MySQL--------SQL优化审核工具实战
1. 背景
SQLAdvisor是由美团点评公司技术工程部DBA团队(北京)开发维护的一个分析SQL给出索引优化建议的工具。它基于MySQL原生态词法解析,结合分析SQL中的where条件、聚合条件、多表Join关系 给出索引优化建议。目前SQLAdvisor在美团点评内部广泛应用,公司内部对SQLAdvisor的开发全面转到github上,开源和内部使用保持一致。
在数据库运维过程中,优化SQL是业务团队与DBA团队的日常任务。例行SQL优化,不仅可以提升程序性能,还能够降低线上故障的概率。
目前常用的SQL优化方式包括但不限于:业务层优化、SQL逻辑优化、索引优化等。其中索引优化通常通过调整索引或新增索引从而达到SQL优化的目的。索引优化往往可以在短时间内产生非常巨大的效果。如果能够将索引优化转化成工具化、标准化的流程,减少人工介入的工作量,无疑会大大提高DBA的工作效率。板面的做法和配料
2. 架构流程图
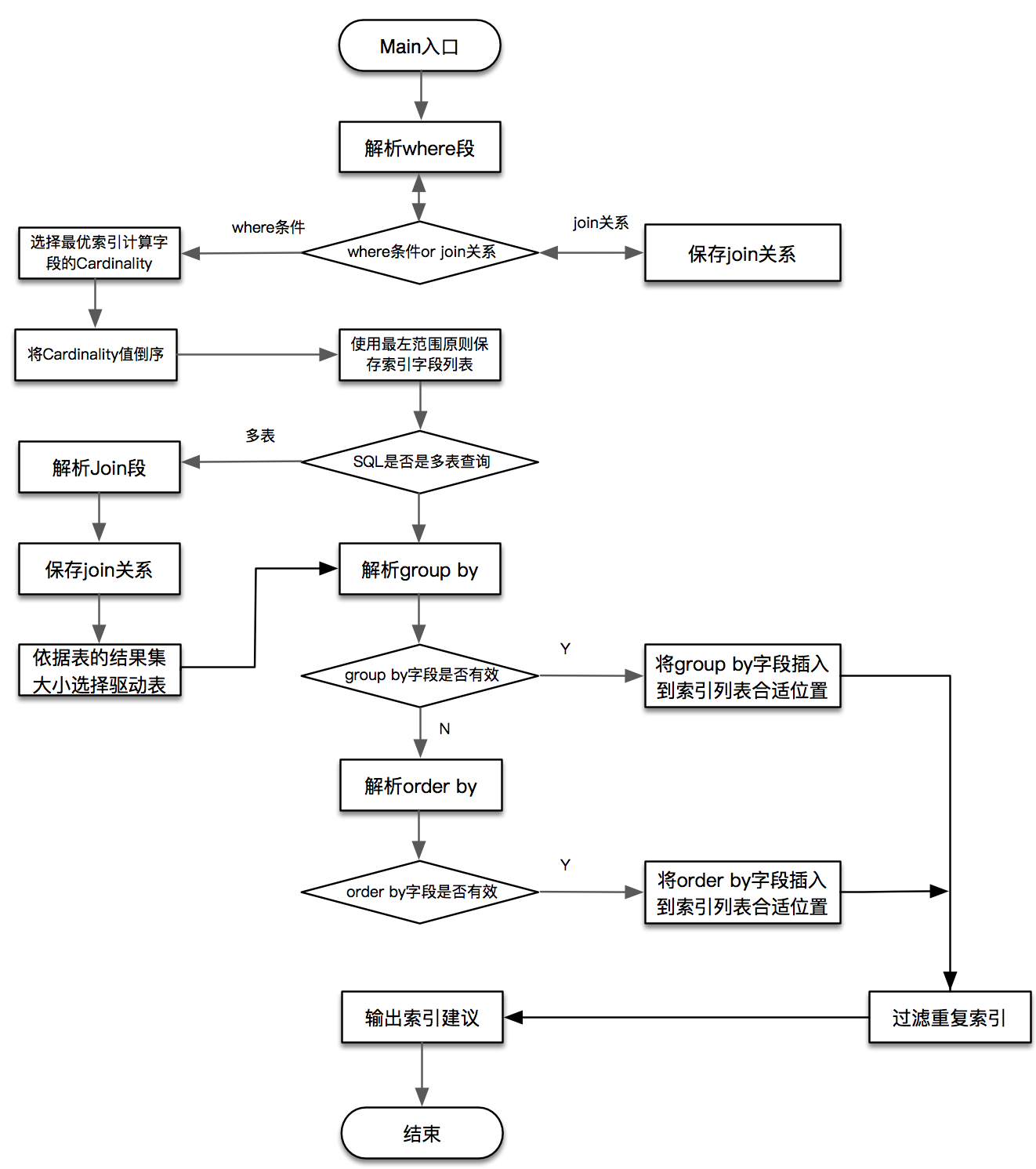
3. 环境
* os version
|
1
2
3
4
5
6
7
8
9
10
11
|
[root@SQLAdvisor ~]# cat /etc/redhat-release CentOS release 6.8 (Final)[root@SQLAdvisor ~]# uname -r2.6.32-642.3.1.el6.x86_64[root@SQLAdvisor ~]# uname -nSQLAdvisor[root@SQLAdvisor ~]# getenforce Disabled |
* mysql version
|
1
2
3
4
5
6
7
|
mysql> show variables like 'version';+---------------+--------+| Variable_name | Value |+---------------+--------+| version | 5.7.18 |+---------------+--------+1 row in set (0.00 sec) |
4. 安装SQLAdvisor
* 获取最新代码
|
1
2
3
4
5
6
|
[root@SQLAdvisor ~]# git clone https://github.com/Meituan-Dianping/SQLAdvisor.gitInitialized empty Git repository in /root/SQLAdvisor/.git/remote: Counting objects: 1460, done.remote: Total 1460 (delta 0), reused 0 (delta 0), pack-reused 1460Receiving objects: 100% (1460/1460), 19.92 MiB | 209 KiB/s, done.Resolving deltas: 100% (368/368), done. |
* 安装依赖项
|
1
2
3
4
5
6
7
|
[root@SQLAdvisor ~]# yum -y install cmake libaio-devel libffi-devel glib2 glib2-devel[root@SQLAdvisor ~]# yum -y install [root@SQLAdvisor ~]# yum -y install Percona-Server-shared-56 [root@SQLAdvisor ~]# ln -s /usr/lib64/libperconaserverclient_r.so.18 /usr/lib64/libperconaserverclient_r.so |
* 编译依赖项sqlparser
|
1
2
3
4
5
|
[root@SQLAdvisor ~]# cd SQLAdvisor/[root@SQLAdvisor SQLAdvisor]# cmake -DBUILD_CONFIG=mysql_release -DCMAKE_BUILD_TYPE=debug -DCMAKE_INSTALL_PREFIX=/usr/local/sqlparser ./[root@SQLAdvisor SQLAdvisor]# make && make install |
* 安装SQLAdvisor
|
1
2
3
4
5
|
[root@SQLAdvisor SQLAdvisor]# cd sqladvisor/[root@SQLAdvisor sqladvisor]# cmake -DCMAKE_BUILD_TYPE=debug ./[root@SQLAdvisor sqladvisor]# make |
* SQLAdvisor Info
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
