JDK源码那些事儿之SynchronousQueue上篇
今天继续来讲解阻塞队列,一个比较特殊的阻塞队列SynchronousQueue,通过Executors框架提供的线程池cachedThreadPool中我们可以看到其被使用作为可缓存线程池的队列实现,下面通过源码来了解其内部实现,便于后面帮助我们更好的使用线程池
前言
JDK版本号:1.8.0_171
synchronousQueue是一个没有数据缓冲的阻塞队列,生产者线程的插入操作put()必须等待消费者的删除操作take(),反过来也一样。当然,也可以不进行等待直接返回,例如poll和offer
在使用上很好理解,每次操作都需要找到对应的匹配操作,如A线程通过put插入操作填入值1,如果无其他线程操作则需要阻塞等待一个线程执行take操作A线程才能继续,反过来同样道理,这样看似乎synchronousQueue是没有队列进行保存数据的,每次操作都在等待其互补操作一起执行
这里和其他阻塞队列不同之处在于,内部类将入队出队操作统一封装成了一个接口实现,内部类数据保存的是每个操作动作,比如put操作,保存插入的值,并根据标识来判断是入队还是出队操作,如果是take操作,则值为null,通过标识符能判断出来是出队操作
多思考下,我们需要找到互补的操作必然需要一个公共的区域来判断已经发生的所有操作,内部类就是用来进行这些操作的,SynchronousQueue分为公平策略(FIFO)和非公平策略(LIFO),两种策略分别对应其两个内部类实现,公平策略使用队列结构实现,非公平策略使用栈结构实现
由于篇幅过长,本篇先说明SynchronousQueue相关知识和公平策略下的实现类TransferQueue,下篇将说明非公平策略下的实现类TransferStack和其他知识
类定义
public class SynchronousQueue<E> extends AbstractQueue<E>
implements BlockingQueue<E>, java.io.Serializable
常量/变量
/** The number of CPUs, for spin control */
// cpu数量,会在自旋控制时使用
static final int NCPUS = Runtime.getRuntime().availableProcessors();
// 自旋次数,指定了超时时间时使用,这个常量配合CAS操作使用,相当于循环次数
// 如果CAS操作失败,则根据这个参数判断继续循环
static final int maxTimedSpins = (NCPUS < 2) ? 0 : 32;
// 自旋次数,未指定超时时间时使用
static final int maxUntimedSpins = maxTimedSpins * 16;
/**
* The number of nanoseconds for which it is faster to spin
* rather than to use timed park. A rough estimate suffices.
*/
// 自旋超时时间阈值,在设置的时间超过这个时间时以这个时间为准,单位,纳秒
static final long spinForTimeoutThreshold = 1000L;
// 后进先出队列和先进先出队列
@SuppressWarnings("serial")
static class WaitQueue implements java.io.Serializable { }
static class LifoWaitQueue extends WaitQueue {
private static final long serialVersionUID = -3633113410248163686L;
}
static class FifoWaitQueue extends WaitQueue {
private static final long serialVersionUID = -3623113410248163686L;
}
// 序列化操作使用
private ReentrantLock qlock;
private WaitQueue waitingProducers;
private WaitQueue waitingConsumers;
/**
* The transferer. Set only in constructor, but cannot be declared
* as final without further complicating serialization. Since
* this is accessed only at most once per public method, there
* isn't a noticeable performance penalty for using volatile
* instead of final here.
*/
// 所有的队列操作都通过transferer来执行,统一方法执行
// 初始化时会根据所选的策略实例化对应的内部实现类
private transient volatile Transferer<E> transferer;
从上边也能看出没有设置变量来保存入队出队操作的数据,统一操作方法都放置到了Transferer中
构造方法
构造方法很清晰,根据所选的策略实现对应的Transferer内部接口实现类来进行队列操作
// 默认非公平策略
public SynchronousQueue() {
this(false);
}
// 可选策略,通过两个内部类TransferQueue和TransferStack来实现公平策略(队列)和非公平策略(栈)
public SynchronousQueue(boolean fair) {
transferer = fair ? new TransferQueue<E>() : new TransferStack<E>();
}
抽象类Transferer
抽象内部类Transferer,transfer方法用来替代put和take操作,每个参数解释如下:
- e:非空时,说明本身为put操作,生产者入队操作,需要消费者出队操作来获取入队的值;空时,说明本身是消费者,消费者消费操作需要生产者入队操作拿到入队的值
- timed:操作是否设置超时
- nanos:超时时间,单位:纳秒
返回值:非空则表明操作成功,返回消费的item或生产的item;空则表明由于超时或中断引起操作失败。调用者可以通过检查Thread.interrupted判断是哪种原因
/**
* Shared internal API for dual stacks and queues.
