Openstack知识点总结
Openstack:
一.云计算+openstack概念:
1.云计算是一种按使用量付费的模式,这种模式提供可用的,便捷的,按需的访问,通过互联网进入可配置的计算资源共享池(资源包括网络,计算,存储,应用软件,服务);
2.OpenStack:是一个开源的云计算管理平台项目,由几个主要的组件组合起来完成具体工作,项目目标是提供实施简单、可大规模扩展、丰富、标准统一的云计算管理平台。
二.Openstack组件
共享服务组件(6个):
数据库服务(database service):Mariadb及Mongodb
消息传输(Message Queues): RabbitMQ
缓存(cache):Memcached
时间同步(time sync):ntp
存储(storge provider):ceph,GFS,LVM,ISICI等
高可用及负载均衡:pacemaker,HAproxy,keepalived,lvs
核心组件:
身份服务(Identity Service):Keystone
计算服务(compute):Nova
镜像服务(Image Service):Glance
网络服务(Network):Neutron
块存储服务(Block Storage):Cinder
Web界面服务(Dashboard):Horizon
对象存储(Object Storage):Swift
测量(Metering):Ceillrmeter
部署编排(Orchestration):Heat
三.RabbitMQ
1.概念:属于一个流行的开源消息队列系统。属于AMQP( 高级消息队列协议 ) 标准的一个 实现。是应用层协议的一个开放标准,为面向消息的中间件设计。用于在分布式系统中存储转发消息,在 易用性、扩展性、高可用性等方面表现不俗。
2.耦合/解耦合
3.rabbitmq中的概念:
Broker:简单来说就是消息队列服务器实体。
Exchange:消息交换机,它指定消息按什么规则,路由到哪个队列。
Queue:消息队列载体,每个消息都会被投入到一个或多个队列。
Binding:绑定,它的作用就是把exchange和queue按照路由规则绑定起来。
Routing Key:路由关键字, exchange根据这个关键字进行消息投递。
vhost:虚拟主机,一个broker里可以开设多个vhost,用作不同用户的权限分离。
producer:消息生产者,就是投递消息的程序。
consumer:消息消费者,就是接受消息的程序。
channel:消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务。
4.工作原理

( 1)客户端连接到消息队列服务器,打开一个channel。
( 2)客户端声明一个exchange,并设置相关属性。
( 3)客户端声明一个queue,并设置相关属性。
( 4)客户端使用routing key,在exchange和queue之间建立好绑定关系。
( 5)客户端投递消息到exchange。
( 6) exchange接收到消息后,就根据消息的key和已经设置的binding,进行消息路由,将消息投递到一个或多个队列里。
5.rabbitmq集群部署: 注意必须至少要有一个disk node
四.Memcache
1.概念:
Memcached 是一个开源的、高性能的分布式内存对象缓存系统。通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高网站访问速度,加速动态WEB应用、减轻数据库负载。
2.缓存流程:
(1). 检查客户端请求的数据是否在 Memcache 中,如果存在,直接将请求的数据返回,不在对数据进行任何操作。
(2).如果请求的数据不在 Memcache 中,就去数据库查询,把从数据库中获取的数据返回给客户端,同时把数据缓存一份 Memcache 中
(3).每次更新数据库的同时更新 Memcache 中的数据库。确保数据信息一致性。
(4).当分配给 Memcache 内存空间用完后,会使用LRU(least Recently Used ,最近最少使用 ) 策略加到其失效策略,失效的数据首先被替换掉,然后在替换掉最近未使用的数据
五.Keystone
1.概念:
用于为OpenStack家族中的其它组件成员提供统一的认证服务,包括身份验证、令牌的发放和校验、服务列表、用户权限的定义等。云环境中所有的服务之间的授权和认证都需要经过 keystone.
(1).管理用户及其权限;
(2).维护 OpenStack Services 的 Endpoint;
(3).Authentication(认证)和 Authorization(鉴权)
2.keystone中概念:
(1).user:指代任何使用open stack的实体,可以是真正的用户,其他系统或服务;
(2).Credentials:是user用来证明自己身份的信息,可以是1. 用户名/密码;2.Token;3. API Key;4. 其他高级方式.
