MAPREDUCE实践篇
1.编程规范
(1)用户编写的程序分成三个部分:Mapper,Reducer,Driver(提交运行mr程序的客户端)
(2)Mapper的输入数据是KV对的形式(KV的类型可自定义)
(3)Mapper的输出数据是KV对的形式(KV的类型可自定义)
(4)Mapper中的业务逻辑写在map()方法中
(5)map()方法(maptask进程)对每一个<K,V>调用一次
(6)Reducer的输入数据类型对应Mapper的输出数据类型,也是KV
(7)Reducer的业务逻辑写在reduce()方法中
(8)Reducetask进程对每一组相同k的<k,v>组调用一次reduce()方法
(9)用户自定义的Mapper和Reducer都要继承各自的父类
整个程序需要一个Drvier来进行提交,提交的是一个描述了各种必要信息的job对
2.wordcount示例编写
(1)定义一个mapper类
//首先要定义四个泛型的类型
//keyin: LongWritable valuein: Text
//keyout: Text valueout:IntWritable public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
//map方法的生命周期: 框架每传一行数据就被调用一次
//key : 这一行的起始点在文件中的偏移量
//value: 这一行的内容
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//拿到一行数据转换为string
String line = value.toString();
//将这一行切分出各个单词
String[] words = line.split(" ");
//遍历数组,输出<单词,1>
for(String word:words){
context.write(new Text(word), new IntWritable(1));
}
}
}
(2)定义一个reducer类
//生命周期:框架每传递进来一个kv 组,reduce方法被调用一次
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//定义一个计数器
int count = 0;
//遍历这一组kv的所有v,累加到count中
for(IntWritable value:values){
count += value.get();
}
context.write(key, new IntWritable(count));
}
}
(3)定义一个主类,用来描述job并提交job
public class WordCountRunner {
//把业务逻辑相关的信息(哪个是mapper,哪个是reducer,要处理的数据在哪里,输出的结果放哪里……)描述成一个job对象
//把这个描述好的job提交给集群去运行
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job wcjob = Job.getInstance(conf);
//指定我这个job所在的jar包
// wcjob.setJar("/home/hadoop/wordcount.jar");
wcjob.setJarByClass(WordCountRunner.class); wcjob.setMapperClass(WordCountMapper.class);
wcjob.setReducerClass(WordCountReducer.class);
//设置我们的业务逻辑Mapper类的输出key和value的数据类型
wcjob.setMapOutputKeyClass(Text.class);
wcjob.setMapOutputValueClass(IntWritable.class);
//设置我们的业务逻辑Reducer类的输出key和value的数据类型
wcjob.setOutputKeyClass(Text.class);
wcjob.setOutputValueClass(IntWritable.class); //指定要处理的数据所在的位置
FileInputFormat.setInputPaths(wcjob, "hdfs://hdp-server01:9000/wordcount/data/big.txt");
//指定处理完成之后的结果所保存的位置
FileOutputFormat.setOutputPath(wcjob, new Path("hdfs://hdp-server01:9000/wordcount/output/")); //向yarn集群提交这个job
boolean res = wcjob.waitForCompletion(true);
System.exit(res?0:1);
}
MAPREDUCE程序运行模式
本地运行模式
(1)mapreduce程序是被提交给LocalJobRunner在本地以单进程的形式运行
