CDH版本Hbase二级索引方案Solr key value index
概述
在Hbase中,表的RowKey 按照字典排序, Region按照RowKey设置split point进行shard,通过这种方式实现的全局、分布式索引. 成为了其成功的最大的砝码。
然而单一的通过RowKey检索数据的方式,不再满足更多的需求,查询成为Hbase的瓶颈,人们更加希望像Sql一样快速检索数据,可是,Hbase之前定位的是大表的存储,要进行这样的查询,往往是要通过类似Hive、Pig等系统进行全表的MapReduce计算,这种方式既浪费了机器的计算资源,又因高延迟使得应用黯然失色。于是,针对HBase Secondary Indexing的方案出现了。
Solr
Solr是一个独立的企业级搜索应用服务器,是Apache Lucene项目的开源企业搜索平台,
其主要功能包括全文检索、命中标示、分面搜索、动态聚类、数据库集成,以及富文本(如Word、PDF)的处理。Solr是高度可扩展的,并提供了分布式搜索和索引复制。Solr 4还增加了NoSQL支持,以及基于Zookeeper的分布式扩展功能SolrCloud。SolrCloud的说明可以参看:SolrCloud分布式部署。它的主要特性包括:高效、灵活的缓存功能,垂直搜索功能,Solr是一个高性能,采用Java5开发,基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎。
Solr可以高亮显示搜索结果,通过索引复制来提高可用,性,提供一套强大Data Schema来定义字段,类型和设置文本分析,提供基于Web的管理界面等。
Key-Value Store Indexer
这个组件非常关键,是Hbase到Solr生成索引的中间工具。
在CDH5.3.2中的Key-Value Indexer使用的是Lily HBase NRT Indexer服务.
Lily HBase Indexer是一款灵活的、可扩展的、高容错的、事务性的,并且近实时的处理HBase列索引数据的分布式服务软件。它是NGDATA公司开发的Lily系统的一部分,已开放源代码。Lily HBase Indexer使用SolrCloud来存储HBase的索引数据,当HBase执行写入、更新或删除操作时,Indexer通过HBase的replication功能来把这些操作抽象成一系列的Event事件,并用来保证写入Solr中的HBase索引数据的一致性。并且Indexer支持用户自定义的抽取,转换规则来索引HBase列数据。Solr搜索结果会包含用户自定义的columnfamily:qualifier字段结果,这样应用程序就可以直接访问HBase的列数据。而且Indexer索引和搜索不会影响HBase运行的稳定性和HBase数据写入的吞吐量,因为索引和搜索过程是完全分开并且异步的。Lily HBase Indexer在CDH5中运行必须依赖HBase、SolrCloud和Zookeeper服务。
实时查询方案
Hbase -----> Key Value Store ---> Solr -------> Web前端实时查询展示
1.Hbase 提供海量数据存储
2.Solr提供索引构建与查询
3. Key Value Store 提供自动化索引构建(从Hbase到Solr)
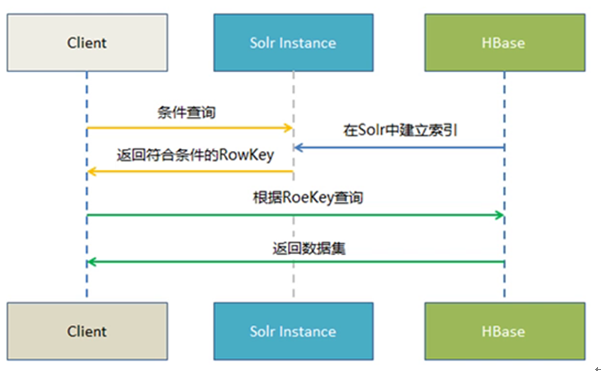
使用流程
前提: CDH5.3.2Solr集群搭建好,CDH5.3.2 Key-Value Store Indexer集群搭建好
1.开启Hbase的复制功能
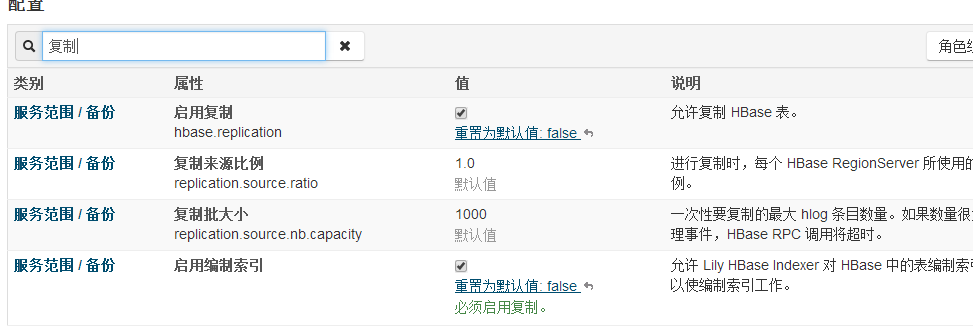
2. Hbase表需要开启REPLICATION复制功能
|
create 'table',{NAME => 'cf', REPLICATION_SCOPE => 1} #其中1表示开启replication功能,0表示不开启,默认为0 |
对于已经创建的表可以使用如下命令
|
disable 'table' alter 'table',{NAME => 'cf', REPLICATION_SCOPE => 1} enable 'table' |
3. 生成实体配置文件, /opt/hbase-indexer/Test是自定义路径,可以自己设置
solrctl instancedir --generate /opt/cdhsolr/waslog
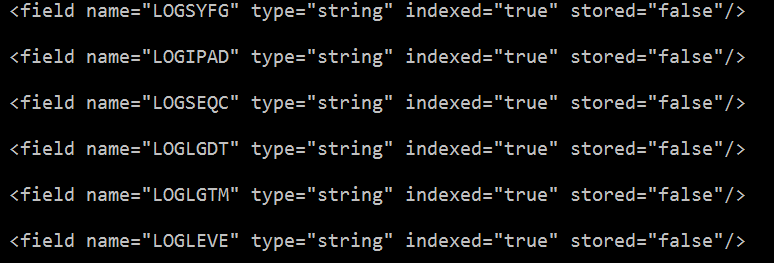
4.编辑生成好的scheme.xml文件
把hbase表中需要索引的列添加到scheme.xml filed节点,其中的name属性值要与Morphline.conf文件中的outputField属性值对应
5.创建collection实例并配置文件上传到zookeeper,命令
solrctl instancedir --create waslog /opt/cdhsor/waslog