(3). Authentication:是 Keystone 验证 User 身份的过程。User 访问 OpenStack时向 Keystone 提交用户名和密码形式的 Credential,Keystone 验证通过后会给 User 签发一个 Token 作为后续访问的 Credential。
(4).Token: Token 是由数字和字母组成的字符串,user成功Authentication后成Token并分配给user。Token用作访问Service的Credential;Service会通过Keystone验证Token的有限性;Token的有效期默认24小时。
(5).Project:用于将open stack的资源进行分组和隔离。根据openstack的服务对象不同,project可以是一个客户,部门或者项目组。
(6).Service:包括nova,glance,cinder,neutron等,每个service会提供若干个Endpoint,user通过Endpoint访问资源和执行操作。
(7).Endpoint:是一个网络上可访问的地址,通常是一个URL。Service通过Endpoint暴露自己的API,Keystone负责管路和维护每个service的Endpoint.
(8).Role:可以为user分配一个或多个Role,Service决定每个role能做什么事,系统基本角色有两个:管理员admin和租户_member_
3.Keystone基本框架
Token: 用来生成和管理token
Catalog: 用来存储和管理service/endpoint
Identity: 用来管理tenant/user/role和验证
Policy: 用来管理访问权限

4.通过’查询可用image’这个实际操作让大家更加清晰keystone的工作过程及原理:
第一步:登入。
用户admin拿着credential请求登入,Authentication认证通过,并给admin用户一个token;
第二步:显示操作界面。
进入操作界面后,这时admin需要访问image服务。在访问image前发生了:admin询问keystone询问到了能访问admin和demo两个project,同时可以访问instance,Volume,glance等服务。因为这时admin已经从keystone拿到了service的Endpoints.
第三步:显示image列表。
Admin要查看project admin中的image,先是把将请求发送到Glance的Endpoint,Glance向keystone询问admin身份是否有效,接下来Glance会查看/etc/glance/policy.json判断admin是否有查看image的权限。权限判定后,Glance将image列表发给admin。
5.keystone主要有两个日志:keystone.log和keystone_access.log,保存在/var/log/apache2/目录里
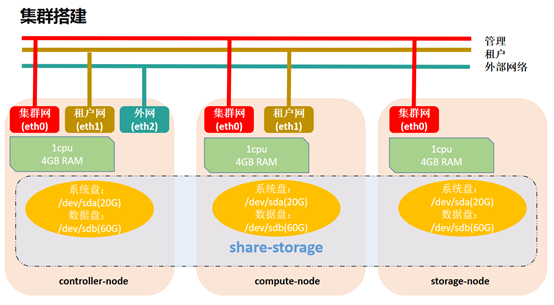
6.集群搭建图
六.Glance
1.glance介绍:是openstack项目中负责镜像管理的模块,其功能包括虚拟机镜像的查找,注册和检索等。Glance提供restful api可以查询虚拟机镜像的metadata及获取镜像。Glance可以将镜像保存到多种后端存储上,比如简单的文件存储或者对象存储。
2.Glance架构
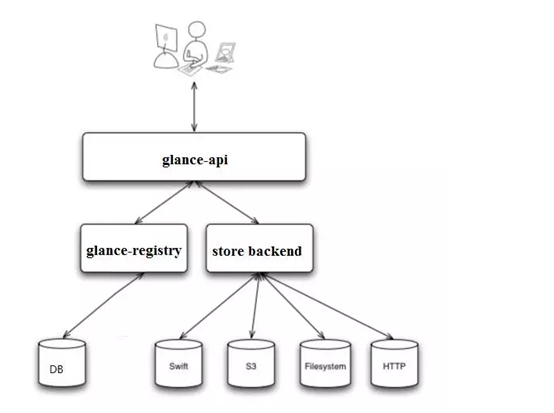
Glance-api
Glance-api是系统后台运行的服务进程,对外提供REST API,响应Image查询,获取和存储的调用。Glance-api不会真正处理请求,如果操作是与image metadata相关,glance-api会把请求转发给glance-registry;如果操作是与image自身存取相关,glance-api会把请求转发给image的store backend.
