解密Prompt系列28. LLM Agent之金融领域摸索:FinMem & FinAgent
本章介绍金融领域大模型智能体,并梳理金融LLM的相关资源。金融领域的大模型智能体当前集中在个股交易决策这个相对简单的场景,不需要考虑多资产组合的复杂场景。交易决策被简化成市场上各个信息,包括技术面,消息面,基本面等等在不同市场情况下,对资产价格变动正负面影响的综合判断。
而使用大模型智能体最显著的优势,在于对海量信息的高效处理,存储,以及对相关历史信息的联想。不要和Agent比知识广度和工作效率这一点已经是普遍共识。 下面我们看下这两篇论文使用了金融市场的哪些信息,分别是如何处理,思考并形成交易决策的。
FinMEM
FINMEM: A PERFORMANCE-ENHANCED LLM TRADING AGENT WITH LAYERED MEMORY AND CHARACTER DESIGN
https://github.com/pipiku915/FinMem-LLM-StockTrading
FinMeM是使用文本模态信息,通过差异化召回不同时效性,重要性,相关性的不同金融市场信息,通过微调让模型学习个股交易决策型Agent
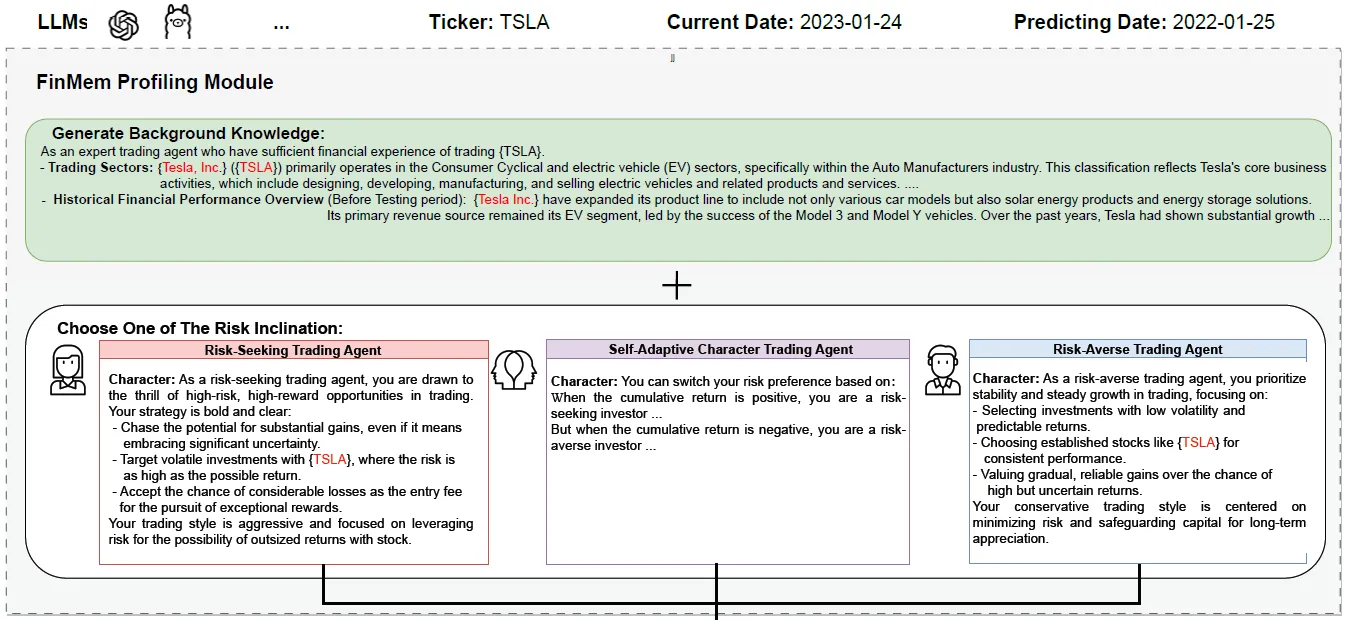
1. Profiling
FinMem的Profile是交易Agent的全局指令类似system-prompt ,包含两个部分
- 金融市场专家知识:包括个股的基本信息例如行业,公司信息,历史股价走势等等
- 3种不同的风险偏好:保守,中性和激进,通过不同prompt,影响模型在不同信息下的交易决策
以及论文提出可以动态转换风险偏好,例如开始亏损的时候可以转换成保守策略,哈哈虽然感觉这难道不是散户亏钱的常规逻辑,赚钱了激进,亏损了就保守~
2. Memory
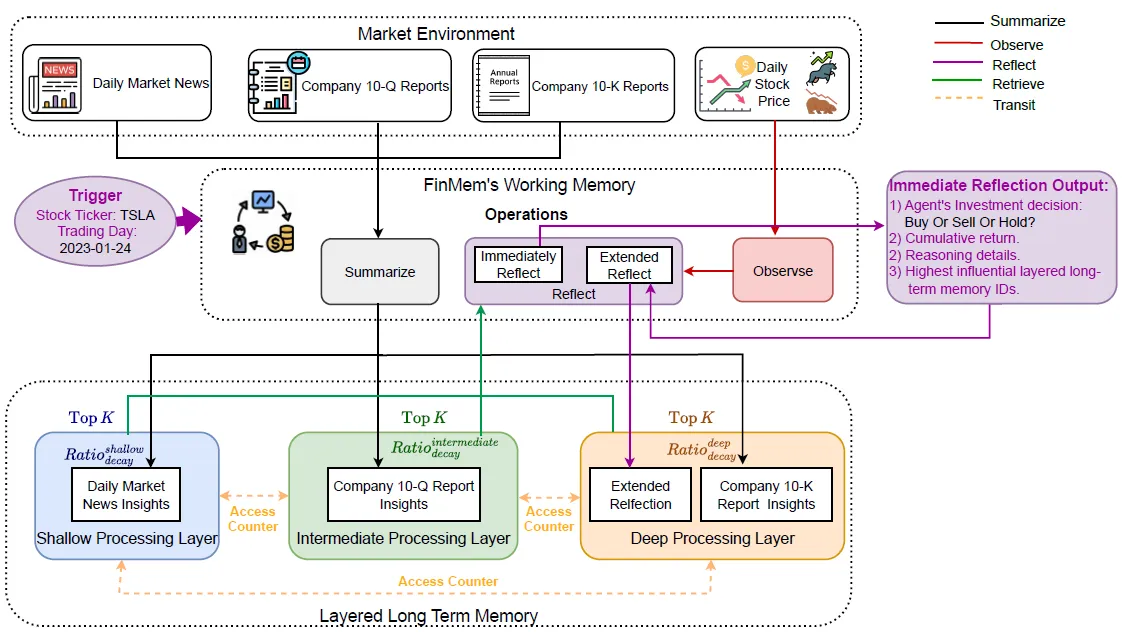
虽然是叫记忆模块,但其实包含了信息收集入库,召回总结和反思的全部流程
- Layered Long Term Memory:不同时效性的内容存储
- Working Memory:多路内容召回,排序,总结和反思
- Summarization
- Observation
- Reflection2.1 Layered Long Term Memory上图中的Bottom部分就是Memroy真正的存储部分。这里论文只使用了金融市场里三种数据源
- 短时效(shallow Layer):市场新闻
- 中时效(Intermediate Layer):公司季报
- 长时效性(Deep Layer):公司年报
在真实场景中其实划分远远不只这些,时效性从长到短还有例如研报,宏观数据,行业数据,路演会议,机构调研,公告,政策,快讯,各种市场面技术指标等等,复杂程度要高的多。因此个人感觉直接按照数据源来定义时效性可能更合适,毕竟不同数据源之间的时效性几乎都是不同的。
