mxnet深度学习实战学习笔记-9-目标检测
1.介绍
目标检测是指任意给定一张图像,判断图像中是否存在指定类别的目标,如果存在,则返回目标的位置和类别置信度
如下图检测人和自行车这两个目标,检测结果包括目标的位置、目标的类别和置信度

因为目标检测算法需要输出目标的类别和具体坐标,因此在数据标签上不仅要有目标的类别,还要有目标的坐标信息
可见目标检测比图像分类算法更复杂。图像分类算法只租要判断图像中是否存在指定目标,不需要给出目标的具体位置;而目标检测算法不仅需要判断图像中是否存在指定类别的目标,还要给出目标的具体位置
因此目标检测算法实际上是多任务算法,一个任务是目标的分类,一个任务是目标位置的确定;二图像分类算法是单任务算法,只有一个分类任务
2.数据集
目前常用的目标检测公开数据集是PASCAL VOC(http://host.robots.ox.ac.uk/pascal/VOC) 和COCO(http://cocodataset.org/#home)数据集,PASCAL VOC常用的是PASCAL VOC2007和PASCAL VOC2012两个数据集,COCO常用的是COCO2014和COCO2017两个数据集
在评价指标中,目标检测算法和常见的图像分类算法不同,目标检测算法常用mAP(mean average precision)作为评价模型效果的指标。mAP值和设定的IoU(intersection-over-union)阈值相关,不同的IoU阈值会得到不同的mAP。目前在PASCAL VOC数据集上常用IoU=0.5的阈值;在COCO数据集中IoU阈值选择较多,常在IoU=0.50:0.05:0.95这10个IoU阈值上分别计算AP,然后求均值作为最终的mAP结果
另外在COCO数据集中还有针对目标尺寸而定义的mAP计算方式,可以参考COCO官方网站(http://cocodataset.org/#detection-eval)中对评价指标的介绍
目标检测算法在实际中的应用非常广泛,比如基于通用的目标检测算法,做车辆、行人、建筑物、生活物品等检测。在该基础上,针对一些特定任务或者场景,往往衍生出特定的目标检测算法,如人脸检测和文本检测
人脸检测:即目前的刷脸,如刷脸支付和刷脸解锁。包括人脸检测和人脸识别这两个主要步骤。人脸检测就是先从输入图像中检测到人脸所在区域,然后将检测到的人脸作为识别算法的输入得到分类结果
文本检测:文字检测作为光学字符识别(optical character recognition,OCR)的重要步骤,主要目的在于从输入图像中检测出文字所在的区域,然后作为文字识别器的输入进行识别
目标检测算法可分为两种类型:one-stage和two-stage,两者的区别在于前者是直接基于网络提取到的特征和预定义的框(anchor)进行目标预测;后者是先通过网络提取到的特征和预定义的框学习得到候选框(region of interest,RoI),然后基于候选框的特征进行目标检测
- one-stage:代表是SSD(sigle shot detection)和YOLO(you only look once)等
- two-stage:代表是Faster-RCNN 等
两者的差异主要有两方面:
一方面是one-stage算法对目标框的预测只进行一次,而two-stage算法对目标框的预测有两次,类似从粗到细的过程
另一方面one-stage算法的预测是基于整个特征图进行的,而two-stage算法的预测是基于RoI特征进行的。这个RoI特征就是初步预测得到框(RoI)在整个特征图上的特征,也就是从整个特征图上裁剪出RoI区域得到RoI特征
3.目标检测基础知识
目标检测算法在网络结构方面和图像分类算法稍有不同,网络的主干部分基本上采用图像分类算法的特征提取网络,但是在网络的输出部分一般有两条支路,一条支路用来做目标分类,这部分和图像分类算法没有什么太大差异,也是通过交叉熵损失函数来计算损失;另一条支路用来做目标位置的回归,这部分通过Smooth L1损失函数计算损失。因此整个网络在训练时的损失函数是由分类的损失函数和回归的损失函数共同组成,网络参数的更新都是基于总的损失进行计算的,因此目标检测算法是多任务算法
1)one-stage
SSD算法首先基于特征提取网络提取特征,然后基于多个特征层设置不同大小和宽高比的anchor,最后基于多个特征层预测目标类别和位置,本章将使用的就是这个算法。
SSD算法在效果和速度上取得了非常好的平衡,但是在检测小尺寸目标上效果稍差,因此后续的优化算法,如DSSD、RefineDet等,主要就是针对小尺寸目标检测进行优化
YOLO算法的YOLO v1版本中还未引入anchor的思想,整体也是基于整个特征图直接进行预测。YOLO v2版本中算法做了许多优化,引入了anchor,有效提升了检测效果;通过对数据的目标尺寸做聚类分析得到大多数目标的尺寸信息从而初始化anchor。YOLO v3版本主要针对小尺寸目标的检测做了优化,同时目标的分类支路采用了多标签分类
2)two-stage
由RCNN 算法发展到Fast RCNN,主要引入了RoI Pooling操作提取RoI特征;再进一步发展到Faster RCNN,主要引入RPN网络生成RoI,从整个优化过程来看,不仅是速度提升明显,而且效果非常棒,目前应用广泛,是目前大多数two-stage类型目标检测算法的优化基础
Faster RCNN系列算法的优化算法非常多,比如R-FCN、FPN等。R-FCN主要是通过引入区域敏感(position sensitive)的RoI Pooling减少了Faster RCNN算法中的重复计算,因此提速十分明显。FPN算法主要通过引入特征融合操作并基于多个融合后的特征成进行预测,有效提高了模型对小尺寸目标的检测效果
虽然算法分为上面的两种类别,但是在整体流程上,主要可以分为三大部分:
- 主网络部分:主要用来提取特征,常称为backbone,一般采用图像分类算法的网络即可,比如常用的VGG和ResNet网络,目前也有在研究专门针对于目标检测任务的特征提取网络,比如DetNet
- 预测部分:包含两个支路——目标类别的分类支路和目标位置的回归支路。预测部分的输入特征经历了从单层特征到多层特征,从多层特征到多层融合特征的过程,算法效果也得到了稳定的提升。其中Faster RCNN算法是基于单层特征进行预测的例子,SSD算法是基于多层特征进行预测的例子,FRN算法是基于多层融合特征进行预测的例子
- NMS操作:(non maximum suppression,非极大值抑制)是目前目标检测算法常用的后处理操作,目的是去掉重复的预测框
3)准备数据集
VOL2007数据集包括9963张图像,其中训练验证集(trainval)有5011张图像(2G),测试集(test)有4952张
VOL2012数据集包含17125张图像,其中训练验证集(trainval)有11540张图像(450M),测试集(test)有5585张
首先使用命令下载数据:
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
下载完后会在当前目录下看见名为VOCtrainval_11-May-2012.tar、VOCtrainval_06-Nov-2007.tar和VOCtest_06-Nov-2007.tar这三个压缩包,然后运行下面的命令进行解压缩:
tar -xvf VOCtrainval_06-Nov-.tar
tar -xvf VOCtest_06-Nov-.tar
tar -xvf VOCtrainval_11-May-.tar
然后在当前目录下就会出现一个名为VOCdevkit的文件下,里面有两个文件为VOL2007和VOL2012,这里以VOL2007为例,可见有5个文件夹:
user@home:/opt/user/.../PASCAL_VOL_datasets/VOCdevkit/VOC2007$ ls
Annotations ImageSets JPEGImages SegmentationClass SegmentationObject
介绍这5个文件夹:
- Annotations:存放的是关于图像标注信息文件(后缀为.xml)
- ImageSets:存放的是训练和测试的图像列表信息
- JPEGImages:存放的是图像文件
- SegmentationClass: 存放的是和图像分割相关的数据,这一章暂不讨论,下章再说
- SegmentationObject:存放的是和图像分割相关的数据,这一章暂不讨论,下章再说
ImageSets文件中有下面的四个文件夹:
- Action:存储人的动作
- Layout:存储人的部位
- Main:存储检测索引
- Segmentation :存储分割
其中Main中,每个类都有对应的classname_train.txt、classname_val.txt和classname_trainval.txt三个索引文件,分别对应训练集,验证集和训练验证集(即训练集+验证集)。
另外还有一个train.txt(5717)、val.txt(5823)和trainval.txt(11540)为所有类别的一个索引。
Annotations包含于图像数量相等的标签文件(后缀为.xml),ls命令查看,有000001.xml到009963.xml这9963个文件
查看其中的000001.xml文件:
user@home:/opt/user/.../PASCAL_VOL_datasets/VOCdevkit/VOC2007/Annotations$ cat .xml
<annotation>
<folder>VOC2007</folder> <!--数据集名称 -->
<filename>.jpg</filename> <!--图像名称 -->
<source>
<database>The VOC2007 Database</database>
<annotation>PASCAL VOC2007</annotation>
<image>flickr</image>
<flickrid></flickrid>
</source>
<owner>
<flickrid>Fried Camels</flickrid>
<name>Jinky the Fruit Bat</name>
</owner>
<size> <!--图像长宽信息 -->
<width></width>
<height></height>
<depth></depth>
</size>
<segmented></segmented>
<object> <!--两个目标的标注信息 -->
<name>dog</name> <!--目标的类别名,类别名以字符结尾,该类别为dog -->
<pose>Left</pose>
<truncated></truncated>
<difficult></difficult>
<bndbox> <!--目标的坐标信息,以字符结尾,包含4个坐标标注信息,且标注框都是矩形框 -->
<xmin></xmin> <!--矩形框左上角点横坐标 -->
<ymin></ymin> <!--矩形框左上角点纵坐标 -->
<xmax></xmax> <!--矩形框右下角点横坐标 -->
<ymax></ymax> <!--矩形框右下角点纵坐标 -->
</bndbox>
</object>
<object>
<name>person</name> <!--目标的类别名,类别名以字符结尾,该类别为person -->
<pose>Left</pose>
<truncated></truncated>
<difficult></difficult>
<bndbox>
<xmin></xmin>
<ymin></ymin>
<xmax></xmax>
<ymax></ymax>
</bndbox>
</object>
</annotation>
初了查看标签文件之外,还可以通过可视化方式查看这些真实框的信息,下面代码根据VOC数据集的一张图像和标注信息得到带有真实框标注的图像
运行时出现一个问题:
_tkinter.TclError: no display name and no $DISPLAY environment variable
原因是我们不是在Windows下跑的,是在Linux下跑的,不同的系统有不同的用户图形接口,所以要更改它的默认配置,把模式更改成Agg。即在代码最上面添加一行代码:
import matplotlib
matplotlib.use('Agg')
代码是:
import mxnet as mx
import xml.etree.ElementTree as ET
import matplotlib
matplotlib.use('Agg')
import matplotlib.pyplot as plt
import matplotlib.patches as patches
import random #解析指定的xml标签文件,得到所有objects的名字和边框信息
def parse_xml(xml_path):
bbox = []
tree = ET.parse(xml_path)
root = tree.getroot()
objects = root.findall('object') #得到一个xml文件中的所有目标,这个例子中有dog和person两个object
for object in objects:
name = object.find('name').text #object的名字,即dog或person
bndbox = object.find('bndbox')#得到object的坐标信息
xmin = int(bndbox.find('xmin').text)
ymin = int(bndbox.find('ymin').text)
xmax = int(bndbox.find('xmax').text)
ymax = int(bndbox.find('ymax').text)
bbox_i = [name, xmin, ymin, xmax, ymax]
bbox.append(bbox_i)
return bbox
#根据从xml文件中得到的信息,标注object边框并生成一张图片实现可视化
def visualize_bbox(image, bbox, name):
fig, ax = plt.subplots()
plt.imshow(image)
colors = dict()#指定标注某个对象的边框的颜色
for bbox_i in bbox:
cls_name = bbox_i[] #得到object的name
if cls_name not in colors:
colors[cls_name] = (random.random(), random.random(), random.random()) #随机生成标注name为cls_name的object的边框颜色
xmin = bbox_i[]
ymin = bbox_i[]
xmax = bbox_i[]
ymax = bbox_i[]
#指明对应位置和大小的边框
rect = patches.Rectangle(xy=(xmin, ymin), width=xmax-xmin, height=ymax-ymin, edgecolor=colors[cls_name],facecolor='None',linewidth=3.5)
plt.text(xmin, ymin-, '{:s}'.format(cls_name), bbox=dict(facecolor=colors[cls_name], alpha=0.5))
ax.add_patch(rect)
plt.axis('off')
plt.savefig('./{}_gt.png'.format(name)) #将该图片保存下来
plt.close() if __name__ == '__main__':
name = ''
img_path = '/opt/user/.../PASCAL_VOL_datasets/VOCdevkit/VOC2007/JPEGImages/{}.jpg'.format(name)
xml_path = '/opt/user/.../PASCAL_VOL_datasets/VOCdevkit/VOC2007/Annotations/{}.xml'.format(name)
bbox = parse_xml(xml_path=xml_path)
image_string = open(img_path, 'rb').read()
image = mx.image.imdecode(image_string, flag=).asnumpy()
visualize_bbox(image, bbox, name)
运行:
user@home:/opt/user/.../PASCAL_VOL_datasets$ python2 mxnet_9_1.py
/usr/local/lib/python2./dist-packages/h5py/__init__.py:: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.
from ._conv import register_converters as _register_converters
返回的图片000001_gt.png是:

4)SSD算法简介
SSD时目前应用非常广泛的目标检测算法,其网络结构如下图所示:
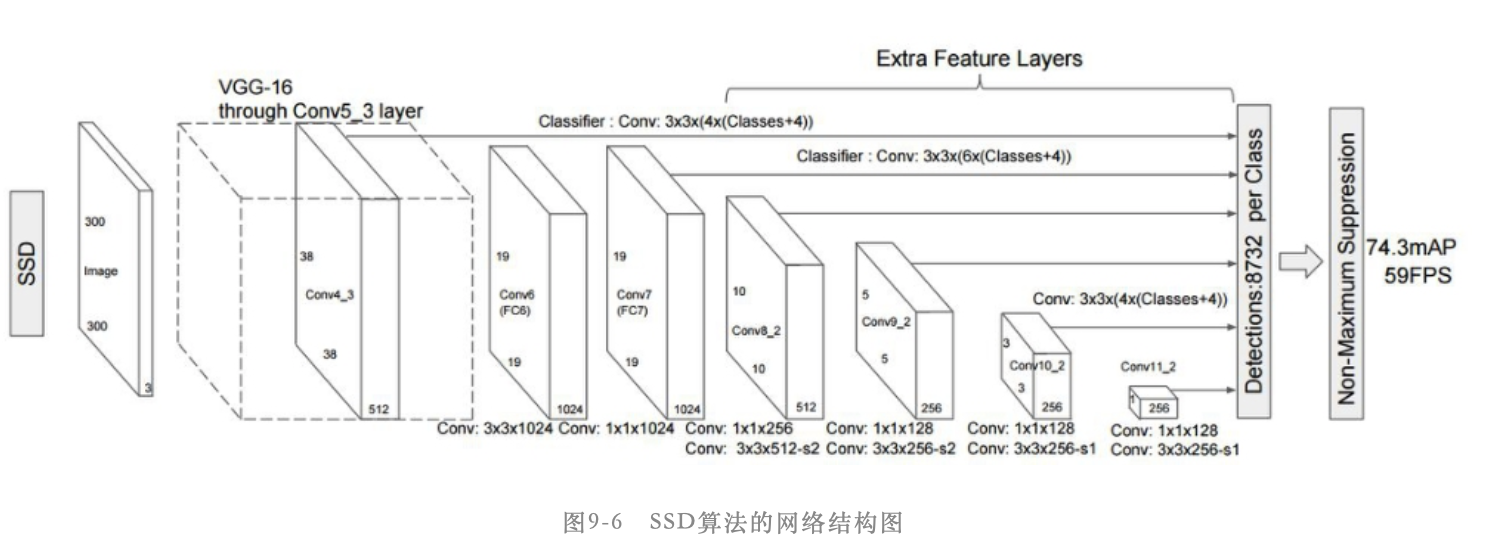
该算法采用修改后的16层网络作为特征提取网络,修改内容主要是将2个全连接层(图中的FC6和FC7)替换成了卷积层(图中的Conv6和Conv7),另外将第5个池化层pool5改成不改变输入特征图的尺寸。然后在网络的后面(即Conv7后面)添加一系列的卷积层(Extra Feature Layer),即图中的Conv8_2、Conv9_2、Conv10_2和Conv11_2,这样就构成了SSD网络的主体结构。
这里要注意Conv8_2、Conv9_2、Conv10_2和Conv11_2并不是4个卷积层,而是4个小模块,就像是resent网络中的block一样。以Conv8_2为例,Conv8_2包含一个卷积核尺寸是1*1的卷积层和一个卷积核尺寸为3*3的卷积层,同时这2个卷积层后面都有relu类型的激活层。当然这4个模块还有一些差异,Conv8_2和Conv9_2的3*3卷积层的stride参数设置为2、pad参数设置为1,最终能够将输入特征图维度缩小为原来的一半;而Conv10_2和Conv11_2的3*3卷积层的stride参数设置为1、pad参数设置为0
在SSD算法中采用基于多个特征层进行预测的方式来预测目标框的位置,具体而言就是使用Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2和Conv11_2这6个特征层的输出特征图来进行预测。假设输入图像大小是300*300,那么这6个特征层的输出特征图大小分别是38*38、19*19、10*10、5*5、3*3和1*1。每个特征层都会有目标类别的分类支路和目标位置的回归支路,这两个支路都是由特定 卷积核数量的卷积层构成的,假设在某个特征层的特征图上每个点设置了k个anchor,目标的类别数一共是N,那么分类支路的卷积核数量就是K*(N+1),其中1表示背景类别;回归支路的卷积核数量就是K*4,其中4表示坐标信息。最终将这6个预测层的分类结果和回归结果分别汇总到一起就构成整个网络的分类和回归结果
5)anchor
该名词最早出现在Faster RCNN系列论文中,表示一系列固定大小、宽高比的框,这些框均匀地分布在输入图像上, 而检测模型的目的就是基于这些anchor得到预测狂的偏置信息(offset),使得anchor加上偏置信息后得到的预测框能尽可能地接近真实目标框。在SSD论文中的default box名词,即默认框,和anchor的含义是类似的
MXNet框架提供了生成anchor的接口:mxnet.ndarray.contrib.MultiBoxPrior(),接下来通过具体数据演示anchor的含义
首先假设输入特征图大小是2*2,在SSD算法中会在特征图的每个位置生成指定大小和宽高比的anchor,大小的设定通过mxnet.ndarray.contrib.MultiBoxPrior()接口的sizes参数实现,而宽高比通过ratios参数实现,代码如下:
import mxnet as mx
import matplotlib.pyplot as plt
import matplotlib.patches as patches input_h =
input_w =
input = mx.nd.random.uniform(shape=(,,input_h, input_w))
anchors = mx.ndarray.contrib.MultiBoxPrior(data=input, sizes=[0.3], ratios=[])
print(anchors)
返回:
[[[0.09999999 0.09999999 0.4 0.4 ]
[0.6 0.09999999 0.9 0.4 ]
[0.09999999 0.6 0.4 0.9 ]
[0.6 0.6 0.9 0.9 ]]]
<NDArray 1x4x4 @cpu()>
可见因为输入特征图大小是2*2,且设定的anchor大小和宽高比都只有1种,因此一共得到4个anchor,每个anchor都是1*4的向量,分别表示[xmin,ymin,xmax,ymax],也就是矩形框的左上角点坐标和右下角点坐标
接下来通过维度变换可以更清晰地看到anchor数量和输入特征维度的关系,最后一维的4表示每个anchor的4个坐标信息:
anchors = anchors.reshape((input_h, input_w, -, ))
print(anchors.shape)
anchors
返回:
(, , , ) [[[[0.09999999 0.09999999 0.4 0.4 ]] [[0.6 0.09999999 0.9 0.4 ]]] [[[0.09999999 0.6 0.4 0.9 ]] [[0.6 0.6 0.9 0.9 ]]]]
<NDArray 2x2x1x4 @cpu()>
那么这4个anchor在输入图像上具体是什么样子?接下来将这些anchor显示在一张输入图像上,首先定义一个显示anchor的函数:
def plot_anchors(anchors, sizeNum, ratioNum): #sizeNum和ratioNum只是用于指明生成的图的不同anchor大小和高宽比
img = mx.img.imread('./000001.jpg')
height, width, _ = img.shape
fig, ax = plt.subplots()
ax.imshow(img.asnumpy())
edgecolors = ['r', 'g', 'y', 'b']
for h_i in range(anchors.shape[]):
for w_i in range(anchors.shape[]):
for index, anchor in enumerate(anchors[h_i, w_i, :, :].asnumpy()):
xmin = anchor[]*width
ymin = anchor[]*height
xmax = anchor[]*width
ymax = anchor[]*height
rect = patches.Rectangle(xy=(xmin,ymin), width=xmax-xmin,
height=ymax-ymin,edgecolor=edgecolors[index],
facecolor='None', linewidth=1.5)
ax.add_patch(rect)
plt.savefig('./mapSize_{}*{}_sizeNum_{}_ratioNum_{}.png'.format(anchors.shape[],
anchors.shape[], sizeNum, ratioNum))
调用函数:
plot_anchors(anchors, , )
返回:
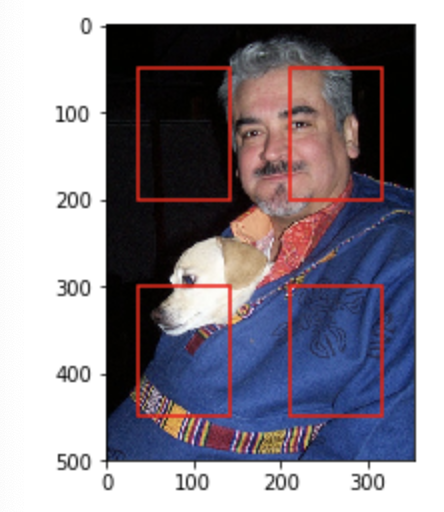
通过修改或增加anchor的宽高比及大小可以得到不同数量的anchor,比如增加宽高比为2和0.5的anchor
input_h =
input_w =
input = mx.nd.random.uniform(shape=(,,input_h, input_w))
anchors = mx.nd.contrib.MultiBoxPrior(data=input, sizes=[0.3],ratios=[,,0.5])
anchors = anchors.reshape((input_h, input_w, -, ))
print(anchors.shape)
plot_anchors(anchors, , )
返回:
(, , , )
图为:
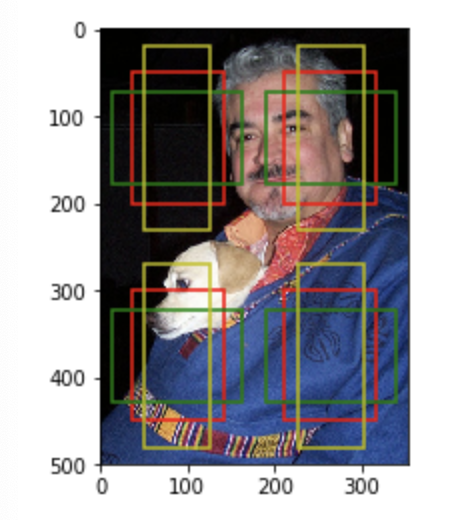
输出结果说明在2*2的特征图上的每个点都生成了3个anchor
接下来再增加大小为0.4的anchor:
input_h =
input_w =
input = mx.nd.random.uniform(shape=(,,input_h, input_w))
anchors = mx.nd.contrib.MultiBoxPrior(data=input, sizes=[0.3,0.4],ratios=[,,0.5])
anchors = anchors.reshape((input_h, input_w, -, ))
print(anchors.shape)
plot_anchors(anchors, , )
返回:
(, , , )
图为:

说明在2*2大小的特征图上的每个点都生成了4个anchor,为什么得到的是4个,而不是2*3=6个呢?