Glance-registry
Glance-registry是系统后台运行的服务进程,负责处理和存取image的metadata,例如image的大小和类型。Glance支持多种格式的image,比较常用的有:Raw,vmdk,ISO,QCOW2.Image的metadata会保持到database中,默认是MySQL。
Store backend
Glance自己并不存储image,真正的image是存放在backend中。Glance支持多种backend,默认是:A directory on a local file system(Filesystem)具体使用哪种backend,实在/etc/glance/glance-api.conf 中配置。
3.创建Image
方法一:在web界面中创建(步骤见博客)
方法二:在命令行创建
1. 将image上传到控制节点的文件系统中,例如: /tmp/cirros-0.3.5-x86_64-disk.img
2. glance image-create --name cirros1 --file /tmp/cirros-0.3.5-x86_64-disk.img --disk-format qcow2 --container-format bare --progress
一般创建比较大的镜像用命令行创建会更快和方便。
Image放在/var/lib/glance/images/下
4.glance日志:glance_api.log 和glance_registry.log,保存/var/log/glance目录中
七.Nova
1.nova介绍:是openstack最核心的服务,负责维护和管理云计算计算资源。
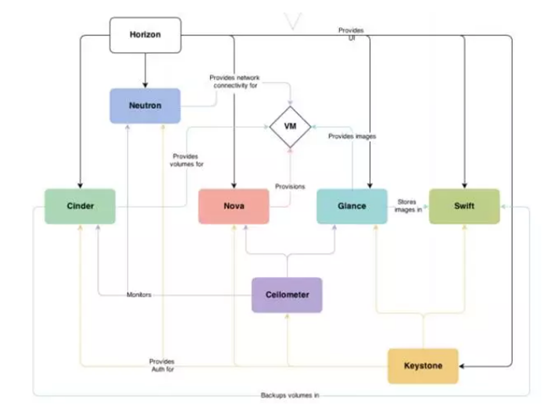
从上图可以看出,nova处于openstack架构的中心,其他组件都为nova提供支持glance为VM提供image,cinder和swift分别为VM提供块存储和对象存储,neutron提供网络连接。
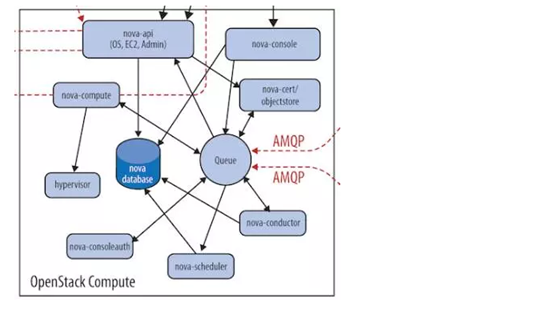
2.nova组件介绍
1.nova-api:
是整个nova的门户,所有对nova的请求都首先由nova-api处理。Nova-api向外暴露若干HTTP rest api 接口在keystone中,客户端可以将请求发送到endpoint指定的地址,向nova-api请求操作。
Nova-api对收到的HTTP api请求会做如下处理:
(1).检查客户端传入的参数是否合法;
(2).调用nova其他子服务的处理客户端HTTP请求;
(3).格式化nova其他子服务返回的结果并返回给客户端。
2.nova-conductor:
Nova-compute需要获取和更新数据库中instance的信息,但nova-compute并不会直接访问数据库,而是通过nova-conductor实现数据的访问。
使用nova-conductor的两个显著好处:
(1).更好的系统安全性:早期的openstack版本中,nova-compute可以直接访问数据库,但试想如果任意一个计算节点被黑客入侵,都会导致控制节点上的数据库面临极大的风险。为了解决这个问题,引入了nova-conductor;
(2)更好的伸缩性:nova-conductor建立后,提高了nova的伸缩性。Nova-compute与conductor是通过消息中间件交互的。这种松散的架构允许配置多个nova-conductor实例,从而应对日益增长的计算节点对数据库的访问。
3.nova-scheduler
虚拟机调度服务,负责决定在哪个计算节点上运行虚机。
如何选择计算节点——启动实例调度策略
Filter scheduler(调度器),调度过程分两步:
(1).通过过滤器(filter)选择满足条件的计算节点(运行nova-compute)
(2).通过权重计算(weighting)选择在最优(权重值最大)的计算节点上创建instance
Filter具体有哪些:
RetryFilter
AvailabilityZoneFilter
RamFilter
DiskFilter
CoreFilter
ComputeFilter
ComputeCapabilitiesFilter
ImagePropertiesFilter