6.上传到zookeeper之后,其他节点就可以从zookeeper下载配置文件。接下来创建collection,命令:
solrctl collection –create waslog -s 15 –r 2 –m 50

7.创建Lily HBase Indexer配置文件
morphline-hbase-mapper.xml <?xml version="1.0" encoding="UTF-8"?>
<indexer table="waslog" mapper="com.ngdata.hbaseindexer.morphline.MorphlineResultToSolrMapper">
<param name="morphlineFile" value="morphlines.conf"></param>
<param name="morphlineId" value="waslogMap"></param>
</indexer>
其中morphlineId 的value是对应Key-Value Store Indexer 中配置文件Morphlines.conf 中morphlines 属性id值
8.修改Morphlines 文件, 具体操作:进入Key-Value Store Indexer面板->配置->查看和编辑->属性-Morphline文件
morphlines : [
{
id :waslogMap
importCommands : ["org.kitesdk.**", "com.ngdata.**"] commands : [
{
extractHBaseCells {
mappings : [
{
inputColumn : "cf:LOGSYFG"
outputField : "LOGSYFG"
type : string
source : value
},
{
inputColumn : "cf:LOGIPAD"
outputField : "LOGIPAD"
type : string
source : value
},
{
inputColumn : "cf:LOGSEQC"
outputField : "LOGSEQC"
type : string
source : value
},
{
inputColumn : "cf:LOGLGDT"
outputField : "LOGLGDT"
type : string
source : value
},
{
inputColumn : "cf:LOGLGTM"
outputField : "LOGLGTM"
type : string
source : value
}
]
}
}
{ logDebug { format : "output record: {}", args : ["@{}"] } }
]
}
]
inputColumn:Hbase的CLOUMN
outputField:Solr的Schema.XML配置的fields

