Spider爬虫-get、post请求
1:概念:
爬虫就是通过编写程序,模拟浏览器上网,然后让其去互联网上抓取数据的过程。
2:python爬虫与其他语言的比较:
(1)php爬虫弊端:多进程多线程支持的不好
(2)java:代码臃肿,重构成本较大
(3)C/c++:不明智的选择,C语言纯面向过程
(4)Python:学习成本低,较多模块,具有框架的支持,Scripy
3:分类(使用场景)
(1)通用爬虫:是搜素引擎中’抓取系统‘的重要组成部分(爬取的是整张页面)。将互联网上页面内容进行抓取下载到服务器本地
扩展:搜素引擎如何抓取互联网的网页
1.门户主动将自己的url提交给搜素引擎公司
2.搜索引擎公司会和DNS服务商进行合作
3.挂靠知名网站的友情链接
(2)聚焦爬虫:根据指定的需求去网上爬去指定的内容
4.robots.txt协议:指定的是门户中哪些数据可以供爬虫程序进行爬取和非爬取。(协议是防君子不防小人)
查看网站后台的robots协议:

5.反爬虫:
门户网站通过相应的策略和技术手段,防止爬虫程序进行网站数据的爬取。
6.反反爬虫:
爬虫程序通过相应的策略和技术手段,破解门户网站的反爬虫手段,从而爬取到相应的数据。
get请求,爬取数据实例:
(1):简单的get请求:模拟浏览器发送get请求,在百度上爬取搜索明星名字页面
import requests
#get请求:爬取百度搜素
get_url='http://www.baidu.com/s'
wd=input('输入你要搜素的明星名字:') param={
'ie':'utf-8',
'wd':wd, }
response=requests.get(url=get_url,params=param)
# print(response.text)
data=response.text filename=wd+'.html'
with open(filename,'wt',encoding='utf-8') as f:
f.write(data)
实现的效果如下:
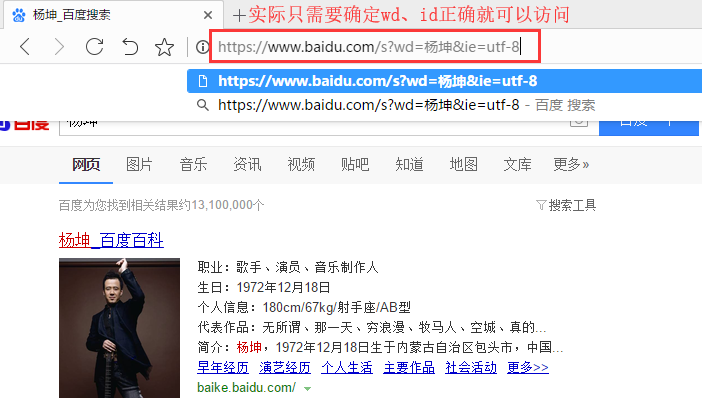
结合fiddler抓包工具图解分析如下:
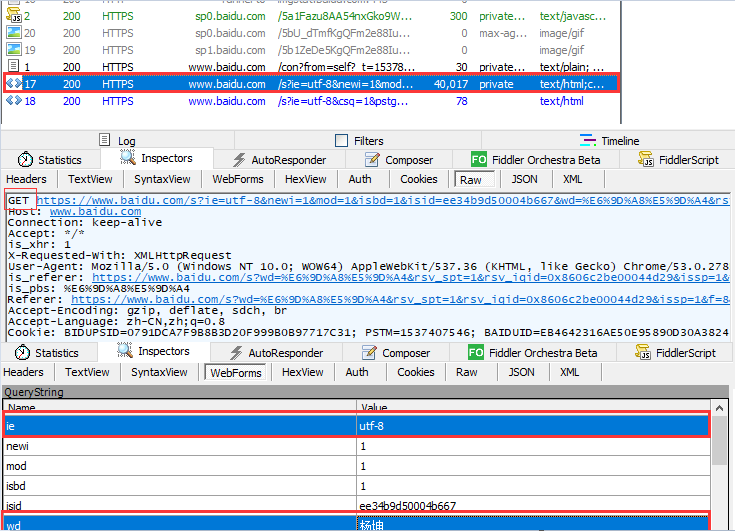
(2):基于ajax的get请求:获取豆瓣网上的电影排行榜信息
import requests
#指定开始位置和结束位置:start开始的视频 limit:即每页显示的视频数量(默认每页是20个可以自己设定每页显示的数值)
get_url='https://movie.douban.com/j/chart/top_list?type=13&interval_id=100%3A90&action=&start=0&limit=20' param={ 'type':'',
'interval_id':'100:90',
'action':'',
'start':'', #指定开始爬取的开始位置
'limit':'', #默认每页的显示的视频个数 } response=requests.get(url=get_url,params=param)
