spark RPC详解
前段时间看spark,看着迷迷糊糊的。最近终于有点头绪,先梳理了一下spark rpc相关的东西,先记录下来。
1,概述
个人认为,如果把分布式系统(HDFS, HBASE,SPARK等)比作一个人,那么RPC可以认为是人体的血液循环系统。它将系统中各个不同的组件(如Hbase中的master, Regionserver, client)联系了起来。同样,在spark中,不同组件像driver,executor,worker,master(stanalone模式)之间的通信也是基于RPC来实现的。
Spark 1.6之前,spark的RPC是基于Akaa来实现的。Akka是一个基于scala语言的异步的消息框架。Spark1.6后,spark借鉴Akka的设计自己实现了一个基于Netty的rpc框架。大概的原因是1.6之前,RPC通过Akka来实现,而大文件是基于netty来实现的,加之akka版本兼容性问题,所以1.6之后把Akka改掉了,具体jira见(https://issues.apache.org/jira/browse/SPARK-5293)。
本文主要对spark1.6之后基于netty新开发的rpc框架做一个较为深入的分析。
2,整体架构
spark 基于netty新的rpc框架借鉴了Akka的中的设计,它是基于Actor模型,各个组件可以认为是一个个独立的实体,各个实体之间通过消息来进行通信。具体各个组件之间的关系图如下(图片来自[1]):
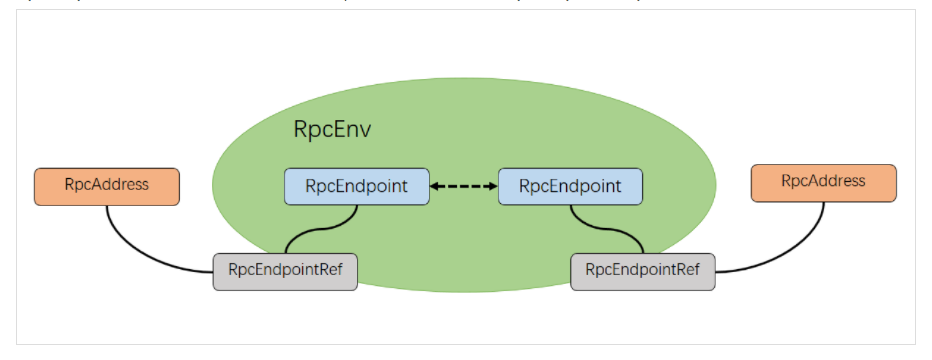
2.1 RpcEndpoint
表示一个个需要通信的个体(如master,worker,driver),主要根据接收的消息来进行对应的处理。一个RpcEndpoint经历的过程依次是:构建->onStart→receive→onStop。其中onStart在接收任务消息前调用,receive和receiveAndReply分别用来接收另一个RpcEndpoint(也可以是本身)send和ask过来的消息。
2.2 RpcEndpointRef