[root@SQLAdvisor sqladvisor]# ./sqladvisor --helpUsage: sqladvisor [OPTION...] sqladvisorSQL Advisor SummaryHelp Options: -?, --help Show help optionsApplication Options: -f, --defaults-file sqls file -u, --username username -p, --password password -P, --port port -h, --host host -d, --dbname database name -q, --sqls sqls -v, --verbose 1:output logs 0:output nothing |
5. 测试
* 生成测试数据表
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
mysql> create database test1 character set utf8mb4;Query OK, 1 row affected (0.00 sec)mysql> create table user( -> id INT PRIMARY KEY AUTO_INCREMENT, -> name VARCHAR(64) NOT NULL, -> age int, -> sex int -> )ENGINE=INNODB DEFAULT CHARSET=utf8mb4;Query OK, 0 rows affected (0.13 sec)mysql> desc user;+-------+-------------+------+-----+---------+----------------+| Field | Type | Null | Key | Default | Extra |+-------+-------------+------+-----+---------+----------------+| id | int(11) | NO | PRI | NULL | auto_increment || name | varchar(64) | NO | | NULL | || age | int(11) | YES | | NULL | || sex | int(11) | YES | | NULL | |+-------+-------------+------+-----+---------+----------------+4 rows in set (0.01 sec) |
* 生成测试数据
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
mysql> insert into user(name,age, sex) select 'lisea', 25, 1;Query OK, 1 row affected (0.01 sec)Records: 1 Duplicates: 0 Warnings: 0mysql> insert into user(name,age, sex) select concat(name, '1'), age+1, sex+1 from user;Query OK, 1 row affected (0.02 sec)Records: 1 Duplicates: 0 Warnings: 0mysql> insert into user(name,age, sex) select concat(name, '2'), age+2, sex from user;Query OK, 2 rows affected (0.02 sec)Records: 2 Duplicates: 0 Warnings: 0mysql> insert into user(name,age, sex) select concat(name, '3'), age+2, sex from user;Query OK, 4 rows affected (0.18 sec)Records: 4 Duplicates: 0 Warnings: 0......mysql> insert into user(name,age, sex) select concat(name, '10'), age+2, sex from user;Query OK, 512 rows affected (0.24 sec)Records: 512 Duplicates: 0 Warnings: 0mysql> insert into user(name,age, sex) select concat(name, '11'), age+4, sex from user;Query OK, 1024 rows affected (0.79 sec)Records: 1024 Duplicates: 0 Warnings: 0mysql> select count(1) from user;+----------+| count(1) |+----------+| 2048 |+----------+1 row in set (0.01 sec) |
* 命令行传参调用测试SQLAdvisor [查找非索引行]
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