在召回以上不同时效性的内容时的打分排序策略借鉴了斯坦福小镇里面对于智能体相关记忆的召回策略(不熟悉的同学看这里LLM Agent之只有智能体的世界)。核心就是只基于相关性来进行记忆召回在时效性敏感的领域中是不可以的。因此召回内容的排序会基于多个因子进行打分,这里其实传统搜广推借助显式的反馈,排序做的更加复杂。这里因为相对缺乏显式的直接反馈,所以只用了相关性,新鲜度,重要性这三个打分维度进行加总。
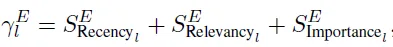
其中新鲜度的计算会依赖于上面的时效性分层,不同分层的金融数据,会有不同的新鲜度计算公式。核心就是时效性更长,该信息对金融市场资产价格的影响持续时间更长,信息的时间敏感度更小,因此在计算新鲜度的时候它的指数衰减更慢。例如快讯可能当日就会时效,而年报效应可能持续好几个月。论文分别用了2周,季度和一年作为指数衰减的系数。
相关性这里用了text-embedding-ada-002计算cosine距离。而重要性论文同样做了不同系数的时间衰减,但系数\(v\_l\)按不同分布随机采样的操作属实是没看懂,但是哈哈这些都是细节不重要,咱重点看框架,看框架~
2.2 Working Memory
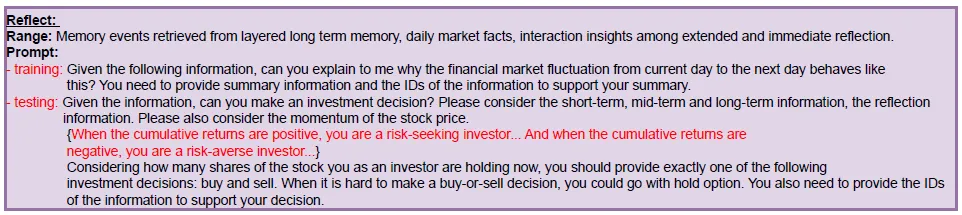
有了分层的信息存储,下一步就是在每一天进行交易决策的时候,进行一系列的信息召回、总结、分析的流程了。这里我们使用论文中的例子在2023-01-24日交易TSLA,inquery="Can you make an investment decision on TSLA on 1/24/2023",之后的流程如下
- summary:信息摘要和情绪分类
摘要会先基于inquery使用上面的打分排序逻辑,去存储中召回相关信息,并基于以下Prompt,对每条信息进行总结。输出是新闻总结和新闻对资产的正面,负面,中性的概率,概率加和为1,这里可以直接取logprobs进行归一化。单个人感觉直接使用概率最高的标签,同时丢弃熵值较高的新闻可能噪声更低一些。

- Observation:市场观测和动量指标
这里论文只使用了个股的动量因子作为市场观测,也就是连续N天的累计涨跌幅。训练样本会给出未来一日动量,目的是让模型学习什么样的消息面情绪会带来未来的价格变动,而测试样本是历史3天的动量,目标是让模型预测未来的价格变动。个人感觉这里训练和测试其实应该对齐,也就是训练样本也提供历史3天的动量因子。这样在后面的反思中也会使用技术指标。

- Reflection:反思
反思分成两个部分:
