两个 RTX2070 super 显卡 可不可以通过 nvlink交换机 进行P2P通信 呢? (答案: 可以)
以前转载了一篇文章: https://www.cnblogs.com/devilmaycry812839668/p/12370685.html
对于里面的结果总感觉有所怀疑,于是斥巨资购入两个 技嘉 rtx2070super 显卡, (至于为啥不弄两个2080ti呢,因为才贵搞不定呢),然后又购入了一款七彩虹的RTX下的nvlink hub 也就是 nvlink 交换机。
环境如下:
操作系统:Ubuntu 18.04
主板:华硕z470-e
cpu:10700k
独立显卡:两个 技嘉2070super
nvlink hub: 七彩虹 (3 slots款)
查看显卡工作情况:

一切正常。
===========================================================
不安装nvlink情况:
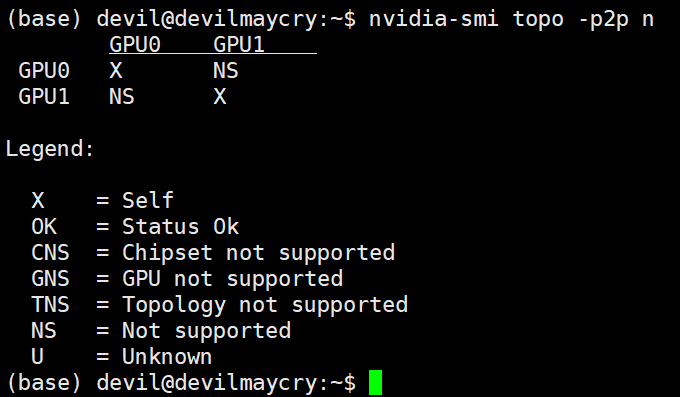
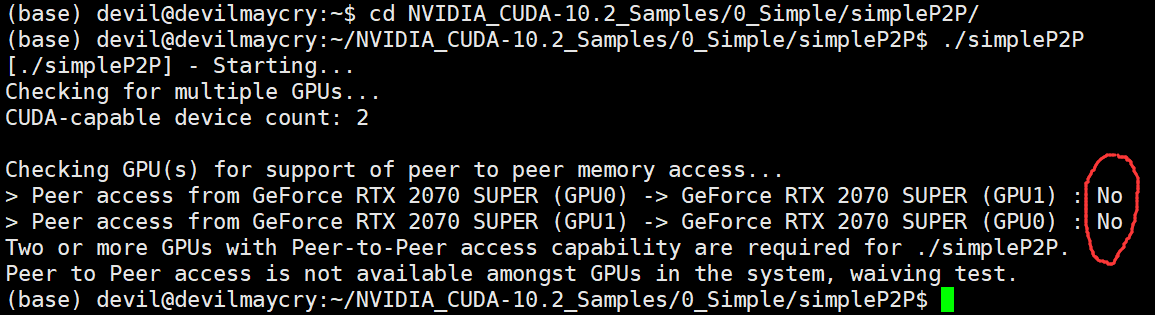
上面结果显示在不使用nvlink桥接器的情况下,Ubuntu系统环境中 两个 rtx2070super显卡无法实现P2P通信。
===========================================================
安装nvlink情况:

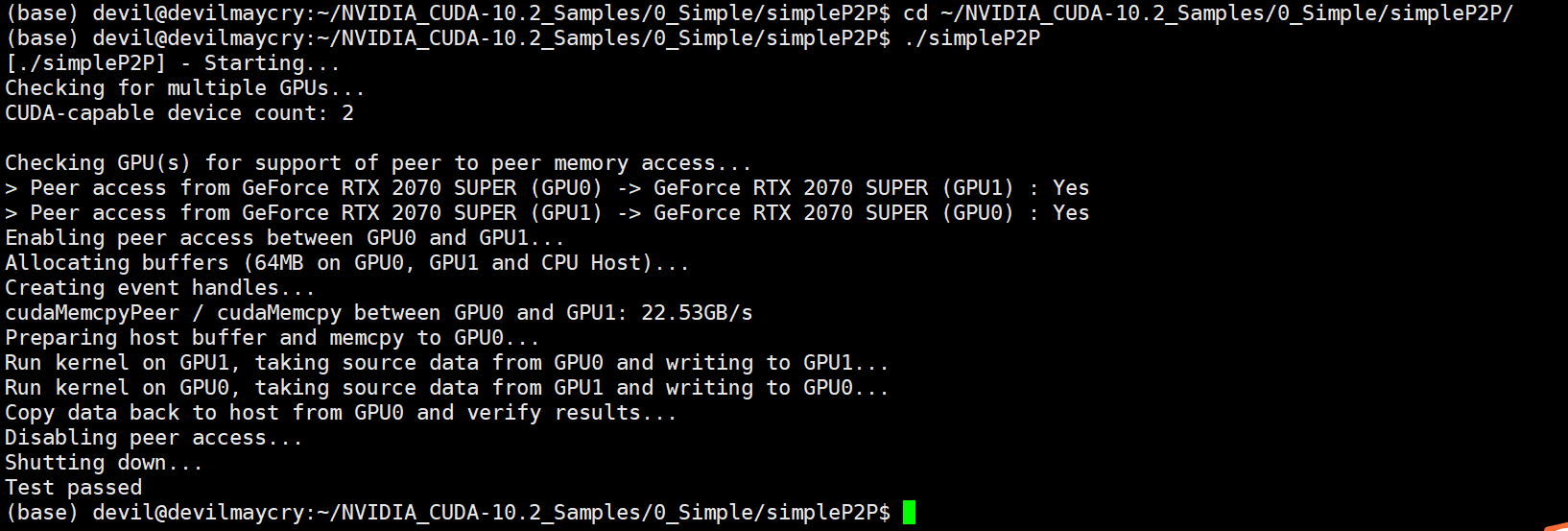
上面结果显示在使用nvlink桥接器的情况下,Ubuntu系统环境中 两个 rtx2070super显卡 可以实现P2P通信。
注:安装nvlink桥接器后,系统启动此时nvlink桥接器的工作灯是亮的(七彩虹的nvlink是有灯的,红色的),如果等没有亮说明该nvlink桥接器没有正常工作,此时需要确认一下nvlink桥接器安装的是否牢靠,有没有把插槽插到底。
网上查询到有个开启 TCC 计算模式的命令:
nvidia-smi -i 0 -dm TCC