[root@SQLAdvisor sqladvisor]# ./sqladvisor -h 127.0.0.1 -P 3306 -u root -p '123' -d test1 -q "select * from user where name = 'lisea'" -v 12017-10-27 05:35:49 34059 [Note] 第1步: 对SQL解析优化之后得到的SQL:select `*` AS `*` from `test1`.`user` where (`name` = 'lisea') 2017-10-27 05:35:49 34059 [Note] 第2步:开始解析where中的条件:(`name` = 'lisea') 2017-10-27 05:35:49 34059 [Note] show index from user 2017-10-27 05:35:49 34059 [Note] show table status like 'user' 2017-10-27 05:35:49 34059 [Note] select count(*) from ( select `name` from `user` FORCE INDEX( PRIMARY ) order by id DESC limit 1024) `user` where (`name` = 'lisea') 2017-10-27 05:35:49 34059 [Note] 第3步:表user的行数:2048,limit行数:1024,得到where条件中(`name` = 'lisea')的选择度:1024 2017-10-27 05:35:49 34059 [Note] 第4步:开始验证 字段name是不是主键。表名:user 2017-10-27 05:35:49 34059 [Note] show index from user where Key_name = 'PRIMARY' and Column_name ='name' and Seq_in_index = 1 2017-10-27 05:35:49 34059 [Note] 第5步:字段name不是主键。表名:user 2017-10-27 05:35:49 34059 [Note] 第6步:开始验证 字段name是不是主键。表名:user 2017-10-27 05:35:49 34059 [Note] show index from user where Key_name = 'PRIMARY' and Column_name ='name' and Seq_in_index = 1 2017-10-27 05:35:49 34059 [Note] 第7步:字段name不是主键。表名:user 2017-10-27 05:35:49 34059 [Note] 第8步:开始验证表中是否已存在相关索引。表名:user, 字段名:name, 在索引中的位置:1 2017-10-27 05:35:49 34059 [Note] show index from user where Column_name ='name' and Seq_in_index =1 2017-10-27 05:35:49 34059 [Note] 第9步:开始输出表user索引优化建议: 2017-10-27 05:35:49 34059 [Note] Create_Index_SQL:alter table user add index idx_name(name) 2017-10-27 05:35:49 34059 [Note] 第10步: SQLAdvisor结束! |
* 命令行传参调用测试SQLAdvisor [查找索引行]
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
[root@SQLAdvisor sqladvisor]# ./sqladvisor -h 127.0.0.1 -P 3306 -u root -p '123' -d test1 -q "select * from user where id = 1" -v 12017-10-27 05:36:46 34062 [Note] 第1步: 对SQL解析优化之后得到的SQL:select `*` AS `*` from `test1`.`user` where (`id` = 1) 2017-10-27 05:36:46 34062 [Note] 第2步:开始解析where中的条件:(`id` = 1) 2017-10-27 05:36:46 34062 [Note] show index from user 2017-10-27 05:36:46 34062 [Note] show table status like 'user' 2017-10-27 05:36:46 34062 [Note] select count(*) from ( select `id` from `user` FORCE INDEX( PRIMARY ) order by id DESC limit 1024) `user` where (`id` = 1) 2017-10-27 05:36:46 34062 [Note] 第3步:表user的行数:2048,limit行数:1024,得到where条件中(`id` = 1)的选择度:1024 2017-10-27 05:36:46 34062 [Note] 第4步:开始验证 字段id是不是主键。表名:user 2017-10-27 05:36:46 34062 [Note] show index from user where Key_name = 'PRIMARY' and Column_name ='id' and Seq_in_index = 1 2017-10-27 05:36:46 34062 [Note] 第5步:字段id是主键。表名:user 2017-10-27 05:36:46 34062 [Note] 第6步:表user 经过运算得到的索引列首列是主键,直接放弃,没有优化建议 2017-10-27 05:36:46 34062 [Note] 第7步: SQLAdvisor结束! |
