Unsupervised Learning of Depth and Ego-Motion from Video(CVPR2017)论文阅读
深度估计问题
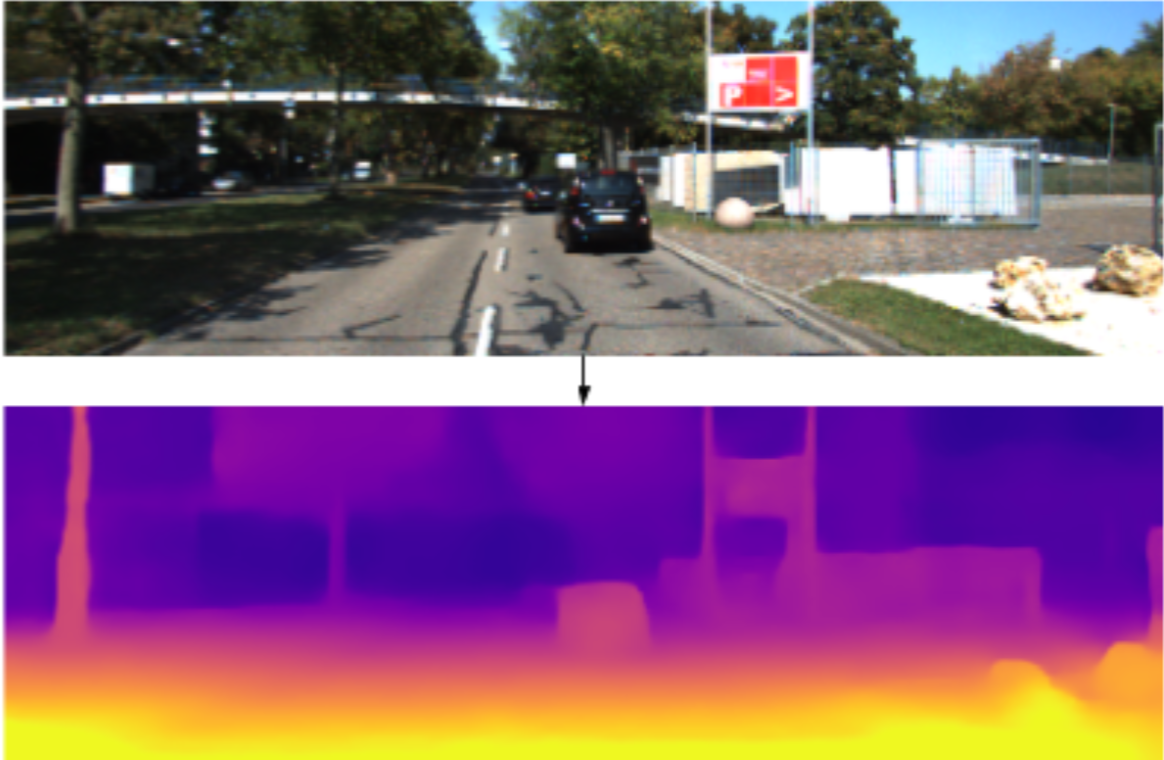
从输入的单目或双目图像,计算图像物体与摄像头之间距离(输出距离图),双目的距离估计应该是比较成熟和完善,但往单目上考虑主要还是成本的问题,所以做好单目的深度估计有一定的意义。单目的意思是只有一个摄像头,同一个时间点只有一张图片。就象你闭上一只眼睛,只用一只眼睛看这个世界的事物一样,距离感也会同时消失。
深度估计与语义分割的区别,及监督学习的深度估计问题
深度估计与语义分割有一定的联系,但也有一些区别。
- 图像的语义分割是识别每个像素的类别,不管这个像素出现在图像的那个位置,是一个分类任务。
- 而深度估计是识别每个像素与当前摄像头的距离,相同的车出现在图像的不同位置,其距离有可能不一样,是一个回归任务。
在深度估计上直接使用语义分割的方案,是可以达到一定的效果,但因为以上的区别,所以要把深度估计做好还是值得探讨。另外,
深度估计有监督学习的方案,但深度估计的监督学习存在两个问题:
- 监督学习所需要的label,制作上的代价比较大,不利于把方案应用到更多情境或验证;
- 如果以激光雷达的数据作为label,但激光雷达的探测距离比视觉近,一些超越探测距离的区域无法训练。
基于这些问题,本论文提出一种不需要真实深度label的自监督方法。
基本原理
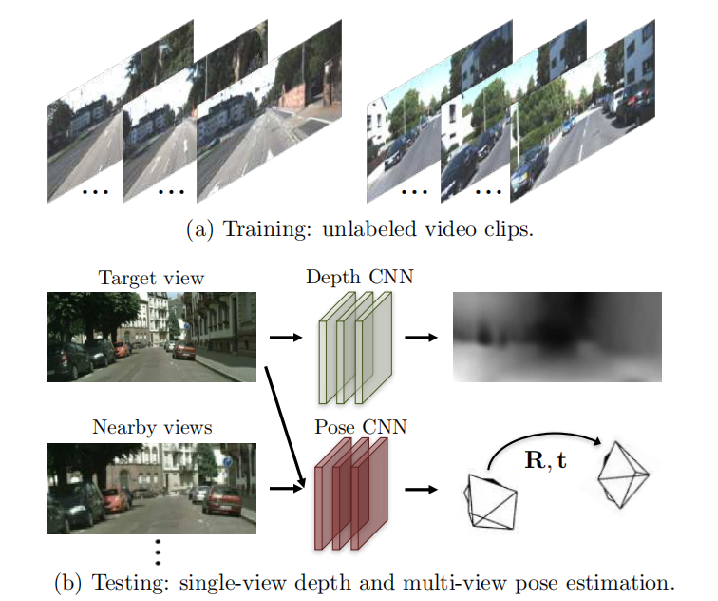
