spark作业
假定用户有某个周末网民网购停留时间的日志文本,基于某些业务要求,要求开发
Spark应用程序实现如下功能:
1、实时统计连续网购时间超过半个小时的女性网民信息。
2、周末两天的日志文件第一列为姓名,第二列为性别,第三列为本次停留时间,单
位为分钟,分隔符为“,”。
数据:
log1.txt:周六网民停留日志
LiuYang,female,20 YuanJing,male,10 GuoYijun,male,5 CaiXuyu,female,50 Liyuan,male,20 FangBo,female,50 LiuYang,female,20 YuanJing,male,10 GuoYijun,male,50 CaiXuyu,female,50 FangBo,female,60
log2.txt:周日网民停留日志
LiuYang,female,20 YuanJing,male,10 CaiXuyu,female,50 FangBo,female,50 GuoYijun,male,5 CaiXuyu,female,50 Liyuan,male,20 CaiXuyu,female,50 FangBo,female,50 LiuYang,female,20 YuanJing,male,10 FangBo,female,50 GuoYijun,male,50 CaiXuyu,female,50 FangBo,female,60
统计日志文件中本周末网购停留总时间超过2个小时的女性网民信息。
1、接收Kafka中数据,生成相应DStream。
2、筛选女性网民上网时间数据信息。
3、汇总在一个时间窗口内每个女性上网时间。
4、筛选连续上网时间超过阈值的用户,并获取结果。
1.启动zk
./zkServer.sh start
2.启动Kafka
./kafka-server-start.sh /root/apps/kafka/config/server.properties
3.创建topic
[root@mini3 kafka]# bin/kafka-console-producer.sh --broker-list mini1: --topic sparkhomework-test
4.生产数据
代码
package org.apache.spark import org.apache.spark.streaming.Seconds
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka.KafkaUtils /**
* Created by Administrator on 2019/6/13.
*/
object SparkHomeWork {
val updateFunction = (iter: Iterator[(String, Seq[Int], Option[Int])]) => {
iter.flatMap { case (x, y, z) => Some(y.sum + z.getOrElse(0)).map(v => (x, v)) }
} def main(args: Array[String]) {
val conf = new SparkConf().setMaster("local[2]").setAppName("SparkHomeWork")
val ssc = new StreamingContext(conf, Seconds(5))
//将回滚点写到hdfs
ssc.checkpoint("hdfs://mini1:9000/kafkatest") val Array(zkQuorum, groupId, topics, numThreads) = Array[String]("mini1:2181,mini2:2181,mini3:2181", "g1", "sparkhomework-test", "2")
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap val lines = KafkaUtils.createStream(ssc, zkQuorum, groupId, topicMap).map(_._2) //筛选女性网民上网时间数据信息
val data = lines.flatMap(_.split(" ")).filter(_.contains("female"))
//汇总每个女性上网时间
val femaleData: DStream[(String, Int)] = data.map { line =>
val t = line.split(',')
(t(0), t(2).toInt)
}.reduceByKey(_ + _)
//筛选出时间大于两个小时的女性网民信息,并输出
val results = femaleData.filter(line => line._2 > 120).updateStateByKey(updateFunction, new HashPartitioner(ssc.sparkContext.defaultParallelism), true)
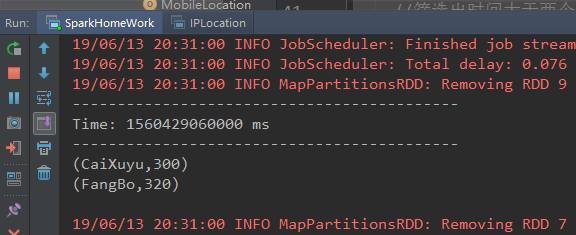
results.print()
ssc.start()
ssc.awaitTermination()
} }
打印结果:
spark作业的更多相关文章
- Spark学习(四) -- Spark作业提交
标签(空格分隔): Spark 作业提交 先回顾一下WordCount的过程: sc.textFile("README.rd").flatMap(line => line.s ...
- 构建Spark作业
首先,要清楚,一个Java或Scala或python实现的Spark作业. 1.用sbt构建Spark作业 2.用Maven构建Spark作业 3.用non-maven-aware工具构建Spark作 ...