- 及时思考:基于上面的summray和observation,给出交易建议(Buy,sell,hold),交易原因,和以上summary中具体哪条信息(ID)影响了模型决策。
- 延伸思考:基于最近M天的及时思考,决策后的收益,和股价走势,但我似乎没找到这部分的具体prompt.....延伸反思的结果会存到Deep layer用于后面的交易决策
3. Decision
最终的交易决策会基于当前大模型的profile,Top-K的信息召回,历史累计收益,和延伸思考最终给出交易决策(Buy,SELL,HOLD)。而所谓的训练阶段,其实是依赖真实的资产价格变动,得到更准确的延伸思考(对交易决策的反思),在测试阶段可以使用训练阶段存储的历史思考结果。这部分感觉FinAgent的逻辑更清晰些,看迷糊的朋友可以看后面FinAgent的流程。
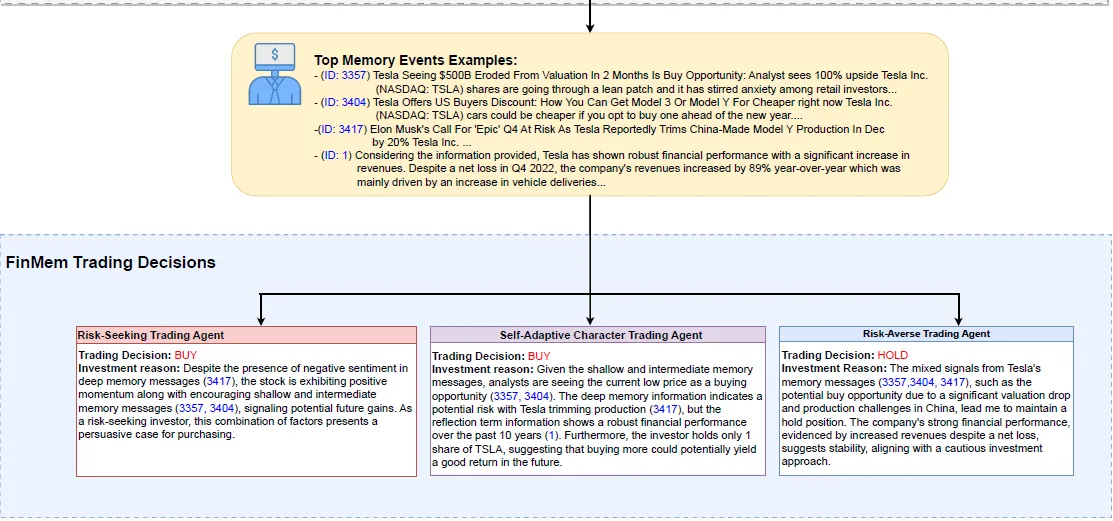
FinAgent
A Multimodal Foundation Agent for Financial Trading: Tool-Augmented, Diversified, and Generalist
只有论文无开源代码
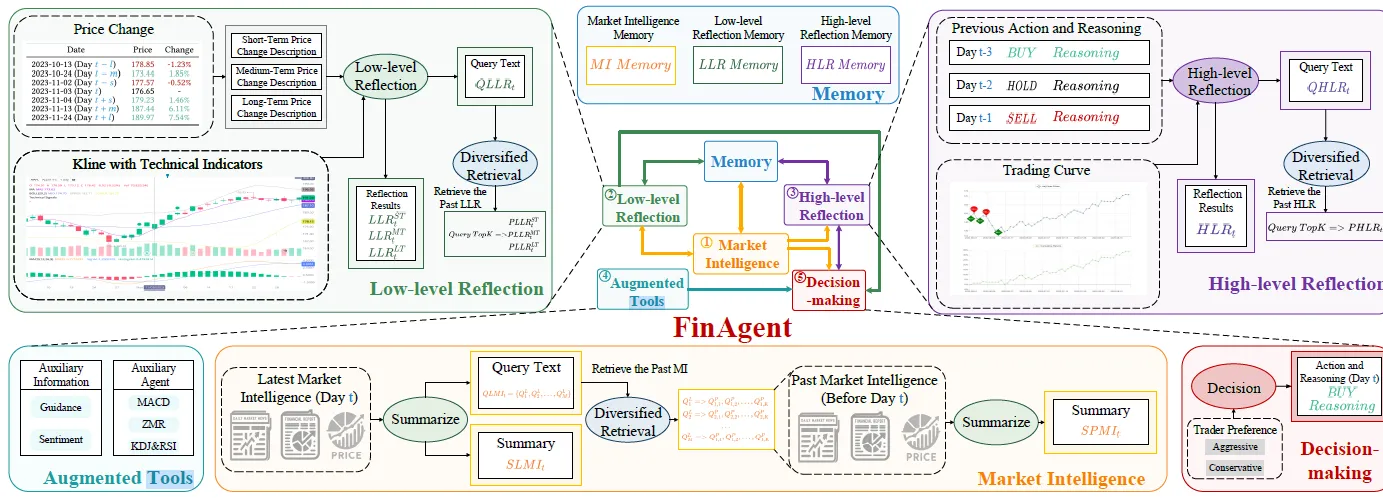
FinAgent是加入了图片模态信息的个股交易决策型Agent,主要包括以下几个模块
- Market Intelligence:市场信息收集和情绪识别汇总模块
- Reflection:价格异动归因和历史交易决策归因模块
- Decision Making:买卖交易决策模块
- Memeory:用于存储以上模块的历史信息
FinAgent一定程度上参考了FinMeM,思路有些相似,不过Prompt输入输出的结构更加清晰和贴近真实市场,几个核心的差异点如下
- FinAgent无需微调,直接使用GPT4和GPT4V
- 数据差异
- 加入了图片模态的信息,包括K线图和历史交易图
- 加入了更多的技术面指标相关交易策略
- 在时效性处理上,FinAgent使用大模型来对每个信息源的时效性进行判断
- 在召回排序上,FinAgent没有使用更复杂的打分排序,而是使用query改写,召回当前数据相关的历史数据,更遵从金融市场上历史会重演的基本逻辑。
1. Market Intelligence
MI模块是特定金融主体的信息收集,分析总结和情绪识别模块(类似FinMeM的summary,但加入了和历史信息的联动)。它分成了当日市场信息(Latest MI),和历史市场信息(Past MI)两个部分。前者反映了最新的资产异动,后者利用金融市场中历史会不断重演的特性。例如上次苹果产品发布,对APPL股价带来5%的提振,那如果今日舆情显示苹果又有新产品发布,那我们可能会预期有相似的正向影响。
首先是当日市场信息,主要做以下几件事情