因为在SSD论文中设定anchor时并不是组合所有设定的尺寸和宽高对比度值,而是分成2部分,一部分是针对每种宽高对比度都与其中一个尺寸size进行组合;另一部分是针对宽高对比度为1时,还会额外增加一个新尺寸与该宽高对比度进行组合
举例说明sizes=[s1, s2, ..., sm], ratios=[r1, r2,...,rn],计算得到的anchor数量为m+n-1,所以当m=2,n=3时,得到的anchor数就是4
首先第一部分就是sizes[0]会跟所有ratios组合,这就有n个anchor了;第二部分就是sizes[1:]会和ratios[0]组合,这样就有m-1个anchor了。对应这个例子就是[(0.3,1), (0.3,2), (0.3,0.5), (0.4,1)]。SSD论文中ratios参数的第一个值要设置为1
上面的例子使用的是2*2的特征图,下面改成5*5的特征图:
input_h =
input_w =
input = mx.nd.random.uniform(shape=(,,input_h, input_w))
anchors = mx.nd.contrib.MultiBoxPrior(data=input, sizes=[0.1,0.15],ratios=[,,0.5])
anchors = anchors.reshape((input_h, input_w, -, ))
print(anchors.shape)
plot_anchors(anchors, , )
返回:
(, , , )
图为:
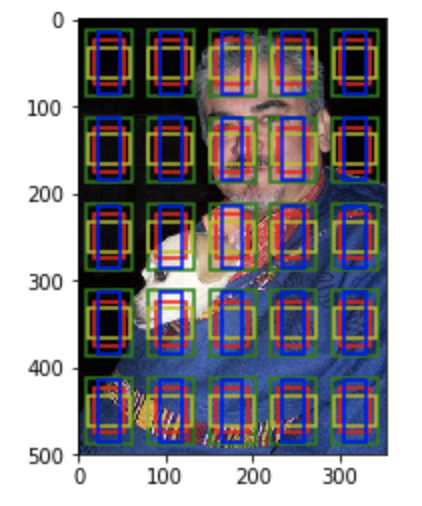
需要说明的是上述代码中设定的anchor大小和特征图大小都是比较特殊的值,因此特征图上不同点之间的anchor都没有重叠,这是为了方便显示anchor而设置的。在实际的SSD算法中,特征图上不同点之间的anchor重叠特别多,因此基本上能够覆盖所有物体
SSD算法基于多个特征层进行目标的预测,这些特征层的特征图大小不一,因此设置的anchor大小也不一样,一般而言在网络的浅层部分特征图尺寸较大(如38*38、19*19),此时设置的anchor尺寸较小(比如0.1、0.2),主要用来检测小尺寸目标;在网络的深层部分特征图尺寸较小(比如3*3、1*1),此时设置的anchor尺寸较大(比如0.8、0.9),主要用来检测大尺寸目标
6)IoU
在目标检测算法中,我们经常需要评价2个矩形框之间的相似性,直观来看可以通过比较2个框的距离、重叠面积等计算得到相似性,而IoU指标恰好可以实现这样的度量。简而言之,IoU(intersection over union,交并比)是目标检测算法中用来评价2个矩形框之间相似度的指标
IoU = 两个矩形框相交的面积 / 两个矩形框相并的面积,如下图所示:
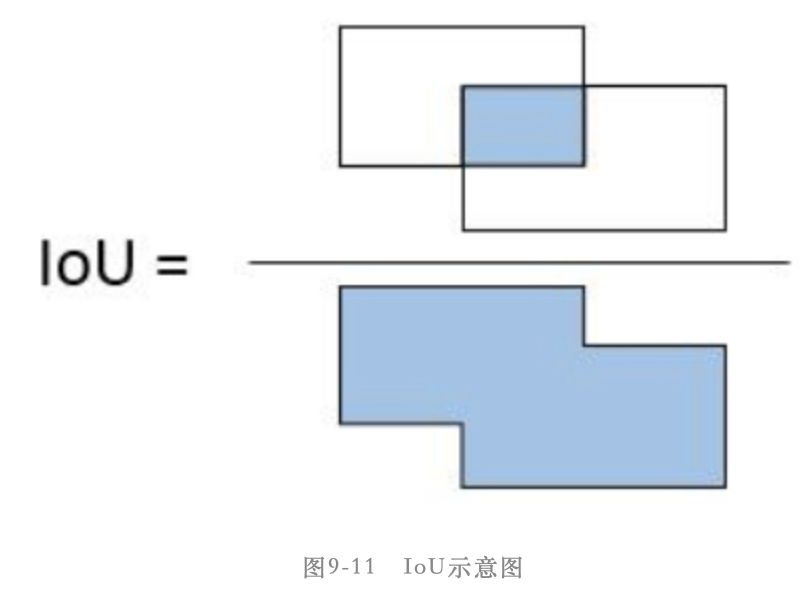
其作用是在我们设定好了anchor后,需要判断每个anchor的标签,而判断的依据就是anchor和真实目标框的IoU。假设某个anchor和某个真实目标框的IoU大于设定的阈值,那就说明该anchor基本覆盖了这个目标,因此就可以认为这个anchor的类别就是这个目标的类别
另外在NMS算法中也需要用IoU指标界定2个矩形框的重合度,当2个矩形框的IoU值超过设定的阈值时,就表示二者是重复框
7)模型训练目标
目标检测算法中的位置回归目标一直是该类算法中较难理解的部分, 一开始都会认为回归部分的训练目标就是真实框的坐标,其实不是。网络的回归支路的训练目标是offset,这个offset是基于真实框坐标和anchor坐标计算得到的偏置,而回归支路的输出值也是offset,这个offset是预测框坐标和anchor坐标之间的偏置。因此回归的目的就是让这个偏置不断地接近真实框坐标和anchor坐标之间的偏置
使用的接口是:mxnet.ndarray.contrib.MultiBoxTarget(),生成回归和分类的目标
import mxnet as mx
import matplotlib.pyplot as plt
import matplotlib.patches as patches def plot_anchors(anchors, img, text, linestyle='-'): #定义可视化anchor或真实框的位置的函数
height, width, _ = img.shape
colors = ['r','y','b','c','m']
for num_i in range(anchors.shape[]):
for index, anchor in enumerate(anchors[num_i,:,:].asnumpy()):
xmin = anchor[]*width
ymin = anchor[]*height
xmax = anchor[]*width
ymax = anchor[]*height
rect = patches.Rectangle(xy=(xmin,ymin), width=xmax-xmin,
height=ymax-ymin, edgecolor=colors[index],
facecolor='None', linestyle=linestyle,
linewidth=1.5)
ax.text(xmin, ymin, text[index],
bbox=dict(facecolor=colors[index], alpha=0.5))
ax.add_patch(rect)
#读取输入图像
img = mx.img.imread("./000001.jpg")
fig,ax = plt.subplots()
ax.imshow(img.asnumpy())
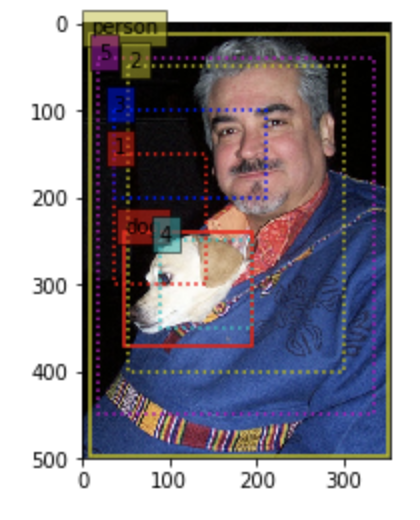
#在上面的输入图像上标明真实框的位置
ground_truth = mx.nd.array([[[, 0.136,0.48,0.552,0.742], #对应类别0 dog的真实框坐标值
[, 0.023,0.024,0.997,0.996]]])#对应类别1 person的真实框坐标值
plot_anchors(anchors=ground_truth[:, :, :], img=img,
text=['dog','person'])
#在上面的输入图像上标明anchor的位置
#坐标值表示[xmin, ymin, xmax, ymax]
anchor = mx.nd.array([[[0.1, 0.3, 0.4, 0.6],
[0.15, 0.1, 0.85, 0.8],
[0.1, 0.2, 0.6, 0.4],
[0.25, 0.5, 0.55, 0.7],
[0.05, 0.08, 0.95, 0.9]]])
plot_anchors(anchors=anchor, img=img, text=['','','','',''],
linestyle=':')
#然后保存图片,图片如下图所示
plt.savefig("./anchor_gt.png")
图为:
接下来初始化一个分类预测值,维度是1*2*5,其中1表示图像数量,2表示目标类别,这里假设只有人和狗两个类别,5表示anchor数量,然后就可以通过mxnet.ndarray.contrib.MultiBoxTarget()接口获取模型训练的目标值。
该接口主要包含一下几个输入:
- anchor :该参数在计算回归目标offset时需要用到
- label:该参数在计算回归目标offset和分类目标时都用到
- cls_pred :该参数内容其实在这里并未用到,因此只要维度符合要求即可
- overlap_threshold: 该参数表示当预测框和真实框的IoU大于这个值时,该预测框的分类和回归目标就和该真实框对应
- ignore_label :该参数表示计算回归目标时忽略的真实框类别标签,因为训练过程中一个批次有多张图像,每张图像的真实框数量都不一定相同,因此会采用全 -1 值来填充标签使得每张图像的真实标签维度相同,因此这里相当于忽略掉这些填充值
- negative_mining_ratio :该参数表示在对负样本做过滤时设定的正负样本比例是1:3
- variances :该参数表示计算回归目标时中心点坐标(x和y)的权重是0.1,宽和高的offset权重是0.2
cls_pred = mx.nd.array([[[0.4, 0.3, 0.2, 0.1, 0.1],
[0.6, 0.7, 0.8, 0.9, 0.9]]])
tmp = mx.nd.contrib.MultiBoxTarget(anchor=anchor, label=ground_truth,
cls_pred=cls_pred, overlap_threshold=0.5,
ignore_label=-, negative_mining_ratio=,
variances=[0.1,0.1,0.2,0.2])
print("location target: {}".format(tmp[]))
print("location target mask: {}".format(tmp[]))
print("classification target: {}".format(tmp[]))
这里三个变量的含义是:
- tmp[0] : 输出的是回归支路的训练目标,也就是我们希望模型的回归支路输出值和这个目标的smooth L1损失值要越小越好。可以看见tmp[0]的维度是1*20,其中1表示图像数量,20是4*5的意思,也就是5个anchor,每个anchor有4个坐标信息。另外tmp[0]中有部分是0,表示这些anchor都是负样本,也就是背景,可以从输出结果看出1号和3号anchor是背景
- tmp[1]:输出的是回归支路的mask,该mask中对应正样本anchor的坐标用1填充,对应负样本anchor的坐标用0填充。该变量是在计算回归损失时用到,计算回归损失时负样本anchor是不参与计算的
- tmp[2]:输出的是每个anchor的分类目标,在接口中默认类别0表示背景类,其他类别依次加1,因此dog类别就用类别1表示,person类别就用类别2表示
返回:
location target:
[[ . . . . 0.14285699 0.8571425
1.6516545 1.6413777 . . . .
-1.8666674 0.5499989 1.6345134 1.3501359 0.11111101 0.24390258
0.3950827 0.8502576 ]]
<NDArray 1x20 @cpu()>
location target mask:
[[. . . . . . . . . . . . . . . . . . . .]]
<NDArray 1x20 @cpu()>
classification target:
[[. . . . .]]
<NDArray 1x5 @cpu()>
所以从上面的结果我们可以知道,anchor 1和3是背景,anchor 2和5是person,4是dog
那么anchor的类别怎么定义呢?