ServerGroupAntiAffinityFilter
ServerGroupAffinityFilter
Weight: 默认实现是根据计算节点空闲的内存量计算权重值: 空闲内存越多,权重越大,instance 将被部署到当前空闲内存最多的计算节点上。
4.nova-compute(装在计算节点上)
nova-compute 在计算节点上运行,负责管理节点上的 instance。OpenStack 对 instance 的操作,最后都是交给 nova-compute 来完成的。nova-compute 与 Hypervisor 一起实现 OpenStack 对 instance 生命周期的管理。
5.Console Interface
nova-console:
用户可以通过多种方式访问虚机的控制台:
nova-novncproxy,基于 Web 浏览器的 VNC 访问
nova-spicehtml5proxy,基于 HTML5 浏览器的 SPICE 访问
nova-xvpnvncproxy,基于 Java 客户端的 VNC 访问
nova-consoleauth
负责对访问虚机控制台请求提供 Token 认证
nova-cert
提供 x509 证书支持
3.从创建虚机流程看nova子服务如何协同工作
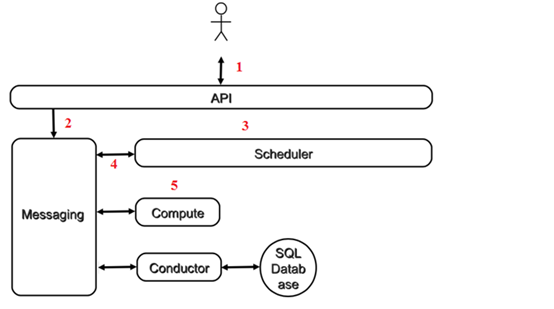
1.客户(可以是 OpenStack 最终用户,也可以是其他程序)向 API(nova-api)发送请求:“帮我创建一个虚机”
2.API 对请求做一些必要处理后,向 Messaging(RabbitMQ)发送了一条消息:“让 Scheduler 创建一个虚机”
3.Scheduler(nova-scheduler)从 Messaging 获取到 API 发给它的消息,然后执行调度算法,从若干计算节点中选出节点 A
4.Scheduler 向 Messaging 发送了一条消息:“在计算节点 A 上创建这个虚机”
5.计算节点 A 的 Compute(nova-compute)从 Messaging 中获取到 Scheduler 发给它的消息,然后在本节点的 Hypervisor 上启动虚机。
6.在虚机创建的过程中,Compute 如果需要查询或更新数据库信息,会通过 Messaging 向 Conductor(nova-conductor)发送消息,Conductor 负责数据库访问。
在前面创建虚机的流程示意图中,我们看到 nova-* 子服务之间的调用严重依赖 Messaging。Messaging 是 nova-* 子服务交互的中枢。
以前没接触过分布式系统的同学可能会不太理解为什么不让 API 直接调用Scheduler,或是让Scheuler 直接调用 Compute,而是非要通过 Messaging 进行中转。 这里做一些解释。程序之间的调用通常分两种:同步调用和异步调用。
同步调用
API 直接调用 Scheduler 的接口是同步调用。 其特点是 API 发出请求后需要一直等待,直到 Scheduler 完成对 Compute 的调度,将结果返回给 API 后 API 才能够继续做后面的工作。
异步调用
API 通过 Messaging 间接调用 Scheduler 就是异步调用。 其特点是 API 发出请求后不需要等待,直接返回,继续做后面的工作。 Scheduler 从 Messaging 接收到请求后执行调度操作,完成后将结果也通过 Messaging 发送给 API。在 OpenStack 这类分布式系统中,通常采用异步调用的方式,其好处是:
1.解耦各子服务。 子服务不需要知道其他服务在哪里运行,只需要发送消息给 Messaging 就能完成调用。
2.提高性能 异步调用使得调用者无需等待结果返回。这样可以继续执行更多的工作,提高系统总的吞吐量。
3.提高伸缩性 子服务可以根据需要进行扩展,启动更多的实例处理更多的请求,在提高可用性的同时也提高了整个系统的伸缩性。而且这种变化不会影响到其他子服务,也就是说变化对别人是透明的。
4.实现 instance 生命周期的管理
nova-compute 创建 instance 的过程可以分为 4 步:
(1).为 instance 准备资源
(2).创建 instance 的镜像文件
(3).创建 instance 的 XML 定义文件
