最常用集合 - arraylist详解
ArrayList介绍
ArrayList实现了List接口,是顺序容器,即元素存放的数据与放进去的顺序相同,允许放入null元素,底层通过数组实现。除该类未实现同步外,其余跟Vector大致相同。每个ArrayList都有一个容量(capacity),表示底层数组的实际大小,容器内存储元素的个数不能多于当前容量。当向容器中添加元素时,如果容量不足,容器会自动增大底层数组的大小。
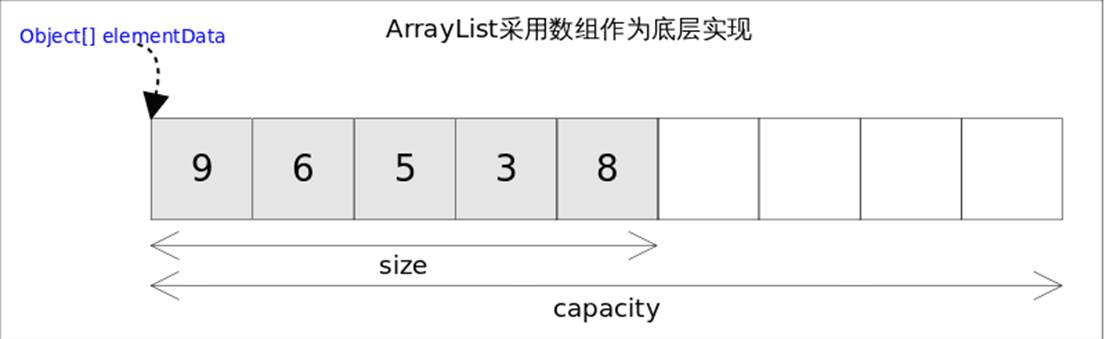
ArrayList 在JDK1.8 前后的实现区别:
- JDK1.7:像饿汉式,直接创建一个初始容量为10的数组
- JDK1.8:像懒汉式,一开始创建一个长度为0的数组,当添加add第一个元素时再创建一个初始容量为10的数组
size(), isEmpty(), get(), set()方法均能在常数时间内完成,add()方法的时间开销跟插入位置有关,addAll()方法的时间开销跟添加元素的个数成正比。其余方法大都是线性时间。
为追求效率,ArrayList没有实现同步(synchronized),如果需要多个线程并发访问,用户可以手动同步,也可使用Vector替代
底层原理介绍
底层数据结构
//集合默认容量10;
private static final int DEFAULT_CAPACITY = 10;
//空数组
private static final Object[] EMPTY_ELEMENTDATA = {};
//默认容量的空的数组
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
// 集合中真实存储数据的数组
transient Object[] elementData; // non-private to simplify nested class access
//集合中元素的个数,注意,这里不是数组的长度
private int size;
构造方法
public ArrayList() {
//将属性中默认的空的数组赋值给了 存储数据的变量
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
//等价于this.elementData = {}
}
//有参构造
public ArrayList(int initialCapacity) {
//给定初始容量,就创建一个这个容量大小的数组
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
//如果传递的是0 就将{}赋值给elementData
this.elementData = EMPTY_ELEMENTDATA;
//等价于this.elementData = {}
} else {
//如果传递的是负数,就会抛异常
//java.lang.IllegalArgumentException: Illegal Capacity: -20
throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity);
}
}
自动扩容
每当向数组中添加元素时,都要去检查添加后元素的个数是否会超出当前数组的长度,如果超出,数组将会进行扩容,以满足添加数据的需求。
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
