Scrapy五大核心组件工作流程
一.Scrapy五大核心组件工作流程
1.核心组件
# 引擎(Scrapy)
对整个系统的数据流进行处理, 触发事务(框架核心).
# 调度器(Scheduler)
用来接受引擎发过来的请求. 由过滤器过滤重复的url并将其压入队列中, 在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么.
# 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的).
# 爬虫(Spiders)
爬虫是主要干活的, 它可以生成url, 并从特定的url中提取自己需要的信息, 即所谓的实体(Item). 用户也可以从中提取出链接, 让Scrapy继续抓取下一个页面.
# 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体, 主要的功能是持久化实体、验证实体的有效性、清除不需要的信息. 当页面被爬虫解析后, 将被发送到项目管道, 并经过几个特定的次序处理数据.
2.工作流程
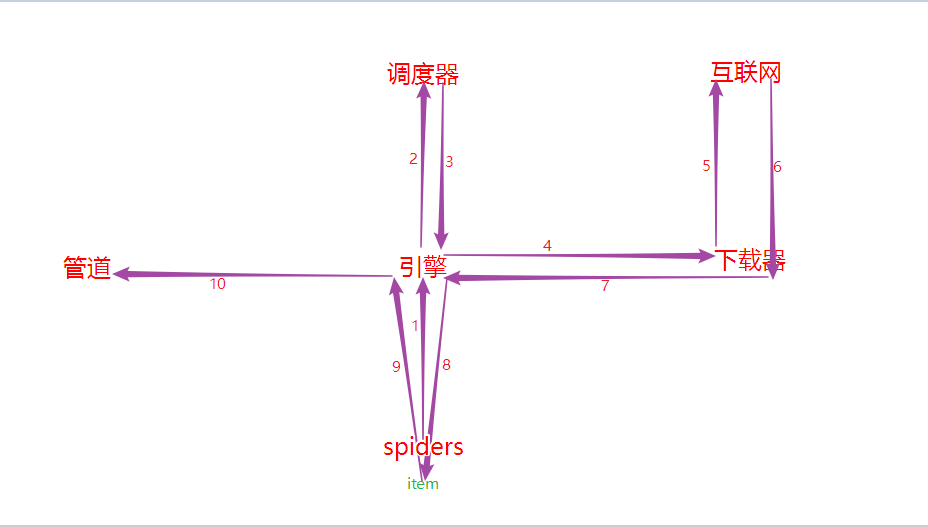
- spider中的url被封装成请求对象交给引擎(每一个url对应一个请求对象);
- 引擎拿到请求对象之后, 将其全部交给调度器;
- 调度器拿到所有请求对象后, 通过内部的过滤器过滤掉重复的url, 最后将去重后的所有url对应的请求对象压入到队列中, 随后调度器调度出其中一个请求对象, 并将其交给引擎;
- 引擎将调度器调度出的请求对象交给下载器;
- 下载器拿到该请求对象去互联网中下载数据;
- 数据下载成功后会被封装到response中, 随后response会被交给下载器;
- 下载器将response交给引擎;
- 引擎将response交给spiders;
- spiders拿到response后调用回调方法进行数据解析, 解析成功后产生item, 随后spiders将item交给引擎;
- 引擎将item交给管道, 管道拿到item后进行数据的持久化存储.
Scrapy五大核心组件工作流程的更多相关文章
- scrapy 五大核心组件-分页
scrapy 五大核心组件-分页 分页 思路 总的原理和之前是一样的,但是由于框架的原因,要遵循他框架的使用方式,每次更改他的url,并指定回调函数 # -*- coding: utf-8 -*- i ...
- scrapy五大核心组件
scrapy五大核心组件 引擎(Scrapy)用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler)用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. ...
- scrapy核心组件工作流程和post请求
一 . 五大核心组件的工作流程 引擎(Scrapy)用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler)用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返 ...