(2)而处理的数据及输出结果可以在本地文件系统,也可以在hdfs上
(3)怎样实现本地运行?写一个程序,不要带集群的配置文件(本质是你的mr程序的conf中是否有mapreduce.framework.name=local以及yarn.resourcemanager.hostname参数)
(4)本地模式非常便于进行业务逻辑的debug,只要在eclipse中打断点即可
如果在windows下想运行本地模式来测试程序逻辑,需要在windows中配置环境变量:
%HADOOP_HOME% = d:/hadoop-2.6.1
%PATH% = %HADOOP_HOME%/bin
并且要将d:/hadoop-2.6.1的
集群运行模式
(1)将mapreduce程序提交给yarn集群resourcemanager,分发到很多的节点上并发执行
(2)处理的数据和输出结果应该位于hdfs文件系统
(3)提交集群的实现步骤:
A、将程序打成JAR包,然后在集群的任意一个节点上用hadoop命令启动
$ hadoop jar wordcount.jar cn.itcast.bigdata.mrsimple.WordCountDriver inputpath outputpath
B、直接在linux的eclipse中运行main方法
(项目中要带参数:mapreduce.framework.name=yarn以及yarn的两个基本配置)
C、如果要在windows的eclipse中提交job给集群,则要修改YarnRunner类
mapreduce程序在集群中运行时的大体流程:

附:在windows平台上访问hadoop时改变自身身份标识的方法之二:
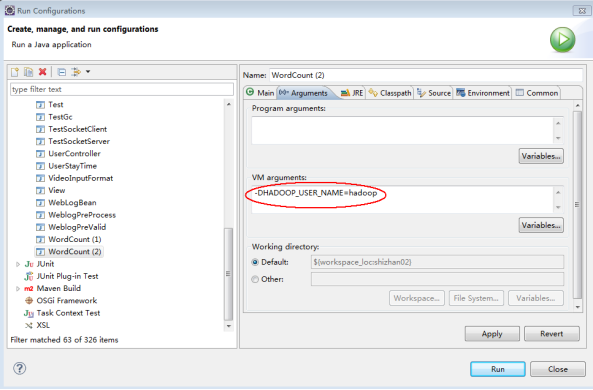
MAPREDUCE中的序列化
Java的序列化是一个重量级序列化框架(Serializable),一个对象被序列化后,会附带很多额外的信息(各种校验信息,header,继承体系。。。。),不便于在网络中高效传输;
所以,hadoop自己开发了一套序列化机制(Writable),精简,高效
Jdk序列化和MR序列化之间的比较
简单代码验证两种序列化机制的差别:
|
public class TestSeri { public static void main(String[] args) throws Exception { //定义两个ByteArrayOutputStream,用来接收不同序列化机制的序列化结果 ByteArrayOutputStream ba = new ByteArrayOutputStream(); ByteArrayOutputStream ba2 = new ByteArrayOutputStream();
//定义两个DataOutputStream,用于将普通对象进行jdk标准序列化 DataOutputStream dout = new DataOutputStream(ba); DataOutputStream dout2 = new DataOutputStream(ba2); ObjectOutputStream obout = new ObjectOutputStream(dout2); //定义两个bean,作为序列化的源对象 ItemBeanSer itemBeanSer = new ItemBeanSer(1000L, 89.9f); ItemBean itemBean = new ItemBean(1000L, 89.9f);
//用于比较String类型和Text类型的序列化差别 Text atext = new Text("a"); // atext.write(dout); itemBean.write(dout);
byte[] byteArray = ba.toByteArray();
//比较序列化结果 System.out.println(byteArray.length); for (byte b : byteArray) {
System.out.print(b); System.out.print(":"); }
System.out.println("-----------------------");
String astr = "a"; // dout2.writeUTF(astr); obout.writeObject(itemBeanSer);
byte[] byteArray2 = ba2.toByteArray(); System.out.println(byteArray2.length); for (byte b : byteArray2) { System.out.print(b); System.out.print(":"); } } } |
自定义对象实现MR中的序列化接口
如果需要将自定义的bean放在key中传输,则还需要实现comparable接口,因为mapreduce框中的shuffle过程一定会对key进行排序,此时,自定义的bean实现的接口应该是:
