内部排序总结之----插入类排序(插入和Shell)
一、直接插入排序
直接插入排序(straight insertion sort)的做法是:
每次从无序表中取出第一个元素,把它插入到有序表的合适位置,使有序表仍然有序。
第一趟比较前两个数,然后把第二个数按大小插入到有序表中; 第二趟把第三个数据与前两个数从后向前扫描,把第三个数按大小插入到有序表中;依次进行下去,进行了(n-1)趟扫描以后就完成了整个排序过程。
void insertSort(int arr[],int len)
{
int i,j;
for(i = ; i < len; ++i)
{
for(j = i; j > && arr[j] < arr[j-]; --j)//j为待排序序列头部
{
int tmp = arr[j];
arr[j] = arr[j-];
arr[j-] = tmp;
}
}
}
直接插入排序总结:
时间复杂度:平均情况O(n2),最好情况O(n),最坏情况O(n2)
空间复杂度:O(1)
稳定性:稳定
直接插入排序较为简单,一笔带过,我们下面看看另一种优化的插入排序---Shell排序。
二、Shell排序
观察一下”插入排序“:其实不难发现它有个缺点:
如果当数据是“5, 4, 3, 2, 1”的时候,此时我们将“待排序序列”中的记录插入到“有序序列”时,每次比较都要挪动数据,此时插入排序的效率可想而知。
shell根据这个弱点进行了算法改进,融入了一种叫做“缩小增量排序法”的思想,其实也蛮简单的,不过有点注意的就是:增量不是乱取,而是有规律可循的。
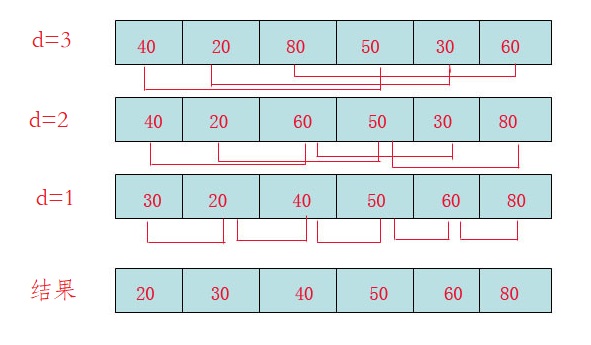
d=3时:将40跟50比,因50大,不交换。
将20跟30比,因30大,不交换。
将80跟60比,因60小,交换。
d=2时:将40跟60比,不交换,拿60跟30比交换,此时交换后的30又比前面的40小,又要将40和30交换,如上图。
将20跟50比,不交换,继续将50跟80比,不交换。
d=1时:这时就是前面讲的插入排序了,不过此时的序列已经差不多有序了,所以给插入排序带来了很大的性能提高。
插入类排序的特点就是:越有序越快。
#include <stdio.h> void Shell(int arr[],int arr_len,int dk)
{
int i,j;
//此时dk就是一个单位长度,相当于直接插入排序中的1 for(i = dk; i < arr_len; ++i)
{
for(j = i - dk; j >= 0 && arr[j+dk] < arr[j]; j -=dk)
{
int tmp = arr[j+dk];
arr[j+dk] = arr[j];
arr[j] = tmp;
}
}
} void ShellSort(int arr[],int arr_len,int dka[],int dka_len)//分组
{
int i;
for (i = 0; i < dka_len; i++)
{
Shell(arr,arr_len,dka[i]);
}
} void Show(int arr[],int len)
{
for(int i = 0; i < len; i++)
{
printf("%d ",arr[i]);
}
printf("\n"); }
int main ()
{
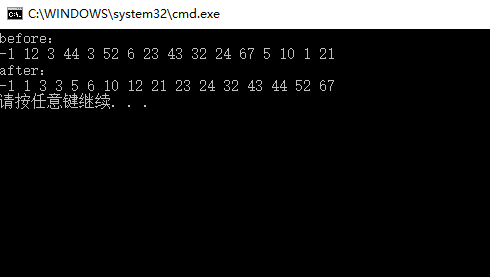
int arr[] = {-1,12,3,44,3,52,6,23,43,32,24,67,5,10,1,21};
int dk[] = {5,3,1};
int len = sizeof(arr)/sizeof(arr[0]);
int lenDk = sizeof(dk)/sizeof(dk[0]); printf("before:\n");
Show(arr,len);
ShellSort(arr,len,dk,lenDk);
printf("after:\n");
Show(arr,len);
return 0;
}
那么如何选取关键字呢?就是分成三组,一组,这个分组的依据是什么呢?为什么不是二组,六组或者其它组嘞?