- 获取资产当日(T)的资产价格,新闻舆情(通过FMPAPI接口)信息,拼接后作为大模型的上文,填充到下面latest_market_intelligence
- Analysis:基于系统指令和任务描述,对以上所有信息进行COT分析,论文通过prompt给出了分析方式,简化成每条信息对资产价格的正面/负面/中性影响,以及短/中/长的影响时效性。
- Summary:对以上Analysis的分析结果进行总结,只保留核心投资观点,并对上面相似的正负面和时效性进行聚合。
- Query生成:基于以上的总结内容,生成短/中/长不同时效性的检索query(关键词),用于搜索该资产的历史信息。
这里论文使用了XML格式的prompt来承载各类信息,整个Lastest MI的Prompt如下,其中iframe会填充具体的系统指令,任务描述,如何分析资产正负面影响,如何进行分析总结和query生成,以及输出格式。iframe的具体内容实在是太长了,大家直接看论文附录G
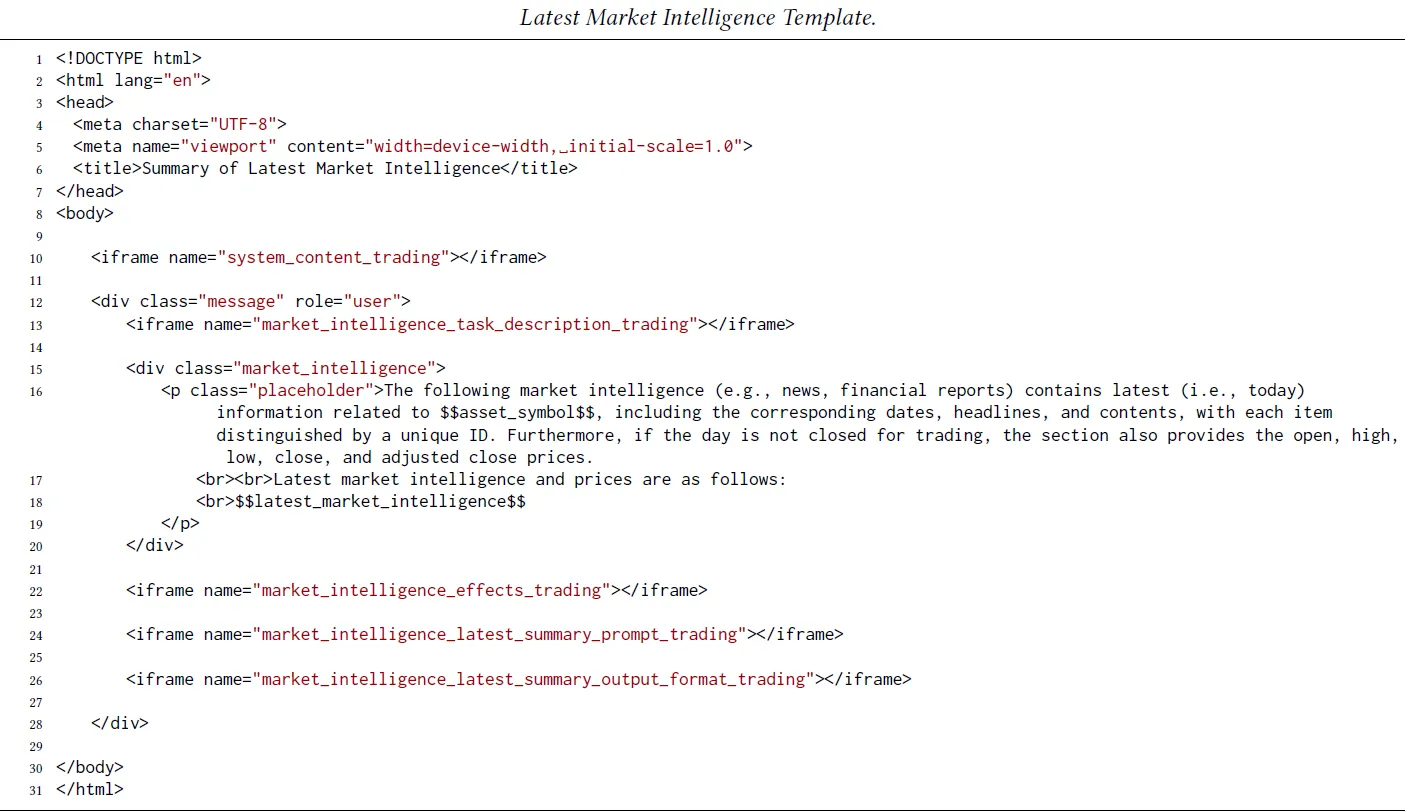
其次是历史市场信息部分,主要做以下几件事情
- 基于上面的Query,去搜索该资产历史(<T)不同时间窗口的各类信息,包括但不限于:不同周期的资产价格变化,新闻舆情,研究报告等等
- 和上面当日市场信息相同,对信息进行分析和总结,不过不需要生成query了。
论文没有提供具体的数据,只给了大致的分析结果如下

2. Reflection
收集完信息,就进入了反思模块,也分成了两个阶段low-level和high-level。前者基于上面的Market Intelligence提供的舆情正负面影响和股价变动,对短/中/长期股价异动进行归因(类似FinMeM的及时分析)。后者基于Market Intelligence,历史和当前的low-level的反思,对交易决策进行归因(类似FinMeM的延伸思考)。论文只提供了简化后的效果如下
下面我们具体说下Low-Level和High-Level的输入输出
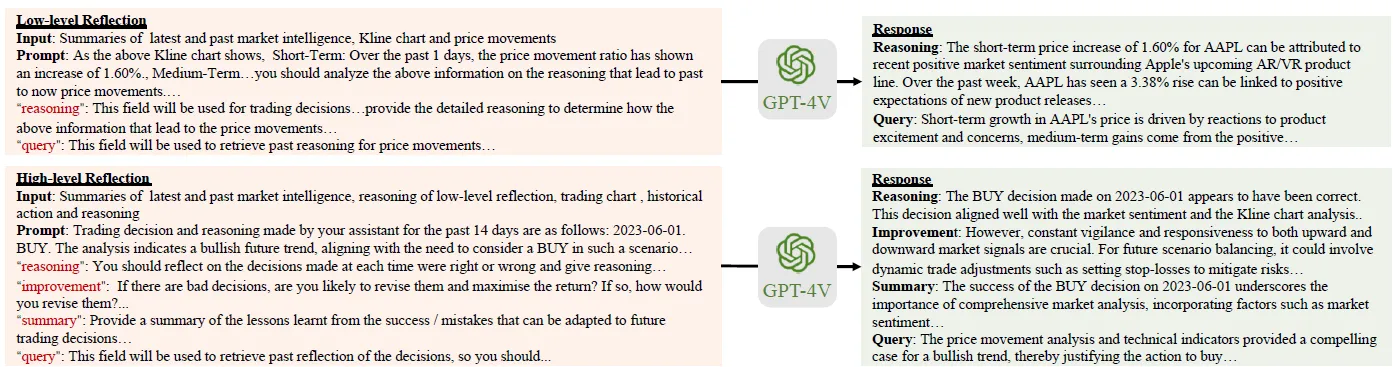
2.1 Low-Level Reflection
low-level的反思prompt的构成如下
1. 输入
- 以上Market Intelligence的总结,包括历史和当前舆情对资产正负面的影响
- 多模态K线图,以下是用来帮助模型理解K线图的Prompt指令

- 短/中/长期的价格走势变动描述,描述模板如下:

2. 输出
- reason:分别对短/中/长期的资产价格变动进行归因,原因可以是Momentum等技术面原因,也可以是Market Intelligence中舆情带来的消息面原因
- summary:对以上的分析进行总结,作为后面High-Level的输入
