java中创建线程的方式
创建线程的方式:
- 继承thread
- 实现runnable
- 线程池
- FurureTask/Callable
第一种:继承thread
demo1:
public class demo1 {
public static void main(String[] args) {
new MyThread().start();
}
}
class MyThread extends Thread{
public void run(){
System.out.println("线程创建");
}
}
第二种:实现runnable
demo2:
public class demo2 {
public static void main(String[] args) {
new Thread(new MyThreadRun()).start();
}
}
class MyThreadRun implements Runnable{
@Override
public void run() {
System.out.println("线程创建");
}
}
用实现runnable接口的方法时,我们一般使用匿名类的形式:
public class demo2 {
public static void main(String[] args) {
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("线程创建");
}
}).start();
}
}
由于Runnable是函数式接口,所以可以使用lambda表达式来写:
public class demo2 {
public static void main(String[] args) {
new Thread(()->{
System.out.println("线程创建");
}).start();
}
}
第三种:使用线程池:
首先了解一下线程池的优点:
线程池做的工作只要是控制运行的线程数量,处理过程中将任务放入队列,然后在线程创建后启动这些任务,如果线程数量超过了最大数量,超出数量的线程排队等候,等其他线程执行完毕,再从队列中取出任务来执行。
它的主要特点为:线程复用;控制最大并发数;管理线程。
第一:降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的销耗。
第二:提高响应速度。当任务到达时,任务可以不需要等待线程创建就能立即执行。
第三:提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会销耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
Java中的线程池是通过Executor框架实现的,该框架中用到了Executor,Executors,ExecutorService,ThreadPoolExecutor这几个类。
Executors有三个创建线程池的方法:
//线程池中创建固定线程数
ExecutorService executorService1 = Executors.newFixedThreadPool(5);
//线程池中创建一个线程
ExecutorService executorService12 = Executors.newSingleThreadExecutor();
//线程池中创建扩容的线程
ExecutorService executorService13 = Executors.newCachedThreadPool();
再来看看他们的源码:
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
可以看到他们最终都是调用同一个方法new ThreadPoolExecutor(),我们再来看看这个构造方法:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
可以看到创建一个线程池需要传入七大参数:
1、corePoolSize:线程池中的常驻核心线程数
2、maximumPoolSize:线程池中能够容纳同时执行的最大线程数,此值必须大于等于1
3、keepAliveTime:多余的空闲线程的存活时间当前池中线程数量超过corePoolSize时,当空闲时间达到keepAliveTime时,多余线程会被销毁直到只剩下corePoolSize个线程为止
4、unit:keepAliveTime的单位
5、workQueue:任务队列,被提交但尚未被执行的任务
