Python递归函数和二分查找算法
递归函数:在一个函数里在调用这个函数本身。
递归的最大深度:998
正如你们刚刚看到的,递归函数如果不受到外力的阻止会一直执行下去。但是我们之前已经说过关于函数调用的问题,每一次函数调用都会产生一个属于它自己的名称空间,如果一直调用下去,就会造成名称空间占用太多内存的问题,于是python为了杜绝此类现象,强制的将递归层数控制在了997(只要997!你买不了吃亏,买不了上当...).
拿什么来证明这个“998理论”呢?这里我们可以做一个实验:
def foo(n):
print(n)
n += 1
foo(n)
foo(1)
由此我们可以看出,未报错之前能看到的最大数字就是998.当然了,997是python为了我们程序的内存优化所设定的一个默认值,我们当然还可以通过一些手段去修改它:
import sys
print(sys.setrecursionlimit(100000))
我们可以通过这种方式来修改递归的最大深度,刚刚我们将python允许的递归深度设置为了10w,至于实际可以达到的深度就取决于计算机的性能了。不过我们还是不推荐修改这个默认的递归深度,因为如果用997层递归都没有解决的问题要么是不适合使用递归来解决要么是你代码写的太烂了~~~
这里我们又要举个例子来说明递归能做的事情。
例一:
现在你们问我,alex老师多大了?我说我不告诉你,但alex比 egon 大两岁。
你想知道alex多大,你是不是还得去问egon?egon说,我也不告诉你,但我比武sir大两岁。
你又问武sir,武sir也不告诉你,他说他比太白大两岁。
那你问太白,太白告诉你,他18了。
这个时候你是不是就知道了?alex多大?
| 1 | 金鑫 | 18 |
| 2 | 武sir | 20 |
| 3 | egon | 22 |
| 4 | alex | 24 |
你为什么能知道的?
首先,你是不是问alex的年龄,结果又找到egon、武sir、太白,你挨个儿问过去,一直到拿到一个确切的答案,然后顺着这条线再找回来,才得到最终alex的年龄。这个过程已经非常接近递归的思想。我们就来具体的我分析一下,这几个人之间的规律。
age(4) = age(3) + 2
age(3) = age(2) + 2
age(2) = age(1) + 2
age(1) = 40
那这样的情况,我们的函数怎么写呢?
def age(n):
if n == 1:
return 40
else:
return age(n-1)+2 print(age(4))
二分查找算法:
如果有这样一个列表,让你从这个列表中找到66的位置,你要怎么做?
l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88]
你说,so easy!
l.index(66)...
我们之所以用index方法可以找到,是因为python帮我们实现了查找方法。如果,index方法不给你用了。。。你还能找到这个66么?
l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88] i = 0
for num in l:
if num == 66:
print(i)
i+=1
上面这个方法就实现了从一个列表中找到66所在的位置了。
但我们现在是怎么找到这个数的呀?是不是循环这个列表,一个一个的找的呀?假如我们这个列表特别长,里面好好几十万个数,那我们找一个数如果运气不好的话是不是要对比十几万次?这样效率太低了,我们得想一个新办法。
l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88]
你观察这个列表,这是不是一个从小到大排序的有序列表呀?
如果这样,假如我要找的数比列表中间的数还大,是不是我直接在列表的后半边找就行了?
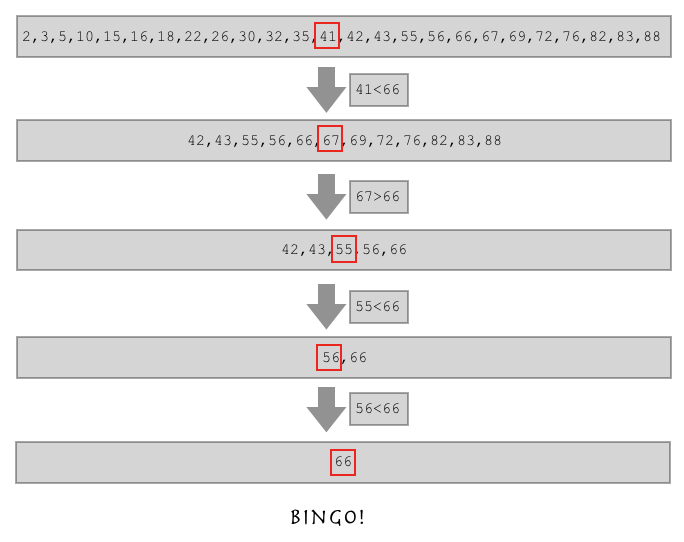
这就是二分查找算法!
那么落实到代码上我们应该怎么实现呢?