*/
abstract static class Transferer<E> {
/**
* Performs a put or take.
*
* @param e if non-null, the item to be handed to a consumer;
* if null, requests that transfer return an item
* offered by producer.
* @param timed if this operation should timeout
* @param nanos the timeout, in nanoseconds
* @return if non-null, the item provided or received; if null,
* the operation failed due to timeout or interrupt --
* the caller can distinguish which of these occurred
* by checking Thread.interrupted.
*/
abstract E transfer(E e, boolean timed, long nanos);
}
重要方法
put/offer
入队操作通过内部类调用transfer,传参含义如下已在上面内部抽象类中说明,入队元素e非空
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
if (transferer.transfer(e, false, 0) == null) {
Thread.interrupted();
throw new InterruptedException();
}
}
public boolean offer(E e, long timeout, TimeUnit unit)
throws InterruptedException {
if (e == null) throw new NullPointerException();
if (transferer.transfer(e, true, unit.toNanos(timeout)) != null)
return true;
if (!Thread.interrupted())
// 超时返回false
return false;
// 线程中断抛错
throw new InterruptedException();
}
public boolean offer(E e) {
if (e == null) throw new NullPointerException();
return transferer.transfer(e, true, 0) != null;
}
take/poll
出队操作通过内部类调用transfer,入队元素e为null
public E take() throws InterruptedException {
E e = transferer.transfer(null, false, 0);
if (e != null)
return e;
Thread.interrupted();
throw new InterruptedException();
}
public E poll(long timeout, TimeUnit unit) throws InterruptedException {
E e = transferer.transfer(null, true, unit.toNanos(timeout));
if (e != null || !Thread.interrupted())
return e;
throw new InterruptedException();
}
public E poll() {
return transferer.transfer(null, true, 0);
}
其他方法以空队列为标准进行处理,比如队列长度直接返回0,判空总是返回true,其他方法类似,直接参考源码,比较简单,不多说
内部实现类
上面已经看到了最重要的核心方法在于transferer.transfer方法,那么其具体的实现类中这个方法是如何实现的呢?
先说明公平策略下的实现类TransferQueue
TransferQueue
基于Transferer实现公平策略下的实现类TransferQueue,既然是公平策略,则需要先进先出,这里queue也表明其结构特点,内部通过QNode类实现链表的队列形态,通过CAS操作更新链表元素
有两种状态需要注意:
- 取消操作(被外部中断或者超时):item == this;
- 离队操作(已成功匹配,找到互补操作):next == this;
QNode
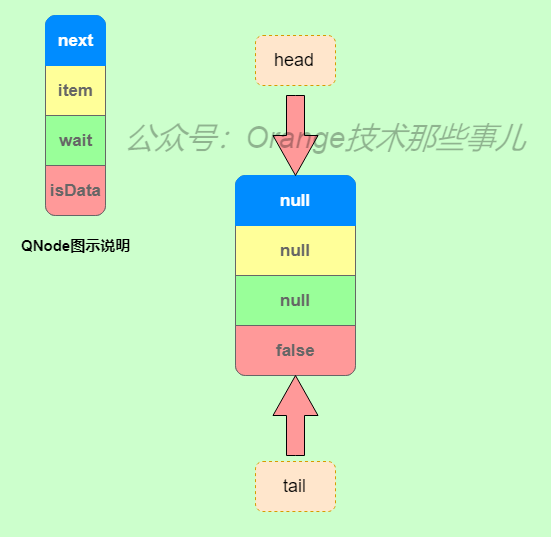
QNode即为队列的链表实现,其中的变量属性isData也可以看出其保存的是每次的操作动作而不仅仅是入队的值,入队操作会以QNode保存,出队操作同样会以QNode保存,同时变量都是通过CAS操作更新
static final class QNode {
// next指向链表下一个节点
volatile QNode next; // next node in queue
// 队列元素的值
volatile Object item; // CAS'ed to or from null
// 保存等待的线程
volatile Thread waiter; // to control park/unpark
// 是否有数据,队列元素的类型标识,入队时有数据值为true,出队时无数据值为false
final boolean isData;
QNode(Object item, boolean isData) {
this.item = item;
this.isData = isData;
}
// cas操作更新next
boolean casNext(QNode cmp, QNode val) {
return next == cmp &&
UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