可以看到,这此时这两个显卡开启TCC模式均失败,查资料发现rtx, gtx 显卡不支持TCC模式,只有泰坦之类的专业显卡才可以打开TCC模式,而且开启TCC模式需要这块显卡没有在执行显示任务才可以。
===========================================================
考虑到网上大部分利用nvlink桥接器的都是在windows环境下,于是改换在windows系统下进行测试:
开机进入系统后,打开NVIDIA的控制面板:

开启 SLI 功能, 如上图所示。
打开资源管理器,查看是否实现两个显卡同时工作:

发现成功可行,两个显卡利用率相同,并且利用率的波形变化图也相近似。
使用 nvidia-smi 命令查看:

发现两个显卡确实同时工作,实现了SLI功能,否则的话会有一个显卡利用率为 0 。
但是 由于不太会用 vs2019, 没有在windows平台上成功编译出 simpleP2P.exe 和 p2pBandwidthLatencyTest.exe 这两个P2P测速程序,因此这里就没有windows环境下的实测数值,具体P2P速度可以参考linux环境下的实测数值。(当然也就无法判断在windows环境下实现P2P功能是否需要开启sli,个人观点这两个功能应该是独立的,也就是说不开启sli也可以使用P2P功能)
-----------------------------------
原来以为在linux环境下要想使用nvlink桥接器组P2P需要至少三个独立显卡,两个相同的显卡组成P2P提供给计算任务使用,第三个显卡进行图像显示之用,实践后发现两个相同的支持sli的独立显卡就可以组成P2P, 当然在linux驱动中我们无法设置sli交火,也就是在linux系统中虽然两个显卡进行了nvlink桥接但是只能实现P2P功能而不能实现sli功能,因为linux驱动中并不能设置sli功能,两个显卡不能同时协同的进行显示任务,但是两个显卡在nvlink连接下可以协同进行计算任务。在windows环境下,要想实现P2P功能是否必须实现sli功能就不得而知了(个人观点可能windows系统下即使不开启sli功能也是可以进行P2P功能的,毕竟linux系统下没有sli功能也是可以P2P功能的),毕竟windows系统支持sli功能而linux系统不支持(linux下N卡的sli功能应该是不支持的,linux系统的NVIDIA控制面板中没有sli设置的选项)