在SSD算法中,首先每个真实框和N个anchor会计算到N个IoU,这N个IoU中的最大值对应的anchor就是正样本,而且类别就是这个真实框的类别。比如上面的图中与person这个真实框计算得到的IoU中最大的是5号anchor,所以5号anchor的分类目标就是person,也就是类别2,所以上面tmp[2][4]的值为2。同理,dog这个真实框的IoU最大的是4号anchor,因此4号anchor的分类目标就是dog,也就是类别1,所以上面的tmp[2][3]等于1。
除了IoU最大的anchor是正样本外,和真实框的IoU大于设定的IoU阈值的anchor也是正样本。这个阈值就是mxnet.ndarray.contrib.MultiBoxTarget()接口中的overlap_threshold参数设置的。显然可以看出2号anchor和person这个真实框的IoU大于设定的0.5阈值,因此2号anchor的预测类别为person,即类别2,tmp[2][1]等于2
关于回归目标的计算,在SSD论文中通过公式2已经介绍非常详细了。假设第i个anchor(用di表示),第j个真实框(用gi表示),那么回归目标就是如下这4个值:

按照上面的公式得到的就是输出的tmp[0]的值
8)NMS
在目标检测算法中,我们希望每一个目标都有一个预测框准确地圈出目标的位置并给出预测类别。但是检测模型的输出预测框之间可能存在重叠,也就是说针对一个目标可能会有几个甚至几十个预测对的预测框,这显然不是我们想要的,因此就有了NMS操作
NMS(non maximum suprression,非极大值抑制)是目前目标检测算法常用的后处理操作,目的是去掉重复的预测框
NMS算法的过程大致如下:
假设网络输出的预测框中预测类别为person的框有K个,每个预测框都有1个预测类别、1个类别置信度和4个坐标相关的值。K个预测框中有N个预测框的类别置信度大于0。首先在N个框中找到类别置信度最大的那个框,然后计算剩下的N-1个框和选出来的这个框的IoU值,IoU值大于预先设定的阈值的框即为重复预测框(假设有M个预测框和选出来的框重复),剔除这M个预测框(这里将这M个预测框的类别置信度设置为0,表示剔除),保留IoU小于阈值的预测框。接下来再从N-1-M个预测框中找到类别置信度最大的那个框,然后计算剩下的N-2-M个框和选出来的这个框的IoU值,同样将IoU值大于预先设定的阈值的框剔除,保留IoU值小于阈值的框,然后再进行下一轮过滤,一直进行到所有框都过滤结束。最终保留的预测框就是输出结果,这样任意两个框的IoU都小于设定的IoU阈值,就达到去掉重复预测框的目的
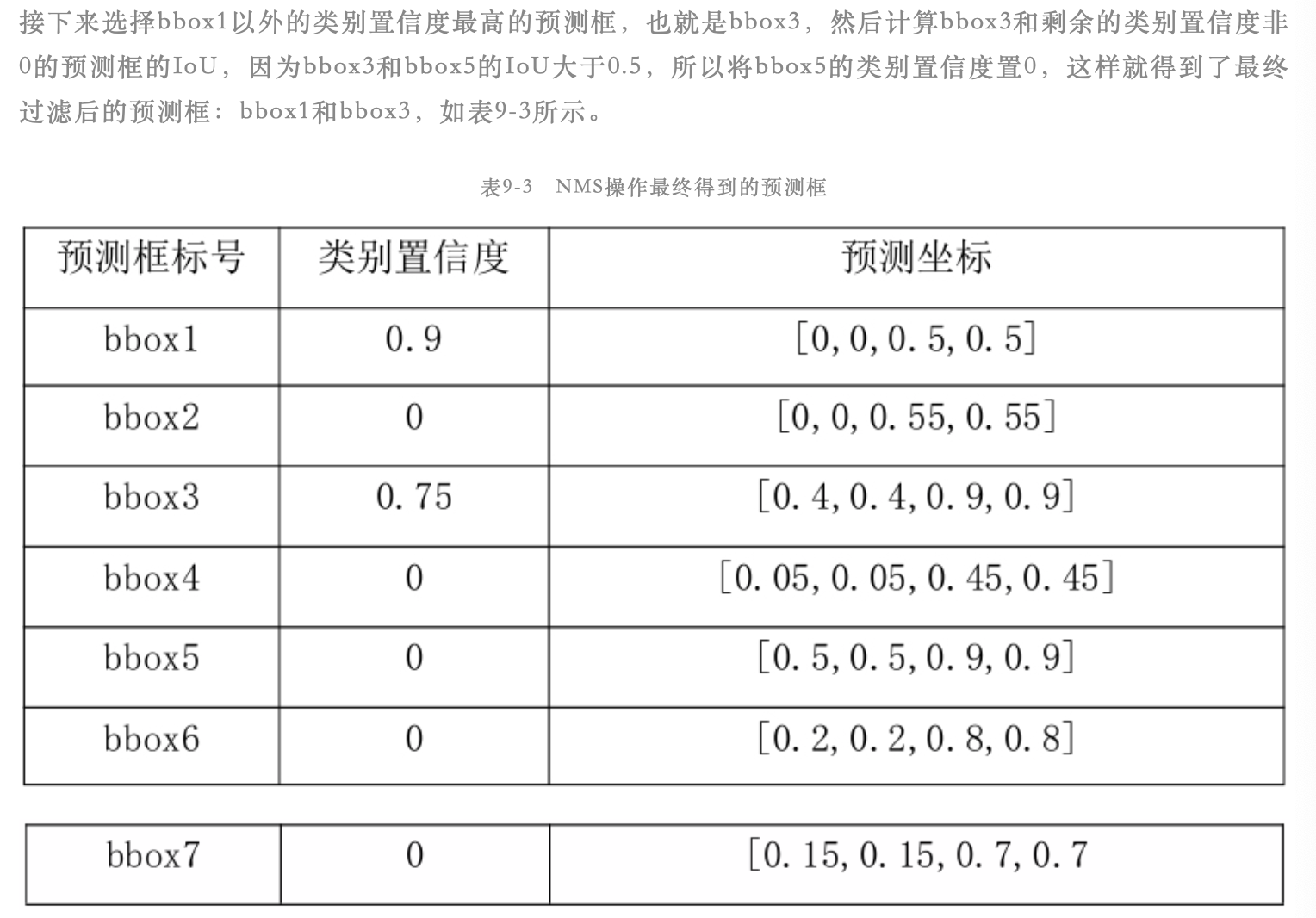
9)评价指标mAP
在目标检测算法中常用的评价指标是mAP(mean average precision),这是一个可以用来度量模型预测框类别和位置是否准确的指标。在目标检测领域常用的公开数据集PASCAL VOC中,有2种mAP计算方式,一种是针对PASCAL VOL 2007数据集的mAP计算方式,另一种是针对PASCAL VOC 2012数据集的mAP计算方式,二者差异较小,这里主要是用第一种
含义和计算过程如下:
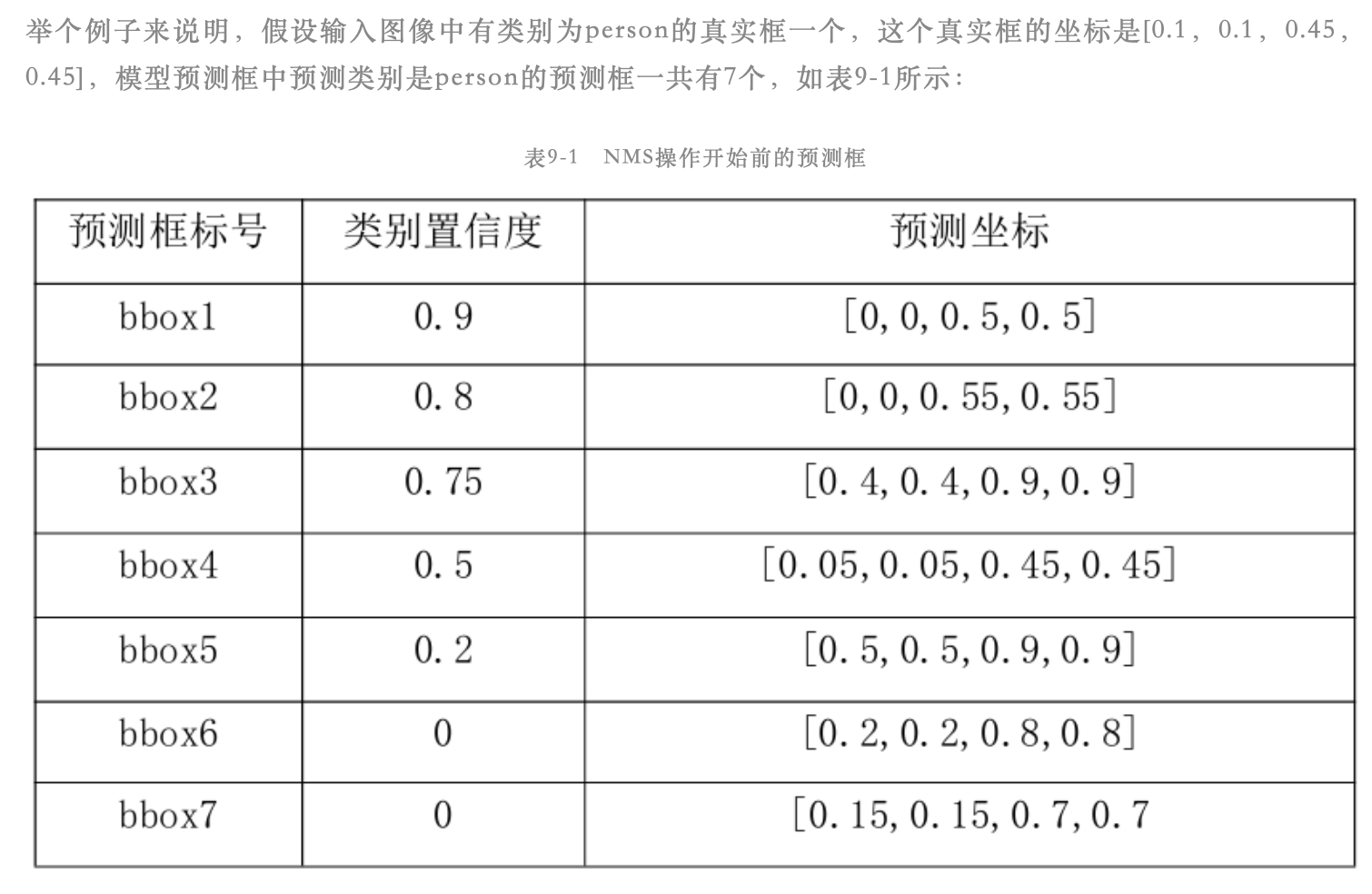
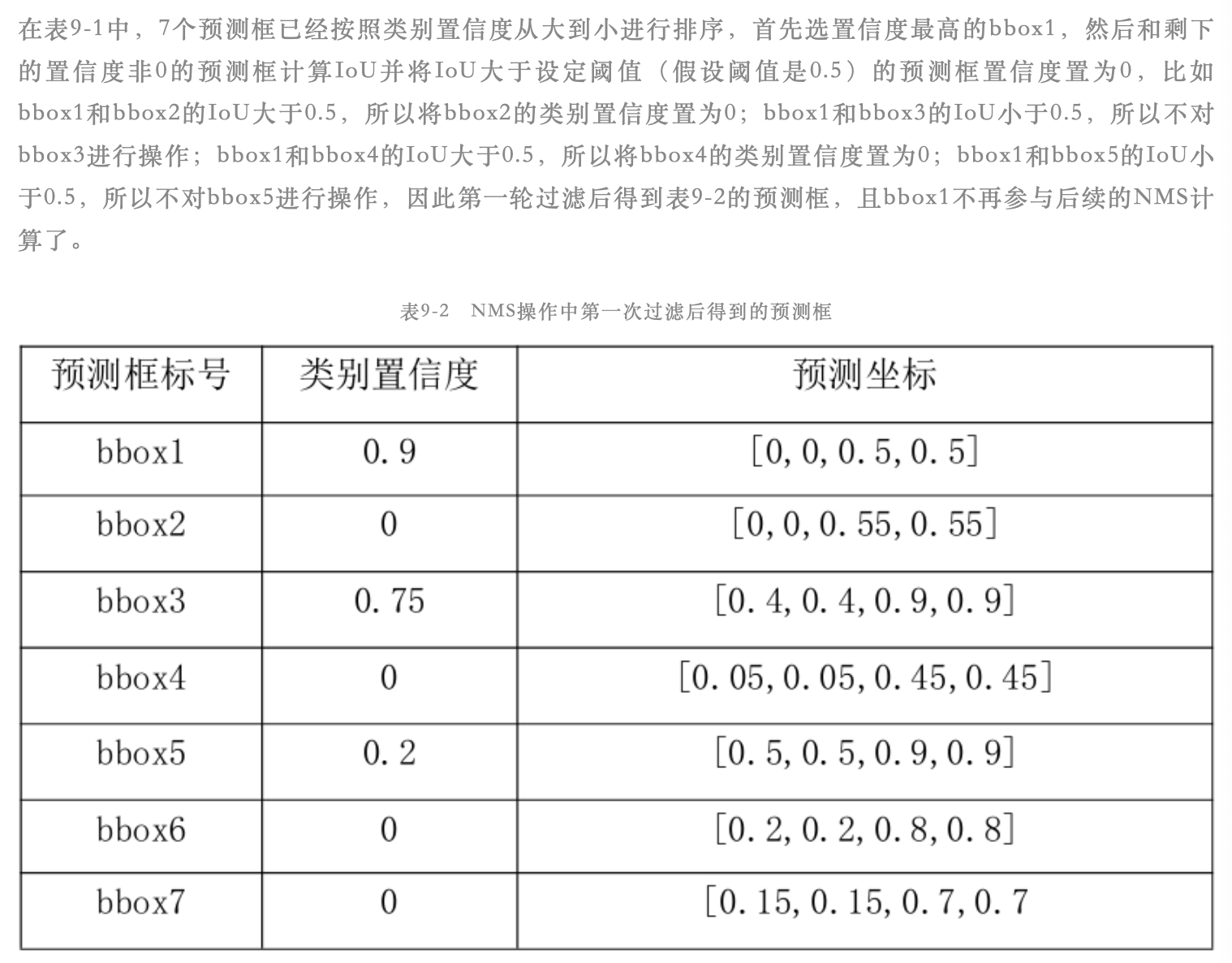
假设某输入图像中有两个真实框:person和dog,模型输出的预测框中预测类别为person的框有5个,预测类别是dog的框有3个,此时的预测框已经经过NMS后处理。
首先以预测类别为person的5个框为例,先对这5个框按照预测的类别置信度进行从大到小排序,然后这5个值依次和person类别的真实框计算IoU值。假设IoU值大于预先设定的阈值(常设为0.5),那就说明这个预测框是对的,此时这个框就是TP(true positive);假设IoU值小于预先设定的阈值(常设为0.5),那就说明这个预测框是错的,此时这个框就是FP(false positive)。注意如果这5个预测框中有2个预测框和同一个person真实框的IoU大于阈值,那么只有类别置信度最大的那个预测框才算是预测对了,另一个算是FP
假设图像的真实框类别中不包含预测框类别,此时预测框类别是cat,但是图像的真实框只有person和dog,那么也算该预测框预测错了,为FP
FN(false negative)的计算可以通过图像中真实框的数量间接计算得到,因为图像中真实框的数量 = TP + FN

癌症类别的精确度就是指模型判断为癌症且真实类别也为癌症的图像数量/模型判断为癌症的图像数量,计算公式如下图:
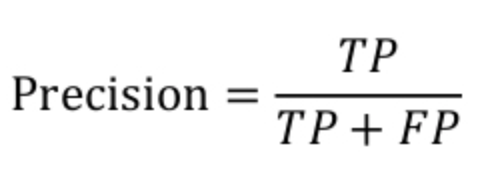
召回率是指模型判为癌症且真实类别也是癌症的图像数量/真实类别是癌症的图像数量,计算公式为:
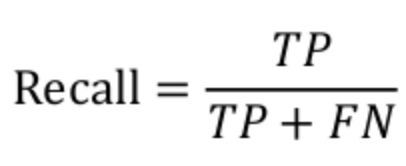
得到的person类精确度和召回率都是一个列表,列表的长度和预测类别为person的框相关,因此根据这2个列表就可以在一个坐标系中画出该类别的precision和recall曲线图
按照PASCAL VOL 2007的mAP计算方式,在召回率坐标轴均匀选取11个点(0, 0.1, ..., 0.9, 1),然后计算在召回率大于0的所有点中,精确度的最大值是多少;计算在召回率大于0.1的所有点中,精确度的最大值是多少;一直计算到在召回率大于1时,精确度的最大值是多少。这样我们最终得到11个精确度值,对这11个精确度求均值久得到AP了,因此AP中的A(average)就代表求精确度均值的过程
mAP和AP的关系是:
因为我们有两个类别,所以会得到person和dog两个类别对应的AP值,这样将这2个AP求均值就得到了mAP
所以如果有N个类别,就分别求这N个类别的AP值,然后求均值就得到mAP了
上面说到有两种mAP计算方式,两者的不同在于AP计算的不同,对于2012标准,是以召回率为依据计算AP
那么为什么可以使用mAP来评价目标检测的效果;
目标检测的效果取决于预测框的位置和类别是否准确,从mAP的计算过程中可以看出通过计算预测框和真实框的IoU来判断预测框是否准确预测到了位置信息,同时精确度和召回率指标的引用可以评价预测框的类别是否准确,因此mAP是目前目标检测领域非常常用的评价指标
4.通用目标检测
1)数据准备
当要在自定义数据集上训练检测模型时,只需要将自定义数据按照PASCAL VOC数据集的维护方式进行维护,就可以顺利进行
本节采用的训练数据包括VOC2007的trainval.txt和VOC2012的trainval.txt,一共16551张图像;验证集采用VOC2007的test.txt,一共4952张图像,这是常用的划分方式
另外为了使数据集更加通用,将VOC2007和VOC2012的trainval.txt文件(在/ImageSets/Main文件夹中)合并在一起,同时合并对应的图像文件夹JPEGImages和标签文件夹Annotations
手动操作,创建一个新的文件夹PASCAL_VOC_converge将需要的文件在这里合并
首先合并JPEGImages:
cp -r /opt/user/.../PASCAL_VOL_datasets/VOCdevkit/VOC2007/JPEGImages/. /opt/user/.../PASCAL_VOC_converge/JPEGImages
cp -r /opt/user/.../PASCAL_VOL_datasets/VOCdevkit/VOC2012/JPEGImages/. /opt/user/.../PASCAL_VOC_converge/JPEGImages
然后合并Annotations:
cp -r /opt/user/.../PASCAL_VOL_datasets/VOCdevkit/VOC2007/Annotations/. /opt/user/.../PASCAL_VOC_converge/Annotations
cp -r /opt/user/.../PASCAL_VOL_datasets/VOCdevkit/VOC2012/Annotations/. /opt/user/.../PASCAL_VOC_converge/Annotations
然后将两者的trainval.txt内容放在同一个trainval.txt中,然后要将trainval.txt和VOC2007的test.txt都放进新创建的lst文件夹中
最后新的文件夹PASCAL_VOC_converge中的文件为:
user@home:/opt/user/.../PASCAL_VOC_converge$ ls
Annotations create_list.py JPEGImages lst
user@home:/opt/user/.../PASCAL_VOC_converge/lst$ ls
test.txt trainval.txt
然后接下来开始基于数据生成.lst文件和RecordIO文件,生成.lst文件的脚本为create_list.py:
import os
import argparse
from PIL import Image
import xml.etree.ElementTree as ET
import random def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument('--set', type=str, default='train')
parser.add_argument('--save-path', type=str, default='')
parser.add_argument('--dataset-path', type=str, default='')
parser.add_argument('--shuffle', type=bool, default=False)
args = parser.parse_args()
return args def main():
label_dic = {"aeroplane": , "bicycle": , "bird": , "boat": , "bottle": , "bus": ,
"car": , "cat": , "chair": , "cow": , "diningtable": , "dog": ,
"horse": , "motorbike": , "person": , "pottedplant": , "sheep": ,
"sofa": , "train": , "tvmonitor": }
args = parse_args()
if not os.path.exists(os.path.join(args.save_path, "{}.lst".format(args.set))):
os.mknod(os.path.join(args.save_path, "{}.lst".format(args.set)))
with open(os.path.join(args.save_path, "{}.txt".format(args.set)), "r") as input_file:
lines = input_file.readlines()
if args.shuffle:
random.shuffle(lines)
with open(os.path.join(args.save_path, "{}.lst".format(args.set)), "w") as output_file:
index =
for line in lines:
line = line.strip()
out_str = "\t".join([str(index), "", ""])
img = Image.open(os.path.join(args.dataset_path, "JPEGImages", line+".jpg"))
width, height = img.size
xml_path = os.path.join(args.dataset_path, "Annotations", line+".xml")
tree = ET.parse(xml_path)
root = tree.getroot()
objects = root.findall('object')
for object in objects:
name = object.find('name').text
difficult = ("%.4f" % int(object.find('difficult').text))
label_idx = ("%.4f" % label_dic[name])
bndbox = object.find('bndbox')
xmin = ("%.4f" % (int(bndbox.find('xmin').text)/width))
ymin = ("%.4f" % (int(bndbox.find('ymin').text)/height))
xmax = ("%.4f" % (int(bndbox.find('xmax').text)/width))
ymax = ("%.4f" % (int(bndbox.find('ymax').text)/height))
object_str = "\t".join([label_idx, xmin, ymin, xmax, ymax, difficult])
out_str = "\t".join([out_str, object_str])
out_str = "\t".join([out_str, "{}/JPEGImages/".format(args.dataset_path.split("/")[-])+line+".jpg"+"\n"])
output_file.writelines(out_str)
index += if __name__ == '__main__':
main()
命令为:
user@home:/opt/user/.../PASCAL_VOC_converge$ python create_list.py --set test --save-path /opt/user/.../PASCAL_VOC_converge/lst --dataset-path /opt/user/.../PASCAL_VOC_converge user@home:/opt/user/.../PASCAL_VOC_converge$ python create_list.py --set trainval --save-path /opt/user/.../PASCAL_VOC_converge/lst --dataset-path /opt/user/.../PASCAL_VOC_converge --shuffle True
然后查看可见/opt/user/.../PASCAL_VOC_converge/lst文件夹下生成了相应的trainval.lst和test.lst文件:
user@home:/opt/user/.../PASCAL_VOC_converge/lst$ ls
test.lst test.txt trainval.lst trainval.txt
对上面的命令进行说明:
- --set:用来指定生成的列表文件的名字,如test说明是用来生成test.txt文件指明的测试的数据集的.lst文件,生成的文件名为test.lst,trainval则生成trainval.txt文件指明的训练验证数据集的.lst文件,生成的文件名为trainval.lst
- --save-path:用来指定生成的.lst文件的保存路径,trainval.txt和test.txt文件要保存在该路径下
- --dataset-path:用来指定数据集的根目录
截取train.lst文件中的一个样本的标签介绍.lst文件的内容,如下:
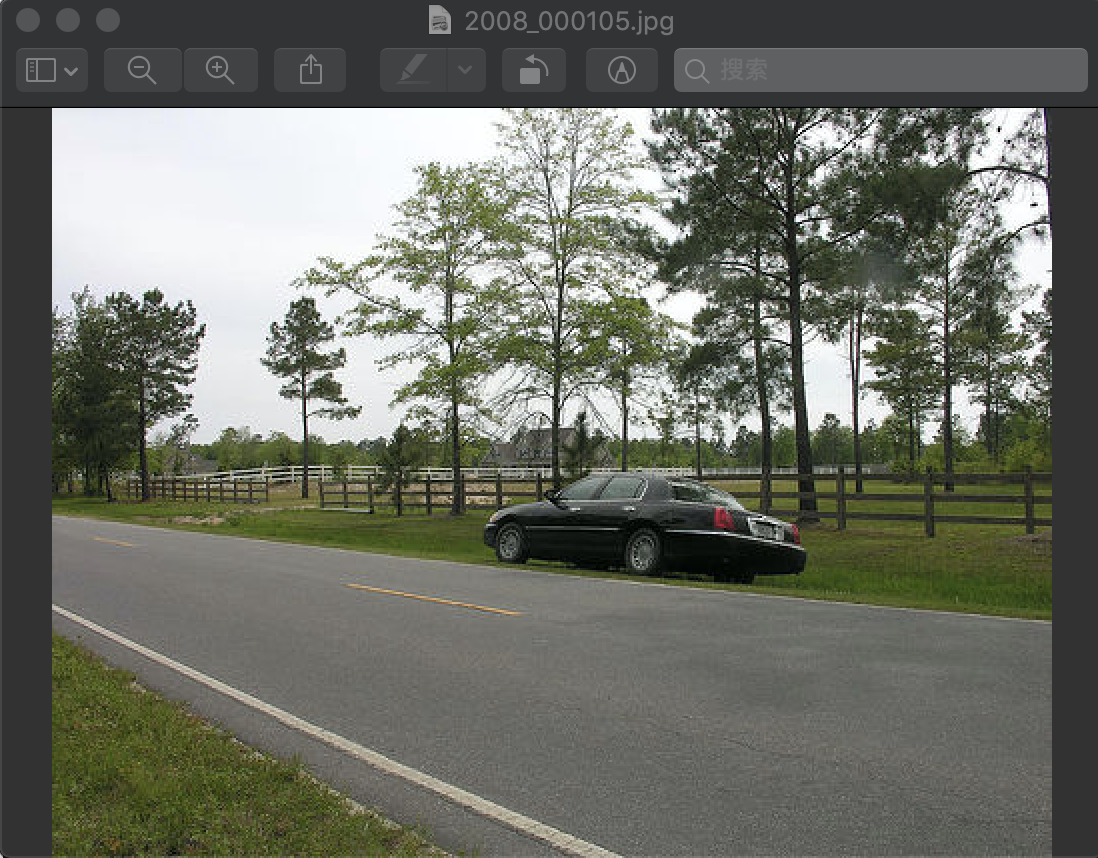
6.0000 0.4300 0.4853 0.7540 0.6400 0.0000 PASCAL_VOC_converge/JPEGImages/2008_000105.jpg