9.注册Lily HBase Indexer configuration 和 Lily Hbase Indexer Service
hbase-indexer add-indexer \ --name cloudIndexer \ --indexer-conf /opt/cdhsolr/morphline-hbase-mapper.xml --connection-param solr.zk=cdh1:2181,cdh2:2181,cdh3:2181/solr \ --connection-param solr.collection=waslog \ --zookeeper cdh1:2181,cdh2:2181,cdh3:2181
验证索引器是否成功创建
hbase-indexer list-indexers

10.测试put数据查看结果
当写入数据后,稍过几秒我们可以在相对于的solr中查询到该插入的数据,表明配置已经成功。


11.使用IK分词器
在/opt/cloudera/parcels/CDH/lib/solr/webapps/solr/WEB-INF创建classes目录
把IKAnalyzer.cfg.xml 和 stopword.dic添加到classes目录
把IKAnalyzer2012FF_u1.jar添加到/opt/cloudera/parcels/CDH/lib/solr/webapps/solr/WEB-INF/lib目录
在Schema.xml中添加
<!--配置IK分词器-->
<fieldType name="text_ik" class="solr.TextField">
<!--索引时候的分词器-->
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<!--查询时候的分词器-->
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
配置好后更新ZK配置文件,重启solr服务
12,扩展命令
Scheme.xml新增索引字段
执行以下命令更新配置
solrctl instancedir --update waslog /opt/cdhsolr /waslog
solrctl collection --reload waslog
查看collection命令:solrctl collection –list
Hbase表数据到SOLR集群迁移
在CDH5.3.2中Hbase-indexer提供了MapReduce来批量构建索引的方式
/opt/cloudera/parcels/CDH-5.3.2-1.cdh5.3.2.p0.10/lib/hbase-solr/tools/hbase-indexer-mr-1.5-cdh5.3.2-job.jar
构建命令
hadoop jar /opt/cloudera/parcels/CDH-5.3.2-1.cdh5.3.2.p0.10/lib/hbase-solr/tools/hbase-indexer-mr-1.5-cdh5.3.2-job.jar D 'mapreduce.reduce.shuffle.memory.limit.percent=0.06' --hbase-indexer-file /opt/cdhsolr/mapping/waslog/morphline-hbase-mapper.xml --zk-host hadoop03:2181,hadoop04:2181,hadoop05:2181/solr --collection waslog --go-live