6、threadFactory:表示生成线程池中工作线程的线程工厂,用于创建线程,一般默认的即可
7、handler:拒绝策略,表示当队列满了,并且工作线程大于等于线程池的最大线程数(maximumPoolSize)时如何来拒绝请求执行的runnable的策略
这时我们再回头看这三个创建线程池的方法,这些传入参数的含义,这里我们还要了解一下BlockingQueue阻塞队列,在创建可扩容的线程池时,采用的阻塞队列与其他两者不一样。
BlockingQueue:
ArrayBlockingQueue:由数组结构组成的有界阻塞队列。
LinkedBlockingQueue:由链表结构组成的有界(但大小默认值为integer.MAX_VALUE)阻塞队列。
PriorityBlockingQueue:支持优先级排序的无界阻塞队列。
DelayQueue:使用优先级队列实现的延迟无界阻塞队列。
SynchronousQueue:不存储元素的阻塞队列,也即单个元素的队列。
LinkedTransferQueue:由链表组成的无界阻塞队列。
LinkedBlockingDeque:由链表组成的双向阻塞队列。
常用方法:


handler:拒绝策略,等待队列已经排满了,再也塞不下新任务了同时,线程池中的max线程也达到了,无法继续为新任务服务,这时候我们需要使用拒绝策略。
AbortPolicy(默认):直接抛出RejectedExecutionException异常阻止系统正常运行
CallerRunsPolicy:“调用者运行”一种调节机制,该策略既不会抛弃任务,也不会抛出异常,而是将某些任务回退到调用者,从而降低新任务的流量。
DiscardOldestPolicy:抛弃队列中等待最久的任务,然后把当前任务加人队列中尝试再次提交当前任务。
DiscardPolicy:该策略默默地丢弃无法处理的任务,不予任何处理也不抛出异常。如果允许任务丢失,这是最好的一种策略。
了解了这些参数以后,我们知道了三种创建线程池的优缺点,但我们一般不会去用他们,而是采用自定义的线程池。
ExecutorService executorService = new ThreadPoolExecutor(
2,
5,
20,
TimeUnit.SECONDS,
new LinkedBlockingDeque<>(3),
new ThreadPoolExecutor.CallerRunsPolicy());
我们写一个demo:
public class ThreadPoolDemo {
public static void main(String[] args) {
/* //线程池中创建固定线程数
ExecutorService executorService1 = Executors.newFixedThreadPool(5);
//线程池中创建一个线程
ExecutorService executorService12 = Executors.newSingleThreadExecutor();
//线程池中创建扩容的线程
ExecutorService executorService13 = Executors.newCachedThreadPool();*/
ExecutorService executorService = new ThreadPoolExecutor(
2,
5,
20,
TimeUnit.SECONDS,
new LinkedBlockingDeque<>(3),
new ThreadPoolExecutor.CallerRunsPolicy());
for (int i = 1; i < 10 ; i++) {
new Thread(()->{
executorService.execute(()->{
System.out.println(Thread.currentThread().getName()+"处理任务");
});
},""+i).start();
}
}
}
线程池原理
1、在创建了线程池后,开始等待请求。
2、当调用execute()方法添加一个请求任务时,线程池会做出如下判断:
2.1如果正在运行的线程数量小于corePoolSize,那么马上创建线程运行这个任务;
2.2如果正在运行的线程数量大于或等于corePoolSize,那么将这个任务放入队列;
2.3如果这个时候队列满了且正在运行的线程数量还小于maximumPoolSize,那么还是要创建非核心线程立刻运行这个任务;