该图为:
列与列之间都是采用Tab键进行分割的。
- 第一列是index,即图像的标号,默认从0开始,然后递增。
- 第二列表示标识符位数,这里第二列的值都为2,因为标识符有2位,也就是第2列和第3列都是标识符,不是图像标签
- 第三列表示每个目标的标签位数,这里第三列都是6,表示每个目标的标签都是6个数字
- 第4列到第9列这6个数字就是第一个目标的标签,其中6表示该目标的类别,即'car'(PASCAL VOC数据集又20类,该列值为0-19);接下来的4个数字(0.4300 0.4853 0.7540 0.6400)表示目标的位置,即(xmin, ymin, xmax, ymax);第9列的值表示是否是difficult,如果为0则表示该目标能正常预测,1则表示该目标比较难检测
如果还有第二个目标的话,那么在第一个目标后面就会接着第二个目标的6列信息,依此类推
- 最后一列是图像的路径
多个目标可见:
14.0000 0.5620 0.0027 1.0000 1.0000 0.0000 19.0000 0.0680 0.3013 0.5760 0.9653 0.0000 PASCAL_VOC_conve
rge/JPEGImages/2008_004301.jpg
图2008_004301.jpg为:
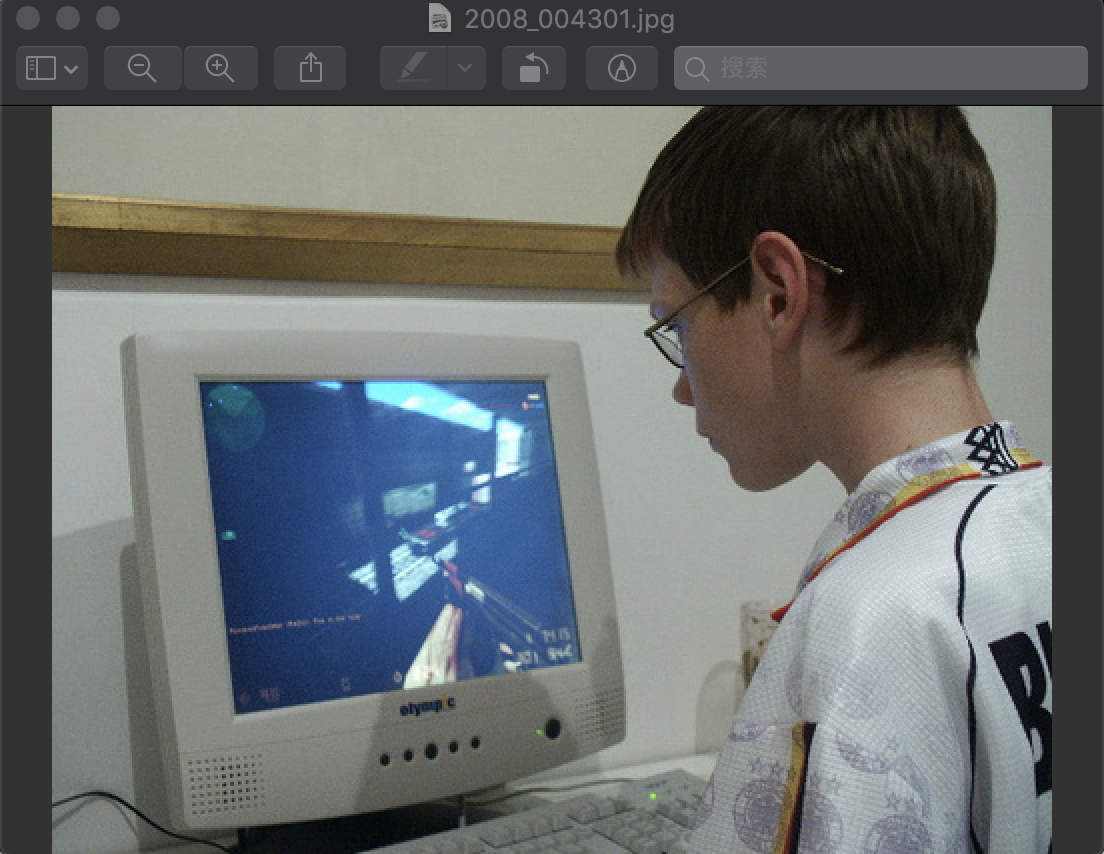
目标分别是类别14的'person'和类别19的'tvmonitor'
生成.lst文件后,就可以基于.lst文件和图像文件生成RecordIO文件了
使用脚本im2rec.py:
#!/usr/bin/env python3
# -*- coding: utf- -*-
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License. from __future__ import print_function
import os
import sys curr_path = os.path.abspath(os.path.dirname(__file__))
sys.path.append(os.path.join(curr_path, "../python"))
import mxnet as mx
import random
import argparse
import cv2
import time
import traceback try:
import multiprocessing
except ImportError:
multiprocessing = None def list_image(root, recursive, exts):
"""Traverses the root of directory that contains images and
generates image list iterator.
Parameters
----------
root: string
recursive: bool
exts: string
Returns
-------
image iterator that contains all the image under the specified path
""" i =
if recursive:
cat = {}
for path, dirs, files in os.walk(root, followlinks=True):
dirs.sort()
files.sort()
for fname in files:
fpath = os.path.join(path, fname)
suffix = os.path.splitext(fname)[].lower()
if os.path.isfile(fpath) and (suffix in exts):
if path not in cat:
cat[path] = len(cat)
yield (i, os.path.relpath(fpath, root), cat[path])
i +=
for k, v in sorted(cat.items(), key=lambda x: x[]):
print(os.path.relpath(k, root), v)
else:
for fname in sorted(os.listdir(root)):
fpath = os.path.join(root, fname)
suffix = os.path.splitext(fname)[].lower()
if os.path.isfile(fpath) and (suffix in exts):
yield (i, os.path.relpath(fpath, root), )
i += def write_list(path_out, image_list):
"""Hepler function to write image list into the file.
The format is as below,
integer_image_index \t float_label_index \t path_to_image
Note that the blank between number and tab is only used for readability.
Parameters
----------
path_out: string
image_list: list
"""
with open(path_out, 'w') as fout:
for i, item in enumerate(image_list):
line = '%d\t' % item[]
for j in item[:]:
line += '%f\t' % j
line += '%s\n' % item[]
fout.write(line) def make_list(args):
"""Generates .lst file.
Parameters
----------
args: object that contains all the arguments
"""
image_list = list_image(args.root, args.recursive, args.exts)
image_list = list(image_list)
if args.shuffle is True:
random.seed()
random.shuffle(image_list)
N = len(image_list)
chunk_size = (N + args.chunks - ) // args.chunks
for i in range(args.chunks):
chunk = image_list[i * chunk_size:(i + ) * chunk_size]
if args.chunks > :
str_chunk = '_%d' % i
else:
str_chunk = ''
sep = int(chunk_size * args.train_ratio)
sep_test = int(chunk_size * args.test_ratio)
if args.train_ratio == 1.0:
write_list(args.prefix + str_chunk + '.lst', chunk)
else:
if args.test_ratio:
write_list(args.prefix + str_chunk + '_test.lst', chunk[:sep_test])
if args.train_ratio + args.test_ratio < 1.0:
write_list(args.prefix + str_chunk + '_val.lst', chunk[sep_test + sep:])
write_list(args.prefix + str_chunk + '_train.lst', chunk[sep_test:sep_test + sep]) def read_list(path_in):
"""Reads the .lst file and generates corresponding iterator.
Parameters
----------
path_in: string
Returns
-------
item iterator that contains information in .lst file
"""
with open(path_in) as fin:
while True:
line = fin.readline()
if not line:
break
line = [i.strip() for i in line.strip().split('\t')]
line_len = len(line)
# check the data format of .lst file
if line_len < :
print('lst should have at least has three parts, but only has %s parts for %s' % (line_len, line))
continue
try:
item = [int(line[])] + [line[-]] + [float(i) for i in line[:-]]
except Exception as e:
print('Parsing lst met error for %s, detail: %s' % (line, e))
continue
yield item def image_encode(args, i, item, q_out):
"""Reads, preprocesses, packs the image and put it back in output queue.
Parameters
----------
args: object
i: int
item: list
q_out: queue
"""
fullpath = os.path.join(args.root, item[]) if len(item) > and args.pack_label:
header = mx.recordio.IRHeader(, item[:], item[], )
else:
header = mx.recordio.IRHeader(, item[], item[], ) if args.pass_through:
try:
with open(fullpath, 'rb') as fin:
img = fin.read()
s = mx.recordio.pack(header, img)
q_out.put((i, s, item))
except Exception as e:
traceback.print_exc()
print('pack_img error:', item[], e)
q_out.put((i, None, item))
return try:
img = cv2.imread(fullpath, args.color)
except:
traceback.print_exc()
print('imread error trying to load file: %s ' % fullpath)
q_out.put((i, None, item))
return
if img is None:
print('imread read blank (None) image for file: %s' % fullpath)
q_out.put((i, None, item))
return
if args.center_crop:
if img.shape[] > img.shape[]:
margin = (img.shape[] - img.shape[]) //
img = img[margin:margin + img.shape[], :]
else:
margin = (img.shape[] - img.shape[]) //
img = img[:, margin:margin + img.shape[]]
if args.resize:
if img.shape[] > img.shape[]:
newsize = (args.resize, img.shape[] * args.resize // img.shape[1])
else:
newsize = (img.shape[] * args.resize // img.shape[0], args.resize)
img = cv2.resize(img, newsize) try:
s = mx.recordio.pack_img(header, img, quality=args.quality, img_fmt=args.encoding)
q_out.put((i, s, item))
except Exception as e:
traceback.print_exc()
print('pack_img error on file: %s' % fullpath, e)
q_out.put((i, None, item))
return def read_worker(args, q_in, q_out):
"""Function that will be spawned to fetch the image
from the input queue and put it back to output queue.
Parameters
----------
args: object
q_in: queue
q_out: queue
"""
while True:
deq = q_in.get()
if deq is None:
break
i, item = deq
image_encode(args, i, item, q_out) def write_worker(q_out, fname, working_dir):
"""Function that will be spawned to fetch processed image
from the output queue and write to the .rec file.
Parameters
----------
q_out: queue
fname: string
working_dir: string
"""
pre_time = time.time()
count =
fname = os.path.basename(fname)
fname_rec = os.path.splitext(fname)[] + '.rec'
fname_idx = os.path.splitext(fname)[] + '.idx'
record = mx.recordio.MXIndexedRecordIO(os.path.join(working_dir, fname_idx),
os.path.join(working_dir, fname_rec), 'w')
buf = {}
more = True
while more:
deq = q_out.get()
if deq is not None:
i, s, item = deq
buf[i] = (s, item)
else:
more = False
while count in buf:
s, item = buf[count]
del buf[count]
if s is not None:
record.write_idx(item[], s) if count % == :
cur_time = time.time()
print('time:', cur_time - pre_time, ' count:', count)
pre_time = cur_time
count += def parse_args():
"""Defines all arguments.