作者巧妙地利用SFM(Structure from motion)原理同时训练DepthNet(深度估计网络)和PoseNet(姿态估计网络),使用它们的输出重构图像$\hat I$与原图像$I$进行比较,免除真实深度label的需要。
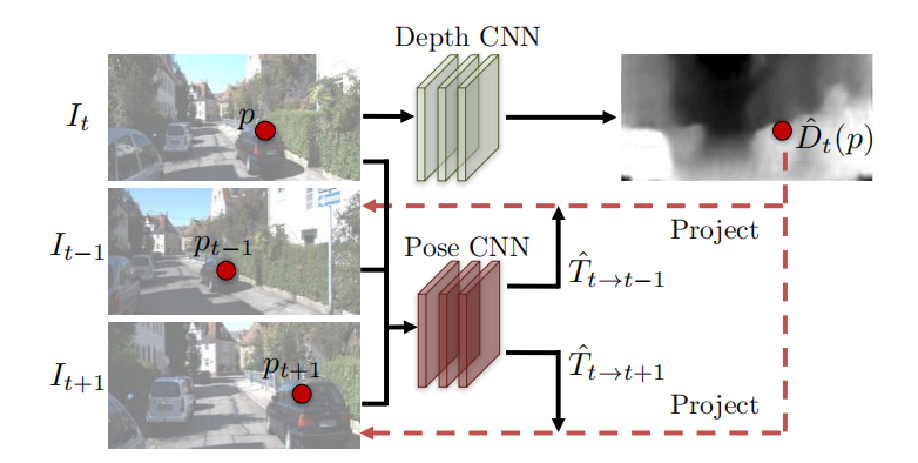
选择从时间上连续的三张图像,分别是$I_{t-1}$,$I_t$,$I_{t+1}$。DepthNet学习$I_t$的深度并输出深度图$\hat D_t$,PoseNet从$I_t$分别到$I_{t-1}$和$I_{t+1}$学习转换矩阵$\hat T_{t \to t-1}$和$\hat T_{t \to t+1}$,如上图,图像$I_t$里的$p$点可以通过对应的深度值$\hat D_t(p)$和转换矩阵$\hat T_{t \to t-1}$投影到$I_{t-1}$上对应位置$p_{t-1}$。
$p_s \sim K \hat T_{t \to s} \hat D_t(p_t)K^{-1}p_t$
其中,$K$是摄像头的内参矩阵(出厂时进行标定或自己标定)。
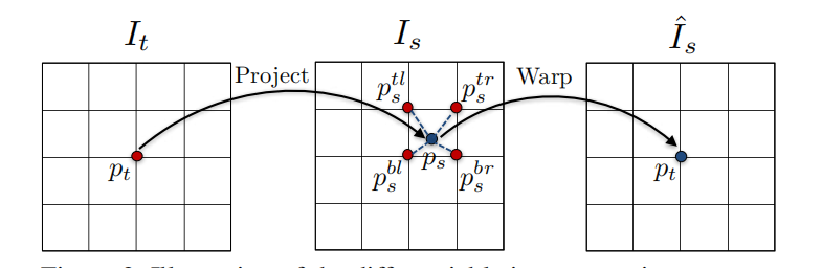
投影到的位置后使用相邻像素进行双线性插值进行图像重建,以光度重建缺失同时训练两个网络。
$L_{vs} = \sum_s{\sum_p | I_t(p) - \hat I_s(p)|}$
局限性
应用在视频时,方案包含了三个假设前提
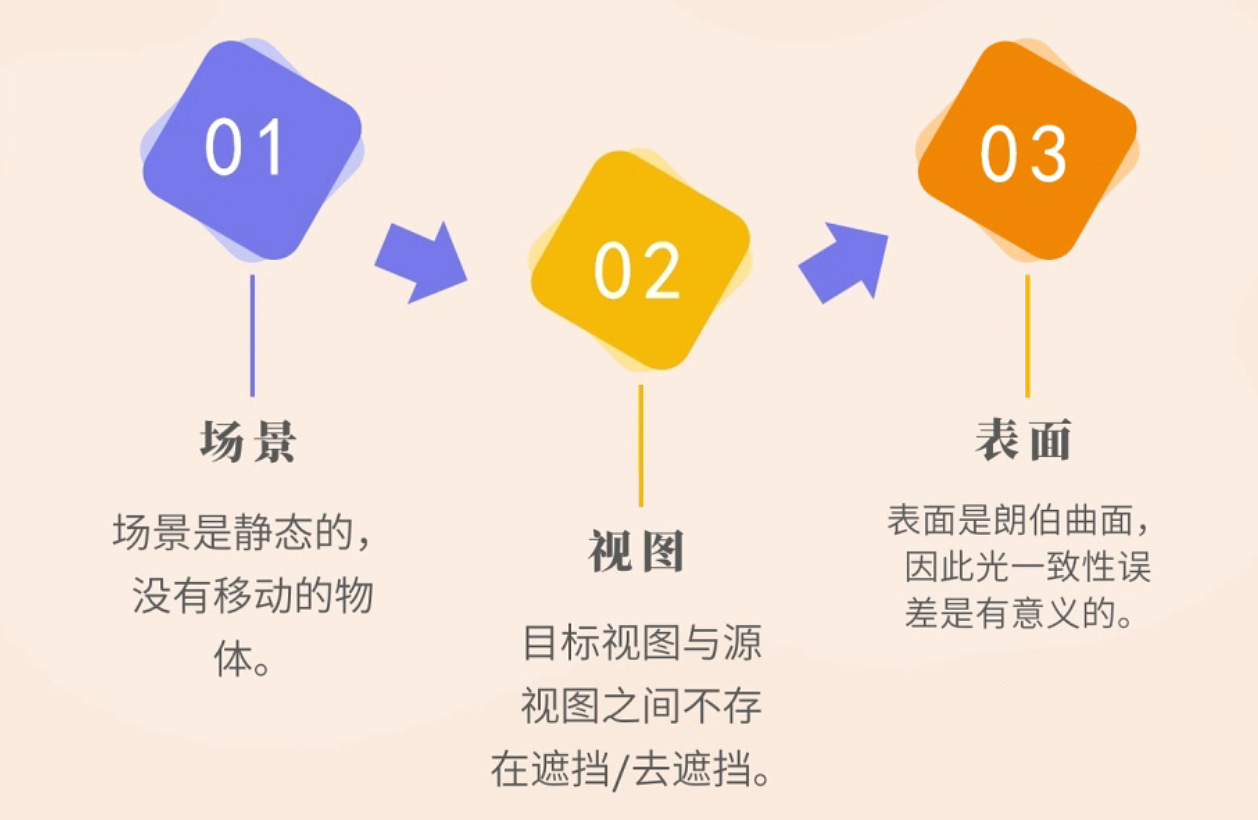
