Apache Flink - 作业和调度
Scheduling:
- Flink中的执行资源通过任务槽(Task Slots)定义。每个TaskManager都有一个或多个任务槽,每个槽都可以运行一个并行任务管道(pipeline)。管道由多个连续的任务组成,例如第n个MapFunction并行实例和第n个ReduceFunction并行实例。Flink经常并发地执行连续的任务:对于流程序,这在任何情况下都会发生,对于批处理程序,它也经常发生。
- 下图说明了这一点。考虑一个具有数据源、MapFunction和ReduceFunction的程序。数据源和MapFunction的并行度为4,而ReduceFunction的并行度为3。一个管道由Source-Map-Reduce序列组成。在一个具有2个TaskManager(每个TaskManager都有3个插槽)的集群中,程序将按照如下所述执行。

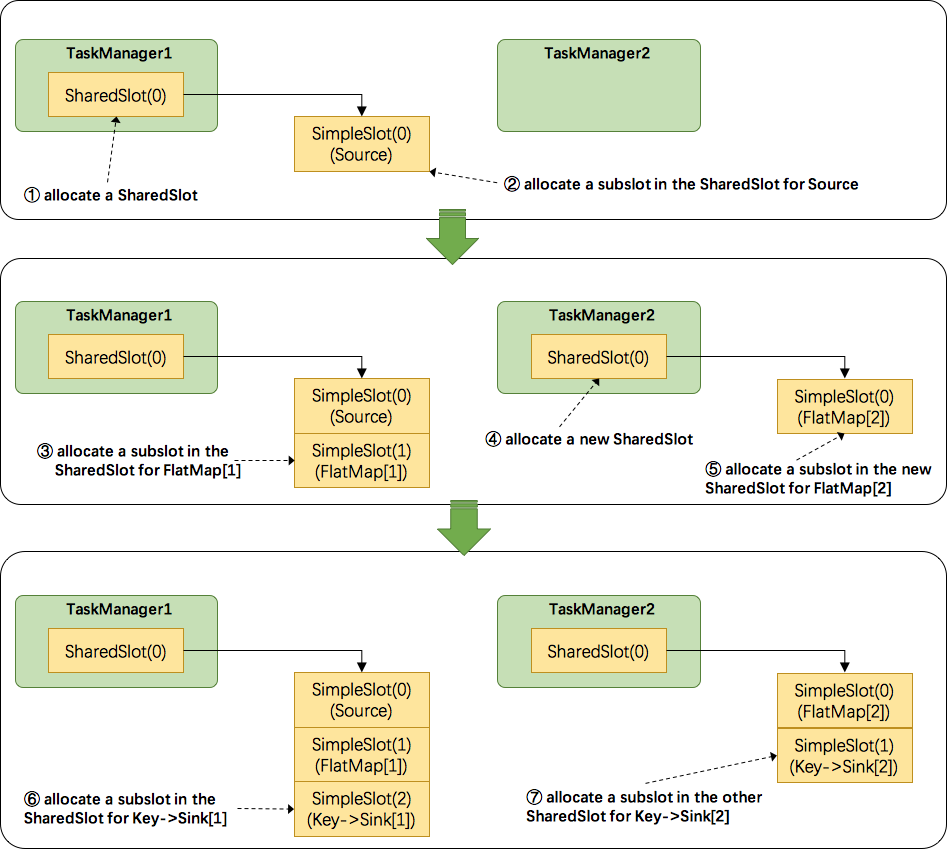
- 关于Flink调度,有两个非常重要的原则:1.同一个operator的各个subtask是不能呆在同一个SharedSlot中的,例如
FlatMap[1]和FlatMap[2]是不能在同一个SharedSlot中的。2.Flink是按照拓扑顺序从Source一个个调度到Sink的。例如WordCount(Source并行度为1,其他并行度为2),那么调度的顺序依次是:Source->FlatMap[1]->FlatMap[2]->KeyAgg->Sink[1]->KeyAgg->Sink[2]。假设现在有2个TaskManager,每个只有1个slot,那么分配slot的过程如图所示:- 为
Source分配slot。首先,我们从TaskManager1中分配出一个SharedSlot。并从SharedSlot中为Source分配出一个SimpleSlot。如上图中的①和②。 - 为
FlatMap[1]分配slot。目前已经有一个SharedSlot,则从该SharedSlot中分配出一个SimpleSlot用来部署FlatMap[1]。如上图中的③。 - 为
FlatMap[2]分配slot。由于TaskManager1的SharedSlot中已经有同operator的FlatMap[1]了,我们只能分配到其他SharedSlot中去。从TaskManager2中分配出一个SharedSlot,并从该SharedSlot中为FlatMap[2]分配出一个SimpleSlot。如上图的④和⑤。 - 为
Key->Sink[1]分配slot。目前两个SharedSlot都符合条件,从TaskManager1的SharedSlot中分配出一个SimpleSlot用来部署Key->Sink[1]。如上图中的⑥。 - 为
Key->Sink[2]分配slot。TaskManager1的SharedSlot中已经有同operator的Key->Sink[1]了,则只能选择另一个SharedSlot中分配出一个SimpleSlot用来部署Key->Sink[2]。如上图中的⑦。
最后
Source、FlatMap[1]、Key->Sink[1]这些subtask都会部署到TaskManager1的唯一个slot中,并启动对应的线程。FlatMap[2]、Key->Sink[2]这些subtask都会被部署到TaskManager2的唯一个slot中,并启动对应的线程。从而实现了slot共享。 - 为
- 最简单的情况下,一个slot只持有一个task,也就是