Returns
-------
args object that contains all the params
"""
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter,
description='Create an image list or \
make a record database by reading from an image list')
parser.add_argument('prefix', help='prefix of input/output lst and rec files.')
parser.add_argument('root', help='path to folder containing images.') cgroup = parser.add_argument_group('Options for creating image lists')
cgroup.add_argument('--list', action='store_true',
help='If this is set im2rec will create image list(s) by traversing root folder\
and output to <prefix>.lst.\
Otherwise im2rec will read <prefix>.lst and create a database at <prefix>.rec')
cgroup.add_argument('--exts', nargs='+', default=['.jpeg', '.jpg', '.png'],
help='list of acceptable image extensions.')
cgroup.add_argument('--chunks', type=int, default=, help='number of chunks.')
cgroup.add_argument('--train-ratio', type=float, default=1.0,
help='Ratio of images to use for training.')
cgroup.add_argument('--test-ratio', type=float, default=,
help='Ratio of images to use for testing.')
cgroup.add_argument('--recursive', action='store_true',
help='If true recursively walk through subdirs and assign an unique label\
to images in each folder. Otherwise only include images in the root folder\
and give them label .')
cgroup.add_argument('--no-shuffle', dest='shuffle', action='store_false',
help='If this is passed, \
im2rec will not randomize the image order in <prefix>.lst')
rgroup = parser.add_argument_group('Options for creating database')
rgroup.add_argument('--pass-through', action='store_true',
help='whether to skip transformation and save image as is')
rgroup.add_argument('--resize', type=int, default=,
help='resize the shorter edge of image to the newsize, original images will\
be packed by default.')
rgroup.add_argument('--center-crop', action='store_true',
help='specify whether to crop the center image to make it rectangular.')
rgroup.add_argument('--quality', type=int, default=,
help='JPEG quality for encoding, 1-100; or PNG compression for encoding, 1-9')
rgroup.add_argument('--num-thread', type=int, default=,
help='number of thread to use for encoding. order of images will be different\
from the input list if >. the input list will be modified to match the\
resulting order.')
rgroup.add_argument('--color', type=int, default=, choices=[-, , ],
help='specify the color mode of the loaded image.\
: Loads a color image. Any transparency of image will be neglected. It is the default flag.\
: Loads image in grayscale mode.\
-:Loads image as such including alpha channel.')
rgroup.add_argument('--encoding', type=str, default='.jpg', choices=['.jpg', '.png'],
help='specify the encoding of the images.')
rgroup.add_argument('--pack-label', action='store_true',
help='Whether to also pack multi dimensional label in the record file')
args = parser.parse_args()
args.prefix = os.path.abspath(args.prefix)
args.root = os.path.abspath(args.root)
return args if __name__ == '__main__':
args = parse_args()
# if the '--list' is used, it generates .lst file
if args.list:
make_list(args)
# otherwise read .lst file to generates .rec file
else:
if os.path.isdir(args.prefix):
working_dir = args.prefix
else:
working_dir = os.path.dirname(args.prefix)
files = [os.path.join(working_dir, fname) for fname in os.listdir(working_dir)
if os.path.isfile(os.path.join(working_dir, fname))]
count =
for fname in files:
if fname.startswith(args.prefix) and fname.endswith('.lst'):
print('Creating .rec file from', fname, 'in', working_dir)
count +=
image_list = read_list(fname)
# -- write_record -- #
if args.num_thread > and multiprocessing is not None:
q_in = [multiprocessing.Queue() for i in range(args.num_thread)]
q_out = multiprocessing.Queue()
# define the process
read_process = [multiprocessing.Process(target=read_worker, args=(args, q_in[i], q_out)) \
for i in range(args.num_thread)]
# process images with num_thread process
for p in read_process:
p.start()
# only use one process to write .rec to avoid race-condtion
write_process = multiprocessing.Process(target=write_worker, args=(q_out, fname, working_dir))
write_process.start()
# put the image list into input queue
for i, item in enumerate(image_list):
q_in[i % len(q_in)].put((i, item))
for q in q_in:
q.put(None)
for p in read_process:
p.join() q_out.put(None)
write_process.join()
else:
print('multiprocessing not available, fall back to single threaded encoding')
try:
import Queue as queue
except ImportError:
import queue
q_out = queue.Queue()
fname = os.path.basename(fname)
fname_rec = os.path.splitext(fname)[] + '.rec'
fname_idx = os.path.splitext(fname)[] + '.idx'
record = mx.recordio.MXIndexedRecordIO(os.path.join(working_dir, fname_idx),
os.path.join(working_dir, fname_rec), 'w')
cnt =
pre_time = time.time()
for i, item in enumerate(image_list):
image_encode(args, i, item, q_out)
if q_out.empty():
continue
_, s, _ = q_out.get()
record.write_idx(item[], s)
if cnt % == :
cur_time = time.time()
print('time:', cur_time - pre_time, ' count:', cnt)
pre_time = cur_time
cnt +=
if not count:
print('Did not find and list file with prefix %s'%args.prefix)
运行命令为:
user@home:/opt/user/.../PASCAL_VOC_converge$ python2 im2rec.py /opt/user/.../PASCAL_VOC_converge/lst/test.lst /opt/user/.../ --no-shuffle --pack-label
/usr/local/lib/python2./dist-packages/h5py/__init__.py:: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.
from ._conv import register_converters as _register_converters
Creating .rec file from /opt/user/.../PASCAL_VOC_converge/lst/test.lst in /opt/user/.../PASCAL_VOC_converge/lst
multiprocessing not available, fall back to single threaded encoding
time: 0.00383400917053 count:
time: 3.74169707298 count:
time: 3.72109794617 count:
time: 3.71359992027 count:
time: 3.665184021 count: user@home:/opt/user/.../PASCAL_VOC_converge$ python2 im2rec.py /opt/user/.../PASCAL_VOC_converge/lst/trainval.lst/opt/user/.../ --pack-label
/usr/local/lib/python2./dist-packages/h5py/__init__.py:: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.
from ._conv import register_converters as _register_converters
Creating .rec file from /opt/user/.../PASCAL_VOC_converge/lst/trainval.lst in /opt/user/.../PASCAL_VOC_converge/lst
multiprocessing not available, fall back to single threaded encoding
time: 0.00398397445679 count:
time: 4.04885816574 count:
time: 4.14898204803 count:
time: 4.22944998741 count:
time: 4.15795993805 count:
time: 4.12708187103 count:
time: 4.13473105431 count:
time: 4.04282712936 count:
time: 3.99953484535 count:
time: 4.11092996597 count:
time: 4.0615940094 count:
time: 4.10190010071 count:
time: 4.11535596848 count:
time: 4.05630993843 count:
time: 4.15138602257 count:
time: 4.08989906311 count:
time: 4.03274989128 count:
命令的第一个参数用来指定.lst文件的路径;第二个参数指定数据集的根目录;--no-shuffle表示不对数据做随机打乱操作;--pack-label表示打包标签信息到RecordIO文件
注意:因为.lst中文件路径的写法是PASCAL_VOC_conve rge/JPEGImages/2008_004301.jpg ,所以上面指数据集的根目录写的是/opt/user/.../
最终得到的所有数据文件为:
user@home:/opt/user/PASCAL_VOC_converge/lst$ ls
test.idx test.lst test.rec test.txt trainval.idx trainval.lst trainval.rec trainval.txt
ssd的mxnet详细代码可见https://github.com/apache/incubator-mxnet/tree/master/example/ssd
2)训练参数及配置
脚本中主要包含模块导入、命令行参数解析函数parse_arguments()和主函数main()
首先看看导入的模块:
import mxnet as mx
import argparse
from symbol1.get_ssd import get_ssd #在本地一直无法导入symbol,将其改名为symbol1即可
from tools.custom_metric import MultiBoxMetric
from eval_metric_07 import VOC07MApMetric
import logging
import os
from data.dataiter import CustomDataIter
import re
命令行参数解析函数parse_arguments()与第八章相似,不再介绍
def parse_arguments():
parser = argparse.ArgumentParser(description='score a model on a dataset')
parser.add_argument('--lr', type=float, default=0.001) #学习率
parser.add_argument('--mom', type=float, default=0.9) #优化器动量momentum
parser.add_argument('--wd', type=float, default=0.0005) #权重衰减
parser.add_argument('--gpus', type=str, default='0,1') #使用的GPU
parser.add_argument('--batch-size', type=int, default=) #batch size
parser.add_argument('--num-classes', type=int, default=) #类别数量
parser.add_argument('--num-examples', type=int, default=) #训练图片数量
parser.add_argument('--begin-epoch', type=int, default=) #从epoch=0开始迭代
parser.add_argument('--num-epoch', type=int, default=) #一共进行240次迭代
parser.add_argument('--step', type=str, default='160,200') #指明在哪个epoch迭代处进行学习率衰减
parser.add_argument('--factor', type=float, default=0.1) #学习率衰减乘的因子factor
parser.add_argument('--frequent', type=int, default=)
parser.add_argument('--save-result', type=str, default='output/ssd_vgg/') #结果存放的路径
parser.add_argument('--save-name', type=str, default='ssd') #存放名字
parser.add_argument('--class-names', type=str, default='aeroplane, bicycle, bird, boat, bottle, bus, car, cat, chair, cow, diningtable, dog, horse, motorbike, person, pottedplant, sheep, sofa, train, tvmonitor') #20个类别的名字
parser.add_argument('--train-rec', type=str, default='data/VOCdevkit/VOC/ImageSets/Main/trainval.rec') #使用的训练数据集的.rec文件
parser.add_argument('--train-idx', type=str, default='data/VOCdevkit/VOC/ImageSets/Main/trainval.idx')#使用的训练数据集的.idx文件
parser.add_argument('--val-rec', type=str, default='data/VOCdevkit/VOC/ImageSets/Main/test.rec') #使用的测试数据集的.rec文件
parser.add_argument('--backbone-prefix', type=str, default='model/vgg16_reduced') #使用的预训练模型
parser.add_argument('--backbone-epoch', type=int, default=) #指明使用的是哪个epoch存储下来的预训练模型,名为vgg16_reduced-.params
parser.add_argument('--freeze-layers', type=str, default="^(conv1_|conv2_).*") #指明训练时固定不训练的层
parser.add_argument('--data-shape', type=int, default=) #图片大小
parser.add_argument('--label-pad-width', type=int, default=)
parser.add_argument('--label-name', type=str, default='label')
args = parser.parse_args()
return args
下面介绍main()函数,顺序执行了如下的几个操作:
- 调用命令行参数解析函数parse_arguments()得到参数对象args
- 创建模型保存路径args.save_result
- 通过logging模块创建记录器logger,同时设定了日志信息的终端显示和文件保存,最后调用记录器logger的info()方法显示配置的参数信息args
- 设定模型训练的环境,在这个代码中默认使用0、1号GPU进行训练,我自己只有一个GPU,所以设置为0
- 调用CustomDataIter类读取训练及验证数据集
- 调用get_ssd()函数构建SSD网络结构
- 通过mxnet.model.load_checkpoint()接口导入预训练的分类模型,在这份代码中使用的是VGG网络,得到的arg_params和aux_params将用于SSD网络的参数初始化
- 假设设定了在训练过程中固定部分层参数,那么就会使用fixed_params_names变量维护固定层名,这里设定为固定特征提取网络(VGG)的部分浅层参数
- 通过mxnet.mod.Module()接口初始化得到一个Module对象mod
- 设定学习率变化策略,这里设置为当训练epoch到达80和160时,将当前学习率乘以args.factor,该参数设置为0.1,也就是将学习率降为当前学习率的0.1倍
- 构建优化相关的字典optimizer_params,在该字典中包含学习率、动量参数、权重衰减参数、学习率变化策略参数等。通过mxnet.initializer.Xavier()接口设定SSD中新增网络层的参数初始化方式
- 通过VOC2017MapMetric类实现验证阶段的评价指标,此时需要传入的参数包括ovp_thresh。该参数表示当预测框和真实框的IoU大于ovp_thresh时,认为预测框是对的。另外还有个参数是pred_idx,是和这份代码设计的SSD网络相关,表示网络的第3个输出是预测框的内容。通过MultiBoxMetric类实现训练阶段的评价指标,在该指标中包括分类支路指标(基于softmax的交叉熵值)和回归支路指标(Smooth L1值)
- 通过mxnet.callback.Speedometer()接口设置训练过程中每训练args.frequent个批次就显示相关信息;通过mxnet.callback.do_checkpoint()接口设置训练结果的保存路径和保存间隔
- 调用mod的fit()方法启动训练
def main():
args = parse_arguments()
if not os.path.exists(args.save_result): #如果没有这个存储路径就创建
os.makedirs(args.save_result)
logger = logging.getLogger()
logger.setLevel(logging.INFO)
stream_handler = logging.StreamHandler()
logger.addHandler(stream_handler)
file_handler = logging.FileHandler(args.save_result + 'train.log')
logger.addHandler(file_handler)
logger.info(args) if args.gpus == '':
ctx = mx.cpu()
else:
ctx = [mx.gpu(int(i)) for i in args.gpus.split(',')] train_data = CustomDataIter(args, is_trainData=True)
val_data = CustomDataIter(args) ssd_symbol = get_ssd(num_classes=args.num_classes)
vgg, arg_params, aux_params = mx.model.load_checkpoint(args.backbone_prefix, args.backbone_epoch) #调用预训练函数 if args.freeze_layers.strip(): #得到固定不训练的层
re_prog = re.compile(args.freeze_layers)
fixed_param_names = [name for name in vgg.list_arguments() if re_prog.match(name)]
else:
fix_param_names = None mod = mx.mod.Module(symbol=ssd_symbol, label_names=(args.label_name,), context=ctx, fixed_param_names=fix_param_names)#得到Module对象mod epoch_size = max(int(args.num_examples / args.batch_size), )#指明一个epoch中有多少个batch
step = [int(step_i.strip()) for step_i in args.step.split(',')] #得到学习率衰减的epoch
step_bs = [epoch_size * (x - args.begin_epoch) for x in step if x - args.begin_epoch > ]
if step_bs:
lr_scheduler = mx.lr_scheduler.MultiFactorScheduler(step=step_bs, factor=args.factor)
else:
lr_scheduler = None optimizer_params = {'learning_rate':args.lr,
'momentum':args.mom,
'wd':args.wd,
'lr_scheduler':lr_scheduler,
'rescale_grad':1.0/len(ctx) if len(ctx)> else 1.0}
initializer = mx.init.Xavier(rnd_type='gaussian', factor_type='out', magnitude=) class_names = [name_i for name_i in args.class_names.split(',')]
VOC07_metric = VOC07MApMetric(ovp_thresh=0.5, use_difficult=False, class_names=class_names, pred_idx=) eval_metric = mx.metric.CompositeEvalMetric()
eval_metric.add(MultiBoxMetric(name=['CrossEntropy Loss', 'SmoothL1 Loss']))#指明使用的两个评价函数 batch_callback = mx.callback.Speedometer(batch_size=args.batch_size, frequent=args.frequent)
checkpoint_prefix = args.save_result + args.save_name
epoch_callback = mx.callback.do_checkpoint(prefix=checkpoint_prefix, period=) mod.fit(train_data=train_data,
eval_data=val_data,
eval_metric=eval_metric,
validation_metric=VOC07_metric,
epoch_end_callback=epoch_callback,
batch_end_callback=batch_callback,
optimizer='sgd',
optimizer_params=optimizer_params,
initializer=initializer,
arg_params=arg_params,
aux_params=aux_params,
allow_missing=True,
num_epoch=args.num_epoch) if __name__ == '__main__':
main()
从主函数main()的内容可以看出网络结构的搭建是通过get_ssd()函数实现的、数据读取是通过CustomDataIter类实现的、训练评价指标计算是通过MultiBoxMetric()类实现的,接下来依次介绍