注意:在运行命令的目录下必须有morphlines.conf文件

文章地址:http://www.cnblogs.com/thinkpad/p/5534627.html
CDH版本Hbase二级索引方案Solr key value index的更多相关文章
- Lily HBase Indexer同步HBase二级索引到Solr丢失数据的问题分析
一.问题描述二.分析步骤2.1 查看日志2.2 修改Solr的硬提交2.3 寻求StackOverFlow帮助2.4 修改了read-row="never"后,丢失部分字段2.5 ...
- HBase二级索引方案总结
转自:http://blog.sina.com.cn/s/blog_4a1f59bf01018apd.html 附hbase如何创建二级索引以及创建二级索引实例:http://www.aboutyun ...
- HBase协处理器同步二级索引到Solr(续)
一. 已知的问题和不足二.解决思路三.代码3.1 读取config文件内容3.2 封装SolrServer的获取方式3.3 编写提交数据到Solr的代码3.4 拦截HBase的Put和Delete操作 ...
- HBase协处理器同步二级索引到Solr
一. 背景二. 什么是HBase的协处理器三. HBase协处理器同步数据到Solr四. 添加协处理器五. 测试六. 协处理器动态加载 一. 背景 在实际生产中,HBase往往不能满足多维度分析,我们 ...
- HBase 二级索引与Join
二级索引与索引Join是Online业务系统要求存储引擎提供的基本特性.RDBMS支持得比较好,NOSQL阵营也在摸索着符合自身特点的最佳解决方案. 这篇文章会以HBase做为对象来探讨如何基于Hba ...
- HBase二级索引与Join
转自:http://www.oschina.net/question/12_32573 二级索引与索引Join是Online业务系统要求存储引擎提供的基本特性.RDBMS支持得比较好,NOSQL阵营也 ...
- HBase二级索引、读写流程
HBase二级索引.读写流程 一.HBse二级索引方案 1.1 基于Coprocessor方案 1.2 Phoenix二级索引特点 1.3 Phoenix 二级索引方案 二.HBase读写流程 2.1 ...
- [转]HBASE 二级索引
1.二级索引的核心思想是什么?2.二级索引由谁来管理?3.在主表中插入某条数据后,hbase如何将索引列写到索引表中去?4.scan查询的时候,coprocessor钩子的作用是什么?5.在split ...
- Lucene 查询原理 传统二级索引方案 倒排链合并 倒排索引 跳表 位图
提问: 1.倒排索引与传统数据库的索引相比优势? 2.在lucene中如果想做范围查找,根据上面的FST模型可以看出来,需要遍历FST找到包含这个range的一个点然后进入对应的倒排链,然后进行求并集 ...
随机推荐
- linux 打开文件数too many open files解决方法
出现这句提示的原因是程序打开的文件/socket连接数量超过系统设定值.查看每个用户最大允许打开的文件数量ulimit -a 其中 open files (-n) 1024 表示每个用户最大允许打开的 ...
- js 考记忆力得小游戏
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 身份证识别接口编写的JAVA调用示例
此java文章是基本聚合数据证件识别接口来演示,基本HTTP POST请求上传图片并接收JSON数据来处理. 使用前你需要通过 https://www.juhe.cn/docs/api/id/153 ...
- rename命令
rename命令用字符串替换的方式批量改变文件名. 语法 rename(参数) 参数 原字符串:将文件名需要替换的字符串: 目标字符串:将文件名中含有的原字符替换成目标字符串: 文件:指定要改变文件名 ...
- Xshell 一款很养眼的配色方案推荐
Xshell 是个很好用的在 windows 下登陆 liunx 的终端原生支持中文,配合 Xftp 管理文件,同是免费软件可远比 Putty 好用多了面对枯燥的代码,我们需要一款很养眼的配色方案来保 ...
- Struts2学习三----------Action搜索顺序
© 版权声明:本文为博主原创文章,转载请注明出处 Struts2的Action的搜索顺序 http://localhost:8080/path1/path2/student.action 1)判断pa ...
- linux下安装redis报错问题。
1.使用tar -xzvf redis-2.4.5.tar.gz来解压安装包 2.使用make命令来编译Redis 如果出现错误需要查看是否缺少gcc gcc-c++ zmalloc.h:50:31: ...
- 【Python基础】之for循环、数组字典
一. for循环实例 1.循环字符串 Python Shell: for i in "hello": print(i) h e l l o 2.循环数组Python Shell: ...
- 嵌入式驱动开发之---Linux ALSA音频驱动(一)
本文的部分内容参考来自DroidPhone的博客(http://blog.csdn.net/droidphone/article/details/6271122),关于ALSA写得很不错的文章,只是少 ...
- android -volley-请求数据
private List<gson.DataBean>arrGson;//请求的数据 //请求数据的方法 public void initData() { RequestQueue mQu ...