RpcEndpointRef是对远程RpcEndpoint的一个引用。当我们需要向一个具体的RpcEndpoint发送消息时,一般我们需要获取到该RpcEndpoint的引用,然后通过该应用发送消息。
2.3 RpcAddress
表示远程的RpcEndpointRef的地址,Host + Port。
2.4 RpcEnv
RpcEnv为RpcEndpoint提供处理消息的环境。RpcEnv负责RpcEndpoint整个生命周期的管理,包括:注册endpoint,endpoint之间消息的路由,以及停止endpoint。
3,实现
Rpc实现相关类之间的关系图如下(图片来自[2]):
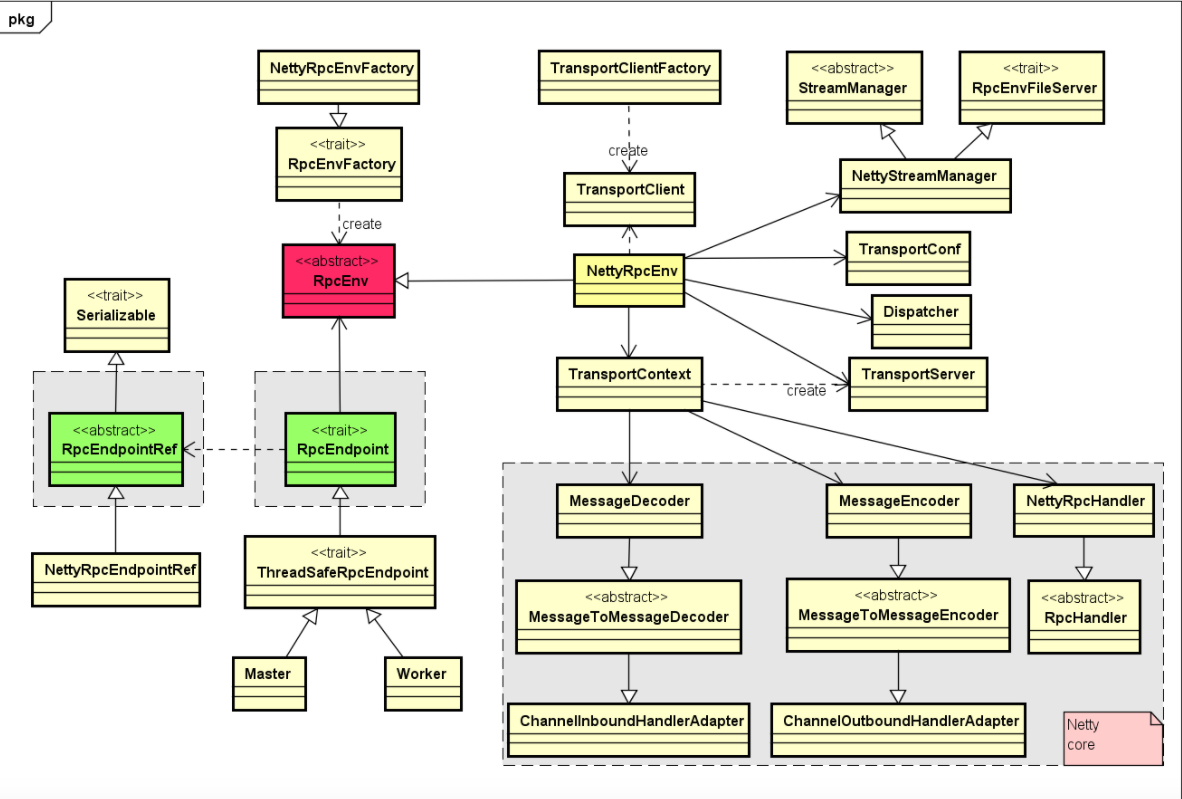
核心要点如下:
1,核心的RpcEnv是一个特质(trait),它主要提供了停止,注册,获取endpoint等方法的定义,而NettyRpcEnv提供了该特质的一个具体实现。
2,通过工厂RpcEnvFactory来产生一个RpcEnv,而NettyRpcEnvFactory用来生成NettyRpcEnv的一个对象。
3,当我们调用RpcEnv中的setupEndpoint来注册一个endpoint到rpcEnv的时候,在NettyRpcEnv内部,会将该endpoint的名称与其本省的映射关系,rpcEndpoint与rpcEndpointRef之间映射关系保存在dispatcher对应的成员变量中。
接下来,我们看一个具体的案例:在standalone模式中,worker会定时发心跳消息(SendHeartbeat)给master,那心跳消息是怎么从worker发送到master的呢,master又是怎么接收消息的?
1,在worker中,forwordMessageScheduler线程会定时每隔心跳超时时间的四分之一时间向自己发送SendHeartbeat消息,在worker的receive函数中,我们看到一旦接收到SendHeartbeat消息,worker会调用sendToMaster函数,将Heartbeat消息(包含worker Id和当前worker的rpcEndpoint引用)发送给master。