print(response.text)
要获取的页面信息如下:
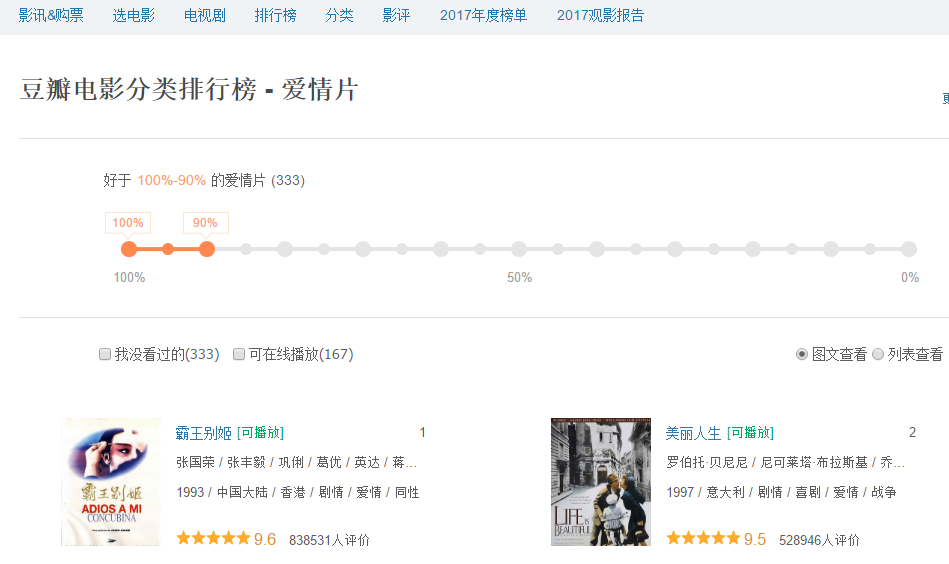
结合抓包工具,分析如下:
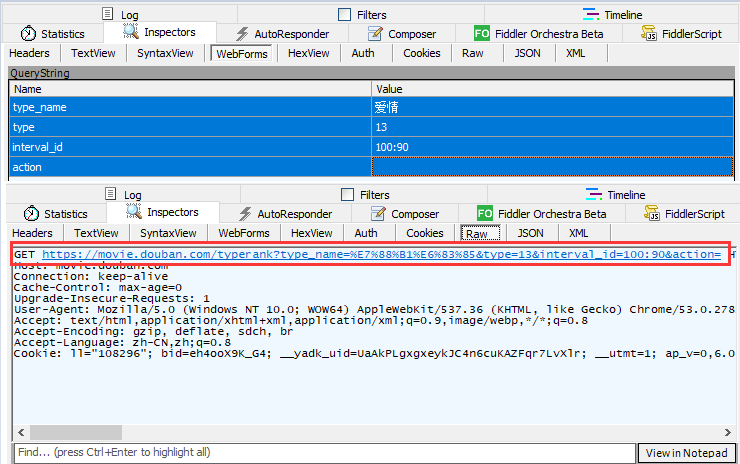
结果如下,就能实现获取指定页数指定数量的电影信息:

post请求,爬取数据实例:
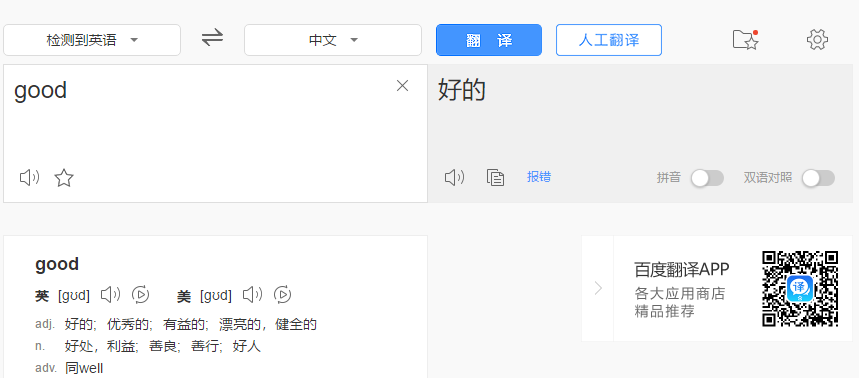
(1):普通post请求,爬取百度翻译信息
import requests
#百度翻译:爬取post请求翻译结果 #如下两行代码表示的是忽略证书(SSLError)
import ssl
ssl._create_default_https_context = ssl._create_unverified_context url='https://fanyi.baidu.com/sug' header={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.89 Safari/537.36', }
data={
'kw':'hi' } response=requests.post(url,data=data,headers=header )
print(response.text)
(2):基于ajax的post请求,搜素肯德基的门店信息
网址:http://www.kfc.com.cn/kfccda/storelist/index.aspx
import requests #KFC门店查询
get_url='http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword' header={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.89 Safari/537.36',
} address=input('输入你要查询的城市>>>:')
start_page=int(input('输入开始页>>>:'))
end_page=int(input('输入结束页>>>:')) #for循环拿到每一页的页码数(for..range取值,所以页码数必须为int类型)
for page in range(start_page,end_page+1): data={
'cname':'',
'pid':'',
'keyword':address,
'pageIndex':str(page),
'pageSize':'', #每页显示10条信息 }
#显示每一页的10条门店信息
response=requests.post(url=get_url,data=data,headers=header)
print(response.text)

Spider爬虫-get、post请求的更多相关文章
- spider 爬虫文件基本参数(3)
一 代码 # -*- coding: utf-8 -*- import scrapy class ZhihuSpider(scrapy.Spider): # 爬虫名字,名字唯一,允许自定义 name ...