// cas操作更新item
boolean casItem(Object cmp, Object val) {
return item == cmp &&
UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val);
}
// cas操作取消操作,将当前的QNode的item赋值为当前的QNode
void tryCancel(Object cmp) {
UNSAFE.compareAndSwapObject(this, itemOffset, cmp, this);
}
// 判断是否取消成功,紧跟着tryCancel操作后进行判断
boolean isCancelled() {
return item == this;
}
// 判断当前节点是否已处于离队状态,这里看到是将节点next指向自己
boolean isOffList() {
return next == this;
}
// 获取item和next的偏移量,操作CAS使用
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long itemOffset;
private static final long nextOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = QNode.class;
itemOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("item"));
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) {
throw new Error(e);
}
}
}
变量
队头队尾元素引用设置,需要注意的是cleanMe节点的含义,在具体方法操作中会进行说明
/** Head of queue */
// 队头
transient volatile QNode head;
/** Tail of queue */
// 队尾
transient volatile QNode tail;
/**
* Reference to a cancelled node that might not yet have been
* unlinked from queue because it was the last inserted node
* when it was cancelled.
*/
// 标记节点,清理链表尾部节点时,不直接删除尾部节点,而是将尾节点的前驱节点next指向设置为cleanMe
// 防止此时向尾部插入节点的线程失败导致出现数据问题
transient volatile QNode cleanMe;
// 偏移量获取
private static final sun.misc.Unsafe UNSAFE;
private static final long headOffset;
private static final long tailOffset;
private static final long cleanMeOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = TransferQueue.class;
headOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("head"));
tailOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("tail"));
cleanMeOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("cleanMe"));
} catch (Exception e) {
throw new Error(e);
}
}
构造方法
头尾节点初始化操作
TransferQueue() {
// 初始化一个值为null的QNode,初始化头尾节点
QNode h = new QNode(null, false); // initialize to dummy node.
head = h;
tail = h;
}
advanceHead/advanceTail/casCleanMe
CAS更新变量操作
/**
* Tries to cas nh as new head; if successful, unlink
* old head's next node to avoid garbage retention.
*/
// 尝试将nh更新为新的队头
void advanceHead(QNode h, QNode nh) {
if (h == head &&
UNSAFE.compareAndSwapObject(this, headOffset, h, nh))
// 原头节点next指向更新为自己,使得h为离队状态,isOffList方法为true
h.next = h; // forget old next
}
/**
* Tries to cas nt as new tail.
*/
// 尝试更新队尾节点
void advanceTail(QNode t, QNode nt) {
if (tail == t)
UNSAFE.compareAndSwapObject(this, tailOffset, t, nt);
}
/**
* Tries to CAS cleanMe slot.
*/
// 尝试更新cleanMe节点
boolean casCleanMe(QNode cmp, QNode val) {
return cleanMe == cmp &&
UNSAFE.compareAndSwapObject(this, cleanMeOffset, cmp, val);
}
transfer
入队和出队操作,统一使用一个方法,即实现接口中的transfer方法来完成,需要明白的是保存的是每次操作这个动作
/**
* Puts or takes an item.