public class FlowBean implements WritableComparable<FlowBean>
需要自己实现的方法是:
|
/** * 反序列化的方法,反序列化时,从流中读取到的各个字段的顺序应该与序列化时写出去的顺序保持一致 */ @Override public void readFields(DataInput in) throws IOException { upflow = in.readLong(); dflow = in.readLong(); sumflow = in.readLong(); } /** * 序列化的方法 */ @Override public void write(DataOutput out) throws IOException { out.writeLong(upflow); out.writeLong(dflow); //可以考虑不序列化总流量,因为总流量是可以通过上行流量和下行流量计算出来的 out.writeLong(sumflow); } @Override public int compareTo(FlowBean o) { //实现按照sumflow的大小倒序排序 return sumflow>o.getSumflow()?-1:1; } |
MAPREDUCE中的Combiner
(1)combiner是MR程序中Mapper和Reducer之外的一种组件
(2)combiner组件的父类就是Reducer
(3)combiner和reducer的区别在于运行的位置:
Combiner是在每一个maptask所在的节点运行
Reducer是接收全局所有Mapper的输出结果;
(4) combiner的意义就是对每一个maptask的输出进行局部汇总,以减小网络传输量
具体实现步骤:
1、 自定义一个combiner继承Reducer,重写reduce方法
2、 在job中设置: job.setCombinerClass(CustomCombiner.class)
(5) combiner能够应用的前提是不能影响最终的业务逻辑
而且,combiner的输出kv应该跟reducer的输入kv类型要对应起来
MapReduce与YARN
YARN概述
Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而mapreduce等运算程序则相当于运行于操作系统之上的应用程序
YARN的重要概念
1、 yarn并不清楚用户提交的程序的运行机制
2、 yarn只提供运算资源的调度(用户程序向yarn申请资源,yarn就负责分配资源)
3、 yarn中的主管角色叫ResourceManager
4、 yarn中具体提供运算资源的角色叫NodeManager
5、 这样一来,yarn其实就与运行的用户程序完全解耦,就意味着yarn上可以运行各种类型的分布式运算程序(mapreduce只是其中的一种),比如mapreduce、storm程序,spark程序,tez ……
6、 所以,spark、storm等运算框架都可以整合在yarn上运行,只要他们各自的框架中有符合yarn规范的资源请求机制即可
7、 Yarn就成为一个通用的资源调度平台,从此,企业中以前存在的各种运算集群都可以整合在一个物理集群上,提高资源利用率,方便数据共享
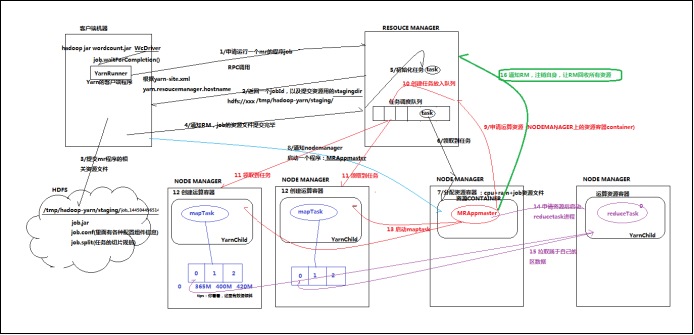
Yarn中运行运算程序的示例
mapreduce程序的调度过程,如下图
MAPREDUCE实践篇的更多相关文章
- Java 8 新特性——实践篇
Java 8 新特性--实践篇 参考 Java8新特性 重要更新:Lambda 表达式和Stream API Lambda 表达式 Lambda 表达式引入之前: 举个场景例子:当我们要对一个班级里的 ...
- Mapreduce的文件和hbase共同输入
Mapreduce的文件和hbase共同输入 package duogemap; import java.io.IOException; import org.apache.hadoop.co ...
- mapreduce多文件输出的两方法
mapreduce多文件输出的两方法 package duogemap; import java.io.IOException; import org.apache.hadoop.conf ...
- mapreduce中一个map多个输入路径
package duogemap; import java.io.IOException; import java.util.ArrayList; import java.util.List; imp ...
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- 软件工程(C编码实践篇)学习心得
孟繁琛 + 原创作品转载请注明出处 + <软件工程(C编码实践篇)>MOOC课程 http://mooc.study.163.com/course/USTC-1000002006 软件工程 ...