linux系统和window系统下 nvlink 最大的不同,个人观点是window是环境下可以实现sli,也就是两个显卡同时负担显示任务,而在两个系统环境下计算任务应该都是相似的都可以实现P2P功能。
在 linux系统下,nvlink桥接器实现P2P功能,此时打开多个视频播放任务, 显卡工作如下:

发现, linux环境下,没有sli功能的nvlink桥接虽然实现了P2P功能但是不能实现sli功能,两个显卡只有主显卡进行显示任务,副显卡基本就没有工作,利用率为 0 。
而在 windows环境下 实现sli功能的nvlink桥接器,主副显卡同时为显示任务工作,利用率基本相同,不存在空闲显卡。
在本文所搭建的环境中,执行 p2pBandwidthLatencyTest 测速程序:
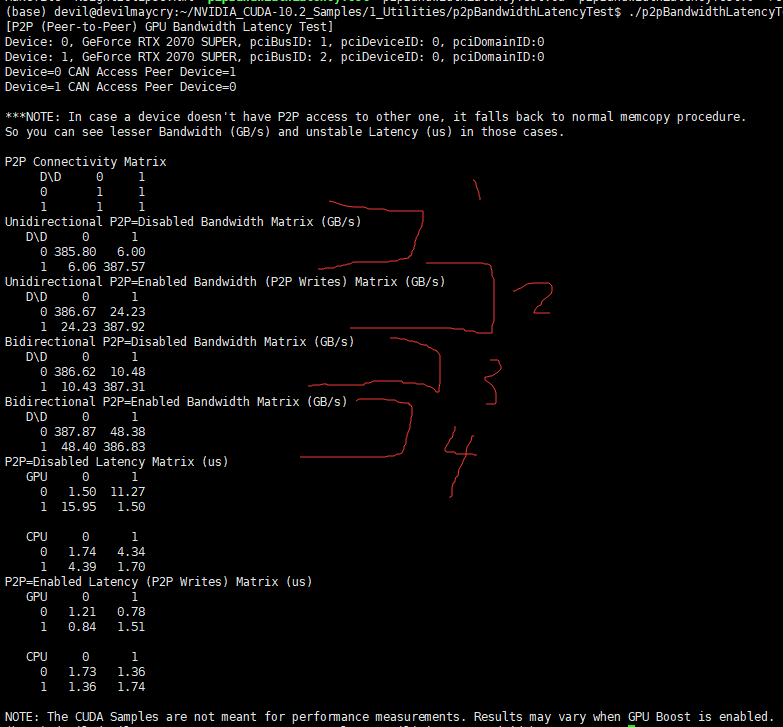
可以看到,PCIE的实际带宽 红色1部分 单向6GB/s, 红色3部分, 双向10.4GB/s , 与实际PCIE3.0*8的理论单向8GB/s ,双向16GB/s 还是有一定距离的。
但是通过NVLINK的P2P通信实测 单向24GB/s , 双向 48GB/s , 其表现还是不错的,虽然比显存内部带宽380GB/s的带宽还是差距很大的,但是比PCIE3.0*8以及*16速度要快不少,当然如果你这里使用的是专业级别显卡NVLINK的带宽可以达到300GB/s 甚至 600GB/s的带宽速度,这样就完全可以把多个显卡的内存当做是在一个显卡内部那样进行调用而不会有明显带宽瓶颈,本文主要是测试目的,由于资金限制也就只能进行消费级别的显卡测试。
下面的 bandwidthTest 测速程序也证明了 主机和GPU的访问带宽和GPU内部的访问带宽:

---------------------------------------
注:
PCIE3.0*16速度是多少?
