库达到17000+ 二.Devops 代码风格检查 An ...
- 不到200行用Vue实现类似Swiper.js的轮播组件
前言 大家在开发过程中,或多或少都会用到轮播图之类的组件,PC和Mobile上使用 Swiper.js ,小程序上使用swiper组件等. 本文将详细讲解如何用Vue一步步实现的类似Swiper.js ...
- 7.28考试总结(NOIP模拟26)[神炎皇·降雷皇·幻魔皇]
或许只需一滴露水,便能守护这绽放的花朵. 前言 疯狂挂分,本来T2是想用树状数组优化一下的不知道为啥后来看了一下就少看了一层循环, 然后就想,我都 n 的复杂度了,足以搞过第一问了,还优化啥呀.... ...