- Spark记录-Spark作业调试
在本地IDE里直接运行spark程序操作远程集群 一般运行spark作业的方式有两种: 本机调试,通过设置master为local模式运行spark作业,这种方式一般用于调试,不用连接远程集群. 集群 ...
- spark作业提交参数设置(转)
来源:https://www.cnblogs.com/arachis/p/spark_parameters.html 摘要 1.num-executors 2.executor-memory 3.ex ...
- 数据倾斜是多么痛?spark作业调优秘籍
目录视图 摘要视图 订阅 [观点]物联网与大数据将助推工业应用的崛起,你认同么? CSDN日报20170703——<从高考到程序员——我一直在寻找答案> [直播]探究L ...
- 【转】数据倾斜是多么痛?spark作业/面试/调优必备秘籍
原博文出自于: http://sanwen.net/a/gqkotbo.html 感谢! 来源:数盟 调优概述 有的时候,我们可能会遇到大数据计算中一个最棘手的问题——数据倾斜,此时Spark作业的性 ...
- spark作业运行过程之--DAGScheduler
DAGScheduler--stage划分和创建以及stage的提交 本篇,我会从一次spark作业的运行为切入点,将spark运行过程中涉及到的各个步骤,包括DAG图的划分,任务集的创建,资源分配, ...
- Spark作业执行流程源码解析
目录 相关概念 概述 源码解析 作业提交 划分&提交调度阶段 提交任务 执行任务 结果处理 Reference 本文梳理一下Spark作业执行的流程. Spark作业和任务调度系统是其核心,通 ...
- Spark作业提交至Yarn上执行的 一个异常
(1)控制台Yarn(Cluster模式)打印的异常日志: client token: N/A diagnostics: Application application_1584359 ...
- Spark作业执行
Spark中一个action触发一个job的执行,在job提交过程中主要涉及Driver和Executor两个节点. Driver主要解决 1. RDD 依赖性分析,生成DAG. 2. 根据RDD D ...
随机推荐
- 【Unity3D】射箭打靶游戏(简单工厂+物理引擎编程)
打靶游戏: 1.靶对象为 5 环,按环计分: 2.箭对象,射中后要插在靶上: 3.游戏仅一轮,无限 trials: 增强要求: 添加一个风向和强度标志,提高难度 游戏成品图: U ...
- Object-C反射读取实体属性和值
举例: 首先定义TestModel如下: @interface TestModel : NSObject @property (nonatomic, strong) NSString *name; @ ...
- 【UML】构件图Component diagram(实现图)(转)
http://blog.csdn.net/sds15732622190/article/details/49048887 前言 下面要介绍UML中的构建图,它属于实现图的一种,五种静态图之一. 定义 ...
- SpringMVC归纳
SpringMVC归纳 操作流程 配置前端控制器 在web.xml中配置 配置处理器映射器 在springmvc配置文件中配置 配置处理器适配器 在springmvc配置文件中配置 配置注解适配器和映 ...
- Beta冲刺(周五)
这个作业属于哪个课程 https://edu.cnblogs.com/campus/xnsy/SoftwareEngineeringClass1 这个作业要求在哪里 https://edu.cnblo ...
- python_91_正则表达式
常用的正则表达式: '.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行 '^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r& ...
- iOS 打印系统字体
NSArray * array = [UIFont familyNames]; for( NSString *familyName in array ){ printf( "Family: ...
- 【转】vxworks的default boot line说明
boot程序的主要功能是引导vxworks 内核,所以boot程序需要知道vxworks的内核存放在何处,通过什么手段去获取.在vxworks缺省的boot程序里有一条内建的default boot ...
- 【转】MFC消息映射详解(整理转载)
消息:主要指由用户操作而向应用程序发出的信息,也包括操作系统内部产生的消息.例如,单击鼠标左按钮,windows将产WM_LBUTTONDOWN消息,而释放鼠标左按钮将产生WM_LBUTTONUP消息 ...
- JDBC操作数据库的详细步骤
1.注册驱动 告知JVM使用的是哪一个数据库的驱动 2.创建连接 使用JDBC中的类,完成对MySQL数据库的连接 3. 得到执行sql语句的Statement对象 通过连接对象获取对SQL语句的执行 ...