* 配置文件传参调用
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
[root@SQLAdvisor sqladvisor]# cat sql.cnf [sqladvisor]username=rootpassword=123host=127.0.0.1port=3306dbname=test1sqls=select * from user where name = 'lisea'[root@SQLAdvisor sqladvisor]# ./sqladvisor -f sql.cnf -v 12017-10-27 05:40:14 34070 [Note] 第1步: 对SQL解析优化之后得到的SQL:select `*` AS `*` from `test1`.`user` where (`name` = 'lisea') 2017-10-27 05:40:14 34070 [Note] 第2步:开始解析where中的条件:(`name` = 'lisea') 2017-10-27 05:40:14 34070 [Note] show index from user 2017-10-27 05:40:14 34070 [Note] show table status like 'user' 2017-10-27 05:40:14 34070 [Note] select count(*) from ( select `name` from `user` FORCE INDEX( PRIMARY ) order by id DESC limit 1024) `user` where (`name` = 'lisea') 2017-10-27 05:40:14 34070 [Note] 第3步:表user的行数:2048,limit行数:1024,得到where条件中(`name` = 'lisea')的选择度:1024 2017-10-27 05:40:14 34070 [Note] 第4步:开始验证 字段name是不是主键。表名:user 2017-10-27 05:40:14 34070 [Note] show index from user where Key_name = 'PRIMARY' and Column_name ='name' and Seq_in_index = 1 2017-10-27 05:40:14 34070 [Note] 第5步:字段name不是主键。表名:user 2017-10-27 05:40:14 34070 [Note] 第6步:开始验证 字段name是不是主键。表名:user 2017-10-27 05:40:14 34070 [Note] show index from user where Key_name = 'PRIMARY' and Column_name ='name' and Seq_in_index = 1 2017-10-27 05:40:14 34070 [Note] 第7步:字段name不是主键。表名:user 2017-10-27 05:40:14 34070 [Note] 第8步:开始验证表中是否已存在相关索引。表名:user, 字段名:name, 在索引中的位置:1 2017-10-27 05:40:14 34070 [Note] show index from user where Column_name ='name' and Seq_in_index =1 2017-10-27 05:40:14 34070 [Note] 第9步:开始输出表user索引优化建议: 2017-10-27 05:40:14 34070 [Note] Create_Index_SQL:alter table user add index idx_name(name) 2017-10-27 05:40:14 34070 [Note] 第10步: SQLAdvisor结束! |
MySQL--------SQL优化审核工具实战的更多相关文章
- mysql sql优化实例
mysql sql优化实例 优化前: pt-query-degist分析结果: # Query 3: 0.00 QPS, 0.00x concurrency, ID 0xDC6E62FA021C85B ...
- sql自动审核工具-inception
[inception使用规范及说明文档](http://mysql-inception.github.io/inception-document/usage/)[代码仓库](https://githu ...