2,在worker的sendToMaster函数中,通过masterRef.send(message)将消息发送出去。那这个调用背后又做了什么事情呢?NettryRpcEnv中send的实现如下:

可以看到,当前发送地址(nettyEnv.address),目标的master地址(this)和发送的消息(SendHeartbeat)被封装成了RequestMessage消息,如果是远程rpc调用的话,最终send将调用postToOutbox函数,并且此时消息会被序列化成Byte流。

3,在postToOutbox函数中,消息将经过OutboxMessage中的sendWith方法(client.send(content)),最终通过TransportClient的send方法(client.send(content)),而在TransportClient中将消息进一步封装,然后发送给master。

4, 在master端TransportRequestHandler的handle方法中,由于心跳信息在worker端被分装成了OneWayMessage,所以在该handle方法中,将调用processOneWayMessage进行处理。

5,processOneWayMessage函数将调用rpcHandler的实现类NettyRpcEnv中的receive方法。在该方法中,首先通过internalRecieve将消息解包成RequestMessage。然后该消息通过dispatcher的分发给对应的endpoint。

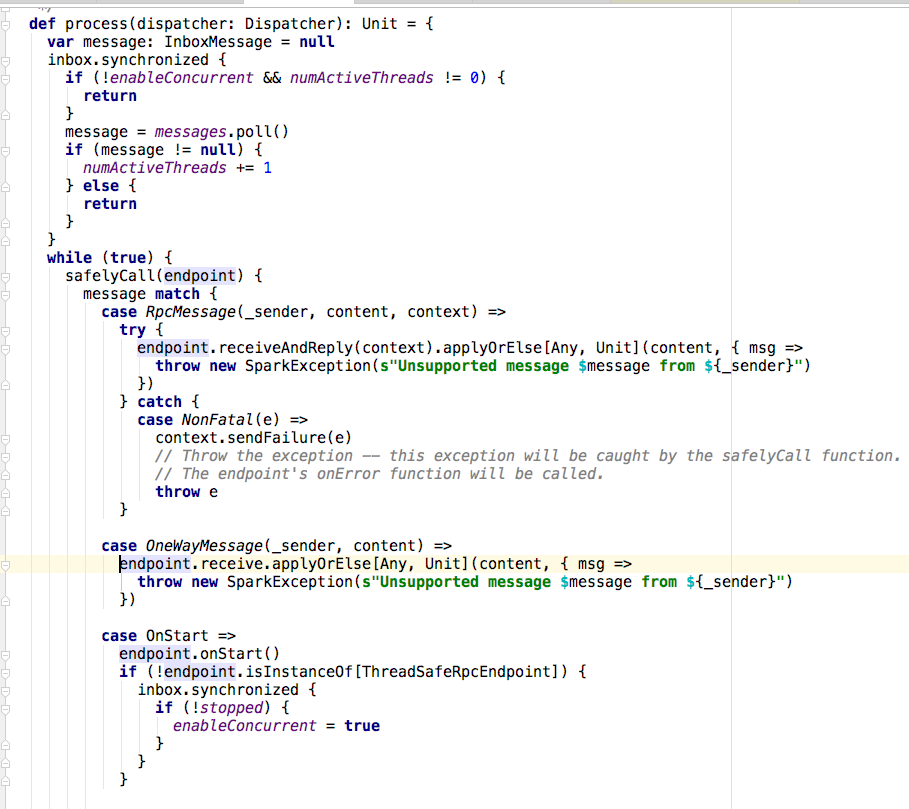
6,那消息是怎么分发的呢?在Dispatcher的postMessage方法中,可以看到,首先根据对应的endpoint的EndpointData信息(主要是该endpoint及其应用以及其信箱(inbox)),然后将消息塞到给endpoint(此例中的master)的信箱中,最后将消息塞到recievers的阻塞队列中。
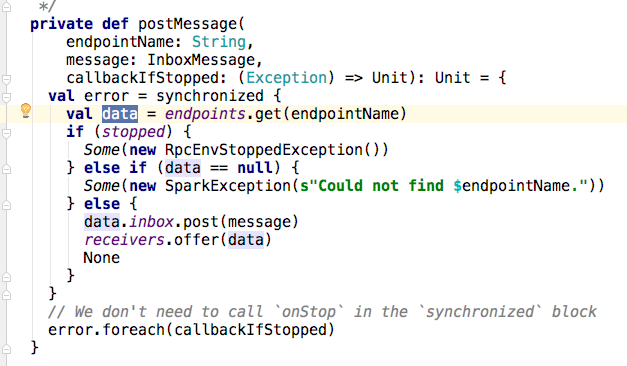
7,那队列中的消息是怎么被消费的呢?在Dispatcher中有一个线程池threadpool在MessageLoop类的run方法中,将receivers中的对象取出来,交由信箱的process方法去处理。如果没有收到任何消息,将会阻塞在take处。
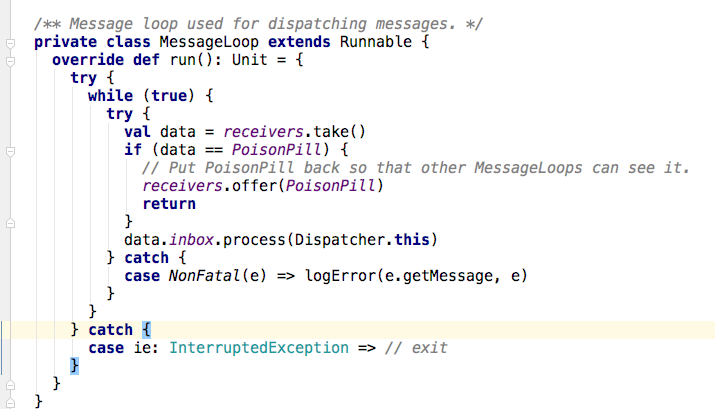
8,在inbox的proces方法中,首先取出消息,然后根据消息的类型(此例中是oneWayMessage),最终将调用endpoint的receiver方法进行处理(也就是master中的receive方法)。至此,整个一次rpc调用的流程结束。
4,小结
本文主要对rpc的历史,初始实现思想以及一次rpc的具体流程做了一个较为深入的分析。此外,对spark rpc实现涉及的一部分类也做了一个概括性说明。这也是一个开始,解下来,会陆续对spark的一些内部原理做较为深入的分析。
[1] https://wongxingjun.github.io/2016/12/08/Spark-RPC%E8%A7%A3%E8%AF%BB/
[2] http://shiyanjun.cn/archives/1545.html