SimpleSlot的实现。复杂点的情况,一个slot能共享给多个task使用,也就是SharedSlot的实现。SharedSlot能包含其他的SharedSlot,也能包含SimpleSlot。所以一个SharedSlot能定义出一棵slots树。
JobManager 数据结构:
- 在job执行期间,JobManager跟踪分布式任务,决定何时调度下一个任务(或一组任务),并对完成的任务或执行失败作出反应。
- JobManager接收JobGraph,这是由运算符(JobVertex)和中间结果(IntermediateDataSet)组成的数据流的表示。每个运算符都有属性,比如并行性和它执行的代码。此外,JobGraph有一组附加的库,这些库是执行操作符代码所必需的。
- JobManager 将 JobGraph 转换为 ExecutionGraph。ExecutionGraph 是 JobGraph 的并行版本:对于每个 JobVertex,它包含每个并行子任务的 ExecutionVertex。并行度为100的运算符将有一个 JobVertex 和100个 ExecutionVertex。ExecutionVertex 跟踪特定子任务的执行状态。一个 JobVertex 中的所有 ExecutionVertex 都保存在 ExecutionJobVertex 中,它会跟踪操作符的整体状态。除顶点外,执行图还包含 IntermediateResult 和 IntermediateResultPartition。
 每个ExecutionGraph都有一个与之相关联的job状态。这个job状态指示当前工作的执行状态。
每个ExecutionGraph都有一个与之相关联的job状态。这个job状态指示当前工作的执行状态。 - Flink job首先处于创建(created)状态,然后切换到运行(running)状态,完成所有工作后切换到已完成(finished)状态。在出现故障的情况下,job首先切换到故障(failing)状态,取消所有正在运行的任务。如果所有job顶点都已达到最终状态,且job不可重新启动,则job转换为失败。如果job可以重新启动,那么它将进入重新启动状态。一旦任务完全重新启动,它将到达创建状态。如果用户取消job,它将进入取消(cancelling)状态。这还需要取消所有当前正在运行的任务。一旦所有运行的任务都达到了最终状态,任务转换到该状态就会被取消。
- 与表示全局终端状态并触发清理作业的已完成、已取消和已失败状态不同,暂停(suspended)状态仅是本地终端。本地终端意味着job的执行已经在相应的JobManager上终止,但是Flink集群的另一个JobManager可以从持久的HA存储中检索这个job并重新启动它。因此,达到暂停状态的作业不会被完全清理。

- 在执行ExecutionGraph过程中,每个并行任务都经历多个阶段,从创建到完成或失败。下面的图表说明了它们之间的状态和可能的转换。一个任务可以多次执行(例如在故障恢复过程中)。由于这个原因,ExecutionVertex的执行被跟踪。每个ExecutionVertex都有当前的执行,以及先前的执行。

Apache Flink - 作业和调度的更多相关文章
- 企业实践 | 如何更好地使用 Apache Flink 解决数据计算问题?
业务数据的指数级扩张,数据处理的速度可不能跟不上业务发展的步伐.基于 Flink 的数据平台构建.运用 Flink 解决业务场景中的具体问题等随着 Flink 被更广泛的应用于广告.金融风控.实时 B ...