//动态扩容,扩容为原来的1.5倍,右移一位即原来的一半
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
//判断新容量是否会超过最大限制
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);//数组的复制操作
}
扩容方法流程:
首先获取数组长度
将数组新容量扩容为原数组容量的1.5倍取整
将新容量和当前所需最小容量做对比,(最小容量是在add方法中得到的,minCapacity=size+1,即原数组中元素数量加1),而newCapacity=elementData.length*1.5,一般来说肯定是1.5倍比+1的大。但是这里要考虑当数组为空时的情况。数组为空又分为两种情况:①指定了数组容量为0 ②没有显式指定数组大小。
当数组为空时进行插入操作,因为元素个数size为0,数组容量也为0,那么就会进行扩容操作,对于空数组,扩容1.5倍后你的容量还是为0,那么此时就会小于我所需的最小容量(也就是1),此时会令 newCapacity = minCapacity;
而对于①,传入到grow方法的minCapacity = 1 ,因此它扩容后的容量就是1
对于②,在ensureCapacityInternal方法中,使minCapacity = DEFAULT_CAPACITY(10),因此扩容后的数组长度就是DEFAULT_CAPACITY,也就是10。
- 原因在于在有参构造方法中使this.elementData = EMPTY_ELEMENTDATA;(无参构造方法中this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;),此时在ensureCapacityInternal方法中会对this.elementData进行判断,因此对于①,传入到grow方法的minCapacity = 1;而对于②,minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity),即minCapacity = 10
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
//比较大小,此时 minCapacity = 10
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
- 最后判断新容量大小是否大于默认数组的最大值(Integer.MAX_VALUE-8),则赋予它整型的最大值
- 扩容之后,会调用Arrays.copyOf()方法对数组进行拷贝。
实际上,对数组的copy需要创建一个新数组,并对原数组进行复制的操作,这会造成资源消耗。因此在添加大量元素前,建议使用ensureCapacity操作先增加 ArrayList 实例的容量,先进行稍少量数组数据的copy,再添加元素
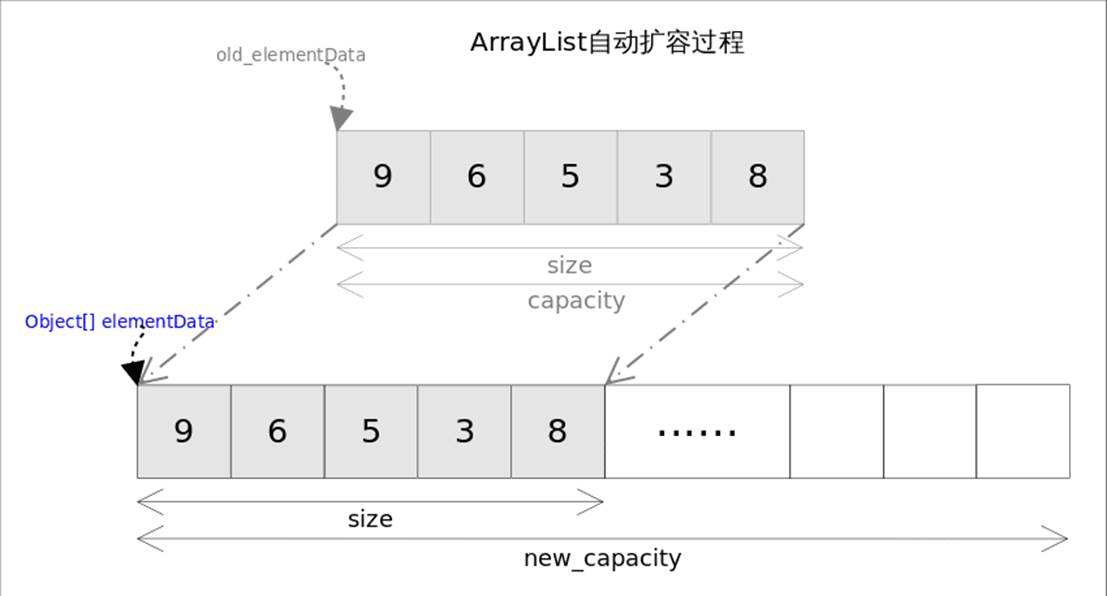
add(), addAll()
add 操作可能会导致capacity不足,因此在添加元素之前,都需要进行剩余空间检查,如果需要则自动扩容。扩容操作最终是通过grow()方法完成的。
假设使用的是空参构造,第一次添加元素 add(1)
public boolean add(E e) {
//确保内部容量 0 + 1
ensureCapacityInternal(size + 1); // Increments modCount!!