(4).创建虚拟网络并启动虚拟机
5.Nova 创建虚拟机详细过程

1.界面或命令行通过RESTful API向keystone获取认证信息。
2、keystone通过用户请求认证信息,并生成auth-token返回给对应的认证请求。
3、界面或命令行通过RESTful API向nova-api发送一个boot instance的请求(携带auth-token)。
4、nova-api接受请求后向keystone发送认证请求,查看token是否为有效用户和token。
5、keystone验证token是否有效,如有效则返回有效的认证和对应的角色(注:有些操作需要有角色权限才能操作)。
6、通过认证后nova-api和数据库通讯。
7、初始化新建虚拟机的数据库记录。
8、nova-api通过rpc.call向nova-scheduler请求是否有创建虚拟机的资源(Host ID)。
9、nova-scheduler进程侦听消息队列,获取nova-api的请求。
10、nova-scheduler通过查询nova数据库中计算资源的情况,并通过调度算法计算符合虚拟机创建需要的主机。
11、对于有符合虚拟机创建的主机,nova-scheduler更新数据库中虚拟机对应的物理主机信息。
12、nova-scheduler通过rpc.cast向nova-compute发送对应的创建虚拟机请求的消息。
13、nova-compute会从对应的消息队列中获取创建虚拟机请求的消息。
14、nova-compute通过rpc.call向nova-conductor请求获取虚拟机消息。(Flavor)
15、nova-conductor从消息队队列中拿到nova-compute请求消息。
16、nova-conductor根据消息查询虚拟机对应的信息。
17、nova-conductor从数据库中获得虚拟机对应信息。
18、nova-conductor把虚拟机信息通过消息的方式发送到消息队列中。
19、nova-compute从对应的消息队列中获取虚拟机信息消息。
20、nova-compute通过keystone的RESTfull API拿到认证的token,并通过HTTP请求glance-api获取创建虚拟机所需要镜像。
21、glance-api向keystone认证token是否有效,并返回验证结果。
22、token验证通过,nova-compute获得虚拟机镜像信息(URL)。
23、nova-compute通过keystone的RESTfull API拿到认证k的token,并通过HTTP请求neutron-server获取创建虚拟机所需要的网络信息。
24、neutron-server向keystone认证token是否有效,并返回验证结果。
25、token验证通过,nova-compute获得虚拟机网络信息。
26、nova-compute通过keystone的RESTfull API拿到认证的token,并通过HTTP请求cinder-api获取创建虚拟机所需要的持久化存储信息。
27、cinder-api向keystone认证token是否有效,并返回验证结果。
28、token验证通过,nova-compute获得虚拟机持久化存储信息。
29、nova-compute根据instance的信息调用配置的虚拟化驱动来创建虚拟机。
九.Horizon
1.区域(Region)
(1).地理上的概念,可以理解为一个独立的数据中心,每个所定义的区域有自己独立的Endpoint;
(2).区域之间是完全隔离的,但多个区域之间共享同一个Keystone和Dashboard(目前Openstack中的Dashboard还不支持多个区域);
(3).除了提供隔离的功能,区域的设计更多侧重地理位置的概念,用户可以选择离自己更新的区域来部署自己的服务,选择不同的区域主要是考虑那个区域更靠近自己,如用户在美国,可以选择离美国更近的区域;
(4).区域的概念是由Amazon在AWS中提出,主要是解决容错能力和可靠性;
2.可用性区域(Availablilty Zone)
AZ是在Region范围内的再次切分,例如可以把一个机架上的服务器划分为一个AZ,划分AZ是为了提高容灾能力和提供廉价的隔离服务;
3.Host Aggreates