*/
@SuppressWarnings("unchecked")
E transfer(E e, boolean timed, long nanos) {
QNode s = null; // constructed/reused as needed
// e为null时相当于出队操作isData为false,入队操作为true
boolean isData = (e != null);
for (;;) {
// 获取最新的尾节点和头节点
QNode t = tail;
QNode h = head;
// 头,尾节点为空,未初始化,则循环spin
if (t == null || h == null) // saw uninitialized value
continue; // spin
// 首尾节点相同则为空队列或尾节点类型和新操作的类型相同,都是入队操作或出队操作
// 为何只判断尾部,因为如果头节点和尾结点不同在队列中不可能存在
// 一入队和一出队直接进入else匹配上不会再保存在链表中
if (h == t || t.isData == isData) { // empty or same-mode
QNode tn = t.next;
// 尾节点已经被其他线程更新修改,则重新循环判断
if (t != tail) // inconsistent read
continue;
// tn非空,说明其他线程已经添加了节点,尝试更新尾节点,重新循环判断
if (tn != null) { // lagging tail
advanceTail(t, tn);
continue;
}
// 设置超时时间并且超时时间小于等于0则直接返回null
if (timed && nanos <= 0) // can't wait
return null;
// s为null则初始化节点s
if (s == null)
s = new QNode(e, isData);
// 尝试将s添加到尾节点的next上,失败则重新循环
if (!t.casNext(null, s)) // failed to link in
continue;
// 尝试更新尾节点,尾节点此时为s
advanceTail(t, s); // swing tail and wait
// 通过awaitFulfill方法自旋阻塞找到匹配操作的节点item,这个下面进行说明
Object x = awaitFulfill(s, e, timed, nanos);
// 表示当前线程已经中断或者超时,在awaitFulfill超时或者中断时更新s.item指向自己
if (x == s) { // wait was cancelled
// 清理节点,取消本次操作
clean(t, s);
return null;
}
// 判断s是否已从队列移除,正常情况下,出队和入队操作匹配上s节点肯定是需要被清理掉的
if (!s.isOffList()) { // not already unlinked
// 未被从队列清除则尝试更新队头
advanceHead(t, s); // unlink if head
// 当前线程为出队操作时,s节点取消操作
if (x != null) // and forget fields
s.item = s;
// 清除等待线程
s.waiter = null;
}
return (x != null) ? (E)x : e;
// 与上次队列操作非同一类型操作,上次入队,这次为出队,上次出队,这次为入队才会执行
// 匹配操作才会执行下面逻辑
} else { // complementary-mode
QNode m = h.next; // node to fulfill
// 头节点或尾节点被其他线程更新或者为空队列则循环操作
if (t != tail || m == null || h != head)
continue; // inconsistent read
// 头节点的下一个节点对应的item
Object x = m.item;
// 同类型,被取消操作或更新item失败则更新头节点指向重新操作
if (isData == (x != null) || // m already fulfilled 相同类型操作说明m已经被其他线程操作匹配
x == m || // m cancelled 取消操作标识
// CAS更新item为匹配上的操作值,比如当前是出队操作,m为入队操作x为入队的值,那么此时要替换为出队值null
// CAS操作失败
!m.casItem(x, e)) { // lost CAS
// 删除匹配上的头节点,更新头节点
advanceHead(h, m); // dequeue and retry
continue;
}
// 更新头节点
advanceHead(h, m); // successfully fulfilled
// 释放m的等待线程锁使得m操作结束
LockSupport.unpark(m.waiter);
return (x != null) ? (E)x : e;
}
}
}
awaitFulfill
在transfer相同类型操作时被调用,正常情况下(不算超时和中断)阻塞线程直到与之匹配的操作到来再继续执行
/**
* Spins/blocks until node s is fulfilled.