3)网络结构搭建
该get_ssd()函数保存在https://github.com/miraclewkf/MXNet-Deep-Learning-in-Action/blob/master/chapter9-objectDetection/9.2-objectDetection/symbol/get_ssd.py
该函数主要执行了下面的几个操作:
- 调用config()函数得到模型构建过程中的参数信息,比如anchor(即default box)的尺寸,这些参数信息通过字典config_dict进行维护
- 调用VGGNet()函数得到特征提取网络,也就是我们常说的backbone,这里选择的是修改版VGG网络,修改的内容主要是将原VGG中的fc6和fc7两个全连接层用卷积层代替,其中fc6采用卷积核大小为3*3,pad参数为(6,6),dilate参数为(6,6)的卷积层,大大增加了该层的感受域(receptive field)。除了修改网络层外,还截掉了fc8层及后面所连接的其他层
- 调用add_extras()函数在VGG主干上添加层,最终返回的就是主干网络和新增网络中共6个特征层,这6个特征层将用于预测框的类别和位置
- 调用create_predictor()函数基于6个特征层构建6个预测层,每个预测层都包含2个支路,分别表示分类支路和回归支路,其中分类支路的输出对应cls_preds,回归支路的输出对应loc_preds。另外在该函数中还会基于6个特征层中的每个特征层初始化指定尺寸的anchor
- 调用create_multi_loss()函数构建分类支路和回归支路的损失函数,从而得到最终的SSD网络——ssd_symbol
from .vggnet import *
def get_ssd(num_classes):
config_dict = config()
backbond = VGGNet()
from_layers = add_extras(backbond=backbond, config_dict=config_dict)
loc_preds, cls_preds, anchors = create_predictor(from_layers=from_layers,
config_dict=config_dict,
num_classes=num_classes)
label = mx.sym.Variable('label')
ssd_symbol = create_multi_loss(label=label, loc_preds=loc_preds, cls_preds=cls_preds, anchors=anchors)
return ssd_symbol
首先介绍一下config()函数
- 'from_layers' :表示用于预测的特征层名,其中'relu4_3'和'relu7'是VGG网络自身的网络层,剩下4个空字符串表示从VGG网络后面新增的网络层选择4个作为预测层所接的层
- 'num_filters':第1个512表示在relu4_3后面接的L2 Normalization层的参数;第二个-1表示该特征层后面不接额外的卷积层,直接接预测层;后面4个值表示在VGG网络后面新增的卷积层的卷积核数量
- 'strides':前面2个-1表示无效,因为这个参数是为VGG网络后面的新增层服务的,而前面两个特征层是VGG网络自身的,所以不需要stride参数;后面4个值表示新增的3*3卷积层的stride参数,具体而言新增的conv8_2、conv9_2的3*3卷积层的stride参数都将设置为2,而conv10_2、conv11_2的3*3卷积层的stride参数设为1
- 'pads'和'strides'参数同理,只不过设置的是卷积层的pad参数
- 'normalization':因为在SSD网络的relu4_3层后用刀L2 Normalization层,因此这里的20就是设置L2 Normalization层的参数,剩下的-1表示无效,因为其他5个层后面都不需要接L2 Normalization层
- 'sizes':这是设置6个用于预测的特征层的anchor大小,可以看到每个层设置的anchor大小都有2个值,其中第一个值将和所有不同宽高比的anchor进行组合,第二个值只与宽高比是1的anchor进行组合,这和SSD论文的处理方式保持一致。每个列表(假设是第k个列表)中的第一个值可以通过下面的式子计算得到,结果为{0.1, 0.2, 0.37, 0.54, 0.71, 0.88}:
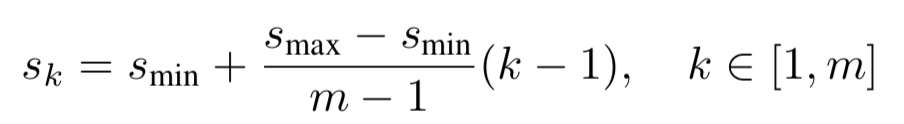
第二个值则是对第k和第k+1个列表的第一个值相乘后求开方得到的,结果为{0.141, 0.272, 0.447, 0.619, 0.79, 0.961}
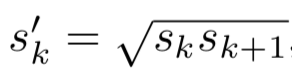
注意当基础层越深,设置的anchor尺寸越大,这是因为越深的网络层的感受域越大,主要用来检测尺寸较大的目标,因此anchor尺寸也设置较大
- 'ratios':这是设置6个用于预测的特征层的anchor的宽高对比度。在SSD论文中,第一个和最后2个用于预测层中设置anchor个数为4的层(因此这里的宽高对比度值设置为3个),其他3个特征层设置的是6个anchor(因此宽高对比度设置为5个值)。结合刚刚介绍的sizes参数,以第一个用于预测的特征层relu4_3为例,此时的sizes=[0.1,0.141],ratios为[1, 2, 0.5]。因为输入图像大小为300*300,所以在size为0.1时,会和所有ratio组合,因此会得到大小为30*30、(30*√2) * (30 / √2)、(30*√0.5)*(30/√0.5)的3个anchor,在size=0.141时,只和ratio=1结合,得到大小为(300*0.141)*(300*0.141)的anchor。最后特征图的每个位置都能得到4个anchor,其他用于预测的特征层anchor设计也是用理
- 'steps':这是设置6个用于预测的特征层的特征图尺寸和输入图像尺寸的倍数关系,在初始化anchor时会用到该参数
def config():
config_dict = {}
config_dict['from_layers'] = ['relu4_3', 'relu7', '', '', '', '']
config_dict['num_filters'] = [, -, , , , ]
config_dict['strides'] = [-, -, , , , ]
config_dict['pads'] = [-, -, , , , ]
config_dict['normalization'] = [, -, -, -, -, -]
config_dict['sizes'] = [[0.1, 0.141], [0.2, 0.272], [0.37, 0.447],
[0.54, 0.619], [0.71, 0.79], [0.88, 0.961]]
config_dict['ratios'] = [[, , 0.5], [, , 0.5, , 1.0/],
[, , 0.5, , 1.0/], [, , 0.5, , 1.0/],
[, , 0.5], [, , 0.5]]
config_dict['steps'] = [x / 300.0 for x in [, , , , , ]]
return config_dict
然后是VGGNet()函数,该函数在16层的VGG网络上做一定修改即可得到,修改内容上面也说到,VGG更改全连接层后的代码可见:
import mxnet as mx def VGGNet():
data = mx.sym.Variable(name='data') conv1_1 = mx.sym.Convolution(data=data, kernel=(,), pad=(,), stride=(,),
num_filter=, name='conv1_1')
relu1_1 = mx.sym.Activation(data=conv1_1, act_type='relu', name='relu1_1')
conv1_2 = mx.sym.Convolution(data=relu1_1, kernel=(,), pad=(,), stride=(,),
num_filter=, name='conv1_2')
relu1_2 = mx.sym.Activation(data=conv1_2, act_type='relu', name='relu1_2')
pool1 = mx.sym.Pooling(data=relu1_2, kernel=(,), stride=(,), pool_type='max',
pooling_convention='full', name='pool1') conv2_1 = mx.sym.Convolution(data=pool1, kernel=(,), pad=(,), stride=(,),
num_filter=, name='conv2_1')
relu2_1 = mx.sym.Activation(data=conv2_1, act_type='relu', name='relu2_1')
conv2_2 = mx.sym.Convolution(data=relu2_1, kernel=(,), pad=(,), stride=(,),
num_filter=, name='conv2_2')
relu2_2 = mx.sym.Activation(data=conv2_2, act_type='relu', name='relu2_2')
pool2 = mx.sym.Pooling(data=relu2_2, kernel=(,), stride=(,), pool_type='max',
pooling_convention='full', name='pool2') conv3_1 = mx.sym.Convolution(data=pool2, kernel=(,), pad=(,), stride=(,),
num_filter=, name='conv3_1')
relu3_1 = mx.sym.Activation(data=conv3_1, act_type='relu', name='relu3_1')
conv3_2 = mx.sym.Convolution(data=relu3_1, kernel=(,), pad=(,), stride=(,),
num_filter=, name='conv3_2')
relu3_2 = mx.sym.Activation(data=conv3_2, act_type='relu', name='relu3_2')
conv3_3 = mx.sym.Convolution(data=relu3_2, kernel=(, ), pad=(, ), stride=(, ),
num_filter=, name='conv3_3')
relu3_3 = mx.sym.Activation(data=conv3_3, act_type='relu', name='relu3_3')
pool3 = mx.sym.Pooling(data=relu3_3, kernel=(, ), stride=(, ), pool_type='max',
pooling_convention='full', name='pool3') conv4_1 = mx.sym.Convolution(data=pool3, kernel=(,), pad=(,), stride=(,),
num_filter=, name='conv4_1')
relu4_1 = mx.sym.Activation(data=conv4_1, act_type='relu', name='relu4_1')
conv4_2 = mx.sym.Convolution(data=relu4_1, kernel=(,), pad=(,), stride=(,),
num_filter=, name='conv4_2')
relu4_2 = mx.sym.Activation(data=conv4_2, act_type='relu', name='relu4_2')
conv4_3 = mx.sym.Convolution(data=relu4_2, kernel=(,), pad=(,), stride=(,),
num_filter=, name='conv4_3')
relu4_3 = mx.sym.Activation(data=conv4_3, act_type='relu', name='relu4_3')
pool4 = mx.sym.Pooling(data=relu4_3, kernel=(,), stride=(,), pool_type='max',
pooling_convention='full', name='pool4') conv5_1 = mx.sym.Convolution(data=pool4, kernel=(,), pad=(,), stride=(,),
num_filter=, name='conv5_1')
relu5_1 = mx.sym.Activation(data=conv5_1, act_type='relu', name='relu5_1')
conv5_2 = mx.sym.Convolution(data=relu5_1, kernel=(,), pad=(,), stride=(,),
num_filter=, name='conv5_2')
relu5_2 = mx.sym.Activation(data=conv5_2, act_type='relu', name='relu5_2')
conv5_3 = mx.sym.Convolution(data=relu5_2, kernel=(,), pad=(,), stride=(,),
num_filter=, name='conv5_3')
relu5_3 = mx.sym.Activation(data=conv5_3, act_type='relu', name='relu5_3')
pool5 = mx.sym.Pooling(data=relu5_3, kernel=(,), pad=(,), stride=(,),
pool_type='max', pooling_convention='full', name='pool5')
#这上面都是VGGNet中D网络的设置
#下面则是更改,将FC6和FC7全连接层改成卷积层
conv6 = mx.sym.Convolution(data=pool5, kernel=(,), pad=(,), stride=(,),
num_filter=, dilate=(,), name='fc6')
relu6 = mx.sym.Activation(data=conv6, act_type='relu', name='relu6') conv7 = mx.sym.Convolution(data=relu6, kernel=(,), stride=(,),
num_filter=, name='fc7')
relu7 = mx.sym.Activation(data=conv7, act_type='relu', name='relu7')
return relu7
然后接下来介绍新增网络函数:add_extras(),该函数用于在修改后的VGG网络后面添加conv8_2、conv9_2、conv10_2和conv11_2
从该函数可以看出,只要内容是通过循环判断config['from_layers']列表判断添加层的起始位置,而添加层的内容主要就是卷积层和激活层
最后将6个用于预测的特征层都保存在layers列表中,用于后续构造预测层
def add_extras(backbone, config_dict):
layers = []
body = backbone.get_internals() #得到Symbol对象的所有层信息,截取到想要的层
for i, from_layer in enumerate(config_dict['from_layers']):
if from_layer is '': #如果为空,这里的i从2开始,5结尾,所以用于生成conv8、conv9、conv10和conv11 block
layer = layers[-] #
num_filters = config_dict['num_filters'][i] #得到卷积核的输出大小
s = config_dict['strides'][i] #stride值
p = config_dict['pads'][i] #pad值
#声明两个卷积层+激活函数
conv_1x1 = mx.sym.Convolution(data=layer, kernel=(,),
num_filter=num_filters // 2,
pad=(,), stride=(,),
name="conv{}_1".format(i+))
relu_1 = mx.sym.Activation(data=conv_1x1, act_type='relu',
name="relu{}_1".format(i+))
conv_3x3 = mx.sym.Convolution(data=relu_1, kernel=(,),
num_filter=num_filters,
pad=(p,p), stride=(s,s),
name="conv{}_2".format(i+))
relu_2 = mx.sym.Activation(data=conv_3x3, act_type='relu',
name="relu{}_2".format(i+))
layers.append(relu_2)
else: #layers前两个值加入的是VGGNet从头到relu4_3,从头到relu7层的两个网络,后面的就是从头到conv8,c从头到conv9...的网络
layers.append(body[from_layer + '_output'])
return layers
接下来介绍添加预测层的函数:create_predictor(),在该函数中基于上面的add_extras()函数返回的6个特征层layers构造预测层,预测层包括分类支路和回归支路。因此create_predictor()函数整体上就是不断循环读取输入的from_layers列表(6个特征层)的过程。在这个大循环中主要执行了一下几个操作:
- 通过config_dict['normalization']的值判断是否需要添加L2 Normalization层,在SSD算法中,只有relu4_3层后面才需要添加L2 Normalization层
- 计算每个基础层的anchor数量,具体而言是通过设定的anchor大小数量和宽高比数量计算得到的:num_anchors = len(anchor_size)-1+len(anchor_ratio)
- 基于基础层构造回归支路,回归支路的构造是通过卷积层实现的,该卷积层的卷积核数量是通过num_loc_pred = num_anchors*4计算得到的,因为每个anchor都会有4个坐标信息,所以最后得到的预测位置值有num_loc_pred个
- 基于基础层构造分类支路,分类支路的构造也是通过卷积层实现的,该卷积层的卷积核数量是通过num_cls_pred = num_anchors * num_classes计算得到的,其中num_classes等于目标类别数+1,1表示背景类别
- 通过mxnet.symbol.contrib.MultiBoxPrior()接口初始化anchor
循环结束后通过mxnet.symbol.concat()接口将6个回归预测层输出合并在一起得到loc_preds,将6个分类预测层输出合并在一起的到cls_preds,将6个特征层的anchor合并在一起的到anchors,最后返回这3个对象
mxnet.symbol.concat(*data, **kwargs)融合接口定义的data参数是可变参数,即传入的参数个数是可变的。因此假如我们采用列表形式传入参数,那么需要在列表前加一个*符号
def create_predictor(from_layers, config_dict, num_classes):
loc_pred_layers = []
cls_pred_layers = []
anchor_layers = []
num_classes += for i, from_layer in enumerate(from_layers):
from_name = from_layer.name
if config_dict['normalization'][i] > : #添加L2 Normalization层
num_filters = config_dict['num_filters'][i]
init = mx.init.Constant(config_dict['normalization'][i])
L2_normal = mx.sym.L2Normalization(data=from_layer, mode="channel",
name="{}_norm".format(from_name))
scale = mx.sym.Variable(name="{}_scale".format(from_name),
shape=(, num_filters, , ),
init=init, attr={'__wd_mult__': '0.1'})
from_layer = mx.sym.broadcast_mul(lhs=scale, rhs=L2_normal) anchor_size = config_dict['sizes'][i]
anchor_ratio = config_dict['ratios'][i]
num_anchors = len(anchor_size) - + len(anchor_ratio) #计算得到anchor数量 # regression layer,回归层
num_loc_pred = num_anchors * #卷积核的数量num_filter
weight = mx.sym.Variable(name="{}_loc_pred_conv_weight".format(from_name),
init=mx.init.Xavier(magnitude=))
loc_pred = mx.sym.Convolution(data=from_layer, kernel=(,),
weight=weight, pad=(,),
num_filter=num_loc_pred,
name="{}_loc_pred_conv".format(
from_name))
loc_pred = mx.sym.transpose(loc_pred, axes=(,,,))
loc_pred = mx.sym.Flatten(data=loc_pred)
loc_pred_layers.append(loc_pred) # classification part,分类层
num_cls_pred = num_anchors * num_classes #卷积核的数量num_filter
weight = mx.sym.Variable(name="{}_cls_pred_conv_weight".format(from_name),
init=mx.init.Xavier(magnitude=))
cls_pred = mx.sym.Convolution(data=from_layer, kernel=(,),
weight=weight, pad=(,),
num_filter=num_cls_pred,
name="{}_cls_pred_conv".format(
from_name))
cls_pred = mx.sym.transpose(cls_pred, axes=(,,,))
cls_pred = mx.sym.Flatten(data=cls_pred)
cls_pred_layers.append(cls_pred) # anchor part,该特征层的anchor
anchor_step = config_dict['steps'][i]
anchors = mx.sym.contrib.MultiBoxPrior(from_layer, sizes=anchor_size,
ratios=anchor_ratio, clip=False,
steps=(anchor_step,anchor_step),
name="{}_anchors".format(from_name))
anchors = mx.sym.Flatten(data=anchors)
anchor_layers.append(anchors)
loc_preds = mx.sym.concat(*loc_pred_layers, name="multibox_loc_preds")
cls_preds = mx.sym.concat(*cls_pred_layers)
cls_preds = mx.sym.reshape(data=cls_preds, shape=(,-,num_classes))
cls_preds = mx.sym.transpose(cls_preds, axes=(,,), name="multibox_cls_preds")
anchors = mx.sym.concat(*anchor_layers)
anchors = mx.sym.reshape(data=anchors, shape=(,-,), name="anchors")
return loc_preds, cls_preds, anchors
构建好预测层后基本上就完成了SSD网络主体结构的搭建,只需要再构造损失函数就可以完成整个网络结构的搭建了。
损失函数层的构建是通过create_multi_loss()函数实现的,主要执行了如下的操作:
- 通过mxnet.symbol.contric.MultiBoxTarget()接口得到模型的训练目标,这个训练目标包括回归支路的训练目标loc_target,也就是anchor和真实框之间的offset;回归支路的mask:loc_target_mask,因为只有正样本anchor采用回归目标,因此这个loc_target_mask是用来标识哪些anchor有回归的训练目标。分类支路的训练目标:cls_target,也就是每个anchor的真实类别标签
- 通过mxnet.symbol.SoftmaxOutput()接口创建分类支路的损失函数,即基于softmax的交叉熵损失函数,注意参数use_ignore和ignore_label,参数use_ignore设置为True表示在回传损失时忽略参数ignore_label设定的标签(这里ignore_label设置为-1,表示背景)所对应的样本,换句话说就是负样本anchor的分类是不会对梯度更新产生贡献的
- 通过mxnet.symbol.smooth_l1()接口创建回归支路的损失函数,这里采用Smooth L1损失函数。该函数的输入参数data设置为loc_target_mask * (loc_preds - loc_target),因为loc_target_mask会将负样本anchor置零,因此回归部分只有正样本anchor才会对损失值计算产生贡献
- 通过mxnet.symbol.MakeLoss()接口将cls_target作为网络的一个输出,这部分是为了后期计算评价指标使用,因此可以看见其grad_scale参数设置为0,表示不传递损失
- 通过mxnet.symbol.contrib.MultiBoxDetection()接口计算预测结果,这部分得到的是预测框的坐标值,用于计算mAP。同样,在这一层后面也用mxnet.symbol.MakeLoss()接口进行封装同时把grad_scale参数设置为0,这是在不影响网络训练的前提下获取除了网络正常输出层以外的其他输出时常用的方法
- 通过mxnet.symbol.Group()接口将几个输出合并在一起并返回。一般常通过mxnet.symbol.Group()接口组合多个损失函数。例如当设置mxnet.symbol.Group([loss1, loss2])时,表示整个网络的损失函数是loss1+loss2,二者之间的权重是一样的。这里通过mxnet.symbol.Group()接口将[cls_prob, loc_loss, cls_label, det]合并在一起,但是因为cls_label和det在构造时将grad_scale参数设置为0,所以是不回传损失值的,因此实际上还是只有分类和回归两部分损失函数
def create_multi_loss(label, loc_preds, cls_preds, anchors):
loc_target,loc_target_mask,cls_target = mx.sym.contrib.MultiBoxTarget(
anchor=anchors,
label=label,
cls_pred=cls_preds,
overlap_threshold=0.5,
ignore_label=-,
negative_mining_ratio=,
negative_mining_thresh=0.5,
minimum_negative_samples=,
variances=(0.1, 0.1, 0.2, 0.2),
name="multibox_target")
#分类损失结果
#cls_prob,也就是目标的分类概率,维度是[B, C+1, N]
#其中B表示批次大小,C表示目标类别数,对于PASCAL VOC数据集C=20,N表示anchor数量,对于SSD算法来说,N默认为8732
cls_prob = mx.sym.SoftmaxOutput(data=cls_preds, label=cls_target,
ignore_label=-, use_ignore=True,
multi_output=True,
normalization='valid',
name="cls_prob")
loc_loss_ = mx.sym.smooth_l1(data=loc_target_mask*(loc_preds-loc_target),
scalar=1.0,
name="loc_loss_")
#回归损失结果
#loc_loss,也就是回归支路的损失值,维度是[B, N*4],已经计算出来了,该损失值会回传
loc_loss = mx.sym.MakeLoss(loc_loss_, normalization='valid',
name="loc_loss")
#分类真实值,用于后期计算评价指标使用
