SQLite3 of python
SQLite3 of python
一、SQLite3 数据库
SQLite3 可使用 sqlite3 模块与 Python 进行集成,一般 python 2.5 以上版本默认自带了sqlite3模块,因此不需要用户另外下载。
在 学习基本语法之前先来了解一下数据库是使用流程吧 ↓↓↓
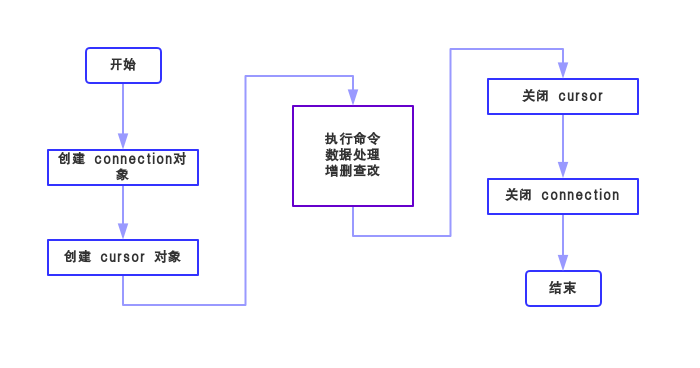
所以,首先要创建一个数据库的连接对象,即connection对象,语法如下:
sqlite3.connect(database [,timeout,其他可选参数])
function: 此API打开与SQLite数据库文件的连接。如果成功打开数据库,则返回一个连接对象。
database: 数据库文件的路径,或 “:memory:” ,后者表示在RAM中创建临时数据库。
timeout: 指定连接在引发异常之前等待锁定消失的时间,默认为5.0(秒)
有了connection对象,就能创建游标对象了,即cursor对象,如下:
connection.cursor([cursorClass])
function: 创建一个游标,返回游标对象,该游标将在Python的整个数据库编程中使用。
接下来,看看connection对象 和 cursor对象的 “技能” 吧 ↓↓↓
| 方法 | 说明 |
| connect.cursor() | 上述,返回游标对象 |
| connect.execute(sql [,parameters]) | 创建中间游标对象执行一个sql命令 |
| connect.executemany(sql [,parameters]) | 创建中间游标对象执行一个sql命令 |
| connect.executescript(sql_script) | 创建中间游标对象, 以脚本的形式执行sql命令 |
| connect.total_changes() | 返回自打开数据库以来,已增删改的行的总数 |
| connect.commit() | 提交当前事务,不使用时为放弃所做的修改,即不保存 |
| connect.rollback() | 回滚自上次调用commit()以来所做的修改,即撤销 |
| connect.close() | 断开数据库连接 |
| 方法 | 说明 |
| cursor.execute(sql [,parameters]) | 执行一个sql命令 |
| cursor.executemany(sql,seq_of_parameters) | 对 seq_of_parameters 中的所有参数或映射执行一个sql命令 |
| cursor.executescript(sql_script) | 以脚本的形式一次执行多个sql命令 |
| cursor.fetchone() | 获取查询结果集中的下一行,返回一个单一的序列,当没有更多可用的数据时,则返回 None。 |
| cursor.fetchmany([size=cursor.arraysize]) | 获取查询结果集中的下一行组,返回一个列表。当没有更多的可用的行时,则返回一个空的列表。size指定特定行数。 |
| cursor.fetchall() | 获取查询结果集中所有(剩余)的行,返回一个列表。当没有可用的行时,则返回一个空的列表。 |
下面用一个简单实例作为介绍 >>>
- def SQLite_Test():
- # =========== 连接数据库 ============
- # 1. 连接本地数据库
- connectA = sqlite3.connect("example.db")
- # 2. 连接内存数据库,在内存中创建临时数据库
- connectB = sqlite3.connect(":memory:")
- # =========== 创建游标对象 ============
- cursorA = connectA.cursor()
- cursorB = connectB.cursor()
- # =========== 创建表 ============
- cursorA.execute("CREATE TABLE class(id real, name text, age real, sex text)")
- cursorB.execute("CREATE TABLE family(relation text, job text, age real)")
- # =========== 插入数据 ============
- cursorA.execute("INSERT INTO class VALUES(1,'Jock',8,'M')")
- cursorA.execute("INSERT INTO class VALUES(2,'Mike',10,'M')")
- # 使用 ? 占位符
- cursorA.execute("INSERT INTO class VALUES(?,?,?,?)", (3,'Sarah',9,'F'))
- families = [
- ['Dad', 'CEO', 35],
- ['Mom', 'singer', 33],
- ['Brother', 'student', 8]
- ]
- cursorB.executemany("INSERT INTO family VALUES(?,?,?)",families)