增量序列的共同特征:
① 最后一个增量必须为1(如果最后一个增量不为1,会出现有数据没有参加排序)
② 应该尽量避免序列中的值(尤其是相邻的值)互为倍数的情况(如果为倍数,相当于,后面的排序再重复之前的行为)
Shell排序总结:
时间复杂度:平均情况O(n1.3),最好情况O(n),最坏情况O(n2)
空间复杂度:O(1)
稳定性:不稳定
优劣:

),Shell排序时间复杂度的下界是n*log2n。Shell排序没有快速排序算法快 O(n(logn)),因此中等大小规模表现良好,对规模非常大的数据排序不是最优选择。但是比O(

)复杂度的算法快得多。并且Shell排序非常容易实现,算法代码短而简单。 此外,Shell算法在最坏的情况下和平均情况下执行效率相差不是很多,与此同时快速排序在最坏的情况下执行的效率会非常差。专家们提倡,几乎任何排序工作在开始时都可以用Shell排序,若在实际使用中证明它不够快,再改成快速排序这样更高级的排序算法. 本质上讲,Shell排序算法是直接插入排序算法的一种改进,减少了其复制的次数,速度要快很多。 原因是,当n值很大时数据项每一趟排序需要移动的个数很少,但数据项的距离很长。当n值减小时每一趟需要移动的数据增多,此时已经接近于它们排序后的最终位置。 正是这两种情况的结合才使Shell排序效率比插入排序高很多。Shell算法的性能与所选取的分组长度序列有很大关系。只对特定的待排序记录序列,可以准确地估算关键词的比较次数和对象移动次数。想要弄清关键词比较次数和记录移动次数与增量选择之间的关系,并给出完整的数学分析,至今仍然是数学难题。
内部排序总结之----插入类排序(插入和Shell)的更多相关文章
- 【PHP数据结构】插入类排序:简单插入、希尔排序
总算进入我们的排序相关算法的学习了.相信不管是系统学习过的还是没有系统学习过算法的朋友都会听说过许多非常出名的排序算法,当然,我们今天入门的内容并不是直接先从最常见的那个算法说起,而是按照一定的规则一 ...
- C语言排序算法学习笔记——插入类排序
排序就是讲原本无序的序列重新排序成有序的序列.序列里可以是一个单独数据,也可以是多个数据组合的记录,按照记录里的主关键字或者次关键字进行排序. 排序的稳定性:如果排序表中有两个元素R1,R2,其对应的 ...
- Java实现单词自定义排序|集合类、工具类排序、comparable、comparator接口
课题 针对单词进行排序,先按字母的长度排序,长者在前: 在长度相等的情况下,按字典降序排序. 例如,有单词序列"apple banana grape orange",排序后输出结果 ...
- 剑指offer 查找和排序的基本操作:查找排序算法大集合
重点 查找算法着重掌握:顺序查找.二分查找.哈希表查找.二叉排序树查找. 排序算法着重掌握:冒泡排序.插入排序.归并排序.快速排序. 顺序查找 算法说明 顺序查找适合于存储结构为顺序存储或链接存储的线 ...
- java中的TreeMap如何顺序按照插入顺序排序
java中的TreeMap如何顺序按照插入顺序排序 你可以使用LinkedHashMap 这个是可以记住插入顺序的. 用LinkedHashMap吧.它内部有一个链表,保持插入的顺序.迭代的时候,也 ...