*
* @param s the waiting node
* @param e the comparison value for checking match
* @param timed true if timed wait
* @param nanos timeout value
* @return matched item, or s if cancelled
*/
// 自旋或阻塞直到超时或被唤醒匹配上节点
// 比如此时是入队操作,上次也是入队操作,在未设置超时时,这里可能需要自旋或阻塞等待一个出队操作来唤醒本次入队操作
// 相当于互补匹配上同时继续完成后续操作,出队操作拿走入队操作的值才能完成 入队操作被出队操作获取值才能完成
Object awaitFulfill(QNode s, E e, boolean timed, long nanos) {
/* Same idea as TransferStack.awaitFulfill */
// 获取超时时间点
final long deadline = timed ? System.nanoTime() + nanos : 0L;
// 当前线程
Thread w = Thread.currentThread();
// 仅在head.next==s时才使用spins(自旋次数),同时判断是否设置了超时
// 非head.next则不走spins,相当于只是在第一次操作入链表时执行自旋spins操作,不是上来就进行阻塞
// 也能明白,在入队和出队操作匹配时 新操作是和头节点匹配,故自旋一定次数而不是直接阻塞来提升执行效率,减少线程切换开销
int spins = ((head.next == s) ?
(timed ? maxTimedSpins : maxUntimedSpins) : 0);
for (;;) {
// 判断当前线程是否中断,外部中断操作,相当于取消本次操作
if (w.isInterrupted())
// 尝试将s节点的item设置为s自己,这样判断的时候就知道这个节点是被取消的
s.tryCancel(e);
Object x = s.item;
// s的item已经改变,直接返回x
// 没改变的情况下即没有匹配的操作,有匹配上的item即x将被改变,取消时如上也会改变,如下超时也会改变
// 故return后还需要要区分出取消和超时的情况
if (x != e)
return x;
// 线程超时将s节点的item设置为s自己
if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
s.tryCancel(e);
continue;
}
}
// 需要自旋时循环
if (spins > 0)
--spins;
// 设置s的等待线程
else if (s.waiter == null)
s.waiter = w;
// 未设置超时,直接阻塞
else if (!timed)
LockSupport.park(this);
// 设置超时时间阻塞
else if (nanos > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanos);
}
}
clean
清理s节点,同时需要关注cleanMe节点,整体处理过程如下:
- 删除的节点不是尾节点,使用pred.casNext(s, s.next) 方式来进行清理
- 删除节点是队尾节点,如果cleanMe为空,则将其前继节点pred更新为cleanMe, 为下次删除做准备