1. 依赖于SFM,如果图像里的物体是“静止”,其实是该物体和本身的运动速度一致,那个该物体在不同时间上的视图里,不会发生变化,固“静止”。
2. 不考虑遮挡,是先把要处理的问题简单化。
3. 重建损失的前提。
局限性解决
1. 解决静止和遮挡
增加一个可解释性预测网络,该网络为每个目标-源对输出每个像素的软掩码$\hat E_s$,表明网络信任那些目标像素能进行视图合成。基于$\hat E_s$后的损失函数为
$L_{vs} = \sum_{<I_1,...,I_N> \in S}{\sum_p{\hat E_s(p)|I_t(p) - \hat I_s(p)|}}
由于不能对$\hat E_s$直接监督,使用上述的损失进行训练将导致网络总是预测$\hat E_s$为零(就最小化了损失)。为了解决这个问题,添加一个正则项$L_{reg}(\hat E_s)$,通过在每个像素位置上使用常数标签1最小化交叉熵损失来鼓励非零预测。
2. 克服梯度局部性
上述的学习方式还有一个遗留问题,梯度主要来自$I(p_t)$和它4个邻居之间的像素强度差,如果像素位于低纹理区域或远离当前估计,则会抑制训练。解决这个问题有两个方案:
1. 使用总面积encoder-deconder架构,深度网络的输出隐含地约束全局平滑,并促进梯度从有意义的区域传播到附近的区域。
2. 明确的多尺度和平滑损失,允许直接从更大的空间区域导出梯度。
作者选择第二种方案,原因是它对架构选择不太敏感。为了平滑,作者最小化预测深度图的二阶梯度的L1范数。最终的损失函数为:
$L_{final} = \sum_l{L_{vs}^l} + \lambda_s L_{smooth}^l + \lambda_e \sum_s{L_{reg}(\hat E_s^l)}$
总结
在作者提出该方案前,已经存在基于深度值的监督学习和基于姿态的监督学习,他的出发点是以多种有相关性的任务同时学习,从而融合它们的学习结果可以回归到原图像,这使一方面同时训练多个相关模型,另一方面能起到自监督的效果。
Unsupervised Learning of Depth and Ego-Motion from Video(CVPR2017)论文阅读的更多相关文章
- Learning under Concept Drift: A Review 概念漂移综述论文阅读
首先这是2018年一篇关于概念漂移综述的论文[1]. 最新的研究内容包括 (1)在非结构化和噪声数据集中怎么准确的检测概念漂移.how to accurately detect concept dri ...
- SfMLearner论文笔记——Unsupervised Learning of Depth and Ego-Motion from Video
1. Abstract 提出了一种无监督单目深度估计和相机运动估计的框架 利用视觉合成作为监督信息,使用端到端的方式学习 网络分为两部分(严格意义上是三个) 单目深度估计 多视图姿态估计 解释性网络( ...
- Unsupervised learning, attention, and other mysteries
Unsupervised learning, attention, and other mysteries Get notified when our free report “Future of M ...