- Java四种排序:冒泡,选择,插入,二分(折半插入)
四种排序:冒泡,选择,插入,二分(折半插入) public class Test{ // public static void main(String[] args) { // Test t=new ...
- php插入式排序的两种写法。
百度了下插入式排序,百度百科中php版本的插入式排序如下: function insert_sort($arr) { // 将$arr升序排列 $count = count($arr); for ($ ...
- 左神算法第一节课:复杂度、排序(冒泡、选择、插入、归并)、小和问题和逆序对问题、对数器和递归(Master公式)
第一节课 复杂度 排序(冒泡.选择.插入.归并) 小和问题和逆序对问题 对数器 递归 1. 复杂度 认识时间复杂度常数时间的操作:一个操作如果和数据量没有关系,每次都是固定时间内完成的操作,叫做常数 ...
- 《Entity Framework 6 Recipes》中文翻译系列 (16) -----第三章 查询之左连接和在TPH中通过派生类排序
翻译的初衷以及为什么选择<Entity Framework 6 Recipes>来学习,请看本系列开篇 3-10应用左连接 问题 你想使用左外连接来合并两个实体的属性. 解决方案 假设你有 ...
随机推荐
- Linux上定时shell脚本
原文链接:http://www.92coder.com/9-Linux%E5%AE%9A%E6%97%B6shell%E8%84%9A%E6%9C%AC/#more 本文主要介绍在Linux系统上部署 ...
- Python如何将字符和Unicode编码转变
小小总结一下,以防过几天忘记,自己的复习资料,如果能帮到大家,也是有所作用!! 1,字符转化为Unicode编码方法: ord("字符") ord("A") o ...
- 电脑串口(com)被占用问题
最近使用串口与设备通信. 这个电脑一个有6个COM口,都要使用. 还有自带一个华为的4G通信模块,这个模块需要虚拟出4个COM口. 使用之前的Gost系统(只有1个物理COM版本的),导致物理COM口 ...
- ORACLE触发器的自治事务的注意事项
直接上代码: Create OR replace Trigger TR_ROBXMX_CLDJBHHX After INSERT OR UPDATE OR DELETE ON ROBXMX1 --要监 ...
- Nginx笔记一
nginx: 为什么选择nginx: nginx是一个高性能的web和反向代理服务器. 作为web服务器:使用更少的资源,支持更多的并发连接,更高的效率,能够支持高达5w个并发连接数的相应, 作为 ...
- 安全开发Java动态代理
关于安全开发的一些思考 之前面试某宝的时候,某人问过我,如果解决开发不懂安全的问题,就比如说SSRF,XEE这样的漏洞,如果一旦发生,应该如果立刻去响应,并帮助开发人员修复漏洞,难道写一个jar包?然 ...
- linux基础5-vi文本处理器
三种模式下各自可以完成的操作: 一般模式:可以完成光标移动.删除单个和整行字.复制和黏贴,通过i.o.a.r这几个命令进入编辑模式 编辑模式:可以输入字符,通过esc返回一般模式 指令模式:读取文件, ...
- SqlServer和Oralce保留几位小数以及当末尾小数为0也显示
需求描述:对数字类型值保留2位小数,当2位小数末尾出现0时也显示 SqlServer处理方法: 1.首先通过Round函数保留2位有效数字,多出的位数值变成0 2.通过Cast函数转成decimal( ...
- java.util.NoSuchElementException
问题引入 Java商店作业不同函数里需要获取用户输入,用Scanner的时候,出现了异常java.util.NoSuchElementException 作业中代码模式如下,func1和func2中都 ...
- MyBatis-05-解决属性名和字段名不一致的问题
5.解决属性名和字段名不一致的问题 1.问题 数据库中的字段 新建一个项目,拷贝之前的,测试实体类字段不一致的情况. public class User { private int id; priva ...