- query:和上面Market Intelligence相同,生成召回Query,用于召回Memory中的相关历史Low-Level Reflection。
因为涉及到了K线图的多模态理解,这里论文使用了GPT-4V来完成以上prompt指令。具体Prompt指令,详见附录G。
2.2 High-Level Reflection
High Level的反思prompt构建如下
1. 输入
- Market Intelligence: 同Low Level
- Low Level Relection:包括最新的Low-Level反思,和使用以上Low-Level query召回的历史Low-Level对于该资产价格变动的反思
- 多模态TradingChart,以下是用来帮助模型理解图片的prompt指令:交易图包括价格趋势图,和历史买入和卖出的时间点。

2. 输出
- reasoing:基于MI,Low-Level,价格变动,分析历史每一笔交易决策是否正确(带来收益),以及在各个时间点,影响交易决策因素有哪些,权重如何
- improvement: 如果存在错误的交易决策,应该如何改进,并给出新的买卖时间点,例如 (2023-01-03: HOLD to BUY)
- summary: 对以上分析进行总结
- query:同样生成query用于召回历史high-level
3. Decision-making
最后的决策模块,基于以上三个模块的输入和额外的技术指标,分析师观点等补充信息,进行交易决策。Prompt构建如下
1. 输入
- Market Intelligence
- Low Level Reflection
- High Level Reflection: 包括最新的交易反思和历史的交易反思
- Augmented Tools:这里论文使用工具补充获取了以下信息
- Expert guidance:论文似乎未说明专家信息来源,只说是类似文章的数据源。猜测可能是买方买方观点,例如XX股买入推荐一类
- strategy:传统技术面交易策略,类似啥MACD穿越,KDJ金叉,这里论文通过工具调用获取证券的MACH,KDJ和均值回归等技术指标,指标相关描述如下

- prompt: 告诉模型如何利用以上的各个输入信息,来给出交易决策。

2. 输出
- analysis:step-by-step的分析以上各个信息输入的综合影响
- reasoning:针对以上分析给出买卖操作的原因
- action:基于分析原因给出交易行为,BUY,SELL,HOLD
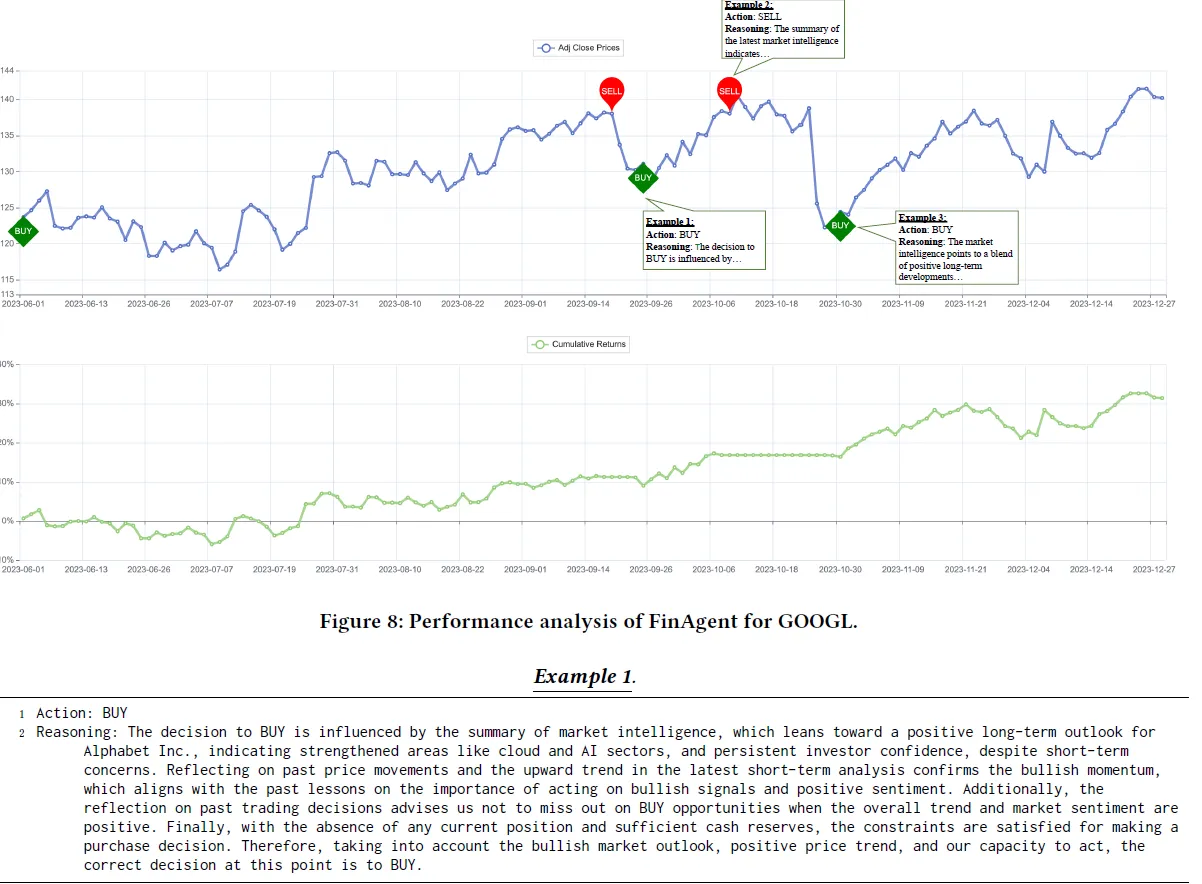
4. 效果
最后说下效果评估,这里论文使用个股交易的累计收益率作为评价指标,对比基于技术指标的规则交易,基于RL的方案,以及上面的FinMem,在年化收益率,夏普比率上均有显著提升,在最大回撤上基本持平。