- # =========== 查找数据 ============
- # 使用 命名变量 占位符
- cursorA.execute("SELECT * FROM class WHERE sex=:SEX", {"SEX":'M'})
- print("TABLE class: >>>select Male\n", cursorA.fetchone())
- cursorA.close()
- cursorB.execute("SELECT * FROM family ORDER BY relation")
- print("TABLE family:\n", cursorB.fetchall())
- cursorB.close()
- # =========== 断开连接 ============
- connectA.close()
- connectB.close()
- SQLite_Test()
运行结果:
TABLE class: >>>select Male
(1.0, 'Jock', 8.0, 'M')
TABLE family:
[('Brother', 'student', 8.0), ('Dad', 'CEO', 35.0), ('Mom', 'singer', 33.0)]
二、小练手
使用目前学的sqlite3数据库知识,对一些数据进行增删查改的操作。此处选择来自下面网站的数据
先将数据从网站上爬取下来,存储为csv文件,然后再保存到数据库中,接着进行数据的操作。对于如何存储为csv文件,请查看 >>> 《此处的最后一个小主题》
对于本次小练习的介绍:
目的:对已爬取的数据进行数据库管理和简单操作
步骤: 创建数据库文件 >>> 创建表 >>> 保存数据到数据库 >>> 对数据进行简单操作
方法:我采用的方法是:
① 编写一个函数( get_data(fileName) ):读取csv文件中的数据,主要完成对数据的格式转换,以便适合保存到数据库中
② 编写一个函数类( class SQL_method ):对数据库进行简单操作,主要完成数据库的创建和数据的增删查改
| 方法 | 说明 |
| __init__(self, dbName, tabelName, data, columns, COLUMNS, Read_All=True) | 对参数进行初始化,参数含义分别为:数据库名称、表格名称、数据、表格首行(用于创建表)、表格首行(用于格式输出)、输出所有数据(插入数据后) |
| creatTable(self) | 创建数据库文件、创建表格 |
| destroyTable(self) | 删除表格 |
| insertDatas(self) | 向数据库的表格中插入多条数据 |
| getAllData(self) | 以列表形式返回数据库表格中的所有数据 |
| searchData(self, condition, IfPrint=True) | 查找特定数据, 参数的含义分别为:查找条件、是否输出(查找的数据) |
| deleteData(self, condition) | 在数据库的表格中删除特定数据, 参数为删除条件 |
| printData(self, data) | 输出数据, 参数为需要输出的数据 |
| run(self) | 运行创建数据库和表格的函数,同时支持输出所有数据(依靠Read_All) |
③ 尝试其他操作 ( 以下的所有操作均在 main 函数中实现 ):
a. 在数据库中查找某一项记录
b. 对数据按照某种排序输出
c. 对数据进行增加权值操作,实现重新排序 【权值详情】
d. 删除数据库中的某些记录
e. 删除数据库中的表
好了,有了前进的方向,那我们杨帆 ----- 起航 >>>
- # -*- coding: utf-8 -*-
- '''
- 使用 url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html" 的数据进行SQLite3数据库的练习使用
- @author: bpf
- '''
- import sqlite3
- from pandas import DataFrame
- import re
- class SQL_method:
- '''
- function: 可以实现对数据库的基本操作
- '''
- def __init__(self, dbName, tableName, data, columns, COLUMNS, Read_All=True):
- '''
- function: 初始化参数
- dbName: 数据库文件名
- tableName: 数据库中表的名称
- data: 从csv文件中读取且经过处理的数据
- columns: 用于创建数据库,为表的第一行
- COLUMNS: 用于数据的格式化输出,为输出的表头
- Read_All: 创建表之后是否读取出所有数据
- '''
- self.dbName = dbName
- self.tableName = tableName
- self.data = data
- self.columns = columns
- self.COLUMNS = COLUMNS
- self.Read_All = Read_All
- def creatTable(self):
- '''
- function: 创建数据库文件及相关的表
- '''
- # 连接数据库