PCIE3.0*16 通道单方向速度为16GB/s ,由于是全双工工作所以是两个方向的速度之和,也就是16GB/s * 2 = 32GB/s , 所以说PCIE3.0*16的全双工工作的速率为32GB/s 。(每个通道是两个方向的,双工工作所以是16GB/s*2)
频率 8 GT/s= 1GBps
编码效率为 128/130 bit
双工效率 2
通道数量 16
所以是 1* (128/130)* 2 *16 =31.5 GB/s ~32GB/s
从NVIDIA给出的官方数据可以了解到,RTX 2080Ti显卡支持两条NVLink通道,双向带宽可达100GB/s,而RTX 2080只支持一条通道,带宽为50GB/s。即便是一条NVLink通道,也要比主板PCI-Ex16的32GB/s的带宽数值大得多,如此大的带宽可以确保两块显卡之间的数据交换无碍,理论上可以让两块显卡都发挥出全部性能,实现1+1=2的效果。(此段源于 http://www.yxdown.com/hardware/346994.html)
一个通道的NVLINK是50GB/s(全双工,两个方向的情况),也就是说一条通道单方向的NVLINK速率为25GB/s 。
PCIE3.0*16 的速率是32GB/s (全双工,两个方向的情况) , 也就是说PCIE3.0*16单方向的的速率为16GB/s 。
RTX2080Ti 支持两条NVLINK通道,双向带宽为100GB/s, 单向带宽50GB/s, 而 RTX2080, RTX2070super 只支持一条通道,双向带宽为50GB/s, 单向通道为25GB/s 。
从上文的图中:
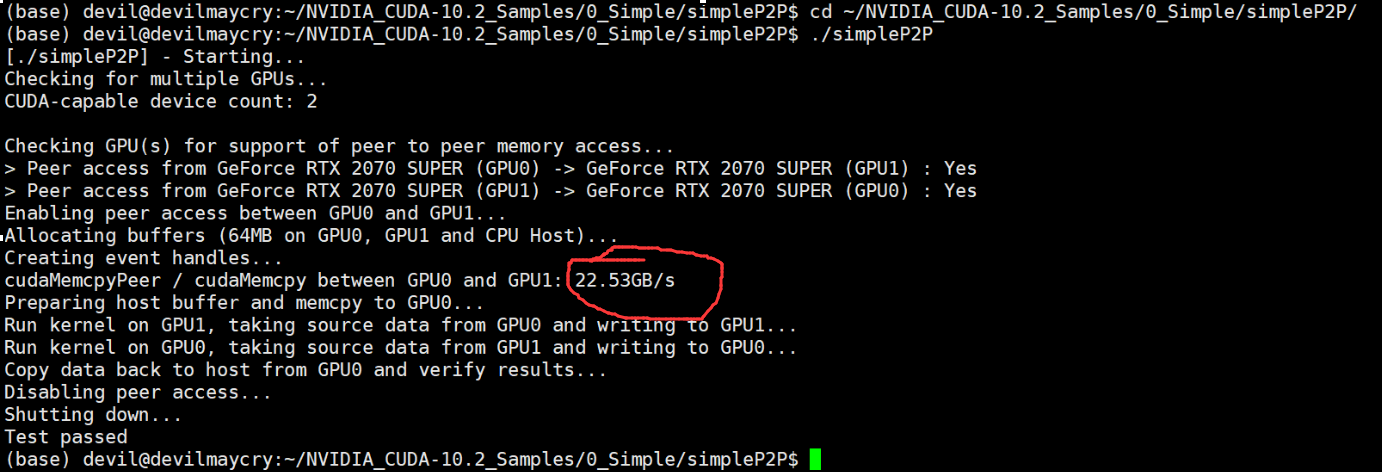
可以知道实际过程中2070super单方向的带宽实测为22.53GB/s , 虽然与理论的25GB/s有一定距离但是还算可以接受。
根据 http://www.gpus.cn/gpus_list_page_techno_support_content?id=30