#grad_scale=,所以不回传损失值
#cls_label是目标的真实标签,即真实类别,维度是[B, N]
cls_label = mx.sym.MakeLoss(data=cls_target, grad_scale=,
name="cls_label")
#得到预测框的坐标值,用于计算mAP
#det对应预测框的坐标,维度为[B, N, 6],6包括1个预测类别、4个坐标信息和1个类别置信度
det = mx.sym.contrib.MultiBoxDetection(cls_prob=cls_prob,
loc_pred=loc_preds,
anchor=anchors,
nms_threshold=0.45,
force_suppress=False,
nms_topk=,
variances=(0.1,0.1,0.2,0.2),
name="detection")
#grad_scale=,所以不回传损失值
det = mx.sym.MakeLoss(data=det, grad_scale=, name="det_out")
output = mx.sym.Group([cls_prob, loc_loss, cls_label, det])
return output
4)数据读取
通过CustomDataIter()类实现,脚本在https://github.com/miraclewkf/MXNet-Deep-Learning-in-Action/blob/master/chapter9-objectDetection/9.2-objectDetection/data/dataiter.py
该类的主要操作是对MXNet官方提供的检测数据读取接口mxnet.io.ImageDetRecordIter()做一定的封装,使其能够用于模型训练。具体的封装过程是针对读取得到的标签进行的,通过该类的内部函数_read_data()将读取到的每个批次数据中的原始标签(原始标签中包含一些标识位等信息,可查看.lst文件,上面数据中有提到)转换成维度为[批次大小, 标签数量, 6],这里的标签数量包括图像的真实目标数量和填充(下面有解释)的标签数量,这样能够保证每一张图像的标签数量都相等
数据读取部分涉及比较多的数据增强操作对模型的训练结果影响较大,下面第3到7点都是数据增强的内容,依次是色彩变换、图像填充、随机裁剪、resize和随机镜像操作,基本上接口代码执行数据增强的顺序也是这样的。下面解释数据读取接口中参数的含义:
- 首先patch_imgrec、batch_size、data_shape、mean_r、mean_g、mean_b这几个参数比较容易理解,即图像.rec文件的路径,batch size的大小、图片的宽高大小、RGB中red的均值、green的均值和blue的均值
- label_pad_width参数表示标签填充长度,因为在目标检测算法中,每一张输入图像中的目标数量不一样,但是在训练过程中每个批次数据的维度要保持一致才能进行训练,因此就有了标签填充这个操作,迷人填充值是-1,这样就不会和真实的标签混合,最终每张图像的标签长度都一致
- 接下来从random_hue_prob到max_random_contrast这8个参数都是和色彩相关的数据增强操作,其中以prob结尾的参数表示使用该数据增强操作的概率,比如random_hue_prob、ramdom_saturation_prob、random_illumination_prob和random_contrast_prob,剩下4个参数是对应的色彩操作相关的参数
- rand_pad_prob、fill_value和max_pad_scale这3个参数是用来填充边界的。假设输入图像大小是h*w(暂不讨论通道),那么首先会在[1, max_pad_scale]之间随机选择一个值,比如2,那么就会先初始化一个大小为2h*2w,使用fill_value进行填充的背景图像,然后将输入图像随机贴在这个背景图像上,这样得到的图像将用于接下来的随机裁剪操作。而rand_pad_prob参数表示随机执行这个填充操作的概率
- 接下来从rand_crop_prob到num_crop_sampler这13个参数都是和随机裁剪相关的。首先rand_crop_prob参数表示执行随机裁剪操作的概率。num_crop_sampler=5参数表示执行多少组不同参数配置的裁剪操作,该参数的值要和裁剪参数列表的长度相等,否则会报错,最终会从设定的num_crop_sampler=5个裁剪结果中随机选择一个输出。max_crop_aspect_ratios和min_crop_aspect_ratios这两个参数表示裁剪时将图像的宽高比变化成这两个值之间的一个随机值,因此这2个参数会对输入图像做一定形变。max_crop_overlaps和min_crop_overlaps这2个参数表示裁剪后图像的标注框和原图像的标注框之间的IoU最小值要大于min_crop_overlaps,同时小于max_crop_overlaps,这是为了防止裁剪后图像的标注框缺失太多。max_crop_trials参数表示在每组max_crop_overlaps和min_crop_overlaps参数下可执行的裁剪次数上限,因为裁剪过程中可能需要裁剪多次才能保证原有的真实框不会被裁掉太多,而只要有某一次裁剪结果符合这个IoU上下限要求,则不再裁剪,转而进入下一组max_crop_overlaps和min_crop_overlaps参数的裁剪
- 接下来是resize操作,对应参数inter_method,表示resize操作时的插值算法,这里选择随机插值,另外还需要的最终图像尺寸已经在data_shape参数中指定
- 最后是随机镜像操作,对应参数rand_mirror_prob,常用的默认值是0.5
import mxnet as mx class CustomDataIter(mx.io.DataIter):
def __init__(self, args, is_trainData=False):
self.args = args
data_shape = (, args.data_shape, args.data_shape)
if is_trainData:#如果要得到的是训练数据
self.data=mx.io.ImageDetRecordIter(
path_imgrec=args.train_rec,
batch_size=args.batch_size,
data_shape=data_shape,
mean_r=123.68,
mean_g=116.779,
mean_b=103.939,
label_pad_width=,
random_hue_prob=0.5,
max_random_hue=,
random_saturation_prob=0.5,
max_random_saturation=,
random_illumination_prob=0.5,
max_random_illumination=,
random_contrast_prob=0.5,
max_random_contrast=0.5,
rand_pad_prob=0.5,
fill_value=,
max_pad_scale=,
rand_crop_prob=0.833333,
max_crop_aspect_ratios=[2.0, 2.0, 2.0, 2.0, 2.0],
max_crop_object_coverages=[1.0, 1.0, 1.0, 1.0, 1.0],
max_crop_overlaps=[1.0, 1.0, 1.0, 1.0, 1.0],
max_crop_sample_coverages=[1.0, 1.0, 1.0, 1.0, 1.0],
max_crop_scales=[1.0, 1.0, 1.0, 1.0, 1.0],
max_crop_trials=[, , , , ],
min_crop_aspect_ratios=[0.5, 0.5, 0.5, 0.5, 0.5],
min_crop_object_coverages=[0.0, 0.0, 0.0, 0.0, 0.0],
min_crop_overlaps=[0.1, 0.3, 0.5, 0.7, 0.9],
min_crop_sample_coverages=[0.0, 0.0, 0.0, 0.0, 0.0],
min_crop_scales=[0.3, 0.3, 0.3, 0.3, 0.3],
num_crop_sampler=,
inter_method=,
rand_mirror_prob=0.5,
shuffle=True
)
else:#得到的是测试数据
self.data=mx.io.ImageDetRecordIter(
path_imgrec=args.val_rec,
batch_size=args.batch_size,
data_shape=data_shape,
mean_r=123.68,
mean_g=116.779,
mean_b=103.939,
label_pad_width=,
shuffle=False
)
self._read_data()
self.reset() @property
def provide_data(self):
return self.data.provide_data @property
def provide_label(self):
return self.new_provide_label def reset(self):
self.data.reset() #读取到的每个批次数据中的原始标签(原始标签中包含一些标识位等信息)
def _read_data(self):
self._data_batch = next(self.data)#得到下一个bath size大小的数据集
if self._data_batch is None:
return False
else:
original_label = self._data_batch.label[]
original_label_length = original_label.shape[]
label_head_length = int(original_label[][].asscalar())
object_label_length = int(original_label[][].asscalar())
label_start_idx = +label_head_length
label_num = (original_label_length-
label_start_idx+)//object_label_length
self.new_label_shape = (self.args.batch_size, label_num,
object_label_length)
self.new_provide_label = [(self.args.label_name,
self.new_label_shape)]
new_label = original_label[:,label_start_idx:
object_label_length*label_num+label_start_idx]
self._data_batch.label = [new_label.reshape((-,label_num,
object_label_length))]
return True def iter_next(self):
return self._read_data() def next(self):
if self.iter_next():
return self._data_batch
else:
raise StopIteration
5)定义训练评价指标
在MXNet中,一般通过继承mxnet.metric.EvalMetric类并重写部分方法实现评价指标的自定义。在大多数目标检测算法中,分类支路都采用基于softmax的交叉熵损失函数,回归支路都采用Smooth L1损失函数,在MultiBoxMetric类中同时执行了这两个指标的计算
在MultiBoxMetric类中主要涉及__init__()、重置方法reset()、指标更新方法update()和指标获取方法get()
注意在重置方法reset()中将self.num_inst和self.num_metric的长度都设置为2,正是和交叉熵及Smooth L1损失对应。指标更新方法update()是这个类的核心,该方法有2个重要输入,分别是标签labels和网络的预测输出preds。在介绍SSD网络结构构造(即上面get_ssd()脚本中的create_multi_loss()函数),在构造函数的最后通过mxnet.symbol.Group()接口将4个输出值组合在一起,而这里的preds变量就是这4个输出值。因此可以看见preds[0]对应cls_prob,也就是目标的分类概率,维度是[B, C+1, N],其中B表示批次大小,C表示目标类别数,对于PASCAL VOC数据集C=20,N表示anchor数量,对于SSD算法来说,N默认为8732。preds[1]对应loc_loss,也就是回归支路的损失值,维度是[B, N*4],因此这个部分就是这个类要输出的损失值之一:Smooth L1。preds[2]对应目标的真实标签,即真实类别,维度是[B, N],这个变量是计算交叉熵损失值的重要输出之一。preds[3]对应预测框的坐标,维度为[B, N, 6],6包括1个预测类别、4个坐标信息和1个类别置信度,preds[3]在这里暂时用不到
注意到update()方法中有一个重要的操作:valid_count = np.sum(cls_label >= 0)这一行是计算有效anchor的数量,该数量用于评价指标的计算
变量mask和indices用于筛选类别预测概率cls_prob和有效anchor对应的真实类别的预测概率,得到这个概率后就可以作为交叉熵函数的输入用于计算交叉熵值
指标获取方法get()内容相对简单,主要就是对update()方法中计算得到的变量self.sum_metric和self.num_inst执行除法操作,需要注意的是当除数为0时,这里设置为输出'nan'
import mxnet as mx
import numpy as np class MultiBoxMetric(mx.metric.EvalMetric):
def __init__(self, name):
super(MultiBoxMetric, self).__init__('MultiBoxMetric')
self.name = name
self.eps = 1e-
self.reset() def reset(self):
self.num = #标明一个位置记录CrossEntropy Loss,一个位置记录SmoothL1 Loss
self.num_inst = [] * self.num
self.sum_metric = [0.0] * self.num def update(self, labels, preds):
cls_prob = preds[].asnumpy() #图像类别的预测概率
loc_loss = preds[].asnumpy() #回归支路的损失值,在create_multi_loss()函数中已经计算得到的Smooth L1损失值
cls_label = preds[].asnumpy() #图像目标的真实类别 valid_count = np.sum(cls_label >= ) #计算有效anchor的数量,该数量用于评价指标的计算
label = cls_label.flatten()
mask = np.where(label >= )[]
indices = np.int64(label[mask])
prob = cls_prob.transpose((, , )).reshape((-, cls_prob.shape[]))
prob = prob[mask, indices] # CrossEntropy Loss
self.sum_metric[] += (-np.log(prob + self.eps)).sum()
self.num_inst[] += valid_count # SmoothL1 Loss
self.sum_metric[] += np.sum(loc_loss)
self.num_inst[] += valid_count def get(self):
result = [sum / num if num != else float('nan') for sum, num in zip(self.sum_metric, self.num_inst)]
return (self.name, result)
在主函数main()中调用自定义的评价指标类时需要先导入对应类,然后通过mxnet.metric.CompositeMetric()接口得到指标管理对象eval_metric,然后调用eval_metric的add()方法添加对应的评价指标类,比如这里的multiBoxMetric类,参数name的设定和训练过程中的日志信息相关,最后将eval_metric作为fit()方法的参数输入即可
from tools.custom_metric import MultiBoxMetric
eval_metric = mx.metric.CompositeEvalMetric()
eval_metric.add(MultiBoxMetric(name=['CrossEntropy Loss', 'SmoothL1 Loss']))
6)训练模型
下载VGG预训练模型https://drive.google.com/open?id=1W-4xGKJZbHCZXIZY4fXfSekoQ2sE3-Ty,并将其放在model目录下
然后开始训练:
nohup python2 train.py --gpus --train-rec /opt/user/PASCAL_VOC_converge/lst/trainval.rec --train-idx /opt/user/PASCAL_VOC_converge/lst/trainval.idx --val-rec /opt/user/PASCAL_VOC_converge/lst/test.rec >> train_1.out &
如果报错:
Traceback (most recent call last):
File "train.py", line , in <module>
from symbol.get_ssd import get_ssd
ImportError: No module named get_ssd
或
Traceback (most recent call last):
File "train.py", line , in <module>
from tools.custom_metric import MultiBoxMetric
ImportError: No module named tools.custom_metric
这些错误可能是因为本地文件中没有__init__.py文件引起的,创建一个空白的__init__.py文件即可
训练结果为:
/usr/local/lib/python2./dist-packages/h5py/__init__.py:: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.
from ._conv import register_converters as _register_converters
Namespace(backbone_epoch=, backbone_prefix='model/vgg16_reduced', batch_size=, begin_epoch=, class_names='aeroplane, bicycle, bird, boat, bottle, bus, car, cat, chair, cow, diningtable, dog, horse, motorbike, person, pottedplant, sheep, sofa, train, tvmonitor', data_shape=, factor=0.1, freeze_layers='^(conv1_|conv2_).*', frequent=, gpus='', label_name='label', label_pad_width=, lr=0.001, mom=0.9, num_classes=, num_epoch=, num_examples=, save_name='ssd', save_result='output/ssd_vgg/', step='160,200', train_idx='/opt/wanghui/ageAndGender/PASCAL_VOC_converge/lst/trainval.idx', train_rec='/opt/wanghui/ageAndGender/PASCAL_VOC_converge/lst/trainval.rec', val_rec='/opt/wanghui/ageAndGender/PASCAL_VOC_converge/lst/test.rec', wd=0.0005)
[::] src/io/iter_image_det_recordio.cc:: ImageDetRecordIOParser: /opt/wanghui/ageAndGender/PASCAL_VOC_converge/lst/trainval.rec, use threads for decoding..
[::] src/io/iter_image_det_recordio.cc:: ImageDetRecordIOParser: /opt/wanghui/ageAndGender/PASCAL_VOC_converge/lst/trainval.rec, label padding width:
[::] src/io/iter_image_det_recordio.cc:: ImageDetRecordIOParser: /opt/wanghui/ageAndGender/PASCAL_VOC_converge/lst/test.rec, use threads for decoding..
[::] src/io/iter_image_det_recordio.cc:: ImageDetRecordIOParser: /opt/wanghui/ageAndGender/PASCAL_VOC_converge/lst/test.rec, label padding width:
[::] src/nnvm/legacy_json_util.cc:: Loading symbol saved by previous version v0.8.0. Attempting to upgrade...
[::] src/nnvm/legacy_json_util.cc:: Symbol successfully upgraded!
[::] src/operator/nn/./cudnn/./cudnn_algoreg-inl.h:: Running performance tests to find the best convolution algorithm, this can take a while... (setting env variable MXNET_CUDNN_AUTOTUNE_DEFAULT to to disable)
Epoch[] Batch [] Speed: 54.01 samples/sec CrossEntropy Loss=3.678806 SmoothL1 Loss=0.801627
Epoch[] Batch [] Speed: 53.12 samples/sec CrossEntropy Loss=2.281143 SmoothL1 Loss=0.752175
Epoch[] Batch [] Speed: 55.09 samples/sec CrossEntropy Loss=1.779993 SmoothL1 Loss=0.702911
Epoch[] Batch [] Speed: 55.56 samples/sec CrossEntropy Loss=1.467279 SmoothL1 Loss=0.669974
Epoch[] Batch [] Speed: 54.36 samples/sec CrossEntropy Loss=1.334813 SmoothL1 Loss=0.659752
Epoch[] Batch [] Speed: 55.33 samples/sec CrossEntropy Loss=1.298537 SmoothL1 Loss=0.623168
Epoch[] Batch [] Speed: 54.41 samples/sec CrossEntropy Loss=1.246134 SmoothL1 Loss=0.619177
Epoch[] Batch [] Speed: 54.33 samples/sec CrossEntropy Loss=1.262615 SmoothL1 Loss=0.609437
Epoch[] Batch [] Speed: 53.99 samples/sec CrossEntropy Loss=1.256767 SmoothL1 Loss=0.587360
Epoch[] Batch [] Speed: 53.62 samples/sec CrossEntropy Loss=1.216275 SmoothL1 Loss=0.558847
Epoch[] Batch [] Speed: 53.15 samples/sec CrossEntropy Loss=1.227030 SmoothL1 Loss=0.549904
Epoch[] Batch [] Speed: 53.78 samples/sec CrossEntropy Loss=1.222743 SmoothL1 Loss=0.567165
Epoch[] Batch [] Speed: 53.21 samples/sec CrossEntropy Loss=1.208321 SmoothL1 Loss=0.594028
Epoch[] Batch [] Speed: 53.32 samples/sec CrossEntropy Loss=1.210765 SmoothL1 Loss=0.569921
Epoch[] Batch [] Speed: 53.68 samples/sec CrossEntropy Loss=1.226451 SmoothL1 Loss=0.548242
Epoch[] Batch [] Speed: 55.09 samples/sec CrossEntropy Loss=1.195439 SmoothL1 Loss=0.535762
Epoch[] Batch [] Speed: 53.16 samples/sec CrossEntropy Loss=1.190477 SmoothL1 Loss=0.537575
Epoch[] Batch [] Speed: 52.66 samples/sec CrossEntropy Loss=1.193106 SmoothL1 Loss=0.519501
Epoch[] Batch [] Speed: 53.71 samples/sec CrossEntropy Loss=1.198750 SmoothL1 Loss=0.499681
Epoch[] Batch [] Speed: 53.86 samples/sec CrossEntropy Loss=1.178342 SmoothL1 Loss=0.514135
Epoch[] Batch [] Speed: 53.36 samples/sec CrossEntropy Loss=1.179339 SmoothL1 Loss=0.496589
Epoch[] Batch [] Speed: 53.04 samples/sec CrossEntropy Loss=1.175921 SmoothL1 Loss=0.526165
Epoch[] Batch [] Speed: 53.83 samples/sec CrossEntropy Loss=1.159254 SmoothL1 Loss=0.500332
Epoch[] Batch [] Speed: 54.13 samples/sec CrossEntropy Loss=1.154471 SmoothL1 Loss=0.506516
Epoch[] Batch [] Speed: 54.64 samples/sec CrossEntropy Loss=1.159192 SmoothL1 Loss=0.481005
Epoch[] Train-CrossEntropy Loss=1.144381
Epoch[] Train-SmoothL1 Loss=0.481581
Epoch[] Time cost=314.980
Epoch[] Validation-aeroplane=0.052555
Epoch[] Validation- bicycle=0.000000
Epoch[] Validation- bird=0.001830
Epoch[] Validation- boat=0.090909
Epoch[] Validation- bottle=0.000000
Epoch[] Validation- bus=0.000000
Epoch[] Validation- car=0.150089
Epoch[] Validation- cat=0.175901
Epoch[] Validation- chair=0.008707
Epoch[] Validation- cow=0.022727
Epoch[] Validation- diningtable=0.005510
Epoch[] Validation- dog=0.134398
Epoch[] Validation- horse=0.000000
Epoch[] Validation- motorbike=0.045455
Epoch[] Validation- person=0.303137
Epoch[] Validation- pottedplant=0.000000
Epoch[] Validation- sheep=0.090909
Epoch[] Validation- sofa=0.003497
Epoch[] Validation- train=0.013722
Epoch[] Validation- tvmonitor=0.000000
Epoch[] Validation-mAP=0.054967 ...