2.4如果队列满了且正在运行的线程数量大于或等于maximumPoolSize,那么线程池会启动饱和拒绝策略来执行。
3、当一个线程完成任务时,它会从队列中取下一个任务来执行。
4、当一个线程无事可做超过一定的时间(keepAliveTime)时,线程会判断:
如果当前运行的线程数大于corePoolSize,那么这个线程就被停掉。
所以线程池的所有任务完成后,它最终会收缩到corePoolSize的大小。
第四种:FurureTask/Callable
FurureTask/Callable的使用和Runnable很像,我们先来看看demo:
class CallAbleTest implements Callable{
@Override
public Integer call() throws Exception {
return 1024;
}
}
public class CallableDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
CallAbleTest callAbleTest = new CallAbleTest();
FutureTask<Integer> futureTask = new FutureTask<>(callAbleTest);
new Thread(futureTask).start();
Integer result = futureTask.get();
System.out.println("reault"+result);
new Thread(futureTask).start();
System.out.println("result:"+futureTask.get());
}
}
我们写一个实现Callable接口的实现类,并重写它的方法。我们可以看到和Runnable的区别:
(1)是否有返回值
(2)是否抛异常
(3)重写方法不一样,一个是run,一个是call
FurureTask/Callable为我们提供了一个更为强大的方法。
由于Callable是一个函数式接口,我们也可以像Runnable一样,写一个匿名内部类的lambda表达式的形式。
public class CallableDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
FutureTask<Integer> futureTask = new FutureTask<Integer>(()->{
return 1024;
});
new Thread(futureTask).start();
System.out.println("result:"+futureTask.get());
}
}
需要注意一点,获取返回值需要通过futureTask.get()获取,这是一个阻塞方法,当所有的线程任务还没有完成时,它就会阻塞到这里等待。例如有三个线程任务,
一个任务执行5秒,一个3秒一个2秒,那么线程总共就会阻塞5秒,等待所有任务线程执行结束。
原理:
在主线程中需要执行比较耗时的操作时,但又不想阻塞主线程时,可以把这些作业交给Future对象在后台完成,
当主线程将来需要时,就可以通过Future对象获得后台作业的计算结果或者执行状态。
一般FutureTask多用于耗时的计算,主线程可以在完成自己的任务后,再去获取结果。
仅在计算完成时才能检索结果;如果计算尚未完成,则阻塞 get 方法。一旦计算完成,
就不能再重新开始或取消计算。get方法而获取结果只有在计算完成时获取,否则会一直阻塞直到任务转入完成状态,
然后会返回结果或者抛出异常。
还有一点就是为什么new Thread(futureTask).start();可以传入一个futureTask,我们可以看看new Thread()方法,
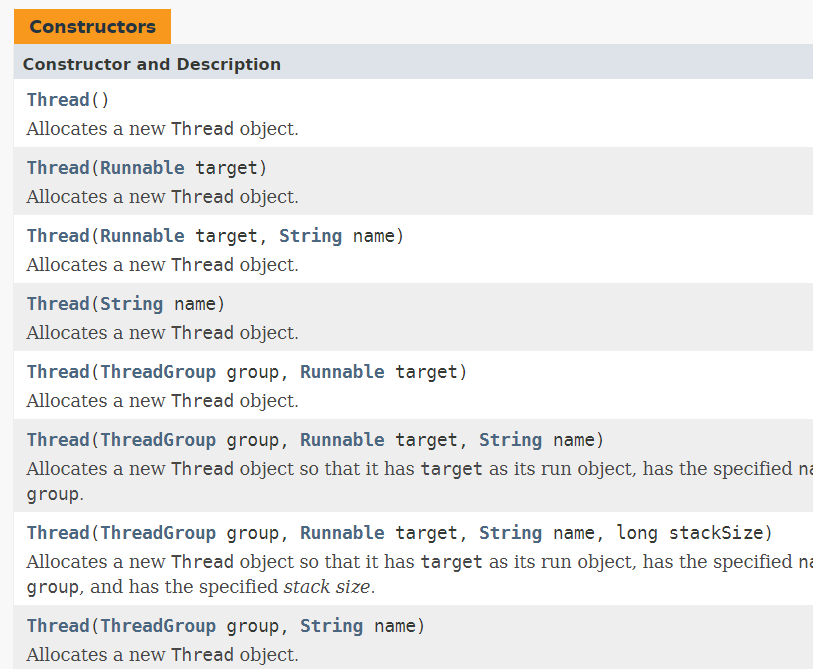
只有与Runnable相关的方法,那么我们应该可以猜到futureTask应该是Runnable的实现类,我们来看看他们的结构关系,可以看到FutureTask确实是实现类。
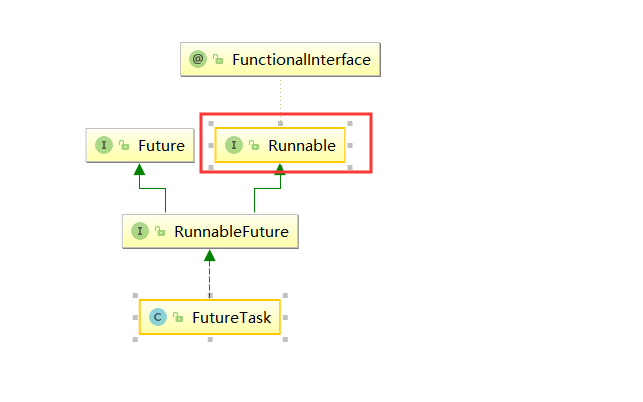
以上就是四种创建线程的方法了,有错误,欢迎指正^-^。
java中创建线程的方式的更多相关文章
- JAVA中创建线程的三种方法及比较
JAVA中创建线程的方式有三种,各有优缺点,具体如下: 一.继承Thread类来创建线程 1.创建一个任务类,继承Thread线程类,因为Thread类已经实现了Runnable接口,然后重写run( ...