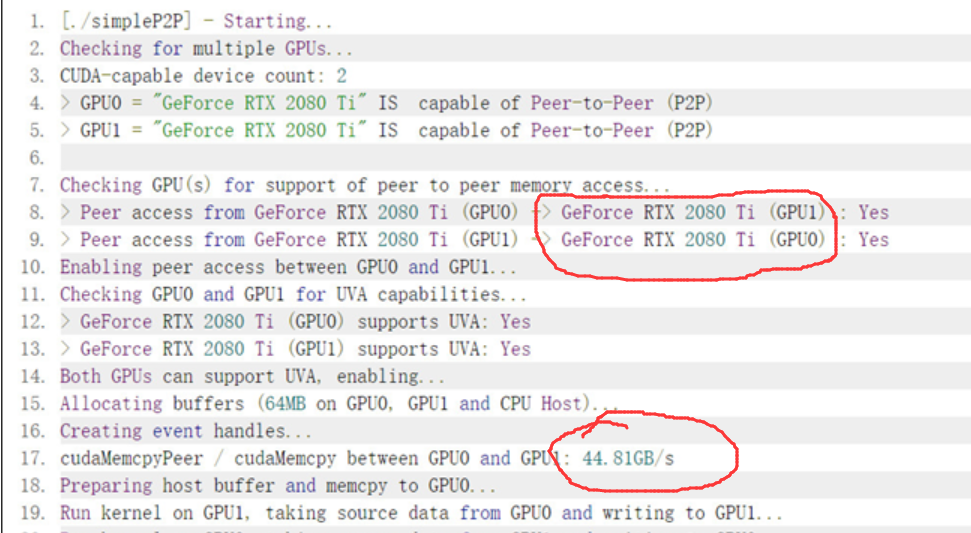
中的两个2080ti P2P实测速率单方向为44.8GB/s , 比理论的单方向带宽 50GB/s 也是存在一定距离, 不过正好是本文2070s的实测带宽的22.53GB/s的大致两倍,这也正好符合双通道和单通道的倍数之差。
文章 https://kheresy.wordpress.com/2019/03/05/nvidia-nvlink-on-geforce-rtx/
给出下面的测试结果:(两个 RTX 2080 Ti 显卡在nvlink下的表现)
p2pBandwidthLatencyTest.exe 测试

上图 1部分结果是单方向情况下 不利用P2P功能的时候 显卡间的带宽为 6.6GB/s 和 9.47GB/s , 显存自身的带宽为500GB/s 多一些。
上图 2部分 是单方向下 利用P2P功能显卡间的带宽为 46GB/s左右,和 rtx2080ti nvlink单方向理论带宽50GB/s 接近。
上图 3 部分 是双方向下 不利用P2P功能时候 显卡间带宽为 7.27GB/s 和 11.42GB/s。
PCIE3.0*16的理论单向带宽为16GB/s, 双向带宽为32GB/s, PCIE3.0*8的理论带宽为单方向8GB/s, 双方向16GB/s , 根据上图 1部分和3部分 可以大胆猜测显卡的插槽PCIE3.0的倍数应该是*8的。
上图4部分 是双方向 利用P2P功能的时候显卡间的带宽 大约为 90GB/s 和 rtx2080ti nvlink双方向理论带宽100GB/s 接近。
-------------------------------------------------------------
对于文章 https://zhuanlan.zhihu.com/p/46061343
NVLink工作在GeForce RTX 2080上和Quadro GP100上有区别吗?
