Jax计算框架的NamedSharding的reshape —— namedsharding-gives-a-way-to-express-shardings-with-names
本篇post的主要讲解的是:
jax.device_put(x, mesh_sharding(P(('a', 'b'), None)))
与
jax.device_put(x, mesh_sharding(P(('b', 'a'), None)))
的不同:
主机的四个CPU情况:
代码:
import os
import functools
from typing import Optional
import numpy as np
import jax
import jax.numpy as jnp
from jax.experimental import mesh_utils
from jax.sharding import PositionalSharding
# Create a Sharding object to distribute a value across devices:
sharding = PositionalSharding(mesh_utils.create_device_mesh((4,)))
# Create an array of random values:
x = jax.random.normal(jax.random.PRNGKey(0), (8192, 8192))
# and use jax.device_put to distribute it across devices:
y = jax.device_put(x, sharding.reshape(2, 2))
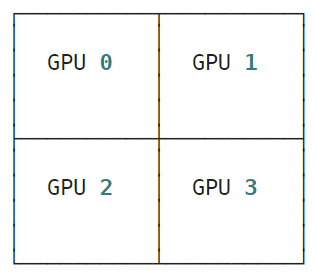
jax.debug.visualize_array_sharding(y)
运行结果:
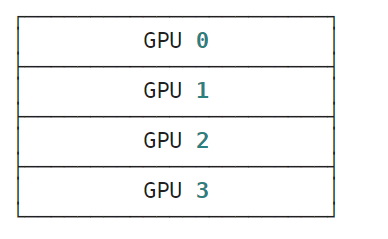
jax.device_put(x, mesh_sharding(P(('a', 'b'), None)))
代码:(行优先的方式展开GPU)
点击查看代码
from typing import Optional
import jax
from jax.sharding import Mesh
from jax.sharding import PartitionSpec
from jax.sharding import NamedSharding
from jax.experimental import mesh_utils
P = PartitionSpec
devices = mesh_utils.create_device_mesh((2, 2))
mesh = Mesh(devices, axis_names=('a', 'b'))
from jax.sharding import PositionalSharding
sharding = PositionalSharding(devices)
x = jax.random.normal(jax.random.PRNGKey(0), (8192, 8192))
x = jax.device_put(x, sharding.reshape(4, 1))
devices = mesh_utils.create_device_mesh((2, 2))
default_mesh = Mesh(devices, axis_names=('a', 'b'))
def mesh_sharding(
pspec: PartitionSpec, mesh: Optional[Mesh] = None,
) -> NamedSharding:
if mesh is None:
mesh = default_mesh
return NamedSharding(mesh, pspec)
y = jax.device_put(x, mesh_sharding(P(('a', 'b'), None)))
jax.debug.visualize_array_sharding(y)
运行结果:
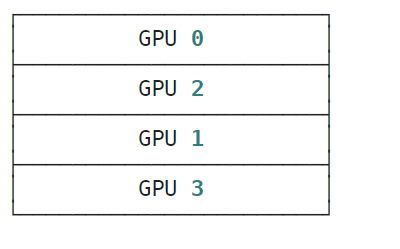
jax.device_put(x, mesh_sharding(P(('b', 'a'), None)))
代码:(列优先的方式展开GPU)
点击查看代码
from typing import Optional
import jax
from jax.sharding import Mesh
from jax.sharding import PartitionSpec
from jax.sharding import NamedSharding
from jax.experimental import mesh_utils
P = PartitionSpec
devices = mesh_utils.create_device_mesh((2, 2))
mesh = Mesh(devices, axis_names=('a', 'b'))
from jax.sharding import PositionalSharding
sharding = PositionalSharding(devices)
x = jax.random.normal(jax.random.PRNGKey(0), (8192, 8192))
x = jax.device_put(x, sharding.reshape(4, 1))
devices = mesh_utils.create_device_mesh((2, 2))
default_mesh = Mesh(devices, axis_names=('a', 'b'))
def mesh_sharding(
pspec: PartitionSpec, mesh: Optional[Mesh] = None,
) -> NamedSharding:
if mesh is None:
mesh = default_mesh
return NamedSharding(mesh, pspec)
y = jax.device_put(x, mesh_sharding(P(('b', 'a'), None)))
jax.debug.visualize_array_sharding(y)
运行结果:
Jax计算框架的NamedSharding的reshape —— namedsharding-gives-a-way-to-express-shardings-with-names的更多相关文章
- Storm分布式实时流计算框架相关技术总结
Storm分布式实时流计算框架相关技术总结 Storm作为一个开源的分布式实时流计算框架,其内部实现使用了一些常用的技术,这里是对这些技术及其在Storm中作用的概括介绍.以此为基础,后续再深入了解S ...
- Spark Streaming实时计算框架介绍
随着大数据的发展,人们对大数据的处理要求也越来越高,原有的批处理框架MapReduce适合离线计算,却无法满足实时性要求较高的业务,如实时推荐.用户行为分析等. Spark Streaming是建立在 ...