- scrapy五大核心组件和中间件以及UA池和代理池
五大核心组件的工作流程 引擎(Scrapy) 用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler) 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. ...
- Scrapy五大核心组件简介
五大核心组件 scrapy框架主要由五大组件组成,他们分别是调度器(Scheduler),下载器(Downloader),爬虫(Spider),和实体管道(Item Pipeline),Scrapy引 ...
- 爬虫-scrapy五大核心组件及工作流
- scrapy框架post请求发送,五大核心组件,日志等级,请求传参
一.post请求发送 - 问题:爬虫文件的代码中,我们从来没有手动的对start_urls列表中存储的起始url进行过请求的发送,但是起始url的确是进行了请求的发送,那这是如何实现的呢? - 解答: ...
- Scrapy中的核心工作流程以及POST请求
五大核心组件工作流程 post请求发送 递归爬取 五大核心组件工作流程 引擎(Scrapy)用来处理整个系统的数据流处理, 触发事务(框架核心) 调度器(Scheduler)用来接受引擎发过来的请求, ...
- scrapy之五大核心组件
scrapy之五大核心组件 scrapy一共有五大核心组件,分别为引擎.下载器.调度器.spider(爬虫文件).管道. 爬虫文件的作用: a. 解析数据 b. 发请求 调度器: a. 队列 队列是一 ...
随机推荐
- Jsp与JavaScript区别
有时候会误以为这两个是同一个概念,但其实不是 Jsp全名为Java Server Pages(Java服务器页面),其根本是一个简化的Servlet设计,他实现了在Java当中使用HTML标签.Jsp ...
- v-model原理解析
vue中v-model可以实现数据的双向绑定,但是为什么这个指令就可以实现数据的双向绑定呢? 其实v-model是vue的一个语法糖.即利用v-model绑定数据后,既绑定了数据,又添加了一个inpu ...
- JSP基础语法总结
任何语言都有自己的语法,Java中有.JSP虽然是在Java上的一种应用,但是依然有其自己扩充的语法,而且在Jsp中,所有Java语句都可以使用. 一.Jsp的模板元素 Jsp页面中的HTML内容称为 ...
- 51nod 1843 排列合并机(DP+组合)
题解链接 不过求ggg不用O(n2)DPO(n^2)DPO(n2)DP,g[n]g[n]g[n]直接就是卡特兰数的第n−1n-1n−1项.即: g[n]=(2(n−1)n−1)−(2(n−1)n−2) ...
- EF非常见错误:EXECUTE 后的事务计数指示 BEGIN 和 COMMIT 语句的数目不匹配
EF非常见错误:EXECUTE 后的事务计数指示 BEGIN 和 COMMIT 语句的数目不匹配 问题原因: 两个表A\B之间存在外键关系,当插入表A的时候,A的外键B在B表中不存在可以引起这个问题: ...
- HR#4 题解
既然考这么差就来写题啦OTZ T1 猜结论?猜nm! 一直到考试结束都没猜出来=.=我就好奇别人如何猜出来的 我们来说DP(from ZBK) 设\(dp[i][j]\)表示胜or负 那我们来看一下代 ...
- [Luogu] 余数求和
question: $$\sum_{i=1}^{n} k \bmod i$$$$\sum_{i=1}^{n} k - \lfloor \frac{k}{i} \rfloor i$$$$\sum_{i= ...
- 【poj2709】Painter--贪心
Painter Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 5621 Accepted: 3228 Descripti ...
- rep stos ptr dword es:[edi]
今天读代码时,忽然跳出如下一条指令==>>汇编代码: rep stos dword ptr es:[edi] 在网上查了相关资料显示:/************************** ...
- 在Android中使用OpenGL ES进行开发第(一)节:概念先行
一.前期基础是知识储备笔者计划写三篇文章来详细分析OpenGL ES基础的同时也是入门关键的三个点: ①OpenGL ES是什么?与OpenGL的关系是什么?——概念部分 ②使用OpenGL ES绘制 ...