中所说的有些内容并不是很认同, 上面这篇文章出现的比较早, 在本次测试中也多次参考这篇文章, 以下说一说自己不认同的地方和认同的地方:
不认同的地方:
无法打开GeForce RTX显卡的TCC模式,这意味着它们将不能“点对点”通信,而这是使用全功能NVLink的前提。-------首先TCC模式主要是指关闭了图形显示功能,一般都是泰坦等专业的计算显卡才可以开启的,但这并不意味着RTX显卡不能支持P2P通信, 经过上面的实测发现RTX显卡也是可以支持P2P功能的。
认同的地方:
RTX显卡即使支持P2P功能,显卡之间通信的带宽也大大受限。-------RTX显卡的P2P带宽确实没有专业显卡的P2P带宽大,不过但是还是可以的。
这篇文章给出了下面的测试结果:
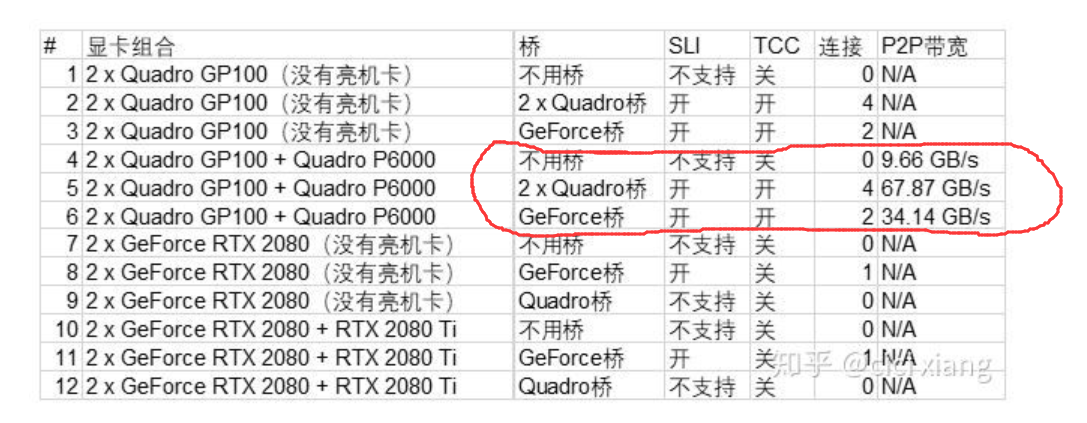
根据本文的实测我们知道 2080ti的P2P带宽为单向理论值50GB/s,实测为44.81GB/s, 2070super的P2P带宽理论单向带宽为25GB/s, 实测为22.53GB/s, 和专业显卡比起来还是可以凑合的, 而比PCIE3.0*16的理论单向带宽16GB/s 还是高上不少的,而且现在很多消费级别的主板两个显卡同时插上只能到达PCIE*8的带宽,这个带宽的理论值为单向8GB/s, 可以看到即使是2080, 2070super这样的单通道P2P显卡的实测带宽也是 PCIE*8的理论带宽的将近3倍(22.53GB/s, 8GB/s, 单方向)
而且 还有一点要说的就是 那篇文章有个 地方有些问题,那就是如果显卡不开TCC模式(当然RTX显卡不支持TCC模式),那么就不需要亮机卡,因为你的RTX显卡在进行P2P通信的同时由于不支持TCC模式所以仍然可以执行图形显示的任务, 也就是说用RTX显卡组成P2P通信是可以的,而且不需要亮机卡,重要的事情说三遍,不需要亮机卡,不需要亮机卡,不需要亮机卡(RTX显卡的情况下)。
在官方资料上可以看到: https://www.nvidia.cn/design-visualization/nvlink-bridges/
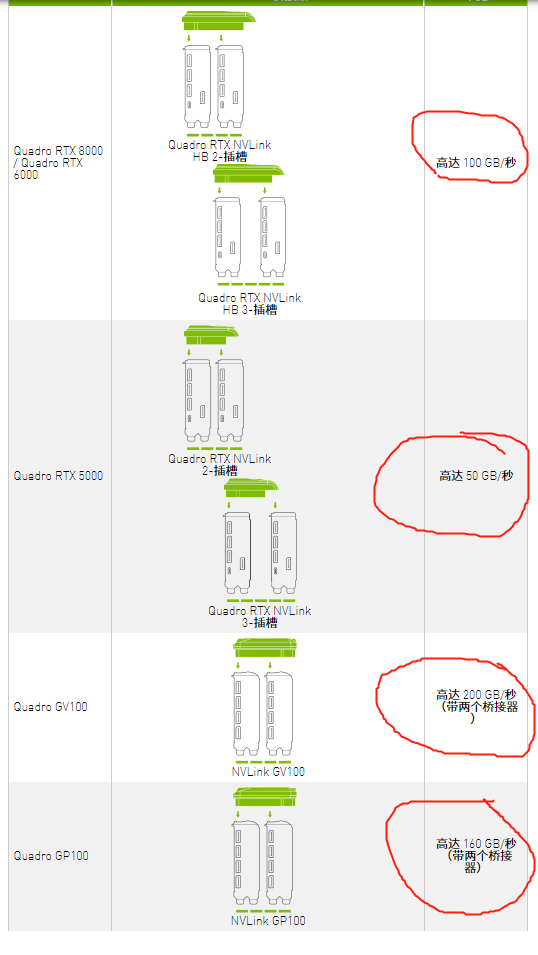
使用nvlink桥接器的话,两个显卡之间的速度分别可以为:
双向带宽: 单向带宽:
50GB/s 25GB/s
100GB/s 50GB/s
160GB/s 80GB/s
200GB/s 100GB/s
RTX2080Ti的双向带宽理论为100GB/s, RTX2080 和 RTX2070super 的理论双向带宽为50GB/s 。虽然比不了速度最高的显卡的200GB/s双向nvlink带宽,但是也不主板上的PCIE3.0*16 双向带宽32GB/s, PCIE3.0*8双向带宽16GB/s 要好上很多了, 当然这种P2P的通信模式虽然速率上去了但是还有一个就是每个显卡的显存是固定的而且远远小于主机内存, 两个显卡不访问主机内存的情况下两个显卡之间所能交换的数据量就是显存大小,这里2070super 为8G, 而我这主机内存最高可以安装128GB, 虽然主机内存和显存的交换要走PCIE要慢一些但是主机内存大,即使NVLINK速度再快显存的大小都难以匹敌主机内存,这样的话使用P2P通信的场景还是很有局限性的。