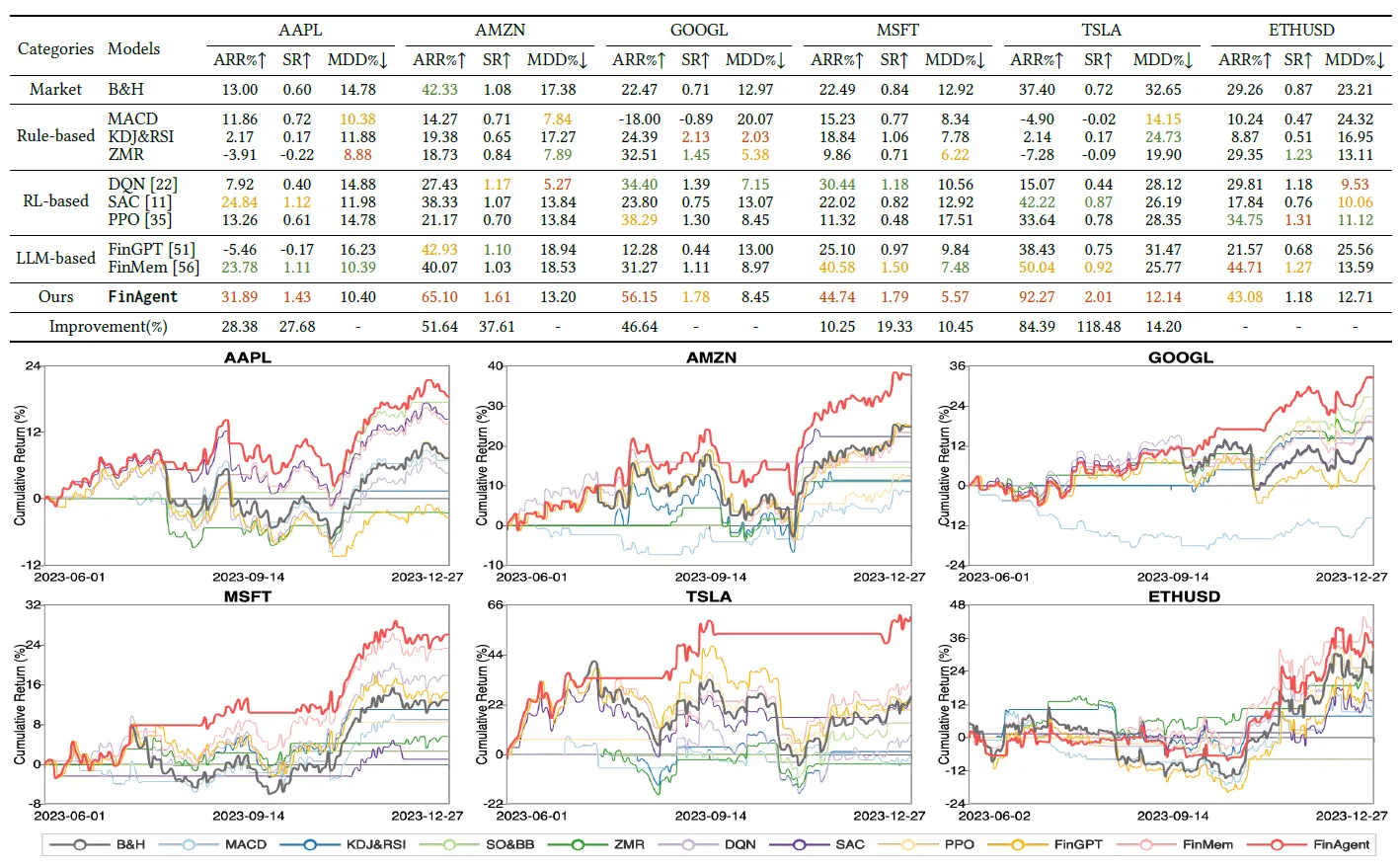
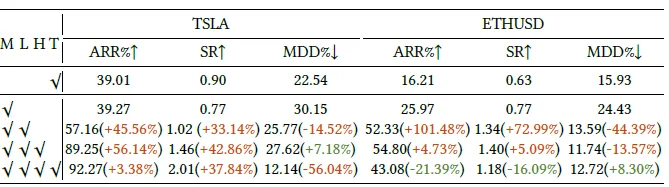
同时论文进行了消融实验,对比只使用M(MI市场信息),只使用T(Tools买卖方观点+技术面),和加入反思,加入交易决策的效果。数据就比较有意思了,只使用M和T的效果竟然差不多,核心提升来自反思模块。不过这里结论和市场有很大关系,哈哈美国市场的实验结论没有直接迁移到A股的可能~
金融领域大模型资源梳理
金融大模型应用
- Reportify: 金融领域公司公告,新闻,电话会的问答和摘要总结
- Alpha派: kimi加持会议纪要 + 投研问答 +各类金融资讯综合的一站式平台
- 况客FOF智能投顾:基金大模型应用,基金投顾,支持nl2sql类的数据查询,和基金信息对比查询等
- ScopeChat:虚拟币应用,对话式组件交互和问答
- AInvest:个股投资类检索增强问答,ChatBI金融数据分析做的有点厉害
- HithinkGPT:同花顺发布金融大模型问财,覆盖查询,分析,对比,解读,预测等多个问题领域
- FinChat.io:超全的个股数据,个股投资助手
- TigerGPT: 老虎证券,GPT4做个股分析,财报分析,投资知识问答
- ChatFund:韭圈儿发布的第一个基金大模型,看起来是做了多任务指令微调,和APP已有的数据功能进行了全方位的打通,从选基,到持仓分析等等
- 无涯Infinity :星环科技发布的金融大模型
- 曹植:达观发布金融大模型融合data2text等金融任务,赋能报告写作
- 妙想: 东方财富自研金融大模型开放试用,但似乎申请一直未通过
- 恒生LightGPT:金融领域继续预训练+插件化设计
- bondGPT: GPT4在细分债券市场的应用开放申请中
- IndexGPT:JPMorgan在研的生成式投资顾问
- Alpha: ChatGPT加持的金融app,支持个股信息查询,资产分析诊断,财报汇总etc
- Composer:量化策略和AI的结合,聊天式+拖拽式投资组合构建和回测
- Finalle.ai: 实时金融数据流接入大模型
金融Agent论文
- WeaverBird: Empowering Financial Decision-Making with Large Language Model, Knowledge Base, and Search Engine
- FinGPT: Open-Source Financial Large Language Models
- FinMem: A Performance-Enhanced LLM Trading Agent with Layered Memory and Character Design