//将要添加的元素添加到数组有数据的下一个位置
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {//第一次添加: minCapacity = 1
//有参构造的情况:new Object[10] != {},不会执行if内的语句。即使有参构造给的是0,也不会执行,因为此时elementData = EMPTY_ELEMENTDATA,不等于DEFAULTCAPACITY_EMPTY_ELEMENTDATA
// 无参构造的情况下:{} = {} 会执行Math.max语句
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
//比较大小,此时 minCapacity = 10
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
//明确数组的容量
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;//记录当前集合操作的次数
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);//扩容操作
}
addAll()方法能够一次添加多个元素,根据位置不同也有两个版本,
在末尾添加的addAll(Collection<? extends E> c)方法,
从指定位置开始插入的addAll(int index, Collection<? extends E> c)方法
跟add()方法类似,在插入之前也需要进行空间检查,如果需要则自动扩容;如果从指定位置插入,也会存在移动元素的情况。 addAll()的时间复杂度不仅跟插入元素的多少有关,也跟插入的位置相关。
set()
由于底层是数组,因此set()方法就是直接对数组的指定位置赋值。
public E set(int index, E element) {
rangeCheck(index);//下标越界检查
E oldValue = elementData(index);
elementData[index] = element;//赋值到指定位置,复制的仅仅是引用
return oldValue;
}
get()
由于底层是数组,get()方法也是直接从数组索引处获取值,唯一要注意的是由于底层数组是Object[],得到元素后需要进行类型转换。
public E get(int index) {
rangeCheck(index);
return (E) elementData[index];//注意类型转换
}
remove方法
remove()方法也有两个
remove(int index)删除指定位置的元素,
remove(Object o)删除第一个满足o.equals(elementData[index])的元素。
删除操作是add()操作的逆过程,会需要将删除点之后的元素向前移动一个位置
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
//判断要删除的索引是否是最后一个,,如果不是最后一个,就需要进行数组的复制操作
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
//然后把最后一个元素置为空,让GC起作用
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
trimToSize()
将底层数组的容量调整为当前列表保存的实际元素的大小的功能
/**
* Trims the capacity of this <tt>ArrayList</tt> instance to be the
* list's current size. An application can use this operation to minimize
* the storage of an <tt>ArrayList</tt> instance.
*/
public void trimToSize() {
modCount++;
if (size < elementData.length) {
elementData = (size == 0)
? EMPTY_ELEMENTDATA
: Arrays.copyOf(elementData, size);
}
}
indexOf(), lastIndexOf()
获取元素的第一次出现的index:
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
获取元素的最后一次出现的index:
public int lastIndexOf(Object o) {
if (o == null) {
for (int i = size-1; i >= 0; i--)
if (elementData[i]==null)
return i;
} else {