在 https://www.expreview.com/64042-8.html
NVIDIA为专业显卡、计算卡设计了全新的NVLink,而2016年发布的Tesla P100是首款搭载NVLink的产品,单个GPU具有160GB/s的带宽,相当于PCIe 3.0 ×16带宽的5倍。去年GTC 2017上发布的TeslaV100搭载的NVLink 2.0更是将GPU带宽提升到了300G/s(六通道),都快是PCIe 3.0 ×16的10倍。
--------------可以知道,原来TeslaV100 可以实现300GB/s的双通道带宽,确实速度很快,不过价格应该也是不菲呀。
---------------------------------------------------------
Quadro RTX 8000 显卡具体情况呢,下面文章给出了描述:
https://www.zhihu.com/question/364933644/answer/965561950
NVIDIA NVLink
使用高速互联技术连接2块GPU,以将显存容量扩展至96GB,并以高达100GB/秒的数据传输速度实现更高性能。
多 GPU 可扩展性
QUADRO RTX 8000 NVLINK HB 桥接器

----------------------------------

两个 RTX2070 super 显卡 可不可以通过 nvlink交换机 进行P2P通信 呢? (答案: 可以)的更多相关文章
- Java中的两个关键字——super、this
Java中的两个关键字——super.this 神话丿小王子的博客主页 一.super super 是java中方的一个关键字,用它可以引用父类中的成员: super可用于访问父类中定义的属性 sup ...
- 图解HTTP第一章
了解 Web 及网络基础 Web 页面是如何呈现的吗? Web 使用一种名为 HTTP(HyperText Transfer Protocol,超文本传输协议)的协议作为规范,完成从客户端到服务器端等 ...
- K8s 网络新手教程(Kubernetes Networking Guide for Beginners)
K8s 网络新手教程(Kubernetes Networking Guide for Beginners) 原文链接: Kubernetes Networking Guide for Beginner ...
- UE4的编程C++创建一个FPSproject(两)角色网格、动画、HUD、子弹类
立即归还,本文将总结所有这些整理UE4有关角色的网络格.动画.子弹类HUD一个简单的实现. (五)角色加入网格 Character类为我们默认创建了一个SkeletaMeshComponent组件,所 ...