一组具有共同属性的节点集合,如以CPU作为区分类型的一个属性,以磁盘(SSD\SAS\SATA)作为区分类型的一个属性,以OS(Windows\Linux)为作区分类型的一个属性;
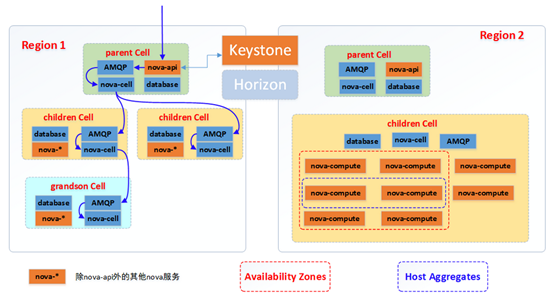
4.Cell
nova为了增加横向扩展以及分布式、大规模(地理位置级别)部署的能力,同时又不增加数据库和消息中间件的复杂度,引入了cell的概念,并引入了nova-cell服务。
(1).主要是用来解决OpenStack的扩展性和规模瓶颈;
(2).每个Cell都有自己独立的DB和AMQP,不与其他模块共用DB和AMQP,解决了大规模环境中DB和AMQP的瓶颈问题;
(3).Cell实现了树形结构(通过消息路由)和分级调度(过滤算法和权重算法),Cell之间通过RPC通讯,解决了扩展性问题;

十.Cinder
1.cinder架构

Cinder-api:接收 API 请求,调用 cinder-volume ;
Cinder-volume:管理 volume 的服务,与 volume provider 协调工作,管理 volume 的生命周期。运行 cinder-volume 服务的节点被称作为存储节点。
cinder-scheduler:scheduler 通过调度算法选择最合适的存储节点创建 volume。
volume provider:数据的存储设备,为 volume 提供物理存储空间。 cinder-volume 支持多种 volume provider,每种 volume provider 通过自己的 driver 与cinder-volume 协调工作。
Message Queue:Cinder 各个子服务通过消息队列实现进程间通信和相互协作。因为有了消息队列,子服务之间实现了解耦,这种松散的结构也是分布式系统的重要特征。
Database Cinder :有一些数据需要存放到数据库中,一般使用 MySQL。数据库是安装在控制节点上。
2.从volume创建流程看cinder子服务如何协同工作:
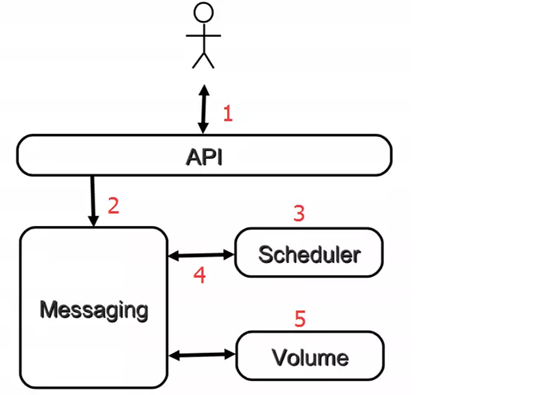
1.客户(可以是 OpenStack 最终用户,也可以是其他程序)向 API(cinder-api)发送请求:“帮我创建一个 volume”;
2.API 对请求做一些必要处理后,向 Messaging(RabbitMQ)发送了一条消息:“让 Scheduler 创建一个 volume”
3.Scheduler(cinder-scheduler)从 Messaging 获取到 API 发给它的消息,然后执行调度算法,从若干计存储点中选出节点 A
4.Scheduler 向 Messaging 发送了一条消息:“让存储节点 A 创建这个 volume”
5.存储节点 A 的 Volume(cinder-volume)从 Messaging 中获取到 Scheduler 发给它的消息,然后通过 driver 在 volume provider 上创建 volume。
数据持久化
如果您想创建一个使用临时存储的实例,意味着当实例被删除时数据会丢失,那么从以下启动项中选择一个:
镜像:本选项使用一个镜像启动实例。
实例快照:此选项使用一个实例快照来启动实例。
如果您想创建一个使用持久存储的实例,意味着当实例被删除时数据被保存,那么选择从以下启动项中选择一个
镜像(带有选中“创建新卷”):此选项使用镜像来启动实例,并且创建一个新卷来持久化实例数据。您可以指定卷大小并指定在删除实例时是否删除实例。
卷:这个选项使用一个已存在的卷。它不创建新卷。您可以选择在删除实例时删除卷。注意:当选择卷时,您只能启动一个实例。
卷快照:此选项使用卷快照启动实例,并且创建一个新卷来持久化实例数据。您可以选择在删除实例时删除卷。
Openstack知识点总结的更多相关文章
- OpenStack知识点详解
一:云计算 一.起源 1. 云计算这个概念首次在2006年8月的搜索引擎会议上提出,成为了继互联网.计算机后信息时代的又一种革新(互联网第三次革命). 2. 云计算的核心是将资源协调在一起,使 ...
- 虚拟化代码博客 good
推荐网站和博客地址 -------------------------------- 虚拟化代码博客 QEMU大牛博客:qemu - 韋任的維基百科 http://people.cs.nctu ...