- Storm实时计算框架的编程模式
storm分布式流式计算框架. nimbus:主进程服务(职责就是任务的分配的,程序的分发) supervisor:工作进程服务(职责就是启动线程池,接受任务,运行任务,报告任务的运行状态) 注意容错 ...
- 开源图计算框架GraphLab介绍
GraphLab介绍 GraphLab 是由CMU(卡内基梅隆大学)的Select 实验室在2010 年提出的一个基于图像处理模型的开源图计算框架.框架使用C++语言开发实现. 该框架是面向机器学习( ...
- 大数据计算框架Hadoop, Spark和MPI
转自:https://www.cnblogs.com/reed/p/7730338.html 今天做题,其中一道是 请简要描述一下Hadoop, Spark, MPI三种计算框架的特点以及分别适用于什 ...
- (第4篇)hadoop之魂--mapreduce计算框架,让收集的数据产生价值
摘要: 通过前面的学习,大家已经了解了HDFS文件系统.有了数据,下一步就要分析计算这些数据,产生价值.接下来我们介绍Mapreduce计算框架,学习数据是怎样被利用的. 博主福利 给大家赠送一套ha ...
- Dream_Spark-----Spark 定制版:005~贯通Spark Streaming流计算框架的运行源码
Spark 定制版:005~贯通Spark Streaming流计算框架的运行源码 本讲内容: a. 在线动态计算分类最热门商品案例回顾与演示 b. 基于案例贯通Spark Streaming的运 ...
- 【流处理】Kafka Stream-Spark Streaming-Storm流式计算框架比较选型
Kafka Stream-Spark Streaming-Storm流式计算框架比较选型 elasticsearch-head Elasticsearch-sql client NLPchina/el ...
- 【codenet】代码相似度计算框架调研 -- 把内容与形式分开
首发于我的gitpages博客 https://helenawang.github.io/2018/10/10/代码相似度计算框架调研 代码相似度计算框架调研 研究现状 代码相似度计算是一个已有40年 ...
- Storm:分布式流式计算框架
Storm是一个分布式的.高容错的实时计算系统.Storm适用的场景: Storm可以用来用来处理源源不断的消息,并将处理之后的结果保存到持久化介质中. 由于Storm的处理组件都是分布式的,而且处理 ...
随机推荐
- 微博Lite版安装
微博Lite版安装 前置条件,需要使用chrome,或chromium内核的浏览器. 1.浏览器输入:https://m.weibo.cn/ 2.在地址栏最右侧点击安装. --
- win10 chrome 百分浏览器 centbrowser 收藏夹栏字体突然变小
win10 chrome 百分浏览器 centbrowser 收藏夹栏字体突然变小 解决方法: 在"开始" >"设置" >"轻松使用&qu ...
- Vue3:项目创建
Vue 3 相对于 Vue 2 带来了许多改进和优点,这些改进主要是为了提高性能.开发体验和可维护性.但是对于创建项目,Vue3也可以采用跟Vue2相同的方式. 使用CLI创建 1. 安装Vue CL ...
- 增补博客 第七篇 python 比较不同Python图形处理库或图像处理库的异同点
OpenCV.Pillow 和 scikit image OpenCV(OpenCV 是一个强大的计算机视觉库,它提供了各种图像处理和计算机视觉算法的实现,可以处理各种图像和视频数据. 异同点 跨平台 ...
- 基于 Swagger 增强 UI FytApi.MUI
FytApi.MUI 介绍 基于swagger的轻量级,注入化的api-ui组件 支持netcore 3.1/5.0/6.0 特点 零浸入.轻量.简单.好看.好用 可配置权限认证以及Header,支持 ...
- YUM退役了?DNF本地源配置
客户遇到在OEL8安装Oracle缺包问题,使用dnf安装也没有,甚至连oracle-database-preinstall-21c都装不上.本质是DNF配置问题. 早期为了解决这类问题,专门写过很多 ...
- notonlysuccess大神的线段树完全版
在大神的网站进不去的时候可以过来看看,另外道客巴巴有个排版比较好的文档,外观派可以去看看http://www.doc88.com/p-2728103209174.html 很早前写的那篇线段树专辑至今 ...
- 12-CentOS7安装与管理数据库mariadb
关于Mariadb Mariadb和MySQL是同一个制作团队,命令几乎一样. 在centos中安装 yum -y install mariadb mariadb-server firewall-cm ...
- float与byte[]互相转换
今天想利用socket发送数据,可是float类型该怎么发送呢?我的想法是先转换成byte[]型,接收之后再转换回来. float类型是4个字节,而byte是1个字节,所以需要转换成为byte[]的类 ...
- 使用AWS SageMaker进行机器学习项目
使用AWS SageMaker进行机器学习项目 本文主要介绍如何使用AWS SageMaker进行机器学习项目. 1. 题目 使用的题目为阿里天池的"工业蒸汽量预测",题目地址为: ...