- Mysql SQL优化&执行计划
SQL优化准则 禁用select * 使用select count(*) 统计行数 尽量少运算 尽量避免全表扫描,如果可以,在过滤列建立索引 尽量避免在where子句对字段进行null判断 尽量避免在 ...
- 18.Mysql SQL优化
18.SQL优化18.1 优化SQL语句的一般步骤 18.1.1 通过show status命令了解各种SQL的执行频率show [session|global] status; -- 查看服务器状态 ...
- mysql sql优化及注意事项
sql优化分析 通过slow_log等方式可以捕获慢查询sql,然后就是减少其对io和cpu的使用(不合理的索引.不必要的数据访问和排序)当我们面对具体的sql时,首先查看其执行计划A.看其是否使用索 ...
- MySQL sql优化(摘抄自文档)
前言 有人反馈之前几篇文章过于理论缺少实际操作细节,这篇文章就多一些可操作性的内容吧. 注:这篇文章是以 MySQL 为背景,很多内容同时适用于其他关系型数据库,需要有一些索引知识为基础. 优化目标 ...
- MySQL SQL优化
一.优化数据库的一般步骤: (A) 通过 show status 命令了解各种SQL的执行频率. (B) 定位执行效率较低的SQL语句,方法两种: 事后查询定位:慢查询日志:--log-slow-qu ...
- MySQL SQL优化之in与range查询【转】
本文来自:http://myrock.github.io/ 首先我们来说下in()这种方式的查询.在<高性能MySQL>里面提及用in这种方式可以有效的替代一定的range查询,提升查询效 ...
- MySql Sql 优化技巧分享
有天发现一个带inner join的sql 执行速度虽然不是很慢(0.1-0.2),但是没有达到理想速度.两个表关联,且关联的字段都是主键,查询的字段是唯一索引. sql如下: SELECT p_it ...
随机推荐
- windows下编译libnet0.10.11
以下编译基于windows下visual studio 2013 (注:编译安装完成之后发现与网上的arp教程中使用的libnet不是一个版本,这个版本太老了,最后没有使用. 网络教程上使用的是lib ...
- Hanlp-地名识别调试方法详解
HanLP收词特别是实体比较多,因此特别容易造成误识别.下边举几个地名误识别的例子,需要指出的是,后边的机构名识别也以地名识别为基础,因此,如果地名识别不准确,也会导致机构名识别不准确. 类型1 数字 ...
- java中public protected friendly private作用域
1.public:public表明该数据成员.成员函数是对所有用户开放的,所有用户都可以直接进行调用 2.private:private表示私有,私有的意思就是除了class自己之外,任何人都不可以直 ...
- 三种SpringSecurity方法级别权限控制
一 JSR-250注解 1.在pom.xml添加 <dependency> <groupId>javax.annotation</groupId> <arti ...
- 适合新手的160个creakme(一)
先跑一下 直接使用这个字符串去check,发现提示信息有关键字符串 CODE:0042FB80 00000021 C Sorry , The serial is incorect ! 找到这个字符串的 ...
- shell习题第19题:最常用的命令
[题目要求] 查看使用最多的10个命令 [核心要点] history 或者 ~/.bash_history sort uniq [脚本] #!/bin/bash # history就是调用cat ~/ ...
- ASP.NET Core 2.0 中读取 Request.Body 的正确姿势
原文:ASP.NET Core 中读取 Request.Body 的正确姿势 ASP.NET Core 中的 Request.Body 虽然是一个 Stream ,但它是一个与众不同的 Stream ...
- aspectcore 简单解析
.netcore 下aspectcore 的使用 动态代理: static void Main(string[] args) { Console.WriteLine("Hello Worl ...
- 史上最全Java集合中List,Set以及Map等集合体系详解
一.概述 List , Set, Map都是接口,前两个继承至collection接口,Map为独立接口 Set下有HashSet,LinkedHashSet,TreeSet List下有ArrayL ...
- Socket的神秘面纱
Tcp/IP协议是目前世界上使用最为广泛的协议,是以Tcp/IP为基础多个层次上的协议的集合.也称Tcp/IP协议族或Tcp/IP协议栈. TCP: Transmission Control Prot ...