- 如果cleanMe不为空,则根据cleanMe删除上次需要删除的节点, 然后将cleanMe置空, 如果此次pred非之前cleanMe,则cleanMe置为pred,为下一次删除操作做准备
/**
* Gets rid of cancelled node s with original predecessor pred.
*/
// 中断取消操作将pred节点代替s节点,修改前后节点之间的关联
void clean(QNode pred, QNode s) {
// 清理前先将等待线程置空
s.waiter = null; // forget thread
// pred与s的前后关系
while (pred.next == s) { // Return early if already unlinked
QNode h = head;
QNode hn = h.next; // Absorb cancelled first node as head
// hn非空且被取消操作,更新头节点为hn
if (hn != null && hn.isCancelled()) {
advanceHead(h, hn);
continue;
}
// 尾节点
QNode t = tail; // Ensure consistent read for tail
// 空队列返回
if (t == h)
return;
// 尾节点下一个
QNode tn = t.next;
// 尾节点已被其他线程更新
if (t != tail)
continue;
// 非空 更新尾节点
if (tn != null) {
advanceTail(t, tn);
continue;
}
// s不是尾节点
if (s != t) { // If not tail, try to unsplice
// s的下一个节点
QNode sn = s.next;
// 更新pred节点后一个节点为s的下一个节点,相当于删除s在链表中的关系
if (sn == s || pred.casNext(s, sn))
return;
}
// 执行到这里说明s为尾节点则需要处理cleanMe节点
QNode dp = cleanMe;
if (dp != null) { // Try unlinking previous cancelled node
// 被清除的节点,从下面else部分代码也可以看出如果为空,传入的节点为清理节点的前一个节点
// 这里代表上次需要清理的cleanMe节点
// 这里d代表真正需要清理的节点即dp.next
QNode d = dp.next;
QNode dn;
if (d == null || // 清除节点为null,相当于已经清理了
d == dp || // dp节点处于离队状态
!d.isCancelled() || // 清除节点被取消
(d != t && // 清除节点非尾节点
(dn = d.next) != null && // 清除节点下一节点非null
dn != d && // 清除节点下一节点在队列中
dp.casNext(d, dn))) // 清理d与其他节点的关系
casCleanMe(dp, null); // 清理完毕设置为null
// 相当于s为需要清理的节点,上边已经清理过了,不需要再次清理
if (dp == pred)
return; // s is already saved node
// 更新cleanMe为pred,为下次清理准备
} else if (casCleanMe(null, pred))
return; // Postpone cleaning s