- connect = sqlite3.connect(self.dbName)
- # 创建表
- connect.execute("CREATE TABLE {}({})".format(self.tableName, self.columns))
- # 提交事务
- connect.commit()
- # 断开连接
- connect.close()
- def destroyTable(self):
- '''
- function: 删除数据库文件中的表
- '''
- # 连接数据库
- connect = sqlite3.connect(self.dbName)
- # 删除表
- connect.execute("DROP TABLE {}".format(self.tableName))
- # 提交事务
- connect.commit()
- # 断开连接
- connect.close()
- def insertDataS(self):
- '''
- function: 向数据库文件中的表插入多条数据
- '''
- # 连接数据库
- connect = sqlite3.connect(self.dbName)
- # 插入多条数据
- connect.executemany("INSERT INTO {} VALUES(?,?,?,?,?,?,?,?,?,?,?,?,?)".format(self.tableName), self.data)
- #for i in range(len(self.data)):
- # connect.execute("INSERT INTO university VALUES(?,?,?,?,?,?,?,?,?,?,?,?,?)", data[i])
- # 提交事务
- connect.commit()
- # 断开连接
- connect.close()
- def getAllData(self):
- '''
- function: 得到数据库文件中的所有数据
- '''
- # 连接数据库
- connect = sqlite3.connect(self.dbName)
- # 创建游标对象
- cursor = connect.cursor()
- # 读取数据
- cursor.execute("SELECT * FROM {}".format(self.tableName))
- dataList = cursor.fetchall()
- # 断开连接
- connect.close()
- return dataList
- def searchData(self, conditions, IfPrint=True):
- '''
- function: 查找特定的数据
- '''
- # 连接数据库
- connect = sqlite3.connect(self.dbName)
- # 创建游标
- cursor = connect.cursor()
- # 查找数据
- cursor.execute("SELECT * FROM {} WHERE {}".format(self.tableName, conditions))
- data = cursor.fetchall()
- # 关闭游标
- cursor.close()
- # 断开数据库连接
- connect.close()
- if IfPrint:
- self.printData(data)
- return data
- def deleteData(self, conditions):
- '''
- function: 删除数据库中的数据
- '''
- # 连接数据库
- connect = sqlite3.connect(self.dbName)
- # 插入多条数据
- connect.execute("DELETE FROM {} WHERE {}".format(self.tableName, conditions))
- # 提交事务
- connect.commit()
- # 断开连接
- connect.close()
- def printData(self, data):
- print("{1:{0}^3}{2:{0}<11}{3:{0}<4}{4:{0}<4}{5:{0}<5}{6:{0}<5}{7:{0}^5}{8:{0}^5}{9:{0}^5}{10:{0}^5}{11:{0}^5}{12:{0}^6}{13:{0}^5}".format(chr(12288), *self.COLUMNS))
- for i in range(len(data)):
- print("{1:{0}<4.0f}{2:{0}<10}{3:{0}<5}{4:{0}<6}{5:{0}<7}{6:{0}<8}{7:{0}<7.0f}{8:{0}<8}{9:{0}<7.0f}{10:{0}<6.0f}{11:{0}<9.0f}{12:{0}<6.0f}{13:{0}<6.0f}".format(chr(12288), *data[i]))
- def run(self):
- try:
- # 创建数据库文件
- self.creatTable()
- print(">>> 数据库创建成功!")
- # 保存数据到数据库
- self.insertDataS()
- print(">>> 表创建、数据插入成功!")
- except:
- print(">>> 数据库已创建!")