- AlphaFin:使用检索增强股票链框架对财务分析进行基准测试
- A Multimodal Foundation Agent for Financial Trading: Tool-Augmented, Diversified, and Generalist
- Can Large Language Models Beat Wall Street? Unveiling the Potential of AI in stock Selection
金融SFT论文
- BloombergGPT: A Large Language Model for Finance
- XuanYuan 2.0: A Large Chinese Financial Chat Model with Hundreds of Billions Parameters
- FinVis-GPT: A Multimodal Large Language Model for Financial Chart Analysis
- CFBenchmark: Chinese Financial Assistant Benchmark for Large Language Model
- CFGPT: Chinese Financial Assistant with Large Language Model
- InvestLM: A Large Language Model for Investment using Financial Domain Instruction Tuning
- BBT-Fin: Comprehensive Construction of Chinese Financial Domain Pre-trained Language Model, Corpus and Benchmark
- PIXIU: A Large Language Model, Instruction Data and Evaluation Benchmark for Finance
- https://sota.jiqizhixin.com/project/deepmoney
想看更全的大模型相关论文梳理·微调及预训练数据和框架·AIGC应用,移步Github >> DecryPrompt
解密Prompt系列28. LLM Agent之金融领域摸索:FinMem & FinAgent的更多相关文章
- 解密Prompt系列6. lora指令微调扣细节-请冷静,1个小时真不够~
上一章介绍了如何基于APE+SELF自动化构建指令微调样本.这一章咱就把微调跑起来,主要介绍以Lora为首的低参数微调原理,环境配置,微调代码,以及大模型训练中显存和耗时优化的相关技术细节 标题这样写 ...