- Linux 桌面玩家指南:11. 在同一个硬盘上安装多个 Linux 发行版以及为 Linux 安装 Nvidia 显卡驱动
特别说明:要在我的随笔后写评论的小伙伴们请注意了,我的博客开启了 MathJax 数学公式支持,MathJax 使用$标记数学公式的开始和结束.如果某条评论中出现了两个$,MathJax 会将两个$之 ...
- python 中的super()继承,搜索广度为先
一.python中类的继承 1.1 单继承 在python 中我们可以这样来定义一个类:及继承它的子类 class Father: def __init__(self, mes): #1 父类的ini ...
- [转帖]nvidia nvlink互联与nvswitch介绍
nvidia nvlink互联与nvswitch介绍 https://www.chiphell.com/thread-1851449-1-1.html 差不多在一个月前在年度gtc会议上,老黄公开了d ...
- Python中super的应用
约定 单继承 多继承 super 是个类 多继承中 super 的工作方式 参考资料 约定 在开始之前我们来约定一下本文所使用的 Python 版本.默认用的是 Python 3,也就是说:本文所定义 ...
- 面对对象二,super......反射
一.super() super() : 主动调用其他类的成员 # 单继承 # 在单继承中 super,主要是用来调用父类的方法的. class A: def __init__(self): self ...
- 【linux】【进程】stand alone 与 super daemon 区别
本文引用自 鸟哥的linux私房菜如果依据 daemon 的启动与管理方式来区分,基本上,可以将 daemon 分为可独立启动的 stand alone , 与透过一支 super daemon 来 ...
随机推荐
- Chapter1 p1 Output Image
由于本文章是对TinyRenderer的模仿,所以并不打算引入外部库. 那么我们第一步需要解决的就是图形输出的问题,毕竟,如果连渲染的结果都看不到,那还叫什么Renderer嘛. 由于不引入外部库,所 ...
- C# .NET 拉卡拉支付接口解析 付款码支付 条码支付
C# .NET 拉卡拉支付接口解析 付款码支付 条码支付 被扫 反扫 刷卡支付 B扫C. 简要: 1.测试环境给的私钥是PKCS8.签名用. 2.CRT证书用X509Certificate2 读取出 ...
- 2个线程交替输出A1B2C3......Z26
引言 经典多线程编程面试题 使用两个线程交替输出A1B2C3......Z26 实现方案1 public static void method2() throws InterruptedExcepti ...
- rabbitMq消息接收转换对象,Json解析字符串报错syntax error, expect {, actual string, pos 0, fastjson-version 1.2.62解决
Expected BEGIN_OBJECT but was STRING at line 1 column 2 path $ syntax error, expect {, actual string ...
- Pytest 失败重运行
需安装第三方插件:pytest-rerun.pytest-rerunfailures 失败重试和失败重运行的区别 失败重试:[--reruns=1],用例执行失败后,会立即开始重试一次此用例,再执行下 ...
- 配置阿里云yum源
CentOS6 rm -f /etc/yum.repos.d/* wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.co ...
- Linux 增加 swap 分区
检查当前swap分区 [root@localhost ~]# free -g total used free shared buffers cached Mem: 15 0 14 0 0 0 -/+ ...
- Nginx负载配置
目录 Nginx 负载均衡笔记 1. 概述 1.1 Nginx 简介 1.2 负载均衡概述 2. 四层负载均衡(传输层) 2.1 工作原理 2.2 特点 2.3 优缺点 优点 缺点 2.4 示例场景 ...
- 谈谈你对MVVM开发模式和MVT的理解?
MVVM分为Model.View.ViewModel三者. Model 代表数据模型,数据和业务逻辑都在Model层中定义: View 代表UI视图,负责数据的展示: ViewModel 负责监听 M ...
- Aspose 导出Excel时 隐藏指定列
Worksheet ws = wb.Worksheets[0]; ws.Cells.HideColumn(0); //隐藏Excel第一列