}
}
举例说明
TransferQueue的源码操作上面已经说明完毕,为了更好的理解其内部数据转换,举个例子同时画图进行说明方便各位理解:
public class SynchronousQueueTest {
public static void main(String[] args) {
BlockingQueue<String> sq = new SynchronousQueue<>(true);
new Thread(() -> {
try {
System.out.println(sq.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
new Thread(() -> {
try {
sq.put("test");
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}
上面代码很简单,公平模式下,一个线程执行take操作,一个线程执行put操作,那么SynchronousQueue内部是如何处理的呢?我们以图进行说明
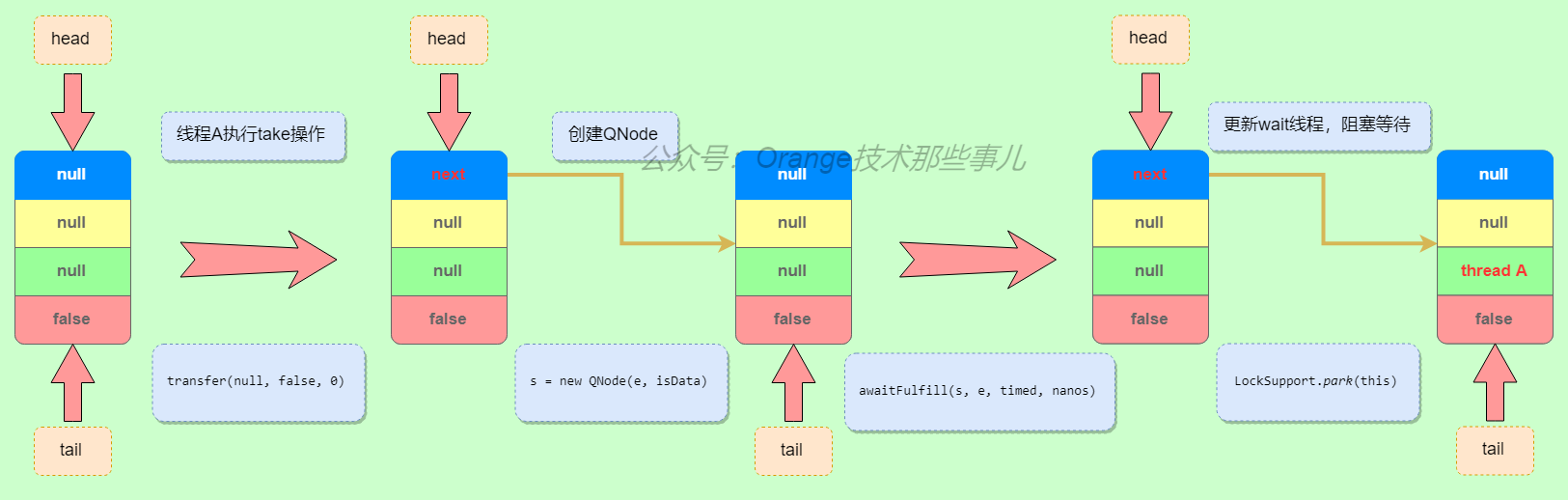
1.创建公平策略下的SynchronousQueue
2.一线程执行take操作,以先执行take的线程为例子进行说明,此时另一线程put操作还未执行,take操作阻塞等待
3.另一线程执行put操作,唤醒之前阻塞等待的take操作,同时处理完成
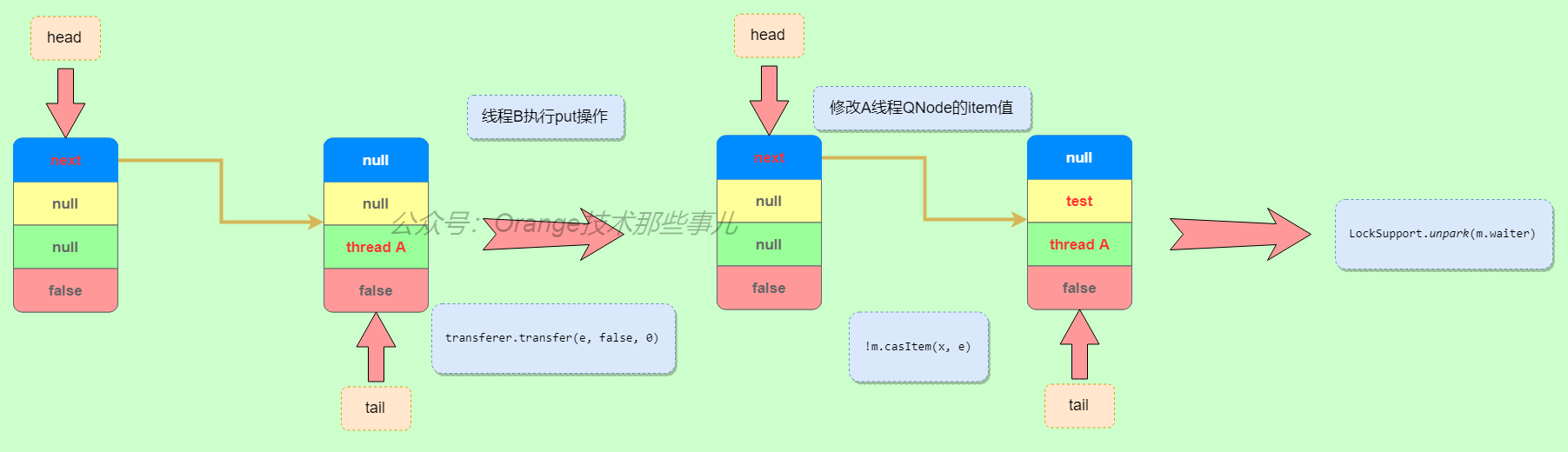
之后会进行节点的清理和头尾节点的指向更新,这部分自行读者可自行画图理解
总结
SynchronousQueue是一个无数据缓冲的阻塞队列,在不进行超时和中断的情况下,入队操作需匹配出队操作才能继续执行下去,相当于进行互补操作,同时执行,成双成对完成,在理解这点的基础上,我们可以看到其拥有以下特点:
- 内部实现主要在于两个内部实现类,同时需要理解内部类中节点保存的不是数据而是每次操作这个动作
- 通过封装的一个接口transfer来完成入队和出队操作
- cleanMe节点操作时的特殊考虑
非公平策略下的实现类TransferStack和其他知识将放在下篇文章进行说明
以上内容如有问题欢迎指出,笔者验证后将及时修正,谢谢
JDK源码那些事儿之SynchronousQueue上篇的更多相关文章
- JDK源码那些事儿之SynchronousQueue下篇
之前一篇文章已经讲解了阻塞队列SynchronousQueue的大部分内容,其中默认的非公平策略还未说明,本文就紧接上文继续讲解其中的非公平策略下的内部实现,顺便简单说明其涉及到的线程池部分的使用 前 ...
- JDK源码那些事儿之并发ConcurrentHashMap上篇
前面已经说明了HashMap以及红黑树的一些基本知识,对JDK8的HashMap也有了一定的了解,本篇就开始看看并发包下的ConcurrentHashMap,说实话,还是比较复杂的,笔者在这里也不会过 ...
- JDK源码那些事儿之浅析Thread上篇
JAVA中多线程的操作对于初学者而言是比较难理解的,其实联想到底层操作系统时我们可能会稍微明白些,对于程序而言最终都是硬件上运行二进制指令,然而,这些又太过底层,今天来看一下JAVA中的线程,浅析JD ...
- JDK源码那些事儿之红黑树基础下篇
说到HashMap,就一定要说到红黑树,红黑树作为一种自平衡二叉查找树,是一种用途较广的数据结构,在jdk1.8中使用红黑树提升HashMap的性能,今天就来说一说红黑树,上一讲已经给出插入平衡的调整 ...