简单版二分法
l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72,76,82,83,88] def func(l,aim):
mid = (len(l)-1)//2
if l:
if aim > l[mid]:
func(l[mid+1:],aim)
elif aim < l[mid]:
func(l[:mid],aim)
elif aim == l[mid]:
print("bingo",mid)
else:
print('找不到')
func(l,66)
func(l,6)
升级版二分法
l1 = [1, 2, 4, 5, 7, 9]
def two_search(l,aim,start=0,end=None):
end = len(l)-1 if end is None else end
mid_index = (end - start) // 2 + start
if end >= start:
if aim > l[mid_index]:
return two_search(l,aim,start=mid_index+1,end=end) elif aim < l[mid_index]:
return two_search(l,aim,start=start,end=mid_index-1) elif aim == l[mid_index]:
return mid_index
else:
return '没有此值'
else:
return '没有此值'
print(two_search(l1,9))
Python递归函数和二分查找算法的更多相关文章
- python函数(4):递归函数及二分查找算法
人理解循环,神理解递归! 一.递归的定义 def story(): s = """ 从前有个山,山里有座庙,庙里老和尚讲故事, 讲的什么呢? ""& ...
- Python学习日记(十三) 递归函数和二分查找算法
什么是递归函数? 简单来说就是在一个函数中重复的调用自己本身的函数 递归函数在调用的时候会不断的开内存的空间直到程序结束或递归到一个次数时会报错 计算可递归次数: i = 0 def func(): ...
- 用Python实现的二分查找算法(基于递归函数)
一.递归的定义 1.什么是递归:在一个函数里在调用这个函数本身 2.最大递归层数做了一个限制:997,但是也可以自己限制 1 def foo(): 2 print(n) 3 n+=1 4 foo(n) ...
- Python——递归、二分查找算法
递归函数 1. 递归 (1)什么是递归:在函数中调用自身函数(2)最大递归深度:默认997/998——是Python从内存角度出发做的限制 n = 0 def story(): global n n+ ...
- python之路——二分查找算法
楔子 如果有这样一个列表,让你从这个列表中找到66的位置,你要怎么做? l = [2,3,5,10,15,16,18,22,26,30,32,35,41,42,43,55,56,66,67,69,72 ...
- python 递归函数和二分查找
1.初始递归 递归属于函数中的一种特殊函数,功能迅速并且干净利落,在函数中递归的基本就是在函数中调用自己本身 def func(): print(111) func() func()#将会无限循环‘1 ...
- Python递归函数,二分查找算法
目录 一.初始递归 二.递归示例讲解 二分查找算法 一.初始递归 递归函数:在一个函数里在调用这个函数本身. 递归的最大深度:998 正如你们刚刚看到的,递归函数如果不受到外力的阻止会一直执行下去.但 ...
- python实现二分查找算法
二分查找算法也成为折半算法,对数搜索算法,一会中在有序数组中查找特定一个元素的搜索算法.搜索过程是从数组中间元素开始的 如果中间元素正好是要查找的元素,则搜索过程结束:如果查找的数大于中间数,则在数组 ...
- 二分查找算法(Python版)
[本文出自天外归云的博客园] 记性不好(@.@),所以平时根本用不到的东西就算学过如果让我去想也会需要很多时间(*.*)! 二分查找算法 在一个有序数组中查找元素最快的算法,也就是折半查找法,先找一个 ...
随机推荐
- 【windows】win7 sp1 系统语言中英文切换
注:Windows 7 Ultimate and Windows 7 Enterprise (旗舰版和企业版) 可以直接在控制面板/地区和语言中修改显示语言,其他系统不行 进入网站下载相关的MUI包安 ...
- 谷歌放弃“不作恶” Alphabet要“遵守法律互相尊重”
对于一些谷歌粉而言,谷歌那条“不作恶(Don’t be evil)”的行为准则是他们引以为傲的精神信仰.这一准则于1999年被首次确认,谷歌在2004年申请上市时也提到了这一点.不过现在这一点要改变了 ...
- Python中类的声明,使用,属性,实例属性,计算属性及继承,重写
Python中的类的定义以及使用: 类的定义: 定义类 在Python中,类的定义使用class关键字来实现 语法如下: class className: "类的注释" 类的实体 ...
- python并发编程之进程2(管道,事件,信号量,进程池)
管道 Conn1,conn2 = Pipe() Conn1.recv() Conn1.send() 数据接收一次就没有了 from multiprocessing import Process,Pip ...
- (转)webView清除缓存
NSURLCache * cache = [NSURLCache sharedURLCache]; [cache removeAllCachedResponses]; [cache setDiskCa ...
- JAVA基础篇—抽象类,抽象方法
class Shape package com.shape; public abstract class Shape { double area;// double per;// String col ...
- LeetCode(292) Nim Game
题目 You are playing the following Nim Game with your friend: There is a heap of stones on the table, ...
- 【HIHOCODER 1181】欧拉路·二
描述 在上一回中小Hi和小Ho控制着主角收集了分散在各个木桥上的道具,这些道具其实是一块一块骨牌. 主角继续往前走,面前出现了一座石桥,石桥的尽头有一道火焰墙,似乎无法通过. 小Hi注意到在桥头有一张 ...
- 新线程 handler
class CalculateThread extends Thread { private Handler handler; @Override public void run() { super. ...
- Java判断浏览器是微信还是支付宝
private static final String WX_AGENT = "micromessenger"; private static final String ALI_A ...