- 别以为真懂Openstack: 虚拟机创建的50个步骤和100个知识点(3)
四.Nova-compute 步骤17:nova-compute接收到请求后,通过Resource Tracker将创建虚拟机所需要的资源声明占用 步骤18:调用Neutron API配置Networ ...
- 别以为真懂Openstack: 虚拟机创建的50个步骤和100个知识点(1)
还是先上图吧,无图无真相 别以为真懂Openstack!先别着急骂我,我也没有说我真懂Openstack 我其实很想弄懂Openstack,然而从哪里下手呢?作为程序员,第一个想法当然是代码,Code ...
- 别以为真懂Openstack: 虚拟机创建的50个步骤和100个知识点(5)
八.KVM 这一步,像virsh start命令一样,将虚拟机启动起来了.虚拟机启动之后,还有很多的步骤需要完成. 步骤38:从DHCP Server获取IP 有时候往往数据库里面,VM已经有了IP, ...
- 别以为真懂Openstack: 虚拟机创建的50个步骤和100个知识点(4)
六.Libvirt 对于Libvirt,在启动虚拟机之前,首先需要define虚拟机,是一个XML格式的文件 列出所有的Instance # virsh list Id Name ...
- 别以为真懂Openstack: 虚拟机创建的50个步骤和100个知识点(2)
二.nova-api 步骤3:nova-api接收请求 nova-api接收请求,也不是随便怎么来都接收的,而是需要设定rate limits,默认的实现是在ratelimit的middleware里 ...
- OpenStack基础知识-打包知识点
OpenStack是使用setuptools工具来进行打包,不过为了满足OpenStack项目的需求,引入了一个辅助工具pbr来配合setuptools完成打包工作. pbr (Python Buil ...
- 写在最前面 - 每天5分钟玩转 OpenStack(1)
<每天5分钟玩转 OpenStack>是一个 OpenStack 教程,这是第 1 篇. 这个教程有下面两个特点: 系统讲解 OpenStack 从架构到各个组件:从整体到细节逐一讨论 重 ...
随机推荐
- scala-currying化
scala的加里化(currying)纠结了很久.通过Scala Worksheet 可以打印很多调试信息,所以用它写了一些测试代码,帮助自己理解. object test { //一个参数列表,3个 ...
- Bootstrap-轮播图-No.5
<!DOCTYPE html> <html lang="zh"> <head> <meta charset="UTF-8&quo ...
- CodeForces 839D - Winter is here | Codeforces Round #428 (Div. 2)
赛后听 Forever97 讲的思路,强的一匹- - /* CodeForces 839D - Winter is here [ 数论,容斥 ] | Codeforces Round #428 (Di ...
- Mysql数据库多对多关系未建新表
原则上,多对多关系是要新建一个关系表的,当遇到没有新建表的情况下如何查询多对多的SQL呢? FIND_IN_SET(str,strlist) 官网:http://dev.mysql.com/doc/r ...
- [Python自学] day-19 (1) (FBV和CBV、路由系统)
一.获取表单提交的数据 在 [Python自学] day-18 (2) (MTV架构.Django框架)中,我们使用过以下方式来获取表单数据: user = request.POST.get('use ...
- 了解Springboot加载文件机制
https://blog.csdn.net/u014044812/article/details/84256764(
- Cogs 647. [Youdao2010] 有道搜索框(Trie树)
[Youdao2010] 有道搜索框 ★☆ 输入文件:youdao.in 输出文件:youdao.out 简单对比 时间限制:1 s 内存限制:128 MB [问题描述] 在有道搜索框中,当输入一个或 ...
- 最远 Manhattan 距离
最远 Manhattan 距离 处理问题 K维空间下的n个点,求两点最远曼哈顿距离 思路 以二维为例介绍算法思想,即可类推到k维.对于P,Q两点,曼哈顿距离|Px-Qx|+|Py-Qy|可看作(±Px ...
- ARTS打卡计划第十一周
Algorithms: https://leetcode-cn.com/problems/linked-list-cycle/ 链表环. Review: “What I learned from do ...
- 2018-2019-2 20165330《网络对抗技术》Exp8 Web基础
目录 基础问题 相关知识 实验内容 实验步骤 实验总结与体会 实验内容 Web前端HTML 能正常安装.启停Apache.理解HTML,理解表单,理解GET与POST方法,编写一个含有表单的HTML ...