- Apache Flink 为什么能够成为新一代大数据计算引擎?
众所周知,Apache Flink(以下简称 Flink)最早诞生于欧洲,2014 年由其创始团队捐赠给 Apache 基金会.如同其他诞生之初的项目,它新鲜,它开源,它适应了快速转的世界中更重视的速 ...
- Apache Flink 进阶(六):Flink 作业执行深度解析
本文根据 Apache Flink 系列直播课程整理而成,由 Apache Flink Contributor.网易云音乐实时计算平台研发工程师岳猛分享.主要分享内容为 Flink Job 执行作业的 ...
- Apache Flink 介绍
原文地址:https://mp.weixin.qq.com/s?__biz=MzU2Njg5Nzk0NQ==&mid=2247483660&idx=1&sn=ecf01cfc8 ...
- 终于等到你!阿里正式向 Apache Flink 贡献 Blink 源码
摘要: 如同我们去年12月在 Flink Forward China 峰会所约,阿里巴巴内部 Flink 版本 Blink 将于 2019 年 1 月底正式开源.今天,我们终于等到了这一刻. 阿里妹导 ...
- 《从0到1学习Flink》—— Apache Flink 介绍
前言 Flink 是一种流式计算框架,为什么我会接触到 Flink 呢?因为我目前在负责的是监控平台的告警部分,负责采集到的监控数据会直接往 kafka 里塞,然后告警这边需要从 kafka topi ...
- Apache Flink流式处理
花了四小时,看完Flink的内容,基本了解了原理. 挖个坑,待总结后填一下. 2019-06-02 01:22:57等欧冠决赛中,填坑. 一.概述 storm最大的特点是快,它的实时性非常好(毫秒级延 ...
- Apache Flink 开发环境搭建和应用的配置、部署及运行
https://mp.weixin.qq.com/s/noD2Jv6m-somEMtjWTJh3w 本文是根据 Apache Flink 系列直播课程整理而成,由阿里巴巴高级开发工程师沙晟阳分享,主要 ...
- Apache Flink 整体介绍
前言 Flink 是一种流式计算框架,为什么我会接触到 Flink 呢?因为我目前在负责的是监控平台的告警部分,负责采集到的监控数据会直接往 kafka 里塞,然后告警这边需要从 kafka topi ...
随机推荐
- javascript原型原型链 学习随笔
理解原型和原型链.需从构造函数.__proto__属性(IE11以下这个属性是undefined,请使用chrome调试).prototype属性入手. JS内置的好多函数,这些函数又被叫做构造函数. ...
- ArcCatalog连接数据库报错
ArcCatalog连接数据库报错: Failed to connect to database. Cannot connect to database because the database cl ...
- web安全在线工具梳理
目录: (一)搜索引擎语法一.百度.国内二.bing(必应).微软的三.google.国外 (二)网络空间搜索引擎用于查找网络空间的目标设备一.撒旦.国外二.钟馗之眼.国内三.佛法.国内 (三)在线w ...
- Android笔记(三十三) Android中线程之间的通信(五)Thread、Handle、Looper和MessageQueue
ThreadLocal 往下看之前,需要了解一下Java的ThreadLocal类,可参考博文: 解密ThreadLocal Looper.Handler和MessageQueue 我们分析一下之前的 ...
- Pyspark笔记一
1. pyspark读csv文件后无法显示中文 #pyspark读取csv格式时,不能显示中文 df = spark.read.csv(r"hdfs://mymaster:8020/user ...
- WebClient 与HttpClient 的区别
需要搜索下资料. -------------------------------------------------- 微软文档介绍,新的开发中推荐使用:HttpClient WebClient 文档 ...
- G1垃圾收集器堆内存划分与角色分派【纯理论】
接着上一次[https://www.cnblogs.com/webor2006/p/11123522.html]G1学习继续开启理论之旅.. G1的设计规划是要替换掉CMS[理想化的] G1在某些方面 ...
- js rsa sign使用笔记(加密,解密,签名,验签)
你将会收获: js如何加密, 解密 js如何签名, 验签 js和Java交互如何相互解密, 验签(重点) 通过谷歌, 发现jsrsasign库使用者较多. 查看api发现这个库功能很健全. 本文使用方 ...
- Codeforces Round #609 (Div. 2) C. Long Beautiful Integer
链接: https://codeforces.com/contest/1269/problem/C 题意: You are given an integer x of n digits a1,a2,- ...
- vue2 自定义过滤器