- [Hadoop in Action] 第5章 高阶MapReduce
链接多个MapReduce作业 执行多个数据集的联结 生成Bloom filter 1.链接MapReduce作业 [顺序链接MapReduce作业] mapreduce-1 | mapr ...
- MapReduce
2016-12-21 16:53:49 mapred-default.xml mapreduce.input.fileinputformat.split.minsize 0 The minimum ...
- 使用mapreduce计算环比的实例
最近做了一个小的mapreduce程序,主要目的是计算环比值最高的前5名,本来打算使用spark计算,可是本人目前spark还只是简单看了下,因此就先改用mapreduce计算了,今天和大家分享下这个 ...
- MapReduce剖析笔记之八: Map输出数据的处理类MapOutputBuffer分析
在上一节我们分析了Child子进程启动,处理Map.Reduce任务的主要过程,但对于一些细节没有分析,这一节主要对MapOutputBuffer这个关键类进行分析. MapOutputBuffer顾 ...
随机推荐
- N次剩余小记
前言 上周在 51nod 交了一些3.4级的题目,然后发现没有写过1级题, 就找到了一道 51nod 1014 \(X^2 \bmod P\) 的题目,当然这题虽然是暴力,但也可以用二次剩余做. 我就 ...
- #树套树,二维线段树#HDU 4819 Mosaic
题目 多组数据,给定一个\(n*n\)的矩阵(\(n\leq 80,a_{i,j}\leq 10^9\)) 多组询问一个以\((x,y)\)为中心,边长为\(L\)的子矩阵最大值\(mx\)和最小值\ ...
- HMS Core打造影音娱乐行业解决方案,助推视听新浪潮
6月28日,HDD·HMS Core. Sparkle影音娱乐线上沙龙在各大直播平台与开发者们见面.本次线上沙龙围绕影音娱乐行业现状观察和趋势.用户数据洞察分析以及HMS Core影音娱乐行业解决方案 ...
- Tailscale 的 TLS 证书过期,网站挂了 90 分钟!
3月7日,基于 WireGuard 的知名 VPN 厂商 Tailscale 的官方网站 tailscale.com 因 TLS 证书过期而中断服务约90分钟. 虽然影响有限,但这起事件还是在 Hac ...
- C#使用PaddleOCR进行图片文字识别✨
PaddlePaddle介绍 PaddlePaddle(飞桨)是百度开发的深度学习平台,旨在为开发者提供全面.灵活的工具集,用于构建.训练和部署各种深度学习模型.它具有开放源代码.高度灵活性.可扩展性 ...
- 为什么使用gs_probackup执行全量备份时,提示无法连接到数据库?
为什么使用 gs_probackup 执行全量备份时,提示无法连接到数据库? 背景介绍: 在使用 gs_probackup 执行全量备份时,提示无法连接到数据库. 报错内容: [ommdoc@host ...
- VMware Workstation之虚拟机NAT模式
[摘要] 三台虚拟机配置成NAT模式,实现三台虚拟机互通并可以访问互联网. 一.虚拟机配置为NAT,实现访问互联网和宿主机 1.虚拟网络编辑器配置 VMnat8为NAT的虚拟网卡,NAT模式可以基于D ...
- Vue3开源组件库
最近收到的很多问题都是关于Vue3组件库的问题 今天就给大家推荐几个基于Vue3重构的开源组件库 目前状态都处于Beta阶段,建议大家抱着学习的心态入场,勿急于用到生产环境 Ant-design-vu ...
- 嘉楠k210 多线程 点亮流水灯
from Maix import GPIO from fpioa_manager import fm import _thread import time fm.register(24, fm.fpi ...
- pyaudio音频录制python
python3.7不支持pyaudio pip在线安装 whl下载地址:https://github.com/intxcc/pyaudio_portaudio/releases 下载后使用pip离线安 ...