- JDK源码那些事儿之红黑树基础上篇
说到HashMap,就一定要说到红黑树,红黑树作为一种自平衡二叉查找树,是一种用途较广的数据结构,在jdk1.8中使用红黑树提升HashMap的性能,今天就来说一说红黑树. 前言 限于篇幅,本文只对红 ...
- JDK源码那些事儿之LinkedTransferQueue
在JDK8的阻塞队列实现中还有两个未进行说明,今天继续对其中的一个阻塞队列LinkedTransferQueue进行源码分析,如果之前的队列分析已经让你对阻塞队列有了一定的了解,相信本文要讲解的Lin ...
- JDK源码那些事儿之ConcurrentLinkedDeque
非阻塞队列ConcurrentLinkedQueue我们已经了解过了,既然是Queue,那么是否有其双端队列实现呢?答案是肯定的,今天就继续说一说非阻塞双端队列实现ConcurrentLinkedDe ...
- JDK源码那些事儿之ConcurrentLinkedQueue
阻塞队列的实现前面已经讲解完毕,今天我们继续了解源码中非阻塞队列的实现,接下来就看一看ConcurrentLinkedQueue非阻塞队列是怎么完成操作的 前言 JDK版本号:1.8.0_171 Co ...
- JDK源码那些事儿之LinkedBlockingDeque
阻塞队列中目前还剩下一个比较特殊的队列实现,相比较前面讲解过的队列,本文中要讲的LinkedBlockingDeque比较容易理解了,但是与之前讲解过的阻塞队列又有些不同,从命名上你应该能看出一些端倪 ...
随机推荐
- pycharm设置开发模板/字体大小/背景颜色(3)
一.pycharm设置字体大小/风格 选择 File –> setting –> Editor –> Font ,可以看到如上界面,可以根据自己的喜好随意调整字体大小,字体风格,文字 ...
- cnbolgs博客中添加Latex支持
参考:http://www.cnblogs.com/ilogic/archive/2012/08/05/latex.html 主要是利用在线生成公式的工具:MathJax,但要在博客上获得 MathJ ...
- 字符串的分隔方法 split()
java中的split()的方法 string.split([separator,[limit]]) 参数 string (必选),要被分解的 String 对象或文字.该对象不会被 split 方法 ...
- PC电脑看电视 / 电视直播 / 高清频道 / 直播源
打开方式 PotPlayer + .m3u播放列表 效果图 .m3u播放列表 #EXTM3U #EXTINF:150,CCTV1综合 http://183.251.61.207/PLTV/888888 ...
- ps -ef|grep详解 、kill与kill -9的区别
ps -ef|grep详解 ps命令将某个进程显示出来 grep命令是查找 中间的|是管道命令 是指ps命令与grep同时执行 PS是LINUX下最常用的也是非常强大的进程查看命令 grep命令是查找 ...
- C++ 获取系统当前时间(日历时)
获取系统当前时间(日历时) //Linux & C++11 #include <chrono> #include <ctime> using namespace std ...
- Python socket编程 (2)--实现文件验证登入
可以实现从客户端输入账号和密码然后发送到服务器进行验证,实现用户登入校正操作. 服务器: import socket import json server = socket.socket() serv ...
- Go语言学习笔记(9)——接口类型
接口 Go 语言提供了另外一种数据类型即接口,它把所有的具有共性的方法定义在一起,任何其他类型只要实现了这些方法就是实现了这个接口. /* 定义接口 */ type interface_name in ...
- Springboot入门及配置文件介绍(内置属性、自定义属性、属性封装类)
目的: 1.Springboot入门 SpringBoot是什么? 使用Idea配置SpringBoo使用t项目 测试案例 2.Springboot配置文件介绍 内置属性 自定义属性 属性封装类 Sp ...
- MySQL 体系结构及存储引擎
MySQL 原理篇 MySQL 索引机制 MySQL 体系结构及存储引擎 MySQL 语句执行过程详解 MySQL 执行计划详解 MySQL InnoDB 缓冲池 MySQL InnoDB 事务 My ...