spark RPC详解的更多相关文章
- Spark参数详解 一(Spark1.6)
Spark参数详解 (Spark1.6) 参考文档:Spark官网 在Spark的web UI在"Environment"选项卡中列出Spark属性.这是一个很有用的地方,可以检查 ...
- Spark:常用transformation及action,spark算子详解
常用transformation及action介绍,spark算子详解 一.常用transformation介绍 1.1 transformation操作实例 二.常用action介绍 2.1 act ...
- Spark框架详解
一.引言 作者:Albert陈凯链接:https://www.jianshu.com/p/f3181afec605來源:简书 Introduction 本文主要讨论 Apache Spark 的设计与 ...
- Spark中的Spark Shuffle详解
Shuffle简介 Shuffle描述着数据从map task输出到reduce task输入的这段过程.shuffle是连接Map和Reduce之间的桥梁,Map的输出要用到Reduce中必须经过s ...
- HUE配置文件hue.ini 的Spark模块详解(图文详解)(分HA集群和HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- hbase之RPC详解
Hbase的RPC主要由HBaseRPC.RpcEngine.HBaseClient.HBaseServer.VersionedProtocol 5个概念组成. 1.HBaseRPC是hbase RP ...
- RPC详解
RPC(Remote Procedure Call),即远程过程调用,是一个分布式系统间通信的必备技术,本文体系性地介绍了 RPC 包含的核心概念和技术,希望读者读完文章,一提到 RPC,脑中不是零碎 ...
- Spark 3.x Spark Core详解 & 性能优化
Spark Core 1. 概述 Spark 是一种基于内存的快速.通用.可扩展的大数据分析计算引擎 1.1 Hadoop vs Spark 上面流程对应Hadoop的处理流程,下面对应着Spark的 ...
- Apache Spark源码走读之13 -- hiveql on spark实现详解
欢迎转载,转载请注明出处,徽沪一郎 概要 在新近发布的spark 1.0中新加了sql的模块,更为引人注意的是对hive中的hiveql也提供了良好的支持,作为一个源码分析控,了解一下spark是如何 ...
随机推荐
- 集训Day5
生活还得继续 bzoj3771 题面让我笑了很长时间 给出 n个物品,价值为别为Xi且各不相同,现在可以取1个.2个或3个,问每种价值和有几种情况? *顺序不同算一种 很傻逼的一个母函数+容斥,用A( ...
- C++正确的cin输入
void test1(void) { int number; cout << ">> pls input a integer number:"; while ...
- HDU4348:To the moon
浅谈主席树:https://www.cnblogs.com/AKMer/p/9956734.html 浅谈标记永久化:https://www.cnblogs.com/AKMer/p/10137227. ...
- WPF架构分析
1.DisptcherObject提供了线程和并发模型,实现了消息系统. 2.DependencyObject提供了更改通知,实现了绑定,样式. 3.Visual是托管API和非托管API(milco ...
- Python之常用模块(一)
time & datatime 模块 random os sys shutil json & picle time & datetime 时间戳(1970年1月1日之后 ...
- Grunt:GruntFile.js
ylbtech-Grunt:GruntFile.js 1.返回顶部 1. module.exports = function (grunt) { grunt.initConfig({ useminPr ...
- 开发商应用被App Store拒绝的79个原因
转自:http://www.gamelook.com.cn/2014/10/186017 作为iOS开发者,估计有很多都遇到过APP提交到App Store被拒,然后这些被拒的原因多种多样,今天小编收 ...
- openStack vm备份
由于VM是可能存在于不同节点上,所以当一个计算节点挂掉后,可以把挂掉的节点运行的VM在新的节点上继续运行. 虽然快照功能可以做恢复使用,但是毕竟快照只能恢复固定时间的VM,所以虚拟机备份很重要!对做好 ...
- JSP环境探针-当前电脑所有系统参数
1 <%@ page contentType="text/html;charset=gb2312" %> <%@ page import="java.u ...
- Promise API
Promise API 刚刚接触promise这个东西,网上看了很多博客,大部分是讲怎么用Promise,丝毫没提怎么实现Promise. 我不甘 心,可是真去看JQuery或者Angular ...