- Java中创建线程的三种方式以及区别
在java中如果要创建线程的话,一般有3种方法: 继承Thread类: 实现Runnable接口: 使用Callable和Future创建线程. 1. 继承Thread类 继承Thread类的话,必须 ...
- java 中创建线程有哪几种方式?
Java中创建线程主要有三种方式: 一.继承Thread类创建线程类 (1)定义Thread类的子类,并重写该类的run方法,该run方法的方法体就代表了线程要完成的任务.因此把run()方法称为执行 ...
- Java中实现线程的方式
Java中实现线程的方式 Java中实现多线程的方式的方式中最核心的就是 run()方法,不管何种方式其最终都是通过run()来运行. Java刚发布时也就是JDK 1.0版本提供了两种实现方式,一个 ...
- JAVA中创建线程池的五种方法及比较
之前写过JAVA中创建线程的三种方法及比较.这次来说说线程池. JAVA中创建线程池主要有两类方法,一类是通过Executors工厂类提供的方法,该类提供了4种不同的线程池可供使用.另一类是通过Thr ...
- Java中创建线程的两种方式
创建线程的第一种方式: 创建一个类继承Thread 重写Thread中的run方法 (创建线程是为了执行任务 任务代码必须有存储位置,run方法就是任务代码的存储位置.) 创建子类对象,其实就是在创建 ...
- Java之创建线程的方式四:使用线程池
import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;import java.util.c ...
- Java之创建线程的方式三:实现Callable接口
import java.util.concurrent.Callable;import java.util.concurrent.ExecutionException;import java.util ...
- Java中创建线程主要有三种方式
一.继承Thread类创建线程类 (1)定义Thread类的子类,并重写该类的run方法,该run方法的方法体就代表了线程要完成的任务.因此把run()方法称为执行体. (2)创建Thread子类的实 ...
随机推荐
- Ubuntu18.04开机动画(bootsplash)安装
一.搜索喜欢的主题 1.通过软件源搜索,这个比较简单但是没有太喜欢的.-----------------------------------------------------------pipci@ ...
- OS创建页目录和页
;开始创建页目录项(PDE) .create_pde: ; 创建Page Directory Entry mov eax, PAGE_DIR_TABLE_POS ; PAGE_DIR_TABLE_PO ...
- Codeforces - 2019年11月补题汇总
大概目标是补到 #500 为止的 Div. 2 ,先定个小目标,寒假开始前补到 #560 为止 Codeforces Round #599 (Div. 2) 5/6 备注:0-1BFS(补图连通块) ...
- Linux的MySQL安装和配置(详细)
打开centos系统 输入root用户和密码(我的用户和密码都是root) 查看有没有安装mysql rpm -qa|grep mysql 没有返回任何信息说明没有安装 我是用的centos7,默认安 ...
- CSS 交集选择器和并集选择器
交集选择器是and 也就是要同时满足 且只能交2个只能交2个只能交2个,第一个是标记,第二个是class或者id,之间不可以有空格 eg: span.small-height 并集选择器是or,也就 ...
- Linux中man命令的使用方法再解释
原文链接:http://www.linuxidc.com/Linux/2017-03/142407.htm Linux提供了丰富的帮助手册,当你需要查看某个命令的参数时不必到处上网查找,只要man一下 ...
- 2018-2019-2 网络对抗技术 20165311 Exp 8 Web基础
2018-2019-2 网络对抗技术 20165311 Exp 8 Web基础 基础问题回答 实践过程记录 1.Web前端:HTML 2.Web前端:javascipt 3.Web后端:MySQL基础 ...
- Mac地址转换成long长整型 2
数据之间的转换可以使用 System.Convert Mac地址转换成long长整型 /// <summary> /// 解析长整形的数据使其转换为macID /// </sum ...
- Java List 和 Array 转化
List to Array List 提供了toArray的接口,所以可以直接调用转为object型数组 List<String> list = new ArrayList<Stri ...
- VS下设置dll环境变量目录的方法
项目=>属性=>Debugging PATH=路径