- # 读取所有数据
- if self.Read_All:
- self.printData(self.getAllData())
- def get_data(fileName):
- '''
- function: 读取获得大学排名的数据 并 将结果返回
- '''
- data = []
- # 打开文件
- f = open(fileName, 'r', encoding='utf-8')
- # 按行读取文件
- for line in f.readlines():
- # 替换掉其中的换行符和百分号 替换百分号是为了方便之后的排序和运算
- line = line.replace('\n', '')
- line = line.replace('%','')
- # 将字符串按照 ',' 分割为列表
- line = line.split(',')
- for i in range(len(line)):
- # 使用 异常处理 避开 出现中文无法转换 的错误
- try:
- # 将空值填充为 0
- if line[i] == '':
- line[i] = ''
- # 将数字转换为数值
- line[i] = eval(line[i])
- except:
- continue
- data.append(tuple(line))
- # EN_columns、CH_columns 分别为 用于数据库创建、数据的格式化输出
- EN_columns = "Rank real, University text, Province text, Grade real, SourseQuality real, TrainingResult real, ResearchScale real, \
- ReserchQuality real, TopResult real, TopTalent real, TechnologyService real, Cooperation real, TransformationResults real"
- CH_columns = ["排名", "学校名称", "省市", "总分", "生涯质量", "培养结果(%)", "科研规模", "科研质量", "顶尖成果", "顶尖人才", "科技服务", "产学研合作", "成果转化"]
- return data[1:], EN_columns, CH_columns
- if __name__ == "__main__":
- # =================== 设置和得到基本数据 ===================
- fileName = "D:\\University_Rank.csv"
- data, EN_columns, CH_columns = get_data(fileName)
- dbName = "university.db"
- tableName = "university"
- # ================= 创建一个SQL_method对象 ==================
- SQL = SQL_method(dbName, tableName, data, EN_columns, CH_columns, False)
- # =================== 创建数据库并保存数据 ===================
- SQL.run()
- # =================== 在数据库中查找数据项 ===================
- # 查找记录并输出结果
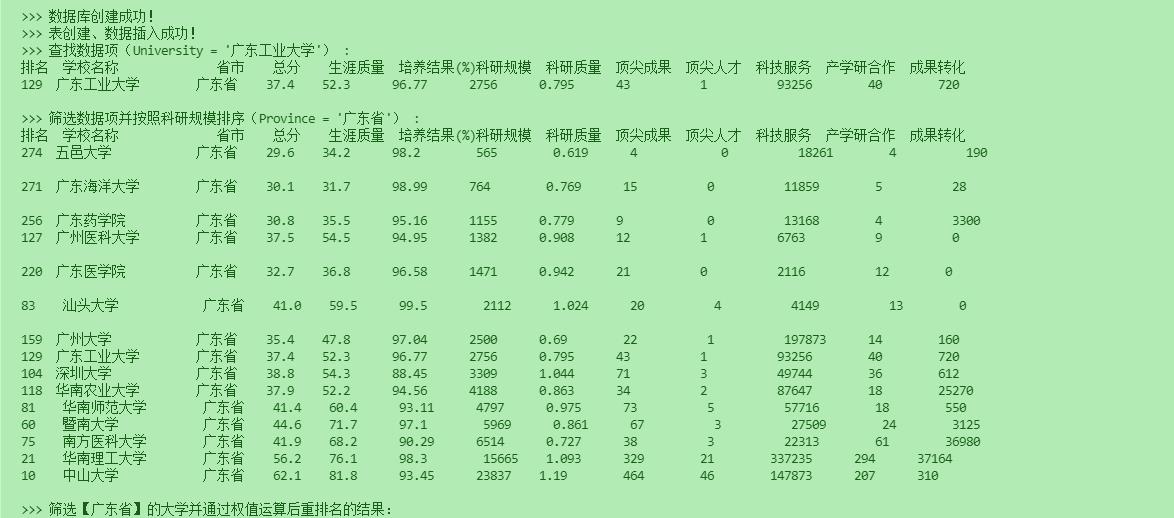
- print(">>> 查找数据项(University = '广东工业大学') :")
- SQL.searchData("University = '广东工业大学'", True)
- # ================= 在数据库中筛选数据项并排序 ==================