for (int i = size-1; i >= 0; i--)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
遍历时删除(添加)常见陷阱
for循环遍历list
删除某个元素后,list的大小发生了变化,而索引也在变化,所以会导致遍历的时候漏掉某些元素。比如当删除第1个元素后,继续根据索引访问第2个元素时,因为删除的关系后面的元素都往前移动了一位,所以实际访问的是第3个元素。因此,这种方式可以用在删除特定的一个元素时使用,但不适合循环删除多个元素时使用。
for(int i=0;i<list.size();i++){
if(list.get(i).equals("del"))
list.remove(i);
}
解决办法:
//从list最后一个元素开始遍历
//从list最后一个元素开始遍历
for(int i=list.size()-1;i>+0;i--){
if(list.get(i).equals("del"))
list.remove(i);
}
增强for循环
删除元素后继续循环会抛异常java.util.ConcurrentModificationException,因为元素在使用的时候发生了并发的修改
for(String x:list){
if(x.equals("del"))
list.remove(x);
}
解决方法:但只能删除一个"del"元素
//解决:删除完毕马上使用break跳出,则不会触发报错
for(String x:list){
if (x.equals("del")) {
list.remove(x);
break;
}
}
iterator遍历
这种方式可以正常的循环及删除。但要注意的是,使用iterator的remove方法,如果用list的remove方法同样会报上面提到的ConcurrentModificationException错误。
Iterator<String> it = list.iterator();
while(it.hasNext()){
String x = it.next();
if(x.equals("del")){
it.remove();
}
}
FailFast机制
上面提到的ConcurrentModificationException异常,都是有这个机制的存在,通过记录modCount参数来实现。在面对并发的修改时,迭代器很快就会完全失败,而不是冒着在将来某个不确定时间发生任意不确定行为的风险。
fail-fast 机制是java集合(Collection)中的一种错误机制。当多个线程对同一个集合的内容进行操作时,就可能会产生fail-fast事件。例如:当某一个线程A通过iterator去遍历某集合的过程中,若该集合的内容被其他线程所改变了;那么线程A遍历集合时,即出现expectedModCount != modCount 时,就会抛出ConcurrentModificationException异常,产生fail-fast事件。
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
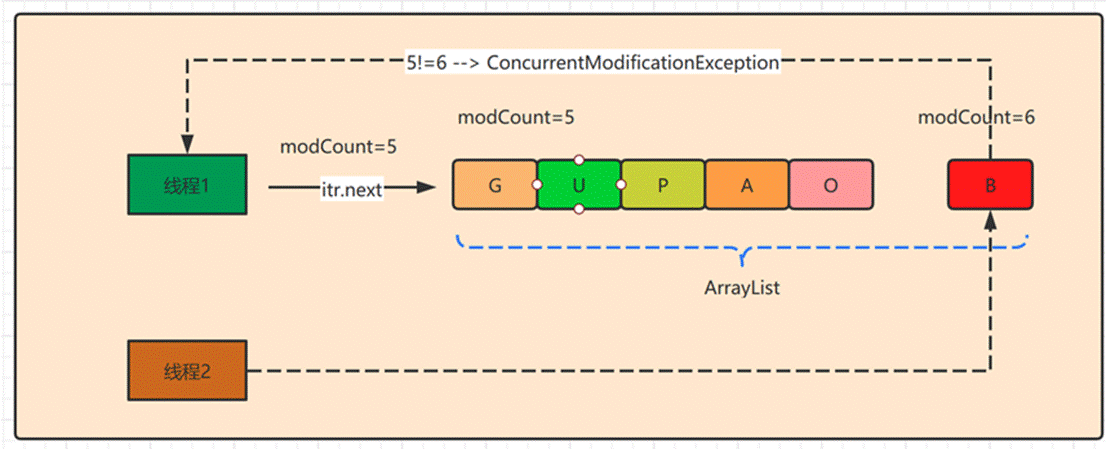
fail-fast 机制并不保证在不同步的修改下抛出异常,他只是尽最大努力去抛出,所以这种机制一般仅用于检测 bug
解决 fail-fast的解决方案:
- 在遍历过程中所有涉及到改变modCount值得地方全部加上synchronized或者直接使用Collections.synchronizedList,这样就可以解决(实际上Vector结构就是这样实现的)。但是不推荐,因为增删造成的同步锁可能会阻塞遍历操作。
List<Integer> arrsyn = Collections.synchronizedList(arr);
- 使用CopyOnWriteArrayList来替换ArrayList。推荐使用该方案。CopyOnWriteArrayList是兼顾了并发的线程安全
ArrayList和Vector和CopyOnWriteArrayList和LinkedList
继承关系结构图:
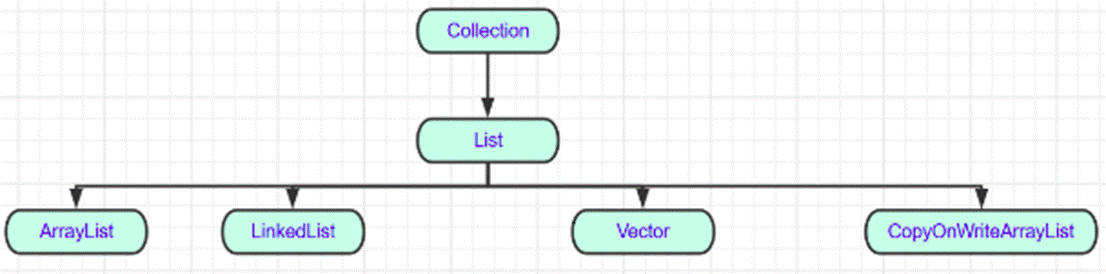
ArrayList和Vector和CopyOnWriteArrayList的区别:
ArrayList非线程安全的,如果需要考虑到线程安全问题,那么可以使用Vector和CopyOnWriteArrayList;
Vector和CopyOnWriteArrayList的区别是:Vector增删改查方法都加了synchronized,保证同步,但是每个方法执行的时候都要去获得锁,性能就会大大下降,而CopyOnWriteArrayList 只是在增删改上加锁,但是读不加锁,在读方面的性能就好于Vector,CopyOnWriteArrayList支持读多写少的并发情况。
ArrayList和LinkedList的区别:
ArrayList基于动态数组实现;
LinkedList基于链表实现。对于随机index访问的get和set方法,ArrayList的速度要优于LinkedList。因为ArrayList直接通过数组下标直接找到元素;LinkedList要移动指针遍历每个元素直到找到为止。
对于 add(int index, E element),remove(int index)的操作:LinkedList 和 ArrayList的时间复杂度一样,都是O(n);虽然时间复杂度一样,但实际执行时间是不一样的,如下代码所示:
List<Integer> a = Lists.newArrayList();
List<Integer> b = Lists.newLinkedList(); Random r = new Random();
a.add(0);
b.add(0); long startTime = System.currentTimeMillis();
for (int i = 0; i <= 20000; i++) {
int p = r.nextInt(a.size());
a.add(p, 0);
}
System.out.println(System.currentTimeMillis() - startTime);// 6 startTime = System.currentTimeMillis();
for (int i = 0; i <= 20000; i++) {
int p = r.nextInt(b.size());
b.add(p, 0);
}
System.out.println(System.currentTimeMillis() - startTime);// 205
虽然ArrayList在索引位置新增或删除数据时需要移动数据(往前移、往后移),但是在连续内存中的块的数据,是可以操作整片内存的。而LinkedList需要一个一个的先查找到具体索引位置的元素,所以在寻址方面数组的效率高于链表。
对于add新增元素:理论上来说LinkedList的速度(O(1))要优于ArrayList(O(n)),因为ArrayList在新增和删除元素时,可能会扩容和复制数组;LinkedList只需要修改指针即可。但在实际测试中,在数据量小的情况下,两者执行时间几乎一致;增大数据量后,就能看出区别了,如下代码所示:
List<Integer> a = Lists.newArrayList();
List<Integer> b = Lists.newLinkedList(); a.add(0);
b.add(0); long startTime = System.currentTimeMillis();
for (int i = 0; i <= 2000000; i++) {
int p = r.nextInt(a.size());
a.add(0);
}
System.out.println(System.currentTimeMillis() - startTime);// 34 startTime = System.currentTimeMillis();
for (int i = 0; i <= 2000000; i++) {
int p = r.nextInt(b.size());
b.add(0);
}
System.out.println(System.currentTimeMillis() - startTime);// 271
关于作者
来自一线程序员Seven的探索与实践,持续学习迭代中~
本文已收录于我的个人博客:https://www.seven97.top
公众号:seven97,欢迎关注~
最常用集合 - arraylist详解的更多相关文章
- 【集合框架】JDK1.8源码分析之ArrayList详解(一)
[集合框架]JDK1.8源码分析之ArrayList详解(一) 一. 从ArrayList字表面推测 ArrayList类的命名是由Array和List单词组合而成,Array的中文意思是数组,Lis ...
- java集合框架详解
java集合框架详解 一.Collection和Collections直接的区别 Collection是在java.util包下面的接口,是集合框架层次的父接口.常用的继承该接口的有list和set. ...
- Delphi中TStringList类常用属性方法详解
TStrings是一个抽象类,在实际开发中,是除了基本类型外,应用得最多的. 常规的用法大家都知道,现在来讨论它的一些高级的用法. 先把要讨论的几个属性列出来: 1.CommaText 2.Delim ...
- Java集合中List,Set以及Map等集合体系详解
转载请注明出处:Java集合中List,Set以及Map等集合体系详解(史上最全) 概述: List , Set, Map都是接口,前两个继承至collection接口,Map为独立接口 Set下有H ...