- 9.scrapy pycharm调试小技巧,请求一次,下次直接调试,不必每次都启动整个爬虫,重新请求一整遍
pycharm调试技巧:调试时,请求一次,下次直接调试,不必每次都启动整个爬虫,重新请求一整遍 [用法]cmd命令运行:scrapy shell 网址 第一步,cmd进行一次请求: scrapy sh ...
- 第三百二十二节,web爬虫,requests请求
第三百二十二节,web爬虫,requests请求 requests请求,就是用yhthon的requests模块模拟浏览器请求,返回html源码 模拟浏览器请求有两种,一种是不需要用户登录或者验证的请 ...
- Python爬虫--- 1.1请求库的安装与使用
来说先说爬虫的原理:爬虫本质上是模拟人浏览信息的过程,只不过他通过计算机来达到快速抓取筛选信息的目的所以我们想要写一个爬虫,最基本的就是要将我们需要抓取信息的网页原原本本的抓取下来.这个时候就要用到请 ...
- 爬虫中网络请求的那些事之urllib库
目录 爬虫之网络请求中的那些事 urllib库 urlopen函数 urlretrieve函数 urlencode.parse_qs函数 urlparse.urlsplit函数: request.Re ...
- spider爬虫练习
package com.jinzhi.spider; import java.io.BufferedReader;import java.io.IOException;import java.io.I ...
- 爬虫scrapy组件 请求传参,post请求,中间件
post请求 在scrapy组件使用post请求需要调用 def start_requests(self): 进行传参再回到 yield scrapy.FormRequest(url=url,form ...
- 爬虫:selenium请求库
一.介绍 二.安装 三.基本使用 四.选择器 五.等待元素被加载 六.元素交互操作 七.其他 八.项目练习 一.介绍 # selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requ ...
- Nginx优化防爬虫 限制http请求方法 CDN网页加速 架构优化 监牢模式 控制并发量以及客户端请求速率
Nginx防爬虫优化 Robots协议(也称为爬虫协议,机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可 ...
随机推荐
- 常用的图片相关方法,读取,保存,压缩,缩放,旋转,drawable转化
import android.content.Context; import android.content.res.AssetManager; import android.content.res. ...
- Android开发学习——小细节注意
Android中通过Intent调用其他应用的方法(转) Android中两种序列化方式的比较Serializable和Parcelable http://www.jcodecraeer.com/a/ ...
- WebView全面学习(二)-- Native与js双方通信
WebView全面学习(二)-- Native与js双方通信 Native与js通信的本质 Native与js通信的核心在于WebView. 两端的通信主要还是单向的.假如要完成js->Nati ...
- (转)VC得到可用的串口列表
//枚举串口 //参数:bEnablePort,哪个串口有效,bEnablePort[0]表示COM1,bEnablePort[n-1]表示COMn //返回值:有效的串口个数 int EnumAll ...
- python基础教程总结15——2 画幅好画
要求:从Internet上下载数据文件: 分析数据文件并提取感兴趣的部分 工具:图形生成包(ReportLab,PYX等) 数据:太阳黑子和射电辐射流量(http://services.swpc.n ...
- UVALive 3983 Robotruck (单调队列,dp)
如果状态定义为序号和重量的话,决策就是下一个垃圾捡或者不减,但是状态数太多了. 如果只定义序号作为状态的话,决策就变成从前面的某个j一直捡到i才送回垃圾. 这就变成了一个区间选最小值的问题,用单调队列 ...
- SpringMVC-概述和入门程序
三层架构和MVC B/S三层架构 表现层:web层,一般使用MVC模型 业务层:service层 持久层:dao层 MVC模型 Model:数据模型,JavaBean的类,用来进行数据封装 View: ...
- 两个对象值转换的方法(BeanUtils.copyProperties与JSONObject.parseObject对比)
将源对象赋值到目标对象方法: 方法一:BeanUtils.copyProperties(源对象, 目标对象); //org.springframework.beans.BeanUtils 方法二:目标 ...
- java基础—equals方法
一.equals方法介绍 1.1.通过下面的例子掌握equals的用法 1 package cn.galc.test; 2 3 public class TestEquals { 4 public s ...
- React动态import()
React动态import() react-router@v4代码分离,推荐的import().这里分享webpack配置和使用方法. 首先安装两个必须的包 cnpm i react-loadable ...