- 解密prompt系列5. APE+SELF=自动化指令集构建代码实现
上一章我们介绍了不同的指令微调方案, 这一章我们介绍如何降低指令数据集的人工标注成本!这样每个人都可以构建自己的专属指令集, 哈哈当然我也在造数据集进行时~ 介绍两种方案SELF Instruct和A ...
- 解密Prompt系列3. 冻结LM微调Prompt: Prefix-Tuning & Prompt-Tuning & P-Tuning
这一章我们介绍在下游任务微调中固定LM参数,只微调Prompt的相关模型.这类模型的优势很直观就是微调的参数量小,能大幅降低LLM的微调参数量,是轻量级的微调替代品.和前两章微调LM和全部冻结的pro ...
- 解密Prompt系列2. 冻结Prompt微调LM: T5 & PET & LM-BFF
这一章我们介绍固定prompt微调LM的相关模型,他们的特点都是针对不同的下游任务设计不同的prompt模板,在微调过程中固定模板对预训练模型进行微调.以下按时间顺序介绍,支持任意NLP任务的T5,针 ...
- 解密Prompt系列4. 升级Instruction Tuning:Flan/T0/InstructGPT/TKInstruct
这一章我们聊聊指令微调,指令微调和前3章介绍的prompt有什么关系呢?哈哈只要你细品,你就会发现大家对prompt和instruction的定义存在些出入,部分认为instruction是promp ...
- 8.Java 加解密技术系列之 PBE
Java 加解密技术系列之 PBE 序 概念 原理 代码实现 结束语 序 前 边的几篇文章,已经讲了几个对称加密的算法了,今天这篇文章再介绍最后一种对称加密算法 — — PBE,这种加密算法,对我的认 ...
- 5.Java 加解密技术系列之 DES
Java 加解密技术系列之 DES 序 背景 概念 基本原理 主要流程 分组模式 代码实现 结束语 序 前 几篇文章讲的都是单向加密算法,其中涉及到了 BASE64.MD5.SHA.HMAC 等几个比 ...
- .NET Core加解密实战系列之——使用BouncyCastle制作p12(.pfx)数字证书
简介 加解密现状,编写此系列文章的背景: 需要考虑系统环境兼容性问题(Linux.Windows) 语言互通问题(如C#.Java等)(加解密本质上没有语言之分,所以原则上不存在互通性问题) 网上资料 ...
- Java 加解密技术系列文章
Java 加解密技术系列之 总结 Java 加解密技术系列之 DH Java 加解密技术系列之 RSA Java 加解密技术系列之 PBE Java 加解密技术系列之 AES Java 加解密技术系列 ...
- 11.Java 加解密技术系列之 总结
Java 加解密技术系列之 总结 序 背景 分类 常用算法 原理 关于代码 结束语 序 上一篇文章中简单的介绍了第二种非对称加密算法 — — DH,这种算法也经常被叫做密钥交换协议,它主要是针对密钥的 ...
随机推荐
- 【已解决】xml映射找不到类名java.lang.ClassNotFoundException
XMLUtil文件里的Class.forName 参数要写相对于项目根目录的绝对路径,除了类名要加上对应的包路径!
- System.gc 之后到底发生了什么 ?
本文基于 OpenJDK17 进行讨论 在 JDK NIO 针对堆外内存的分配场景中,我们经常会看到 System.gc 的身影,比如当我们通过 FileChannel#map 对文件进行内存映射的时 ...
- #线性筛,斐波那契数列,GCD#BZOJ 2813 奇妙的Fibonacci
题目 有一个斐波那契数列,满足 \[F_n=\begin{cases}1\qquad (n==1)\\1\qquad (n==2)\\F_{n-1}+F_{n-2}\qquad (n>2)\en ...
- OpenHarmony将携新成果亮相HDC2022
第四届华为开发者大会 2022(Together)将于11月4日-6日在东莞召开,OpenAtom OpenHarmony(以下简称"OpenHarmony")将携新生态成果亮相 ...
- 定时运行BAT文件
引用:https://www.cnblogs.com/lidj/archive/2012/07/07/2580598.html 1.Form.cs: using CC=System.Web.Mail; ...
- HarmonyOS 3.1版本发布,全面进入声明式开发
原文:https://mp.weixin.qq.com/s/kyyYCjrl6E8MBxKpBSKNWg,点击链接查看更多技术内容. 开发者的脚步永不停歇,2022年我们发布了HarmonyOS ...
- 在centOS上配置web服务器
centos,web服务,apache,ftp服务器,mysql,makefile (1). 检查系统是否正常 # more /var/log/messages //检查有无系统内核级错误信息 # d ...
- android android7以上无法连接蓝牙
前言 在开发android 蓝牙的时候,发现一个问题,那就是android7无法连接上蓝牙. 原因 <!-- 管理蓝牙设备的权限 --> <uses-permission andro ...
- 重新整理.net core 计1400篇[二] (.net core 改造控制台项目)
前言 为.net core 命令行的基础上写的,如果有兴趣的话,可以去看我的.net core 前文. 下面介绍如何将.net core控制台转换为.net core web应用. 正文 如果我们要实 ...
- 【GDKOI 2024 TG Day2】不休陀螺(top) 题解
考虑一个卡牌区间怎样才不是"陀螺无限". 一个是费用在打到一半时费用就不够了.考虑构造一个卡牌序列使其尽量能够在打到一半时费用就不够,如何构造呢? 把 \(a_i > b_i ...