- # 将选取广东省的数据 并 对科研规模大小排序
- print("\n>>> 筛选数据项并按照科研规模排序(Province = '广东省') :")
- SQL.searchData("Province = '广东省' ORDER BY ResearchScale", True)
- # =============== 对数据库中的数据进行重新排序操作 ================
- # 定义权值
- Weight = [0.3, 0.15, 0.1, 0.1, 0.1, 0.1, 0.05, 0.05, 0.05]
- value, sum = [], 0
- # 获取 Province = '广东省' 的所有数据
- sample = SQL.searchData("Province = '广东省'", False)
- # 按照权值求出各个大学的总得分
- for i in range(len(sample)):
- for j in range(len(Weight)):
- sum += sample[i][4+j] * Weight[j]
- value.append(sum)
- sum = 0
- # 将结果通过 pandas 的 DataFrame 方法组成一个二维序列
- university = [university[1] for university in sample]
- uv, tmp = [], []
- for i in range(len(university)):
- tmp.append(university[i])
- tmp.append(value[i])
- uv.append(tmp)
- tmp = []
- df = DataFrame(uv, columns=list(("大学", "总分")))
- df = df.sort_values('总分')
- df.index = [i for i in range(1, len(uv)+1)]
- # 输出结果
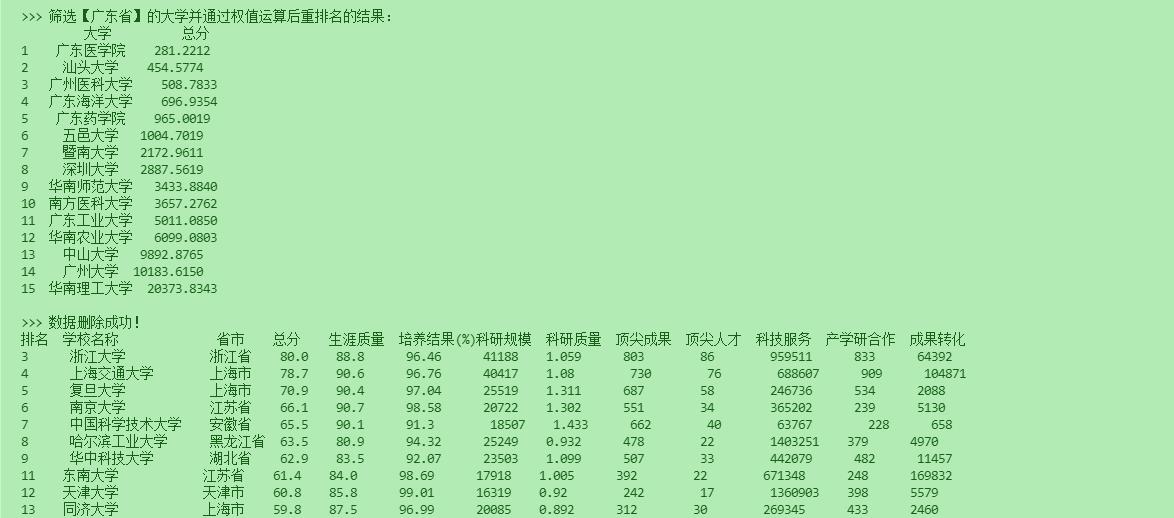
- print("\n>>> 筛选【广东省】的大学并通过权值运算后重排名的结果:\n", df)
- # ===================== 在数据库中删除数据项 =====================
- SQL.deleteData("Province = '北京市'")
- SQL.deleteData("Province = '广东省'")
- SQL.deleteData("Province = '山东省'")
- SQL.deleteData("Province = '山西省'")
- SQL.deleteData("Province = '江西省'")
- SQL.deleteData("Province = '河南省'")
- print("\n>>> 数据删除成功!")
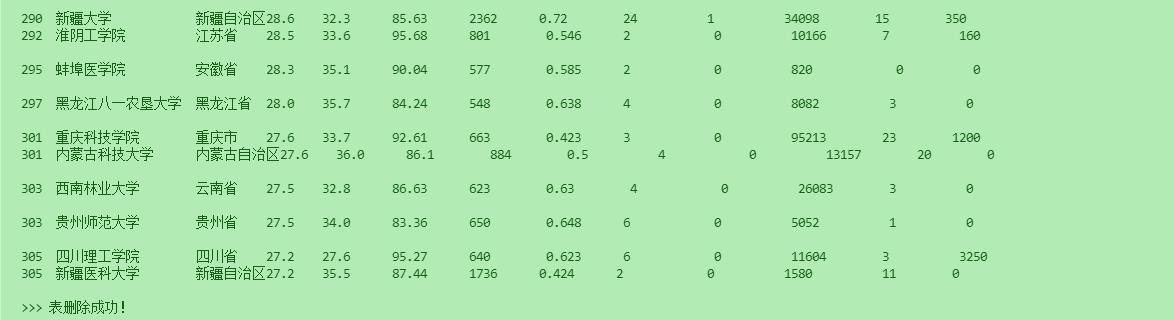
- SQL.printData(SQL.getAllData())
- # ====================== 在数据库中删除表 ========================
- SQL.destroyTable()
- print(">>> 表删除成功!
用于我将所有的要求都写在 main 函数中,因此显得有点乱,但只要明白上面提及的要求就不乱了!
那我们看看执行效果吧,有些地方结果太多就不 一 一 展示。
^ v ^ 今天就分享到这,下期再会 ~~~
SQLite3 of python的更多相关文章
- sqlite3 on python for newbies
python 集成了 sqlite3 ,其接口很简单: import sqlite3 db_connection = sqlite3.connect(db_filename) db_cursor = ...