Epoch[] Train-CrossEntropy Loss=0.419221
Epoch[] Train-SmoothL1 Loss=0.184243
Epoch[] Time cost=298.695
Saved checkpoint to "output/ssd_vgg/ssd-0225.params"
Epoch[] Validation-aeroplane=0.746456
Epoch[] Validation- bicycle=0.807950
Epoch[] Validation- bird=0.731754
Epoch[] Validation- boat=0.654885
Epoch[] Validation- bottle=0.422976
Epoch[] Validation- bus=0.788919
Epoch[] Validation- car=0.837169
Epoch[] Validation- cat=0.862399
Epoch[] Validation- chair=0.545606
Epoch[] Validation- cow=0.770324
Epoch[] Validation- diningtable=0.722630
Epoch[] Validation- dog=0.840437
Epoch[] Validation- horse=0.804539
Epoch[] Validation- motorbike=0.778533
Epoch[] Validation- person=0.756137
Epoch[] Validation- pottedplant=0.482842
Epoch[] Validation- sheep=0.742795
Epoch[] Validation- sofa=0.704094
Epoch[] Validation- train=0.841322
Epoch[] Validation- tvmonitor=0.744847
Epoch[] Validation-mAP=0.729331 ...
Epoch[] Batch [] Speed: 56.65 samples/sec CrossEntropy Loss=0.426443 SmoothL1 Loss=0.183919
Epoch[] Batch [] Speed: 57.01 samples/sec CrossEntropy Loss=0.431296 SmoothL1 Loss=0.200060
Epoch[] Batch [] Speed: 52.16 samples/sec CrossEntropy Loss=0.429510 SmoothL1 Loss=0.200417
Epoch[] Batch [] Speed: 56.65 samples/sec CrossEntropy Loss=0.418150 SmoothL1 Loss=0.184664
Epoch[] Batch [] Speed: 53.66 samples/sec CrossEntropy Loss=0.462474 SmoothL1 Loss=0.211466
Epoch[] Batch [] Speed: 54.13 samples/sec CrossEntropy Loss=0.435430 SmoothL1 Loss=0.196258
Epoch[] Batch [] Speed: 55.91 samples/sec CrossEntropy Loss=0.442141 SmoothL1 Loss=0.206768
Epoch[] Batch [] Speed: 55.58 samples/sec CrossEntropy Loss=0.404212 SmoothL1 Loss=0.185162
Epoch[] Batch [] Speed: 56.38 samples/sec CrossEntropy Loss=0.433802 SmoothL1 Loss=0.204757
Epoch[] Batch [] Speed: 53.80 samples/sec CrossEntropy Loss=0.428380 SmoothL1 Loss=0.190957
Epoch[] Batch [] Speed: 54.36 samples/sec CrossEntropy Loss=0.414101 SmoothL1 Loss=0.182156
Epoch[] Batch [] Speed: 55.74 samples/sec CrossEntropy Loss=0.438334 SmoothL1 Loss=0.200135
Epoch[] Batch [] Speed: 56.93 samples/sec CrossEntropy Loss=0.425816 SmoothL1 Loss=0.198305
Epoch[] Batch [] Speed: 55.92 samples/sec CrossEntropy Loss=0.444168 SmoothL1 Loss=0.216135
Epoch[] Batch [] Speed: 55.69 samples/sec CrossEntropy Loss=0.439784 SmoothL1 Loss=0.204467
Epoch[] Batch [] Speed: 55.63 samples/sec CrossEntropy Loss=0.435857 SmoothL1 Loss=0.188829
Epoch[] Batch [] Speed: 55.63 samples/sec CrossEntropy Loss=0.447643 SmoothL1 Loss=0.215523
Epoch[] Batch [] Speed: 55.76 samples/sec CrossEntropy Loss=0.438492 SmoothL1 Loss=0.201567
Epoch[] Batch [] Speed: 54.95 samples/sec CrossEntropy Loss=0.410612 SmoothL1 Loss=0.180233
Epoch[] Batch [] Speed: 55.87 samples/sec CrossEntropy Loss=0.436391 SmoothL1 Loss=0.199497
Epoch[] Batch [] Speed: 54.86 samples/sec CrossEntropy Loss=0.414704 SmoothL1 Loss=0.185385
Epoch[] Batch [] Speed: 55.74 samples/sec CrossEntropy Loss=0.426018 SmoothL1 Loss=0.197811
Epoch[] Batch [] Speed: 55.83 samples/sec CrossEntropy Loss=0.415611 SmoothL1 Loss=0.189821
Epoch[] Batch [] Speed: 54.99 samples/sec CrossEntropy Loss=0.430231 SmoothL1 Loss=0.201216
Epoch[] Batch [] Speed: 55.18 samples/sec CrossEntropy Loss=0.427003 SmoothL1 Loss=0.193450
Epoch[] Train-CrossEntropy Loss=0.435620
Epoch[] Train-SmoothL1 Loss=0.198597
Epoch[] Time cost=298.379
Saved checkpoint to "output/ssd_vgg/ssd-0240.params"
Epoch[] Validation-aeroplane=0.753590
Epoch[] Validation- bicycle=0.805885
Epoch[] Validation- bird=0.724330
Epoch[] Validation- boat=0.663261
Epoch[] Validation- bottle=0.426557
Epoch[] Validation- bus=0.791799
Epoch[] Validation- car=0.836057
Epoch[] Validation- cat=0.860048
Epoch[] Validation- chair=0.541711
Epoch[] Validation- cow=0.780643
Epoch[] Validation- diningtable=0.723618
Epoch[] Validation- dog=0.845353
Epoch[] Validation- horse=0.805521
Epoch[] Validation- motorbike=0.778549
Epoch[] Validation- person=0.756852
Epoch[] Validation- pottedplant=0.484081
Epoch[] Validation- sheep=0.745561
Epoch[] Validation- sofa=0.704528
Epoch[] Validation- train=0.846411
Epoch[] Validation- tvmonitor=0.742994
Epoch[] Validation-mAP=0.730868
7)测试模型
训练得到模型后,就可以基于训练得到的模型进行测试,脚本为https://github.com/miraclewkf/MXNet-Deep-Learning-in-Action/blob/master/chapter9-objectDetection/9.2-objectDetection/demo.py
其主函数main()主要执行了一下几个部分:
- 调用load_model()函数导入模型,需要传入的参数包括模型保存路径、prefix、模型保存名称中的index和环境信息context
- 定义数据的预处理操作,比如通过mxnet.image.CastAug()接口将输入图像的数值类型转成float32类型,通过mxnet.image.ForceResizeAug()接口将输入图像缩放到指定尺寸,通过mxnet.image.ColorNormalizeAug()接口对输入图像的数值做归一化
- 读取测试文件夹中的图像数据,读取进来的图像先通过transform()函数进行第2点的预处理操作,然后通过mxnet.ndarray.transpose()接口调整通道维度的顺序,再通过mxnet.ndarray.expand_dims()接口增加批次维度,最终数据是维度为[N, C, H, W]的4维NDArray变量,维度表示批次、通道、高和宽。这里因为输入只有一张图,所以N=1
- 通过mxnet.io.DataBatch()接口封装数据并作为model的forward()方法的输入进行前向计算
- 调用model的get_outputs()方法得到输出。有四个输出,其中第四个输出是通过mxnet.symbol.contrib.MultiBoxDetection()接口实现的,该接口用于得到检测结果,并对预测框也做了NMS操作,因此其就是我们想要的检测结果model.get_outputs()[3]
- 去掉检测结果中类别为-1的预测框,剩下的就是目标的预测框了,对应变量det。最后调用plit_pred()函数将预测框画在测试图像上并保存在detection_result文件夹下
def main():
model = load_model(prefix="output/ssd_vgg/ssd",
index=,
context=mx.gpu()) cast_aug = mx.image.CastAug()
resize_aug = mx.image.ForceResizeAug(size=[, ])
normalization = mx.image.ColorNormalizeAug(mx.nd.array([, , ]),
mx.nd.array([, , ]))
augmenters = [cast_aug, resize_aug, normalization] img_list = os.listdir('demo_img')
for img_i in img_list:
data = mx.image.imread('demo_img/'+img_i)
det_data = transform(data, augmenters)
det_data = mx.nd.transpose(det_data, axes=(, , ))
det_data = mx.nd.expand_dims(det_data, axis=) model.forward(mx.io.DataBatch((det_data,)))
det_result = model.get_outputs()[].asnumpy()
det = det_result[np.where(det_result[:,:,] >= )]
plot_pred(det=det, data=data, img_i=img_i) if __name__ == '__main__':
main()
主函数中调用的模型导入函数load_model(),会先对图像尺寸、数据名、标签名、标签维度做初始化;然后通过mxnet.model.load_checkpoint()接口导入训练好的模型,得到模型参数arg_params和aux_params;接着通过调用get_ssd()函数构造SSD网络结构。
准备好这些内容后就可以通过mxnet.mod.Module()接口初始化得到一个Module对象——model;然后调用model的bind()方法将数据信息和网络结构添加到执行器,从而构成一个完整的能够运行的对象;最后调用model的set_params()方法用导入的模型参数初始化构建的SSD网络,这样就得到了最终的检测模型
def load_model(prefix, index, context):
batch_size =
data_width, data_height = ,
data_names = ['data']
data_shapes = [('data', (batch_size, , data_height, data_width))]
label_names = ['label']
label_shapes = [('label', (batch_size, , ))]
body, arg_params, aux_params = mx.model.load_checkpoint(prefix, index)
symbol = get_ssd(num_classes=)
model = mx.mod.Module(symbol=symbol, context=context,
data_names=data_names,
label_names=label_names)
model.bind(for_training=False,
data_shapes=data_shapes,
label_shapes=label_shapes)
model.set_params(arg_params=arg_params, aux_params=aux_params,
allow_missing=True)
return model
运行测试:
user@home:/opt/user/mxnet-learning/9.2-objectDetection$ nohup python2 demo.py >> test1.out &
若出现错误:
_tkinter.TclError: no display name and no $DISPLAY environment variable
还是和上面一样,在demo.py代码中添加:
import matplotlib
matplotlib.use('Agg')
还出现另一个错误:
IOError: cannot write mode RGBA as JPEG
这是因为得到的图片有RGBA4个通道,JPEG格式只有RGB3个通道,而PNG有RGBA4个通道
将图片保存为PNG格式即可,添加下面一样命令重置img_i为png:
plt.axis('off')
img_i = img_i.strip().split('.')[] + '.png'
plt.savefig("detection_result/{}".format(img_i))
然后可以到detection_result文件夹中去查看结果
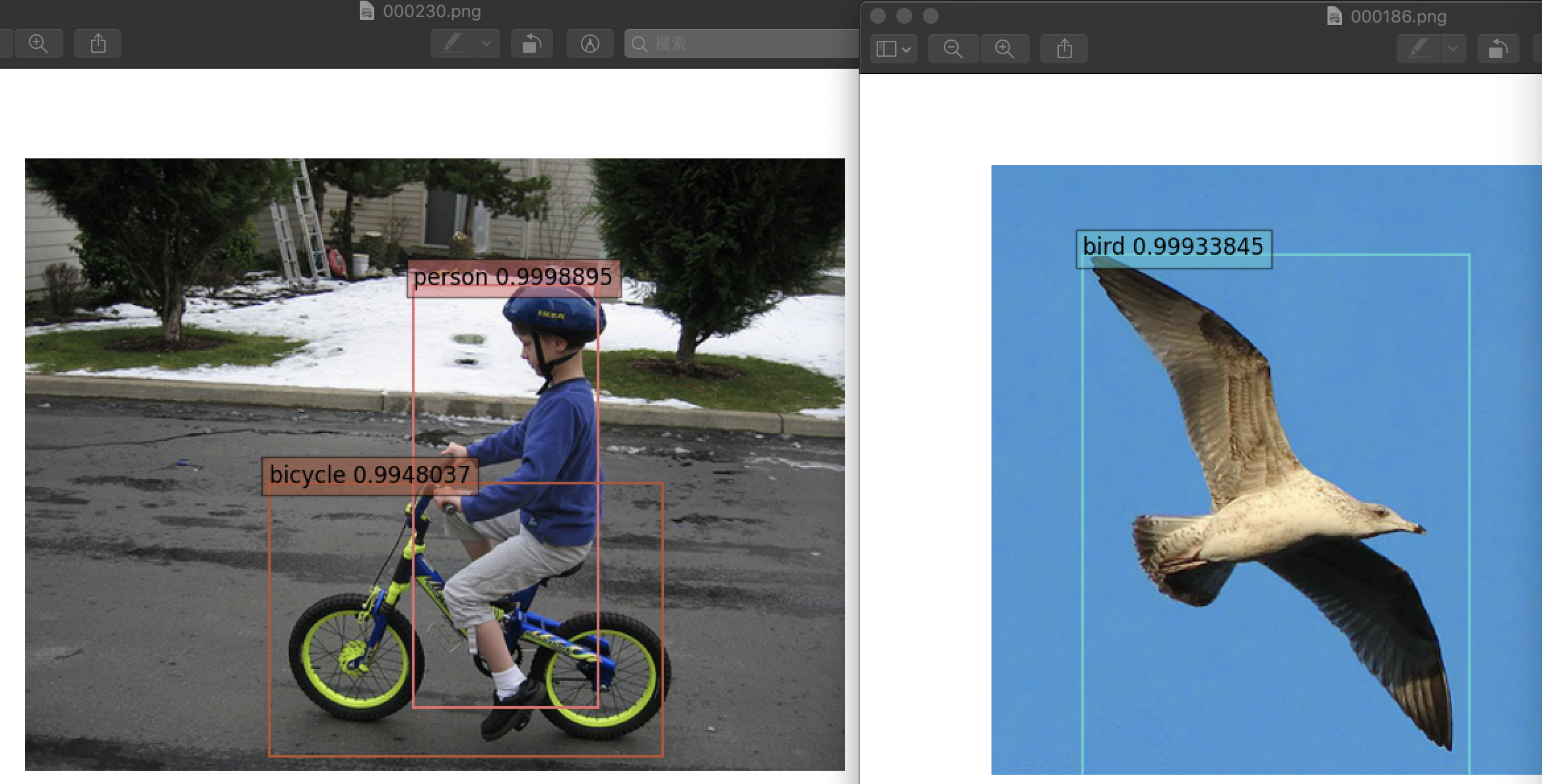
mxnet深度学习实战学习笔记-9-目标检测的更多相关文章
- 深度学习与CV教程(12) | 目标检测 (两阶段,R-CNN系列)
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/37 本文地址:http://www.showmeai.tech/article-det ...
- 深度学习与CV教程(13) | 目标检测 (SSD,YOLO系列)
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/37 本文地址:http://www.showmeai.tech/article-det ...
- CVPR2018论文看点:基于度量学习分类与少镜头目标检测
CVPR2018论文看点:基于度量学习分类与少镜头目标检测 简介 本文链接地址:https://arxiv.org/pdf/1806.04728.pdf 距离度量学习(DML)已成功地应用于目标分类, ...
- 深度学习笔记之目标检测算法系列(包括RCNN、Fast RCNN、Faster RCNN和SSD)
不多说,直接上干货! 本文一系列目标检测算法:RCNN, Fast RCNN, Faster RCNN代表当下目标检测的前沿水平,在github都给出了基于Caffe的源码. • RCNN RCN ...
- OpenCV 学习笔记 07 目标检测与识别
目标检测与识别是计算机视觉中最常见的挑战之一.属于高级主题. 本章节将扩展目标检测的概念,首先探讨人脸识别技术,然后将该技术应用到显示生活中的各种目标检测. 1 目标检测与识别技术 为了与OpenCV ...
- ng-深度学习-课程笔记-13: 目标检测(Week3)
1 目标定位( object localization ) 目标定位既要识别,又要定位,它要做的事就是用一个框框把物体目标的位置标出来. 怎么做这个问题呢,我们考虑三目标的定位问题,假定图中最多只出现 ...
- 论文笔记:目标检测算法(R-CNN,Fast R-CNN,Faster R-CNN,FPN,YOLOv1-v3)
R-CNN(Region-based CNN) motivation:之前的视觉任务大多数考虑使用SIFT和HOG特征,而近年来CNN和ImageNet的出现使得图像分类问题取得重大突破,那么这方面的 ...
- TF项目实战(基于SSD目标检测)——人脸检测1
SSD实战——人脸检测 Tensorflow 一 .人脸检测的困难: 1. 姿态问题 2.不同种族人, 3.光照 遮挡 带眼睛 4.视角不同 5. 不同尺度 二. 数据集介绍以及转化VOC: 1. F ...
- CenterNet算法笔记(目标检测论文)
论文名称:CenterNet: Keypoint Triplets for Object Detectiontection 论文链接:https://arxiv.org/abs/1904.08189 ...
随机推荐
- ES6中let、const和var的区别
一.let 1.基本用法 ES6 新增了let命令,用来声明变量. let 的用法类似于 var,但所声明的变量只在 let 命令所在的代码块内有效(一个“{}”相当于一个代码块) { let a = ...
- shell 文本替换 ---出现--- sed:-e 表达式 #1,字符 8:“s”的未知选项
需要替换的行为: monitor.url=http://192.168.25.100:8443/rest 查询资料得知,报错是因为替换的字符串包含有分隔符/ 所以这行改一下分隔符就可以解决问题了 ( ...
- zookeeper学习(2)----zookeeper和kafka的关系
转载: Zookeeper 在 Kafka 中的作用 leader 选举 和 follower 信息同步 如上图所示,kafaka集群的 broker,和 Consumer 都需要连接 Zookeep ...
- orm多表查询基于双下划线
###########基于双下划线的跨表查询(基于join实现的)############# key: 正向查询按字段,反向查询按表名小写 1.查询python这本书出版社的名字 ret = Book ...
- /tmp/supervisor.sock no such file 报错
背景: 在执行 supervisorctl 时,报了这么一个错(如图),查找对应文档后解决,记录下来用来以后遇到使用 解决: 1. 将 supervisord.conf 文件下对应的 /tmp 目录 ...
- python_面向对象——多继承
1.多继承 class Shenxian: def fly(self): print('神仙会飞~') class Monkey: def eat_peach(self): print('猴子喜欢吃桃 ...
- setTimeout与setInterval区别
setTimeout与setInterval区别 代码 setTimeout("showresponse('${rootUrl}index/movie.do','movieId')" ...
- vuex 全局store,前后端交互
1.监听input输入框 titleHandler <div> <!-- 监听input输入框 titleHandler--> <input type="tex ...
- 使用unittest测试(基础一)
#导入unittest单元测试框架 ##用例的方法前缀必须要以 test 开头的 #这是用来组织用例的 import unittest class TestDBQB(unittest.TestCase ...
- 靠边的列表如果没有设置margin-left:20px,那么是看不到列表序号的。
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...