- Javascript常用的设计模式详解
Javascript常用的设计模式详解 阅读目录 一:理解工厂模式 二:理解单体模式 三:理解模块模式 四:理解代理模式 五:理解职责链模式 六:命令模式的理解: 七:模板方法模式 八:理解javas ...
- ArrayList详解-源码分析
ArrayList详解-源码分析 1. 概述 在平时的开发中,用到最多的集合应该就是ArrayList了,本篇文章将结合源代码来学习ArrayList. ArrayList是基于数组实现的集合列表 支 ...
- Eclipse或Myeclipse常用快捷键组合详解
Eclipse 是一个开放源代码的.基于Java的可扩展开发平台,就其本身而言,它只是一个框架和一组服务,用于通过插件组件构建开发环境.. Eclipse(Myeclipse)中有很多便于开发的快捷键 ...
- maven常用插件配置详解
常用插件配置详解Java代码 <!-- 全局属性配置 --> <properties> <project.build.name>tools</proje ...
- e lisp 常用缓冲区函数详解
e lisp 常用缓冲区函数详解 函数名 函数概要 buffer-name 返回当前缓冲区的名字 buffer-file-name 返回当前缓冲区所指文件的名字,包括路径 current-buffer ...
- 转:springmvc常用注解标签详解
Spring5:@Autowired注解.@Resource注解和@Service注解 - IT·达人 - 博客园--这篇顺序渐进,讲得超级好--此人博客很不错http://www.cnblogs.c ...
随机推荐
- TI AM62x工业核心板规格书(单/双/四核ARM Cortex-A53 + 单核ARM Cortex-M4F,主频1.4GHz)
1 核心板简介 创龙科技SOM-TL62x是一款基于TI Sitara系列AM62x单/双/四核ARM Cortex-A53 + 单核ARM Cortex-M4F异构多核处理器设计的高性能低功耗工业级 ...
- JavaSE 计算2个List集合中的交集、差集、并集、去重并集
VideoOrder.java 重写里面的equals和hashCode方法 class VideoOrder { private int price; private String title; p ...
- 历代iPhone及Android手机的屏幕参数对比
手机逻辑分辨率Point,也就是CSS像素,是进行网页适配的关键,以下是平时整理的一些备忘录数据,可以收藏. 屏幕清晰度分类 SD标清 HD高清(2倍屏) FHD全高清(3倍屏) QHD倍高清(4倍屏 ...
- SQL_left join 和from 两个表的区别
一个是普通的联接,结果中的记录在两个表中都有.一个是左外联接,结果中的记录在A表中存在,B表中不一定有.相当于a表为主体表,b为辅助表. 例子: mysql> select * from a;+ ...
- AT_arc041_b 题解
洛谷链接&Atcoder 链接 本篇题解为此题较简单做法及较少码量,并且码风优良,请放心阅读. 题目简述 给定一个 \(N \times M\) 的矩阵,此矩阵的每一个元素都向上.下.左.右 ...
- C#:SqlSugar中时间戳(TimeStamp)的使用
1.数据库建表 CREATE TABLE dbo.Test ( tId INT IDENTITY NOT NULL , tName NVARCHAR (20) NOT NULL , tSalary D ...
- 软件设计 软件设计模式之SOLID原则
软件设计模式之SOLID原则 By:授客 QQ:1033553122 #单一职责原则(SRP) 定义:任何一个软件模块都只对某一类行为者负责 说明:这里"软件模块",在大部分情况下 ...
- 使用 useRequestURL 组合函数访问请求URL
title: 使用 useRequestURL 组合函数访问请求URL date: 2024/7/26 updated: 2024/7/26 author: cmdragon excerpt: 摘要: ...
- Activity的创建
Activity的创建: 1.layout内写入相关代码 此处为显示的页面 2.Java内创建相关类写入代码 3.在清单内写入 快捷方法:直接完成上面步骤 layout: match_parent// ...
- NameCheap域名怎么样,如何注册购买域名?如何解析域名?
Namecheap介绍 Namecheap是一家国外域名注册商和网站托管公司,成立于2000年,提供域名注册.虚拟主机.电子邮件托管.SSL证书.免费的WHOIS保护.CDN.VPS主机和独立服务器. ...