- Machine Learning Algorithms Study Notes(4)—无监督学习(unsupervised learning)
1 Unsupervised Learning 1.1 k-means clustering algorithm 1.1.1 算法思想 1.1.2 k-means的不足之处 1 ...
- Unsupervised Learning: Use Cases
Unsupervised Learning: Use Cases Contents Visualization K-Means Clustering Transfer Learning K-Neare ...
- Unsupervised Learning and Text Mining of Emotion Terms Using R
Unsupervised learning refers to data science approaches that involve learning without a prior knowle ...
- Supervised Learning and Unsupervised Learning
Supervised Learning In supervised learning, we are given a data set and already know what our correc ...
- Unsupervised learning无监督学习
Unsupervised learning allows us to approach problems with little or no idea what our results should ...
- PredNet --- Deep Predictive coding networks for video prediction and unsupervised learning --- 论文笔记
PredNet --- Deep Predictive coding networks for video prediction and unsupervised learning ICLR 20 ...
- 131.005 Unsupervised Learning - Cluster | 非监督学习 - 聚类
@(131 - Machine Learning | 机器学习) 零. Goal How Unsupervised Learning fills in that model gap from the ...
随机推荐
- Django笔记三十一之全局异常处理
本文首发于公众号:Hunter后端 原文链接:Django笔记三十一之全局异常处理 这一篇笔记介绍 Django 的全局异常处理. 当我们在处理一个 request 请求时,会尽可能的对接口数据的格式 ...
- react中super()的理解
首先 super() 是在 es6的class(类)的方法创建组件出现 下面是分别是构造函数创建组件和class(类)创建组件 构造函数方法创建组件 在构造函数方法中,在组件接收参数的时候,props ...
- Python-pprint的简单使用
Data pretty printer 一.简介 print()和pprint()都是python的打印模块,功能基本一样,唯一的区别就是pprint()模块打印出来的数据结构 ...
- Prism Sample 20-NavigateToExistingViews
上一个例子介绍了INavigationAware中的OnNavitationTo,这次是第二个实现函数. IsNavitationTarget,这个名字有点误导,真实的作用是,当从其它页面导航至本页面 ...
- Vulhub activewq_漏洞复现——源码分析
Vulhub activewq_漏洞复现--源码分析 漏洞简介 Apache ActiveMQ是由美国阿帕奇(Apache)软件基金会开发的开源消息中间件,支持Java消息服务.集群.Spring框架 ...
- Wolai 使用教程:嵌入小组件库,打造精美、强大的知识库主页
Wolai /我来云笔记在 2022.7.11 日的更新中,支持嵌入包括 NotionPet.芦笋.Replit 等在内的第三方应用.感谢 Wolai 云笔记官方对于 NotionPet 的支持. 趁 ...
- nginx发布vue 项目
在本次使用nginx发布vue项目遇到 配置location 始终404 和 在项目子目录点击浏览器刷新出现404问题 使用nginx发布vue项目,为了方便测试就下载了一个nginx 放置自己目录下 ...
- Cobalt Strike 连接启动教程(1)
第一步:把cobaltstrike4(解压后)拷贝到虚拟机Kali系统的root目录下 第二步:进入cobalstrike4文件夹中 第三步:选寻kali系统 IP地址 第四步: 启动服务端:(t ...
- 【rabbitMQ】-延迟队列-模拟控制智能家居的操作指令
这个需求为控制智能家居工作,把控制智能家居的操作指令发到队列中,比如:扫地机.洗衣机到指定时间工作 一.什么是延迟队列? 延迟队列存储的对象是对应的延迟消息,所谓"延迟消息" ...
- odoo开发教程九:Odoo10 API
一:纪录集API model中的数据是以集合的形式使用的,因此可以使用集合运算来操作. 集合运算符 record in set返回record是否在set中,record须为单条记录,record n ...