- From CSV to SQLite3 by python 导入csv到sqlite
'''初次使用SQLite,尝试把之前一个csv文件导进去,看了网上各种教程,大多是在SQLite shell模式下使用的,比较麻烦, 这里用了panda,就方便多了,仅作示例供参考. 第一篇开博,想 ...
- python使用上下文管理器实现sqlite3事务机制
如题,本文记录如何使用python上下文管理器的方式管理sqlite3的句柄创建和释放以及事务机制. 1.python上下文管理(with) python上下文管理(context),解决的是这样一类 ...
- python sqlite3 数据库操作
python sqlite3 数据库操作 SQLite3是python的内置模块,是一款非常小巧的嵌入式开源数据库软件. 1. 导入Python SQLite数据库模块 import sqlite3 ...
- python sqlite3 入门 (视频讲座)
python sqlite3 入门 (视频讲座) an SQLite mini-series! - Simple Databases with Python 播放列表: YouTube https:/ ...
- Python学习笔记:sqlite3(sqlite数据库操作)
对于数据库的操作,Python中可以通过下载一些对应的三方插件和对应的数据库来实现数据库的操作,但是这样不免使得Python程序变得更加复杂了.如果只是想要使用数据库,又不想下载一些不必要的插件和辅助 ...
- Python 资源
转:http://www.360doc.com/content/16/0308/14/31385575_540482688.shtml 本页面是俺收集的各种 Python 资源,不定期更新. 下面列出 ...
- python开源项目及示例代码
本页面是俺收集的各种 Python 资源,不定期更新. 下面列出的各种 Python 库/模块/工具,如果名称带超链接,说明是第三方的:否则是 Python 语言内置的. 1 算法 1.1 字符串处理 ...
- Python读取和处理文件后缀为".sqlite"的数据文件
最近在弄一个项目分析的时候,看到有一个后缀为”.sqlite”的数据文件,由于以前没怎么接触过,就想着怎么用python来打开并进行数据分析与处理,于是稍微研究了一下. SQLite是一款非常流行的关 ...
随机推荐
- (转)linux下文件删除的原理精华讲解(考试题答案系列)
linux下文件删除的原理精华讲解(考试题答案系列) 说明:本文为老男孩linux培训某节课前考试试题及答案分享博文内容的一部分,也是独立成题的,你可以点下面地址查看全部的内容信息.http://ol ...
- ORACLE将查询的多条语句拼在一个字段下
select listagg(字段名,'分隔符') within group (order by 某个字段)
- Oracle Form个性化案例(一)
业务场景: 现有Form A,需通过A中的菜单栏中调用另一Form B,需将某值作为参数传入Form B中:
- 微信公众平台网页开发实战--3.利用JSSDK在网页中获取地理位置(HTML5+jQuery)
复制一份JSSDK环境,创建一份index.html文件,结构如图7.1所示. 图7.1 7.1节文件结构 在location.js中,封装“getLocation”接口,如下: 01 wxJSSD ...
- LeetCode Single Number III (xor)
题意: 给一个数组,其中仅有两个元素是出现1次的,且其他元素均出现2次.求这两个特殊的元素? 思路: 跟查找单个特殊的那道题是差不多的,只是这次出现了两个特殊的.将数组扫一遍求全部元素的异或和 x,结 ...
- jquery UI_tabs
1.tab使用 <!doctype html> <html lang="en"> <head> <meta charset="u ...
- FTP添加虚拟目录(图)
设置 访问效果 可以看到有这个文件:
- CSS样式表优化
前几天公司要模仿一家客户的网站模板来为另一客户新建一个模板,说白了就是换个数据源,然后样式表再小修小改一下就行了.但通过浏览器控制台下载素材时,发现这个网站开发的挺专业的,单就样式表而言,代码工整,注 ...
- linux 命令——25 linux文件属性详解
Linux 文件或目录的属性主要包括:文件或目录的节点.种类.权限模式.链接数量.所归属的用户和用户组.最近访问或修改的时间等内容.具体情况如下: 命令: ls -lih 输出: [root@loca ...
- IOS 创建一个可以随意拉伸不变形的图片
创建一个扩展 UIImage的类 #import "UIImage_Extension.h" @implementation UIImage+Extension /** *返回一张 ...